
- 116_安装gradle并在IDEA中进行整合_idea gradle
- 2uniapp小程序设置页面横屏_uniapp如何控制页面横屏显示
- 3纯SQL去除字段特殊符号_删除数据库表中的某字段的特定符号
- 4BP神经网络用于预测_p=[3.2 3.2 3 3.2 3.2 3.4 3.2 3 3.2 3.2 3.2 3.9 3.1
- 5Linux子系统下的pytorch3d安装记录_linux pytorch3d
- 6PAT 乙级 1011 A+B 和 C C语言实现
- 7构建多语言数字资产交易平台和秒合约系统:从概念到实现
- 8ionic3 文件上传(控件上传)_fileuploadoptions
- 9算法笔记(Java)——动态规划_java动态规划
- 10bp神经网络是用来干嘛的,bp神经网络是什么网络_bp神经网络预测是干什么的
CVPR 2021 | 即插即用! CA:新注意力机制,助力分类/检测/分割涨点!
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:AI人工智能初学者
Coordinate Attention for Efficient Mobile Network Design 论文:https://arxiv.org/abs/2103.02907代码链接(刚刚开源):https://github.com/Andrew-Qibin/CoordAttention
论文:https://arxiv.org/abs/2103.02907代码链接(刚刚开源):https://github.com/Andrew-Qibin/CoordAttention
本文提出Coordinate Attention,CA,可以插入到Mobile Network中,可以使MobileNetV2、EfficientNet等网络涨点,性能优于SE、CBAM等注意力模块,同时还可以提高检测、分割任务的性能,代码即将开源!
作者单位:南洋理工大学
1 简介
Mobile Network设计的最新研究成果表明,通道注意力(例如,SE注意力)对于提升模型性能具有显著效果,但它们通常会忽略位置信息,而位置信息对于生成空间选择性attention maps是非常重要。
因此在本文中,作者通过将位置信息嵌入到通道注意力中提出了一种新颖的移动网络注意力机制,将其称为“Coordinate Attention”。
与通过2维全局池化将特征张量转换为单个特征向量的通道注意力不同,coordinate注意力将通道注意力分解为两个1维特征编码过程,分别沿2个空间方向聚合特征。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。

本文所提的Coordinate注意力很简单,可以灵活地插入到经典的移动网络中,例如MobileNetV2,MobileNeXt和EfficientNet,而且几乎没有计算开销。大量实验表明,Coordinate注意力不仅有益于ImageNet分类,而且更有趣的是,它在下游任务(如目标检测和语义分割)中表现也很好。
2 相关工作
2.1 Mobile Network
最近的很多关于Mobile Network的工作大多数都是基于深度可分离卷积和inverted残差模块:
HBONet:在每个inverted残差模块中引入下采样操作,用于建模具有代表性的空间信息。
ShuffleNetV2:在inverted残差模块之前和之后使用通道分割模块和通道shuffle模块。
MobileNetV3:结合神经网络结构搜索算法,寻找最优激活函数和不同深度的inverted残差块的扩展比。
MixNet、EfficientNet和ProxylessNAS:也采用不同的搜索策略来搜索深度可分卷积的最优核大小或标量,从而从扩展比、输入分辨率、网络深度和宽度等方面控制网络权值。
最近,有学者重新思考了基于深度可分离卷积的方法,专门设计了基于Mobile Network的bottleneck结构,并基于此设计MobileNeXt。
2.2 注意力机制
想必大家都已经知道注意力机制在各种计算机视觉任务中都是有帮助,如图像分类和图像分割。其中最为经典和被熟知的便是SENet,它通过简单地squeeze每个2维特征图,进而有效地构建通道之间的相互依赖关系。

CBAM进一步推进了这一思想,通过大尺度核卷积引入空间信息编码。后来的研究如GENet、GALA、AA、TA,通过采用不同的空间注意力机制或设计高级注意力块,扩展了这一理念。

Non-local/self-attention Network则着重于构建spatial或channel注意力。典型的例子包括NLNet、GCNet、A2Net、SCNet、gsopnet和CCNet,它们都利用Non-local机制来捕获不同类型的空间信息。然而,由于self-attention模块内部计算量大,常被用于大型模型中,不适用于Mobile Network。

与Non-local/self-attention的方法不同,CA方法考虑了一种更有效的方法来捕获位置信息和通道关系,以增强Mobile Network的特征表示。通过将二维全局池操作分解为两个一维编码过程,本文方法比其他具有轻量级属性的注意力方法(如SENet、CBAM和TA)运行得更好。
3 Coordinate Attention
一个coordinate attention块可以被看作是一个计算单元,旨在增强Mobile Network中特征的表达能力。它可以将任何中间特征张量作为输入并通过转换输出了与 张量具有相同size同时具有增强表征的 。为了更加清晰的描述CA注意力,这里先对SE block进行讨论。
3.1 Revisit SE Block
在结构上,SE block可分解为Squeeze和Excitation 2步,分别用于全局信息嵌入和通道关系的自适应Re-weight。
Squeeze
在输入 的条件下,第 通道的squeeze步长可表示为:

式中,
是与第
通道相关的输出。
输入 来自一个固定核大小的卷积层,因此可以看作是局部描述符的集合。Sqeeze操作使模型收集全局信息成为可能。
Excitation
Excitation的目的是完全捕获通道之间的依赖,它可以被表述为:

其中
为通道乘法,
为
激活函数,
为变换函数生成的结果,公式如下:

这里,
和
是2个线性变换,可以通过学习来捕捉每个通道的重要性。
为什么SE Block不好?
SE Block虽然近2年来被广泛使用;然而,它只考虑通过建模通道关系来重新衡量每个通道的重要性,而忽略了位置信息,但是位置信息对于生成空间选择性attention maps是很重要的。因此作者引入了一种新的注意块,它不仅仅考虑了通道间的关系还考虑了特征空间的位置信息。
3.2 Coordinate Attention Block
Coordinate Attention通过精确的位置信息对通道关系和长期依赖性进行编码,具体操作分为Coordinate信息嵌入和Coordinate Attention生成2个步骤。
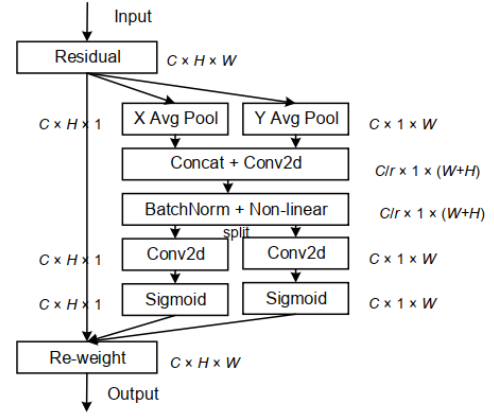
3.2.1 Coordinate信息嵌入
全局池化方法通常用于通道注意编码空间信息的全局编码,但由于它将全局空间信息压缩到通道描述符中,导致难以保存位置信息。为了促使注意力模块能够捕捉具有精确位置信息的远程空间交互,本文按照以下公式分解了全局池化,转化为一对一维特征编码操作:

具体来说,给定输入
,首先使用尺寸为(H,1)或(1,W)的pooling kernel分别沿着水平坐标和垂直坐标对每个通道进行编码。因此,高度为
的第
通道的输出可以表示为:

同样,宽度为
的第
通道的输出可以写成:

上述2种变换分别沿两个空间方向聚合特征,得到一对方向感知的特征图。这与在通道注意力方法中产生单一的特征向量的SE Block非常不同。这2种转换也允许注意力模块捕捉到沿着一个空间方向的长期依赖关系,并保存沿着另一个空间方向的精确位置信息,这有助于网络更准确地定位感兴趣的目标。
3.2.2 Coordinate Attention生成
通过3.2.1所述,本文方法可以通过上述的变换可以很好的获得全局感受野并编码精确的位置信息。为了利用由此产生的表征,作者提出了第2个转换,称为Coordinate Attention生成。这里作者的设计主要参考了以下3个标准:
首先,对于Mobile环境中的应用来说,新的转换应该尽可能地简单;
其次,它可以充分利用捕获到的位置信息,使感兴趣的区域能够被准确地捕获;
最后,它还应该能够有效地捕捉通道间的关系。
通过信息嵌入中的变换后,该部分将上面的变换进行concatenate操作,然后使用 卷积变换函数 对其进行变换操作:

式中
为沿空间维数的concatenate操作,
为非线性激活函数,
为对空间信息在水平方向和垂直方向进行编码的中间特征映射。这里,
是用来控制SE block大小的缩减率。然后沿着空间维数将
分解为2个单独的张量
和
。利用另外2个
卷积变换
和
分别将
和
变换为具有相同通道数的张量到输入
,得到:
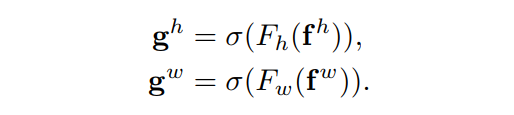
这里
是sigmoid激活函数。为了降低模型的复杂性和计算开销,这里通常使用适当的缩减比
(如32)来减少
的通道数。然后对输出
和
进行扩展,分别作为attention weights。
最后,Coordinate Attention Block的输出 可以写成:

3.2.3 CA Block的PyTorch实现
- import torch
- from torch import nn
-
-
- class CA_Block(nn.Module):
- def __init__(self, channel, h, w, reduction=16):
- super(CA_Block, self).__init__()
-
- self.h = h
- self.w = w
-
- self.avg_pool_x = nn.AdaptiveAvgPool2d((h, 1))
- self.avg_pool_y = nn.AdaptiveAvgPool2d((1, w))
-
- self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel//reduction, kernel_size=1, stride=1, bias=False)
-
- self.relu = nn.ReLU()
- self.bn = nn.BatchNorm2d(channel//reduction)
-
- self.F_h = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)
- self.F_w = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)
-
- self.sigmoid_h = nn.Sigmoid()
- self.sigmoid_w = nn.Sigmoid()
-
- def forward(self, x):
-
- x_h = self.avg_pool_x(x).permute(0, 1, 3, 2)
- x_w = self.avg_pool_y(x)
-
- x_cat_conv_relu = self.relu(self.conv_1x1(torch.cat((x_h, x_w), 3)))
-
- x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([self.h, self.w], 3)
-
- s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))
- s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))
-
- out = x * s_h.expand_as(x) * s_w.expand_as(x)
-
- return out
-
-
- if __name__ == '__main__':
- x = torch.randn(1, 16, 128, 64) # b, c, h, w
- ca_model = CA_Block(channel=16, h=128, w=64)
- y = ca_model(x)
- print(y.shape)

4. 实验
4.1 消融实验

当水平注意力和垂直注意力结合时得到了最好的结果,如表1所示。实验结果表明,Coordinate Information Embedding在图像分类中,可以在保证参数量的情况下提升精度。
4.2 与其他Attention进行比较

可以看出,添加SE attention已经使分类性能提高了1%以上。对于CBAM与SE注意相比,似乎在Mobile Network中没有提升。然而,当使用本文所提出的CA注意力时,取得了最好的结果。

在上图中,作者还将使用不同注意力方法的模型生成的特征图进行了可视化。显然,CA注意力比SE和CBAM更有助于目标的定位。
4.3 Stronger Baseline

为了检验所提CA注意力在EfficientNet上的表现,作者简单地用CA注意力代替SE。对于其他设置遵循原始文件。结果如表5。与原有的含SE的EfficientNet-b0方法以及其他与EfficientNet-b0的方法相比,CA注意力络获得了最好的结果。这也所提出的CA注意力在强大的Mobile Network中仍然具有良好的性能。
4.4 目标检测实验
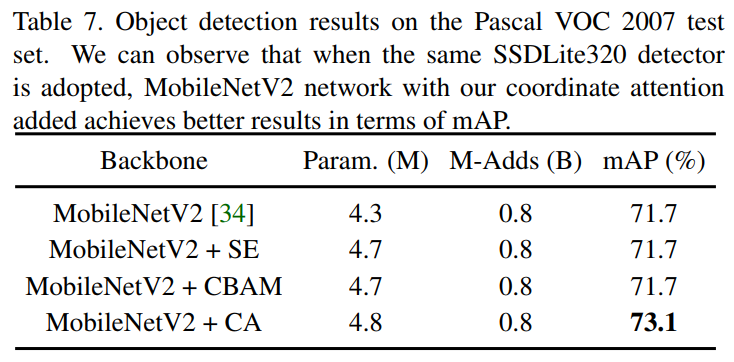
作者通过实验观察到SE和CBAM并不能改善Baseline的性能。然而,增加CA注意力可以很大程度上提高平均AP从71.7%到73.1%。在COCO和Pascal VOC数据集上的检测实验都表明,与其他注意力方法相比,具有CA注意力的分类模型具有更好的迁移能力。
4.5 语义分割实验
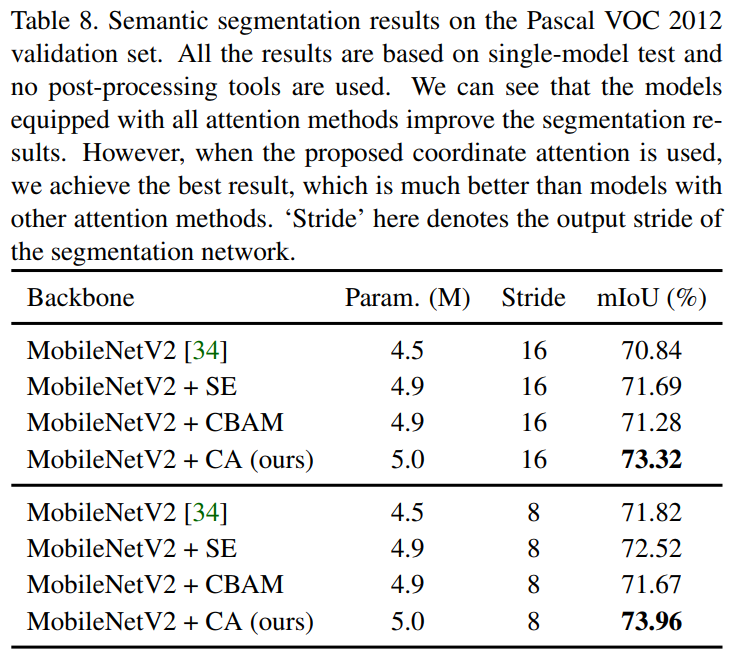
从表8可以看出,具有CA注意力的模型比vanilla MobileNetV2使用其他注意力的模型的表现要好得多。
5 参考
[1].Coordinate Attention for Efficient Mobile Network Design
上述论文和代码下载
后台回复:CA,即可下载上述论文PDF和项目源代码
后台回复:CVPR2021,即可下载CVPR 2021论文和开源代码合集
点击下方卡片并关注,了解CV最新动态
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看!![]()

