
热门标签
热门文章
- 1【网络安全】2024年热门网络安全运营工具/方案推荐_网络安全运营产品
- 2【花雕动手做】ASRPRO语音识别(46)---四路继电器的智能控制_asrpro语音模块四路继电器接线
- 3大模型基础理论学习笔记——大模型适配_大模型精确匹配
- 4解密人工智能:KNN | K-均值 | 降维算法 | 梯度Boosting算法 | AdaBoosting算法_adaboost降维
- 5【深度学习】语言模型与注意力机制以及Bert实战指引之一_bert模型注意力机制
- 66-1体育俱乐部I(构造函数)_体育俱乐部i(构造函数)
- 7什么是docker_何为docker
- 81DCNN和CNN的区别?
- 9寄予厚望!2024中科院《预警期刊名单》
- 10OpenCV 4基础篇| OpenCV图像的拼接_opencv 拼接
当前位置: article > 正文
Python数据分组计算利器:Transform函数_python transform
作者:Gausst松鼠会 | 2024-04-02 05:54:27
赞
踩
python transform
使用Python进行数据清洗时,需要对数据进行分组计算,一般使用’goupby+计算函数’,但是返回的结果并不是原来表格的格式。或者是使用遍历的方式,将每组计算的结果返回到原表格中。
Transform是Pandas中的一个函数,它用于在dataframe中对数据进行转换或操作,并且按照原来的Dataframe格式输出结果。transform函数通常用于按照分组的方式对数据进行操作,例如对每个组进行标准化、填充缺失值等。
(PS: 虽然标准化、缺失值填充现在都有sklearn都有对应的函数,但是直接调用Transform还是目前了解到的最方便的分组处理方法。)
语法参数介绍
df.transform(func, axis=0, *args, **kwargs)
其中,
- 参数func是一个函数,它定义了对数据进行的操作,可以是一个内置函数或用户自定义函数;
- 参数axis指定了操作的方向,可以是0表示对列进行操作,1表示对行进行操作,默认值为0。
- 另外,还可以使用可选参数*args和****kwargs**传递给func函数。
常用的内置函数介绍:
| 函数名称 | 解释 |
|---|---|
| sum() | 对数据进行求和操作。 |
| mean() | 对数据进行求平均值操作。 |
| median() | 对数据进行求中位数操作。 |
| min() | 对数据进行求最小值操作。 |
| max() | 对数据进行求最大值操作。 |
| count() | 对数据进行计数操作。 |
| cumsum() | 对数据进行累计求和操作。 |
| cumprod() | 对数据进行累计乘积操作。 |
| cummax() | 对数据进行累计最大值操作。 |
| cummin() | 对数据进行累计最小值操作。 |
| rank() | 对数据进行排名操作。 |
| diff() | 对数据进行差分操作。 |
| pct_change() | 对数据进行百分比变化操作。 |
使用代码案例
import pandas as pd import numpy as np # 创建一个数据框 df = pd.DataFrame({'group': ['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C'], 'data': [1, 2, 3, 4, 5, 6, 7, np.nan, 9]}) # 对数据框按照分组进行标准化 df['data_standardized'] = df.groupby('group')['data'].transform(lambda x: (x - np.mean(x)) / np.std(x)) # 对数据框按照分组,取该组最后一个值 df['data_last'] = df.groupby('group')['data'].transform('last') # 对数据框按照分组,对空值进行平均值填充 df['data_filled'] = df.groupby('group')['data'].transform(lambda x: x.fillna(x.mean())) # 打印输出结果 print(df)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
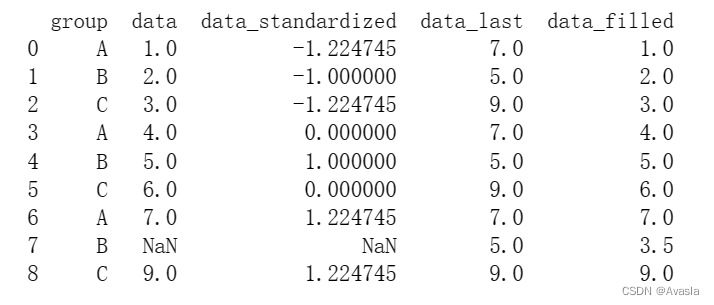
Labmda Vs 内置函数 该使用哪个更好?
#labmda
df['lam_sum_by_group'] = df.groupby('group')['data'].transform(lambda x: x.sum())
#直接调用内置函数
df['sum_by_group'] = df.groupby('group')['data'].transform('sum')
#结果查看
df
- 1
- 2
- 3
- 4
- 5
- 6
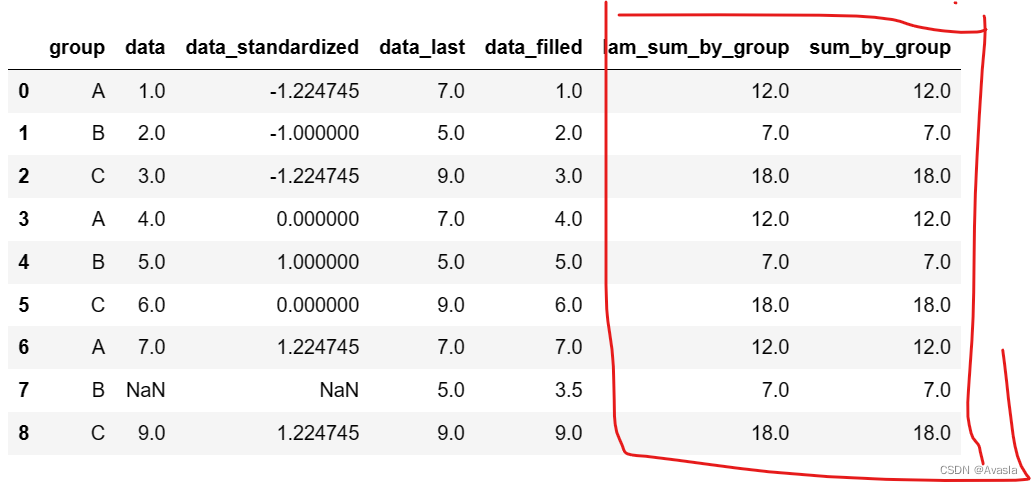
最后结果是一致的。 两种方法的作用是相同的,都是对"df"按照"group"进行分组,然后在每个组内计算"data"列的和。
两者的区别在于函数的传递方式。
使用lambda函数可以更加灵活的操作,包括使用任意的Python表达式和语句和自定义函数。而调用内置函数只能使用原本系统定义好的函数。但是,在性能上,使用内置函数要比使用lambda函数更加高效。具体使用哪种方式需要根据实际情况进行选择。
参考资料;
这个总结的也很全面:【Python】Pandas中的宝藏函数-transform()
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/351043
推荐阅读
相关标签

