
- 1智能写手ChatGPT:学术论文写作新视野
- 2论文ai写作生成器论文论文(ai写作网站免费)
- 3人工智能读书笔记-第三章_irrevocable search 算法
- 4HarmonyOS鸿蒙开发指南:自适应布局 网格布局_鸿蒙os 控件高度设置自适应
- 5【数据挖掘】数据清洗、数据集成、数据标准化的详解(超详细 附源码)_数据集成 实体识别
- 6【深度学习+面经】Transformer 网络学习笔记_transformer的head
- 7AI情绪检测器:准确检测并解读人类情绪_ai情绪识别
- 8Atomikos 事务超时时间设置_default-jta-timeout
- 9论文笔记:基于多粒度信息融合的社交媒体多模态假新闻检测
- 10BERT(cpu)代码复现_bert代码复现
大模型中的「罗翔老师」!北大兔展联合团队搞出ChatLaw,发布即登顶热榜,可提供法律咨询...
赞
踩
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
大模型中的“罗翔老师”,出现了!
北大团队打造的法律大模型ChatLaw,发布即冲上知乎热搜第一。

它具备大模型能力和充足法律知识,能给法律小白们答疑解惑、提供法律建议。
比如针对网络热议事件,它能给出应该参考的法条,并针对具体案例进行分析:

还可以生成专业的法律文书:

仿佛就像是在和真人律师对话。
如果它察觉到人类需要寻求人工服务时,还会推荐相应的法律援助中心。

同时ChatLaw也能成为专业律师们的小助手,帮他们处理繁琐的基础工作。

这就是北京大学深圳研究生院-兔展智能AIGC联合实验室(主任:北大田永鸿教授)带来的最新工作。
他们在通用大模型基础上,使用大量法律领域结构化文本数据进行训练,并找来资深律师辅助人工标注、进行高质量事实型多轮对话,最后炼成了ChatLaw。
与此同时还开源了3个模型:ChatLaw-13B、ChatLaw-33B和ChatLaw-TextVec。
效果到底如何?我们已经拿到内测资格实际体验了~
而且和主创团队问了问ChatLaw背后更多细节。
大模型中的“罗翔老师”
进入主页后,可以发现ChatLaw提供对话、写作、知识库三种模式。

以对话模式为例,又可分为普通类和专业类。对话模型包括快速、均衡和详细三种,可以按照自己的需要来做选择。

然后就可以用最普通的大白话,来向ChatLaw描述自己的遭遇了。
和常见的通用大模型不同,ChatLaw不是一上来就回答问题,而是会先引导你补充更多详细信息。
这也符合一般法律咨询的情况,当事人往往很难一次性提供全面的信息,很多表述都不明确。

在得到补充信息后,它就能做出相应的分析了。

当然ChatLaw还能处理更加复杂的情况,比如从文件中抽取关键信息做出分析。
在下面的场景中,当事人描述了自己突然被公司强制解雇的情况,ChatLaw简单分析后认为,这可能存在劳务纠纷,为了能更准确提供建议,它需要当事人提供劳动合同以及解雇通知等。
可以看到ChatLaw是支持上传文件的。

在拿到对应后,它将信息总结成了一个清晰的树状图,并将事实用法律语言进行描述,和当事人确认情况。

而且ChatLaw也能处理多模态信息,比如读取录音文件。

更进一步还可以生成法律文书。

而且不光是给普通人提供法律咨询服务,ChatLaw还能充当专业律师的助手。
比如可以基于上下文批量生成文书。


所以,ChatLaw是如何实现如上效果的?
先验知识约束+模型调度
在构成上,ChatLaw是由1个调度模型和3个子模型组成。
这使得它能更加专业地解决具体问题。
主要创新性工作有两方面:
先验知识约束
模型调度
这两方面工作可以有效降低模型幻觉,并让它能更加灵活智能地解决问题。
先来看先验知识约束方面。
研究团队认为,对于一个垂直领域大模型而言,需要既专业又准确。
尤其是法律这种严肃的行业,一定要尽可能降低模型回答的错误率。
但对于通用大模型来说,训练数据集中往往没有包含非常充足的专业法律知识。比如ChatGPT显然是没有拿国内法条训练过的,乱回答的现象非常严重。

这也就是常说的“模型幻觉”问题。
想要避免就需要进行大量的专业知识训练,即先验知识约束。
在这方面,研究团队使用大量判例文书、法律法规和司法解释,建立了一个大规模知识库。
同时和北大国际法学院、行业知名律师事务所合作,确保数据专业性。
然后在训练阶段将这些法律数据注入大模型中,专门建立一个微调子模型,可以进行关键词检索,来改善单纯依赖矢量数据库检索时不准确的问题。
同时在推理阶段也引入多个模块,将通识模型、专业模型和知识库融为一体,在推理中进行约束,以保证ChatLaw生成正确的法律建议,尽可能减少模型幻觉。
具体模型架构如下:

目前这一方法也同步在arXiv上发表。

据了解,团队还特地整理了过去十年的法考考试题,建立了一个包含2000个问题的司法考试测试集。
通过ELO机制进行检验,ChatLaw模型在测试集上成功击败GPT4,获得最高分。
同时也论证了在专业领域,百亿参数量的模型可以保持卓越的准确性。

而在实际应用场景中,仅仅有强大的专业能力还不够,还需要能够灵活应对各种提问。
在这方面,ChatLaw提出了一个“调度模型”的概念。
研究团队使用针对性微调训练了一个专用调度模型,它能够对问题进行分析,然后对子模型和插件进行调度重组,最终呈现出多个模态的输入和输出。
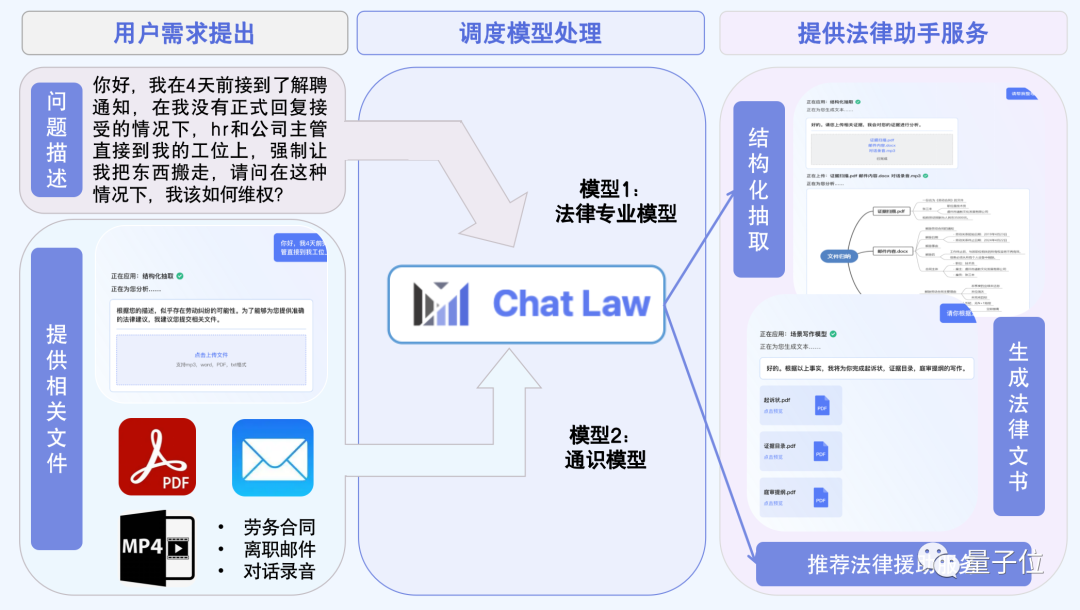
这样一来,ChatLaw就能将文件、音频、文字整合在一起分析,同时支持法律文书、思维导图等输出,还能推荐专业的法律援助。
值得一提的是,除了发布ChatLaw,团队还一并开源了三个模型。
ChatLaw-13B,此版本为学术demo版,基于姜子牙Ziya-LLaMA-13B-v1训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。
ChatLaw-33B,此版本为学术demo版,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。
ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,例如:
“请问如果借款没还怎么办?”
“合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;贷款人可以催告借款人在合理期限内返还。”
两段文本的相似度计算为0.9960.
在官方展示的测试中,ChatLaw还可以具备联网能力,效果可以更好。
不过由于目前服务器资源不足,暂时关闭了法条检索模块。

以及在用户隐私保护方面,ChatLaw会对上传的文件数据进行脱敏处理。
和ChatExcel团队师出同门
不过为啥研究团队想要做一个法律领域的专业大模型呢?
这就还得从一家跑路的雅思机构说起了……
主创团队小哥表示,2018年他报名的雅思课,才开课一星期机构就卷钱跑路了。他想要通过法律途径维权,结果发现这还真不是一件容易的事:
请一个律师至少要3000块,包括法律咨询、写诉讼状等……成本太高了。
但普通人自己来搞定这些,又确实很难。比如需要使用“法言法语”描述问题等……
结合今年的趋势他就想到,能不能让大模型来给普通人提供法律咨询服务。
毕竟大数据也显示,2022年,全国法院共受理案件3372.3万件,其中由律师办理诉讼案件仅有824.4万件。74%的案件没有律师参与,当事人只能自己写材料、诉讼、协商。
而且主创团队还从专业法律人士方面了解到,律师们也很希望有一个AI工具能够帮自己提升工作效率,辅助完成一些基本工作。
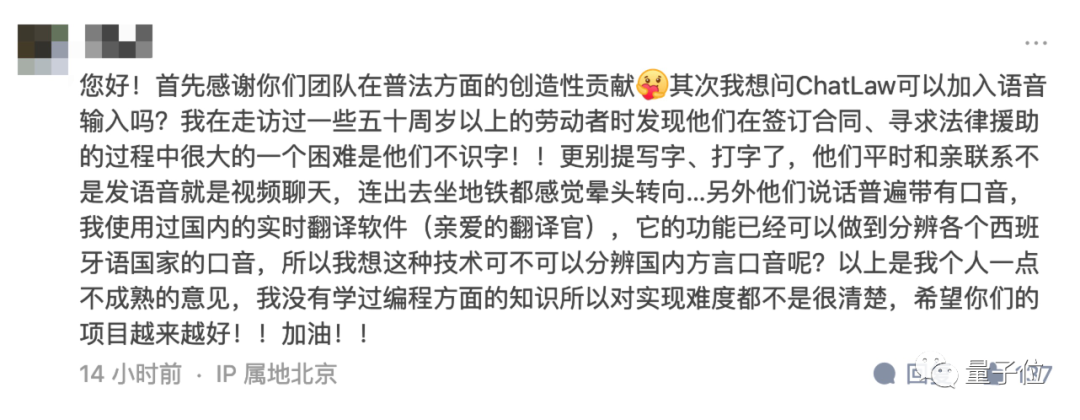
(工作发表后马上有专业人士留言希望AI能提供更强大的功能)
ChatLaw的幕后团队是北京大学深圳研究生学院-兔展智能AIGC联合实验室。
值得一提的是,他们和之前爆火过的ChatExcel团队师出同门。
都是来自北京大学信息工程学院袁粒老师课题组。
袁粒是北京大学信息工程学院助理教授、博士生导师。
团队主创成员有三位,分别是课题组内的准博士生伯华、家熙,以及研究生晏阳。
此外他们也联合了北京大学国际法学院、阿尔法律师事务所提供法律专业建议和指导。
对于法律领域大模型,团队表示他们认为这在国内有着巨大的发展空间。
只有中国,拥有如此巨大规模的人口,统一的法律服务市场,规范的法律判例。
因此,我们坚定的向这个项目投入算力、资源、人力。也许我们的产品现在还有诸多未完善的地方,但技术的发展是非线性的。也许在未来某个时间点,我们能够超越GPT,为这片土地的普通人带来普惠的法律服务。
据了解,目前ChatLaw已经有一些落地合作,而法律领域还只是北大-兔展智能AIGC实验室的第一步。
未来两个月内,他们预计会陆续推出政务、金融等领域的大模型。
并且已经有了商业计划,“想做中国版Cohere”。专注于企业服务。基于法律、政务、金融3个领域,不断完善行业级大模型。
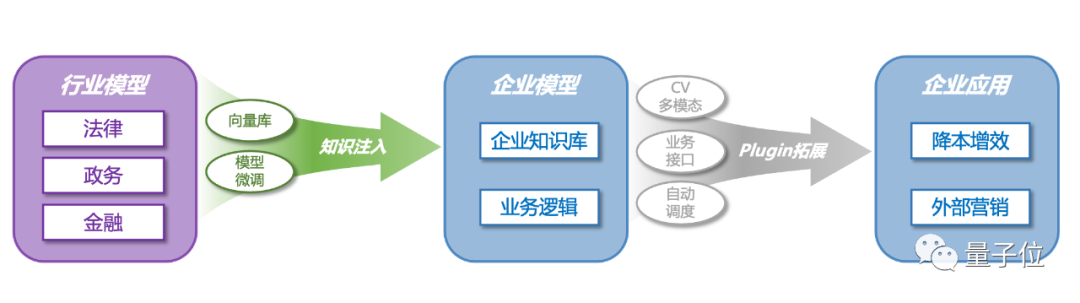
但同时这些能力也会继续向普通人开放。
感兴趣的童鞋,可戳下方体验链接申请内测~
官方地址:https://www.chatlaw.cloud/?
GitHub地址:
https://github.com/PKU-YuanGroup/ChatLaw
论文地址:
https://arxiv.org/abs/2306.16092
— 完 —
「AIGC+垂直领域社群」
招募中!
欢迎关注AIGC的伙伴们加入AIGC+垂直领域社群,一起学习、探索、创新AIGC!
请备注您想加入的垂直领域「教育」或「电商零售」,加入AIGC人才社群请备注「人才」&「姓名-公司-职位」。

点这里声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/365343
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

