
- 1Hadoop学习笔记_hadoop可以运行深度学习吗
- 2轻量化网络:SqueezeNet_fire module
- 3Per-FedAvg:联邦个性化元学习
- 4一、Docker部署GitLab(详细步骤)
- 5如何用DockerFile部署项目
- 6大模型训练推理如何选择GPU?一篇文章带你走出困惑(附模型大小GPU推荐图)
- 7NLP(一)——文本处理
- 8RabbitMQ消费消息的两种模式:推和拉_rabbitmq是推还是拉
- 9用于文本的TensorFlow:使用Attention TensorFlow的神经机器翻译_python tensorflow文本理解
- 10Mui+H5plus+Vue移动混合App—IOS打包上传篇02—解决被拒:Guideline 2.3.1 - Performance_we discovered that your app contains hidden featur
Python爬取某二手房官网某地区二手房的数据【附加源码】
赞
踩
一、前言
Python爬取二手房数据并保存到Excel表中是一个常见的数据爬取与处理任务。您可以使用Python中的库如Requests、BeautifulSoup来爬取网页数据,再使用Pandas库将数据保存到Excel表中。
爬虫(Web crawler)是一种自动化程序,用于在互联网上按照一定规则抓取信息。它会自动访问网页、提取数据并进行处理,通常用于搜索引擎、数据采集、监控等方面。
爬虫的基本工作流程通常包括以下几个步骤:
-
发起请求:向指定的网页发送HTTP请求。
-
获取响应:接收网页服务器返回的HTTP响应,其中包含网页内容。
-
解析内容:对网页内容进行解析,提取所需的信息,通常使用HTML解析库如BeautifulSoup。
-
孯理数据:对提取的数据进行处理、清洗、存储等操作。
-
循环迭代:根据设定的规则,继续访问其他链接,重复上述步骤。
二、安装对应的库
在Pycharm中下载好相应的库:requests、bs4、BeautifulSoup、pandas等。具体下载方式有三种,这里我只是列出常见的一种,如下效果图:
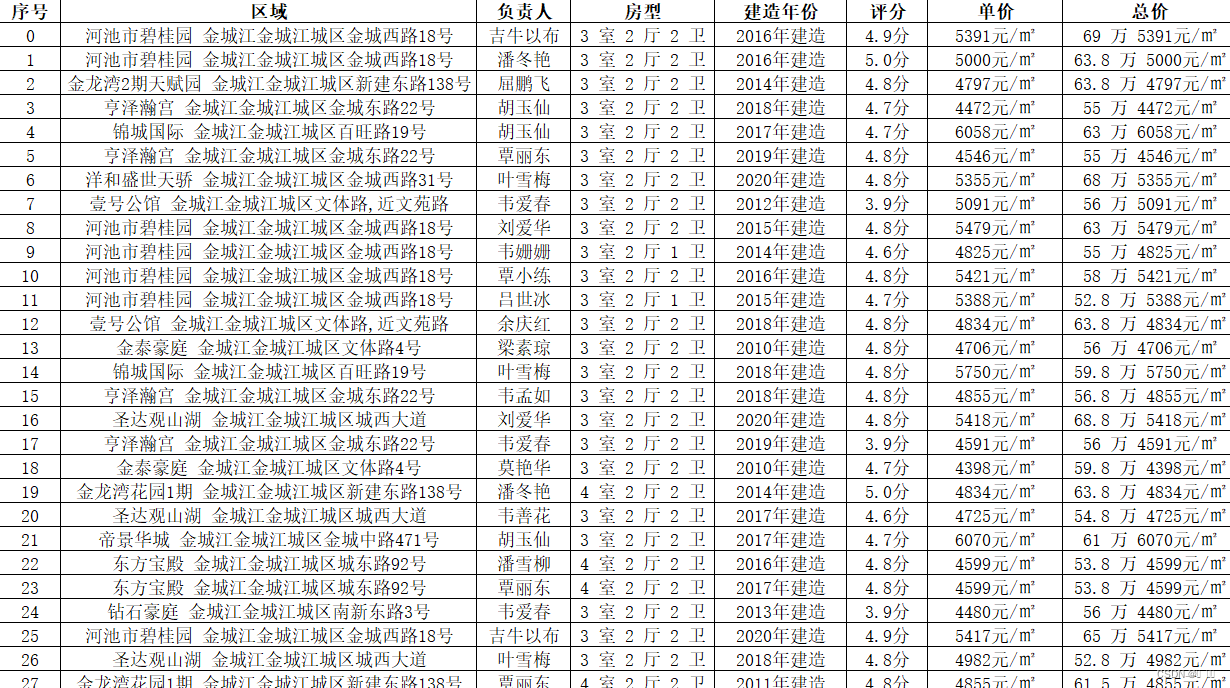
三、具体数据爬取效果图
以安居客二手房官网为实现对象,爬取某地区二手房的详细情况,这里我爬取金城江(地名)二手房为列效果图如下(仅供参考):
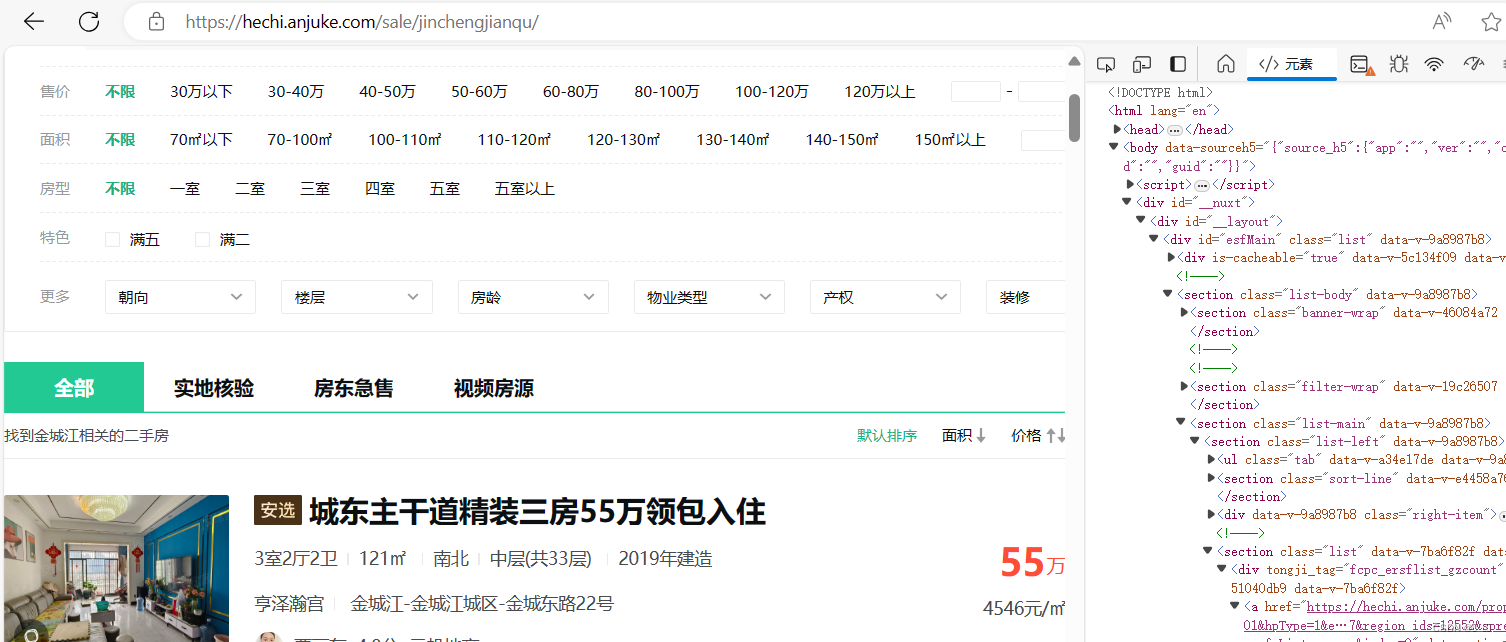
四、实现爬取过程相关数据的代码的截取
首先根据个人的需求来进行相关信息指定的相关官网对象数据的爬取,进入到相对应的官网,这里我进入的官网是安居客二手房:https://hechi.anjuke.com/,选择地址是金城江,所以在爬取的代码的URL为该地址指定的链接:https://hechi.anjuke.com/sale/jinchengjianqu/。相关代码如下:
url = f"https://hechi.anjuke.com/sale/jinchengjianqu{page_number}/"打开该地址官网后在该网页点击鼠标“右键”在弹出的窗口中找到“检查”并点击,会弹出如下图效果:
1.以爬取金城江一些区域数据为列,对象是“区域”。任意选择一家二手房具体步骤如下图标记的序号进行操作。

代码:
- row['区域'] = house_info.find("div", {"class": "property-content-info property-content-info-comm"}).get_text() \
- if house_info.find("div", {"class": "property-content-info property-content-info-comm"}) else None
***注意代码公式***:
row['区域'] = house_info.find("(这里是标签)如上图第三步的div", {"class": "这里是第三步上图class后划红线的部分"}).get_text() if house_info.find("(这里是标签)如上图第三步的div", {"class": "这里是第三步上图class后划红线的部分"}) else None
*********
2.若发现多个并列标签,只想提取其中的一个。这里我以金城江一些二手房的“建造年份”作为爬取对象,如下图效果:

像这种情况我们使用第一点的源码行不通,它只能爬取到①的数据,这时想爬取后面并列的②~⑤中的一种,我们可以使用以下的源码(这里我以金城江一些二手房的“建造年份”作为爬取对象):
- p_tags = house_info.find_all("p", {"class": "property-content-info-text"})
- if len(p_tags) >= 1:
- row['建造年份'] = p_tags[4].get_text()
- else:
- row['建造年份'] = None
***注意***:
p_tags = house_info.find_all("(这里是标签)如上图第三步的p", {"class": "这里是第三步上图class后划红线的部分"})
if len(p_tags) >= 1:
①:
row['房型'] = p_tags[0].get_text()
else:
row['房型'] = None
②:
row['大小'] = p_tags[1].get_text()
else:
row['大小'] = None
③:
row['方位'] = p_tags[2].get_text()
else:
row['方位'] = None
④:
row['楼层数'] = p_tags[3].get_text()
else:
row['楼层数'] = None
⑤:
row['建造年份'] = p_tags[4].get_text()
else:
row['建造年份'] = None
************
五、保存数据到Excel
具体源码如下:
- def main():
- all_data = []
-
- for i in range(1, 11): # 爬取前10页数据作为示例
-
- print(f"正在爬取第{i}页...")
-
- all_data += fetch_data(i)
-
- df = pd.DataFrame(all_data)
-
- df.to_excel('金城江二手房详细信息.xlsx', index=False)
-
- print("数据已保存到 '金城江二手房详细信息.xlsx'")
六、完整的源码
以安居客二手房官网为实现对象,爬取某地区二手房的详细情况,这里我爬取金城江(地名)二手房为列具体完整的代码如下:
- import requests
-
- from bs4 import BeautifulSoup
-
- import pandas as pd
-
- def fetch_data(page_number, counter=0):
- url = f"https://hechi.anjuke.com/sale/jinchengjianqu{page_number}/"
-
- response = requests.get(url)
-
- if response.status_code != 200:
- print("请求失败")
-
- return []
-
- soup = BeautifulSoup(response.text, 'html.parser')
-
- rows = []
-
- for house_info in soup.find_all("div", {"class": "property"}):
- row = {}
-
- row['序号'] = counter
- counter += 1
-
- row['区域'] = house_info.find("div", {"class": "property-content-info property-content-info-comm"}).get_text() \
- if house_info.find("div", {"class": "property-content-info property-content-info-comm"}) else None
-
- sp_tags = house_info.find_all("span", {"class": "property-extra-text"})
- if len(sp_tags) >= 1:
- row['负责人'] = sp_tags[0].get_text()
- else:
- row['负责人'] = None
-
- row['房型'] = house_info.find("p", {"class": "property-content-info-text property-content-info-attribute"}).get_text() \
- if house_info.find("p", {"class": "property-content-info-text property-content-info-attribute"}) else None
-
- p_tags = house_info.find_all("p", {"class": "property-content-info-text"})
- if len(p_tags) >= 1:
- row['建造年份'] = p_tags[4].get_text()
- else:
- row['建造年份'] = None
-
- sp_tags = house_info.find_all("span", {"class": "property-extra-text"})
- if len(sp_tags) >= 1:
- row['评分'] = sp_tags[1].get_text()
- else:
- row['评分'] = None
-
- row['单价'] = house_info.find("p", {"class": "property-price-average"}).get_text() if house_info.find("p", {
- "class": "property-price-average"}) else None
-
- row['总价'] = house_info.find("div", {"class": "property-price"}).get_text() if house_info.find("div", {
- "class": "property-price"}) else None
-
- rows.append(row)
-
- return rows
-
-
- # 主函数
-
- def main():
- all_data = []
-
- for i in range(1, 11): # 爬取前10页数据作为示例
-
- print(f"正在爬取第{i}页...")
-
- all_data += fetch_data(i)
-
- df = pd.DataFrame(all_data)
-
- df.to_excel('金城江二手房详细信息.xlsx', index=False)
-
- print("数据已保存到 '金城江二手房详细信息.xlsx'")
-
- if __name__ == "__main__":
- main()



