
- 1OpenAI的组织形态、决策机制与产品构建
- 2人工智能基础知识:计算机视觉、自然语言处理、机器学习、强化学习等技术简介_计算机视觉、自然语言处理、其他
- 3sentence_transformers 教程_sentence transformer loss
- 4从0开始的深度学习——搭建一个卷积神经网络_卷积神经网络搭建
- 5让人费解的动态规划——最低票价_动态规划算法最低票价
- 6终极方案——解决MacBook/Mac mini连接无线鼠标卡顿、漂移_macmini鼠标不流畅
- 7AI工程化:各家的AI平台、AI中台架构图_人工智能算法 开源中台
- 8JVM调优参数简介、调优目标及调优经验
- 9自然语言处理的注意力机制:从Transformer到BERT和GPT
- 10微软的 SwiftKey 键盘为 iOS 和 Android 带来更多人工智能注入的超能力
Per-FedAvg:联邦个性化元学习
赞
踩
关注公众号,发现CV技术之美

Personalized Federated Learning with Theoretical Guarantees: A Model-Agnostic Meta-Learning Approach
论文链接:https://proceedings.neurips.cc/paper/2020/file/24389bfe4fe2eba8bf9aa9203a44cdad-Paper.pdf
▊ 介绍与引言
传统联邦学习弊端:只为所有用户开发一个公共模型,因此,它不会将模型适应于每个用户,这是一个重要的缺失特性,特别是当考虑到不同用户的底层数据分布的异质性。
在本文中,作者研究了联邦学习的个性化变体,其中我们的目标是找到一个初始共享模型,基于初始模型,当前或新用户通过对自己的数据执行一步或几步梯度下降,可以很容易地适应他们的本地数据集。这种方法保留了联邦学习体系结构的所有好处,并通过结构为每个用户提供了更个性化的模型。
传统联邦学习设置如下图1所示,传统的联邦学习设置是由中央服务器汇聚所有客户端模型的参数进行平均聚合获取全局模型。但是,该方案为所有用户开发了一个全局的公共模型,因此它并不适合每个用户,因为每个用户拥有其自身的特性(异构性)。

图1:传统FL设置
作者通过考虑一个包含个性化的联邦学习模型的修正损失函数来克服这个问题,作者基于元学习MAML的思想出发去做联邦学习个性化,主要是以下两点:
1)目标是找到所有用户之间共享的初始点,在每个用户更新自己的损失函数后表现良好,可能是通过执行基于梯度的方法的一些步骤。
2)虽然初始模型是以所有用户的分布式方式派生的,但是每个用户基于自身数据实现的最终模型不同于其他模型。
作者研究了FedAvg算法的一个个性化变体,称为Per-FedAvg,旨在解决所提出的个性化FL问题。特别地,我们描述了不同用户的数据异质性和数据分布的紧密性,通过分布距离测量,如Total Variation或1-Wasserstein,对Per-FedAvg收敛的作用。
▊ 相关工作
在这项工作中,作者更关注MAML方法对FL设置的收敛,这更具有挑战性,因为节点在发送更新到服务器之前执行多个本地更新,这在以前的元学习理论工作中没有考虑到。
然而,我们的主要重点是关于这个公式的理论评估,其中我们描述了Per-FedAvg的收敛性,以及该算法的参数对其性能的作用。
使用元学习和多任务学习来实现个性化并不限于MAML框架,还考虑了一个训练单个全局模型和局部模型的框架,为每个用户提供个性化的解决方案;以及另一论文作者提出了一种自适应联邦学习算法,该算法学习局部和全局模型的混合作为个性化模型。
▊ 通过模型不可知论的元学习进行个性化联邦学习
如果我们假设每个用户都接受初始点,并使用关于它自己的损失函数的一个梯度下降的步骤来更新它:
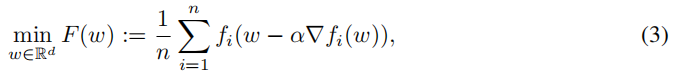
这个公式的优点是,它不仅允许我们保持FL的优势,而且它捕获用户之间的区别。
作者提出了个性化的FedAvg(Per-FedAvg)方法来解决问题(3),即如何来寻找问题(3)的最优解。针对(3)中每个Fw可知:
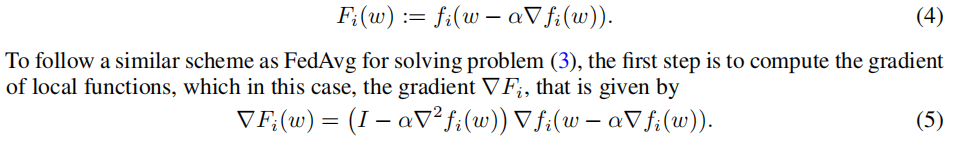
那么我们针对每个Fw进行求导,由于fw求导耗时,所以考虑无偏估计替代:

类似MAML进行模型初始化,然后根据自身数据再训练一次或若干次,如下图公式所示,这样我们就可以得到个性化的客户端模型:
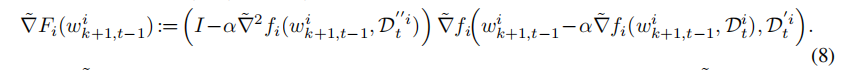
总结一下:作者通过使用无偏估计代替原始参数求导,大大减轻模型开销,同时作者借鉴MAML思想,将服务器发送给客户端的模型进行初始化,然后客户端根据自身私有数据再进行若干次训练,从而达到联邦个性化元学习的效果。个人感觉有点类似于:模型初始参数迁移 + 微调。
▊ 理论结果
作者关注非凸设置,并描述了服务器和用户之间的整体通信回合,以找到一个近似的一阶平稳点。
关于Per-FedAvg算法描述如下图2所示:

图2:Per-FedAvg伪代码
作者考虑两种手段代替2阶偏导(FO and HF):
1 )FO( First-Order MAML):直接考虑使用一阶偏导代替二阶导;
2 )HF( Hessian-vector MAML):考虑使用一阶偏导的差(二阶导的定义)代替二阶偏导。
接下来作者通过实验进行论证:
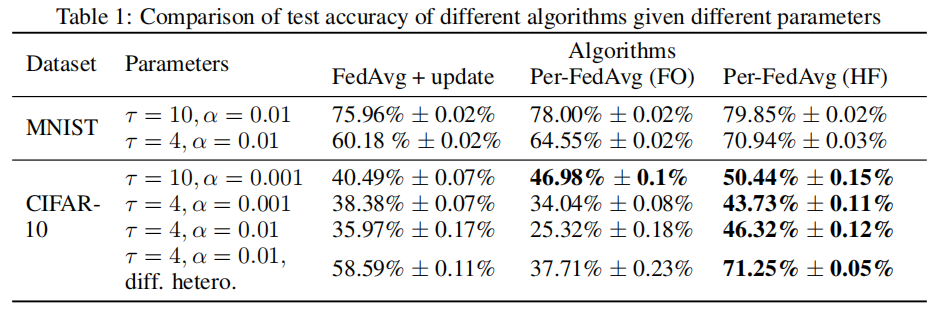
通过实验我们可以得知,使用Hessian-vector黑森矩阵来代替二阶偏导的效果优于直接考虑使用一阶偏导代替二阶导,说明作者方法的有效性。
▊ 总结
作者考虑联邦学习(FL)问题在异构情况下,并研究个性化的经典的FL公式,其目标是找到一个适当的初始化模型,可以快速适应本地数据后的每个用户的训练阶段。
作者提供了一组数值实验,说明了两种不同的一阶近似的性能(FO and HF)及其与FedAvg方法的比较,可以知道综合来看Per-FedAvg(HF)优于FedAvg。同时也间接证明了作者所提模型不可知论的元学习进行个性化联邦学习方法的有效性。核心就是作者通过MAML的启发来作为模型初始化参数再利用微调适应本地私有数据,从而提升模型性能与效率。
参考链接
Fallah, Alireza, Aryan Mokhtari, and Asuman Ozdaglar. "Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach." Advances in Neural Information Processing Systems 33 (2020): 3557-3568.

END
欢迎加入「元学习」交流群
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

