
- 1如何面对“00后整顿职场”
- 2大数据分析与内存计算——Spark安装以及Hadoop操作——注意事项
- 310款生成PPT的AI工具实测_pptai生成
- 4Springboot + vue 实现文件上传_springboot vue文件上传
- 5Android架构探究之MVC设计模式_android mvc
- 6深度学习pytorch好用网站分享
- 7NTFS磁盘格式读写工具Tuxera NTFS for Mac 2023中文版新功能介绍_microsoft ntfs for mac by tuxera
- 8msf添加路由及socks代理进行内网穿透_msf内网代理
- 9『Nginx安全访问控制』利用Nginx实现账号密码认证登录的最佳实践_何通过前端传递传递nginx验证的账号和密码
- 10【面试HOT200】滑动窗口篇
大数据Hadoop(一):集群搭建--Hadoop3.3.1、CentOS8、HDFS集群、YARN集群最新保姆级教程
赞
踩
前言:本教程仅演示快速搭建Hdoop集群,并不对相关知识点与背景进行详细说明,电脑建议16G及以上内存,需要同时开启3台虚拟机,8G内存有点不够使用。
所需工具(提取码:0620 ):VMware Workstation 16、Centos stream 8、Xshell、nodepad++(尽管运营者很恶心)、jdk8、hadoop3.3.1。
一、安装CentOS8虚拟机
- 安装好VMware Workstation 16 后运行并新建虚拟机。
- 选择典型,下一步。
- 选择“安装程序光盘镜像文件”,选择CentOS8镜像文件(iso)所在路径,下一步。
- 设置虚拟机名称为node1,自己设置安装路径,下一步。
- 最大磁盘大小60G,选择虚拟磁盘拆分成多个文件,下一步。
- 自定义硬件,内存设置2G,点击完成。
- 选择第一个,Enter键确认,此时我们在虚拟机内,鼠标无法使用,ctrl+alt返回你的计算机。


- 设置root密码123456,可以理解为管理员密码,点击2次完成。点击安装目的地,直接点击完成。


- 开始安装,过程有点漫长。接受许可信息,安装完成后设置自己的用户名和密码。

二、克隆虚拟机
- 关闭虚拟机,鼠标移动到node1标签,右键>管理>克隆

- 选择“克隆虚拟机的当前状态”,“创建完整克隆”。克隆两台,分别命名node2、node3。



- 现在已有三台虚拟机

三、修改VMnet8的ip
- 确认好vmnet8生成的网关地址。在VMware Workstation顶部菜单栏点击编辑>虚拟网络编辑器>VMnet8>NAT设置。获取网关ip:192.168.179.2,每个人都不同,记住自己的。点击DHCP设置,获取起始ip与结束ip。


2. 在windows任务栏搜索“网络连接”并打开,选择VMnet8,右击>属性>双击Internet协议版本4(tcp/ipv4),IP和DNS都改为手动,默认网关就填上面显示的网关,ip地址前三段与默认网关保持一致,后一段设置为1。DNS填写如图(为了方便)



四、修改虚拟机ip(三台机器都做)
IP规划,IP前三段与你自己的网关前三段相同,最后一段分别为10、20、30,后面所有的IP操作都要根据你自己的实际情况设置。
| 主机名 | IP |
|---|---|
| node1 | 192.168.179.10 |
| node2 | 192.168.179.20 |
| node3 | 192.168.179.30 |
方式一:命令修改(不太建议)
-
以虚拟机
node1为例,启动虚拟机,点击左上角活动,然后选择终端,在终端输以下命令,获取mac地址,按右键可以在终端粘贴命令。ifconfig- 1

-
输入下列命令,并输入密码,ens160是网卡名称,有的是ens33有的是eth0
sudo vim /etc/sysconfig/network-scripts/ifcfg-ens160- 1
-
按
i键进入编辑模式,修改或增加以下内容。此时只能用方向键移动光标。修改 BOOTPROTO=none ONBOOT=yes 增加 HWADDR=你的mac地址 IPADDR=你想设置的IP地址 PREFIX=24 GATEWAY=你的网关 DNS1=114.114.114.114 DNS2=8.8.8.8- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
如图所示

-
修改完毕后先按Esc键,再按英文冒号,输入
wq!(英文叹号),强制写入并保存,然后输入reboot重启。 -
对另外两台虚拟机进行相同操作。
测试是否设置成功:
- 输入
ifconfig查看IP是否和自己设置的一样。

- 查看火狐浏览器是否能正常上网或终端输入
sudo ping www.baidu.com,ctrl+c停止ping,丢包率为0%.


方式二:图形化界面修改
- 点击活动,进入设置

- 找到网络,选择有线

- 点击身份,下拉菜单选择MAC地址

- 点击IPV4,选择手动,地址填:192.168.179.10,子网掩码:255.255.255.0,网关:192.168.179.2,DNS填
114.114.114.114,8.8.8.8。地址、网关根据你自己的进行设置,最后点击应用。

测试是否成功方法与上述相同
五、设置主机名 (三台机器都做)
-
主机名设置
- 以
node1为例,查看当前主机名,在终端输入hostname

- 终端输入
sudo vim /etc/hostname,按i键进行编辑,删除原内容,添加node1,按Esc键,再按英文冒号,输入wq!,最后按Enter键,重启生效。

- 输入
hostname检测

- 以
-
hosts映射
- 以
node1为例,终端输入命令sudo vim /etc/hosts

- 添加三台机器IP与主机名,保存退出,
重启虚拟机使配置生效。(参照下图)

- 输入
sudo ping node1、sudo ping node2、sudo ping node3均能pign通。CTRL+C结束。丢包率0%。

- 以
-
关闭防火墙
- 关闭防火墙
systemctl stop firewalld.service- 1
- 禁止防火墙开启自启
systemctl disable firewalld.service- 1
- 查看防火墙状态
systemctl status firewalld- 1

- 关闭防火墙
六、使用Xshell连接虚拟机
- 安装好Xshell过后,打开Xshell,选择新建会话。注意此时确保三台虚拟机都处于开启状态。

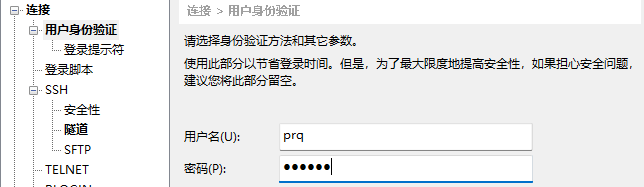
- 名称输入node1,主机输入node1或者192.168.179.10(你的第一台主机ip),点击用户身份验证,
用户名输入root(方便后面操作,学习用无所谓,真实场景慎用),密码123456,并点击连接。接受并保存主机密钥。


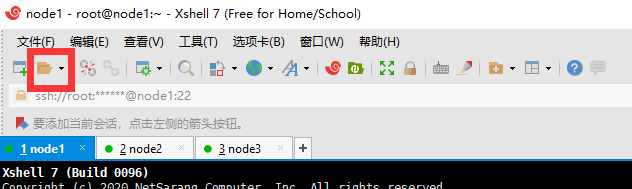
- 连接成功样图,
将三台虚拟机都连接上。

- 有时会出现找不到刚才配置的会话,点击这里就OK了,完成过后我们的VMware Workstation就可以最小化了,之后的操作都在Xshell上进行。
七、ssh免密登录(node1做即可)
- 以
node1为例,在Xshell的node1会话中输入ssh-keygen,敲击四个回车

- 在终端输入
ssh-copy-id node1确认,输入yes,第二次输入密码。接着输入ssh-copy-id node2,ssh-copy-id node3

- 在终端分别输入
ssh node1、ssh node2、ssh node3,能登录则成功。exit退出登录。

八、时间同步(三台机器都做)
- 以
node1为例,在node1会话里先后输入以下命令yum install chrony -y #安装chrony timedatectl set-timezone Asia/Shanghai #修改时区 vim /etc/chrony.conf #修改chrony.conf文件 pool ntp.aliyun.com iburst #注释第三行,在第四行添加,保存并退出- 1
- 2
- 3
- 4

- 重启chrony服务
systemctl restart chronyd- 1
- 时间同步
chronyc sources -v- 1

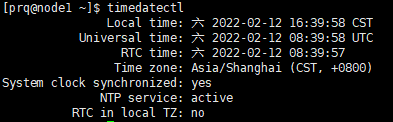
- 查看本机时间
timedatectl- 1
九、上传并解压安装包(node1做即可)
- 集群规划。
| 主机 | IP | 运行角色 |
|---|---|---|
| node1 | 192.168.179.10 | namenode、datanode、resourcemanager 、nodemanager |
| node2 | 192.168.179.20 | secondarynamenode、datanode、nodemanager |
| node3 | 192.168.179.30 | datanode、nodemanager |
- 在Xshell的node1会话里面先后输入以下命令,创建相应文件夹。
mkdir -p /export/server/ #软件安装路径 mkdir -p /export/software/ #安装包存放路径- 1
- 2
- 进入到
/export/software/目录下,将下载好的hadoop-3.3.1.tar.gz和jdk-8u321-linux-x64.tar.gz上传。输入ll查看是否上传成功,命令如下cd /export/software #进入该目录 yum -y install lrzsz #安装lrzsz rz -E #上传安装包 ll #查看当前文件夹所包含的文件夹及文件- 1
- 2
- 3
- 4

- 输入下列命令,对包进行解压。
tar zxvf jdk-8u321-linux-x64.tar.gz -C /export/server/ tar zxvf hadoop-3.3.1.tar.gz -C /export/server/- 1
- 2
- 输入下列命令,前往目录
/export/server/,查看是否解压成功cd /export/server ll- 1
- 2

十、安装JDK(node1做即可)
- 删除原装jdk,如果没有则跳过。
rpm -qa | grep java- 1
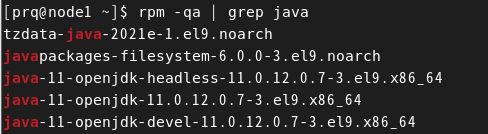
rpm -e tzdata-java-2021e-1.el9.noarch javapackages-filesystem-6.0.0-3.el9.noarch java-11-openjdk-headless-11.0.12.0.7-3.el9.x86_64 java-11-openjdk-11.0.12.0.7-3.el9.x86_64 java-11-openjdk-devel-11.0.12.0.7-3.el9.x86_64- 1
- 配置环境变量
vim /etc/profile 在最末尾添加 export JAVA_HOME=/export/server/jdk1.8.0_321 export PATH=:$JAVA_HOME/bin:$PATH- 1
- 2
- 3
- 4
- 5
- 6

- 更新profile,使配置生效
source /etc/profile- 1
- 验证。
java -version javac- 1
- 2

十一、编辑Hadoop配置文件(node1做即可)
-
Hadoop安装包目录结构

-
在node1中创建用于存放数据的data目录
mkdir -p /export/server/hadoop-3.3.1/data/namenode #NameNode数据 mkdir -p /export/server/hadoop-3.3.1/data/datanode #DataNode数据- 1
- 2
-
安装好notepad++后打开,在顶部菜单栏点击插件>插件管理>搜索NppFTP并安装,安装好后点击Show NppFTP window,选择小齿轮,点击第二个,添加新连接。连接成功后双击根目录。在里面前往此目录
/export/server/hadoop-3.3.1/etc/hadoop



-
修改hadoop-env.sh文件,在第55行添加下列代码并保存。
#配置JAVA_HOME export JAVA_HOME=/export/server/jdk1.8.0_321 #设置用户以执行对应角色shell命令 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

-
修改core-site.xml(配置NameNode),第19行及后面所有代码替换为下列代码并保存。
<configuration> <!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。--> <!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。--> <!-- hdfs文件系统访问地址:http://nn_host:8020。--> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 在Web UI访问HDFS使用的用户名。--> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

-
修改hdfs-site.xml文件(配置HDFS路径),第19行及后面所有代码替换为下列代码并保存。
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:9868</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/export/server/hadoop-3.3.1/data/namenode</value> <description>NameNode存储名称空间和事务日志的本地文件系统上的路径</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/export/server/hadoop-3.3.1/data/datanode</value> <description>DataNode存储名称空间和事务日志的本地文件系统上的路径</description> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

-
修改mapred-site.xml文件(配置MapReduce),第19行及后面所有代码替换为下列代码并保存。
<configuration> <!-- mr程序默认运行方式。yarn集群模式 local本地模式--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR App Master环境变量。--> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <!-- MR MapTask环境变量。--> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <!-- MR ReduceTask环境变量。--> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

-
修改yarn-site.xml文件(配置YARN),第15行及后面所有代码替换为下列代码并保存。
<configuration> <!-- yarn集群主角色RM运行机器。--> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 每个容器请求的最小内存资源(以MB为单位)。--> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <!-- 每个容器请求的最大内存资源(以MB为单位)。--> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <!-- 容器虚拟内存与物理内存之间的比率。--> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> </property> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

-
修改workers文件,删除第一行localhost,然后添加以下三行。
node1 node2 node3- 1
- 2
- 3

-
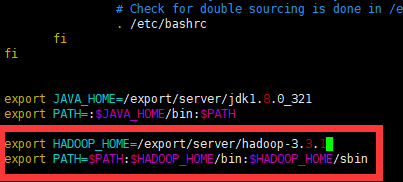
关闭notepad++,进入Xshell的node1会话,在node1上配置Hadoop环境变量。
vim /etc/profile 在末尾添加以下内容 export HADOOP_HOME=/export/server/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- 1
- 2
- 3
- 4
-
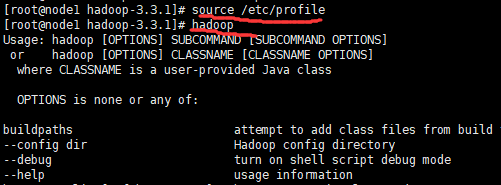
输入
source /etc/profile使配置生效,输入hadoop检验环境变量是否生效。
十二、分发配置
- 在
node1会话上面输入下列命令,将所有配置复制给node2和node3。scp -r /export node2:/ scp -r /export node3:/ scp -r /etc/profile node2:/etc/ scp -r /etc/profile node3:/etc/- 1
- 2
- 3
- 4
- 在node2和node3上分别执行
source /etc/profile,使配置生效。并输入hadoop检验环境变量是否生效。
十三、启动Hadoop集群
-
格式化HDFS,
首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。hdfs namenode -format itcast-hadoop- 1

-
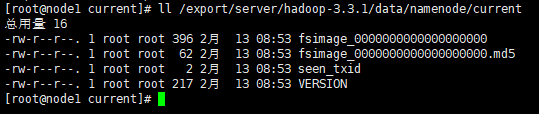
在
node1中输入命令ll /export/server/hadoop-3.3.1/data/namenode/current,查看是否格式化成功。
-
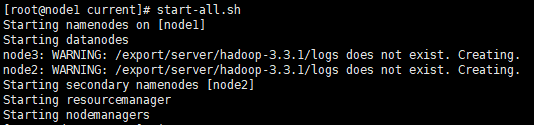
一键启动Hadoop集群
start-all.sh #启动 stop-all.sh #停止- 1
- 2
-
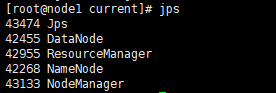
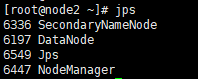
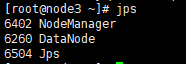
检测是否启动成功,在三个节点分别输入命令
jps。与下图相同则启动成功,进程分别是5个、4个、3个。
-
输入
ll /export/server/hadoop-3.3.1/logs/查看启动日志。

十四、访问Hadoop Web UI页面
- 在浏览器访问http://node1:9870,访问Hadoop Web UI页面-HDFS集群,点击顶部菜单栏的Datanodes,会看到三个节点均已启动。

- 在浏览器访问http://node1:8088,访问Hadoop Web UI页面-YARN集群


