
- 1可调时钟频率——IP核PLL/MMCM仿真及上板实验(Vivado)_vivado仿真测试时钟分频代码100hz
- 2大数据架构之关系型数据仓库——解读大数据架构(二)
- 3Debezium日常分享系列之:Debezium2.5稳定版本之MySQL连接器配置示例和Connector参数详解_debezium mysql
- 4启动Hadoop报错JAVA_HOME is not set and could not be found_hadoop java_home is not set and could not be found
- 5Cannot use @TaskAction annotation on method TransformTask.transform()_cannot use @taskaction annotation on method increm
- 6关于IDEA中Git版本回滚整理_git rollback changes idea
- 7JDK环境变量配置成功,命令提示符(CMD)中,输入java、javac、java -version等没有反应_命令行输入javac无内容
- 8Git撤销远程仓库的修改(push)_git撤销远程更改
- 9python pdb 调试 命令_pdb 退出循环
- 10拒绝纸张浪费,Paperless-ngx开源文档管理系统将纸质版转换成可搜索的电子版档案
C++中部署YOLOv5实例分割
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
目录
1.1 配置OpenVINO C++开发环境
1.2 下载并转换YOLOv5预训练模型
1.3 使用OpenVINO Runtime C++ API编写推理程序
1.3.1 采集图像&图像解码
1.3.2 YOLOv5-Seg模型的图像预处理
1.3.3 执行AI推理计算
1.3.4 推理结果进行后处理
1.4 总结
YOLOv5兼具速度和精度,工程化做的特别好,Git clone到本地即可在自己的数据集上实现目标检测任务的训练和推理,在产业界中应用广泛。开源社区对YOLOv5支持实例分割的呼声高涨,YOLOv5在v7.0中正式官宣支持实例分割。
本文主要介绍在C++中使用OpenVINO工具包部署YOLOv5-Seg模型,主要步骤有:
配置OpenVINO C++开发环境
下载并转换YOLOv5-Seg预训练模型
使用OpenVINO Runtime C++ API编写推理程序
下面,本文将依次详述
1.1 配置OpenVINO C++开发环境
配置OpenVINO C++开发环境的详细步骤,请参考《在Windows中基于Visual Studio配置OpenVINO C++开发环境》。
1.2 下载并转换YOLOv5预训练模型
下载并转换YOLOv5-seg预训练模型的详细步骤,请参考:https://mp.weixin.qq.com/s/K3wP5YLAU4p5jsdiMYjuMg,本文所使用的OpenVINO是2022.3 LTS版。
首先,运行命令获得 yolov5s-seg ONNX 格式模型:yolov5s-seg.onnx:
python export.py --weights yolov5s-seg.pt --include onnx然后运行命令获得yolov5s-seg IR格式模型:yolov5s-seg.xml和yolov5s-seg.bin,如下图所示
mo -m yolov5s-seg.onnx --compress_to_fp16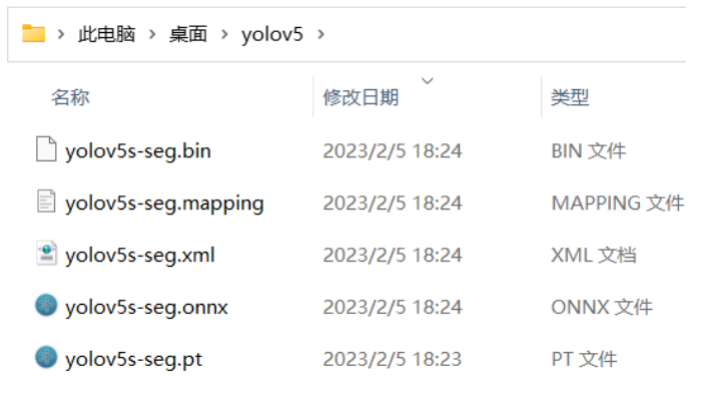
1.3 使用OpenVINO Runtime C++ API编写推理程序
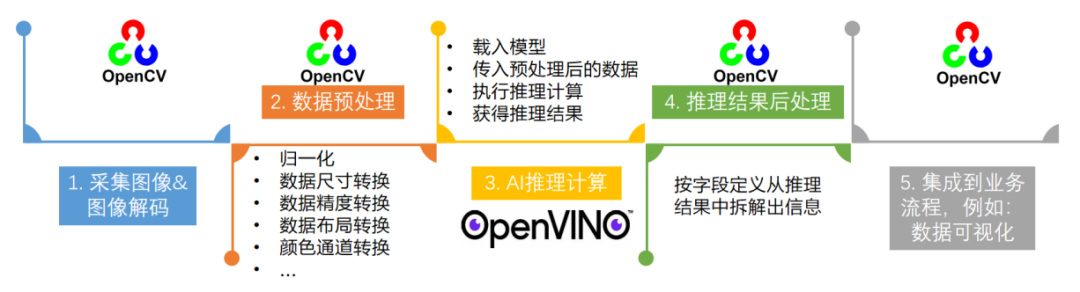
一个端到端的AI推理程序,主要包含五个典型的处理流程:
采集图像&图像解码
图像数据预处理
AI推理计算
对推理结果进行后处理
将处理后的结果集成到业务流程
1.3.1 采集图像&图像解码
OpenCV提供imread()函数将图像文件载入内存,
Mat cv::imread (const String &filename, int flags=IMREAD_COLOR)若是从视频流(例如,视频文件、网络摄像头、3D摄像头(Realsense)等)中,一帧一帧读取图像数据到内存,则使用cv::VideoCapture类,对应范例代码请参考OpenCV官方范例代码:https://github.com/opencv/opencv/tree/4.x/samples/cpp。
1.3.2 YOLOv5-Seg模型的图像预处理
YOLOv5-Seg模型构架是在YOLOv5模型构架基础上,增加了一个叫“Proto”的小型卷积神经网络,用于输出检测对象掩码(Mask),如下图所示:
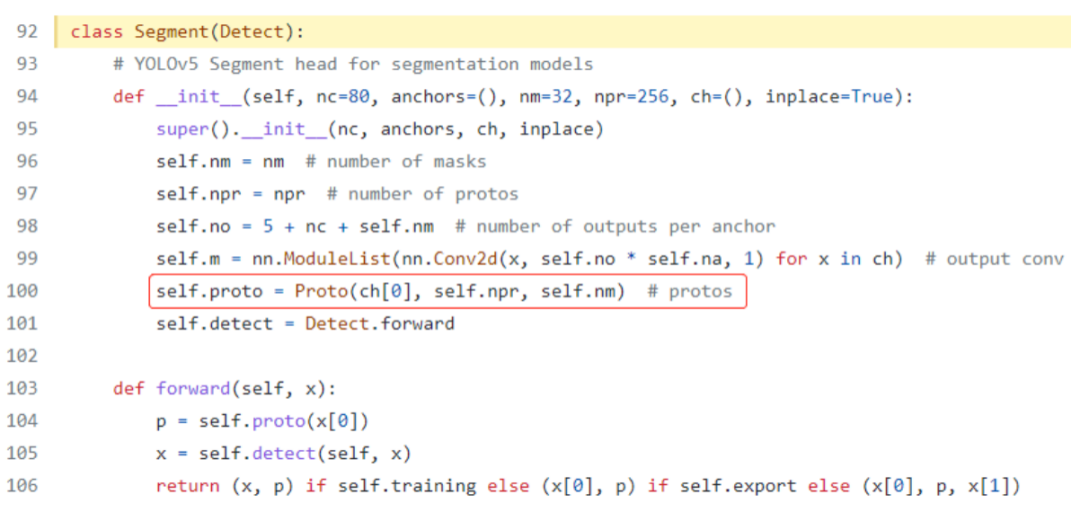
详细参看:https://github.com/ultralytics/yolov5/blob/master/models/yolo.py#L92
由此可知,YOLOv5-Seg模型对数据预处理的要求跟YOLOv5模型一模一样,YOLOv5-Seg模型的预处理代码可以复用YOLOv5模型的C++预处理代码。
另外,从代码可以看出YOLOv5-Seg模型的输出有两个张量,一个张量输出检测结果,一个张量输出proto,其形状可以用Netron打开yolov5-seg.onnx查知,如下图所示。
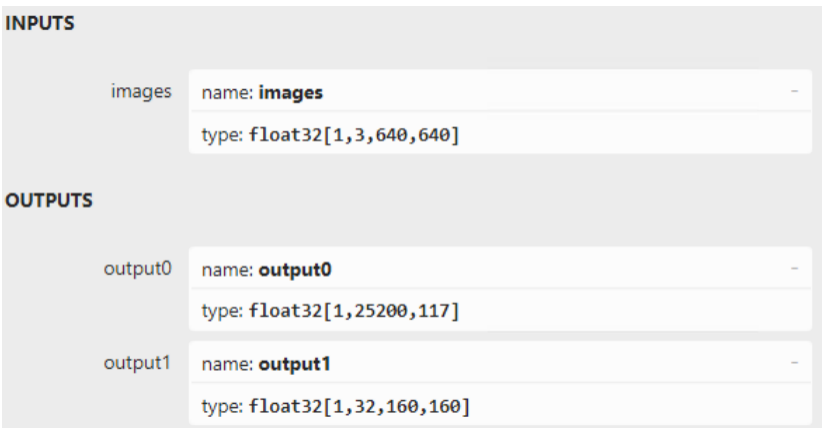
“output0”是检测输出,第一个维度表示batch size,第二个维度表示25200条输出,第三个维度表示有117个字段,其中前85个字段(0~84)表示:cx、cy、w、h、confidence和80个类别分数,后32个字段与”output1”做矩阵乘法,可以获得尺寸为160x160的检测目标的掩码(mask),如下图所示。

1.3.3 执行AI推理计算
基于OpenVINO Runtime C++ API实现AI推理计算主要有两种方式:一种是同步推理方式,一种是异步推理方式,本文主要介绍同步推理方式。
主要步骤有:
初始化Core类:ov::Core core;
编译模型:core.compile_model()
创建推理请求infer_request:compiled_model.create_infer_request()
读取图像数据并做预处理:letterbox()
将预处理后的blob数据传入模型输入节点:infer_request.set_input_tensor()
调用infer()方法执行推理计算:infer_request.infer()
获得推理结果:infer_request.get_output_tensor()
基于OpenVINO Runtime C++API的同步推理代码如下所示:
- // -------- Step 1. Initialize OpenVINO Runtime Core --------
- ov::Core core;
- // -------- Step 2. Compile the Model --------
- auto compiled_model = core.compile_model(model_file, "GPU.1"); //GPU.1 is dGPU A770
- // -------- Step 3. Create an Inference Request --------
- ov::InferRequest infer_request = compiled_model.create_infer_request();
- // -------- Step 4. Read a picture file and do the preprocess --------
- cv::Mat img = cv::imread(image_file); //Load a picture into memory
- std::vector<float> paddings(3); //scale, half_h, half_w
- cv::Mat resized_img = letterbox(img, paddings); //resize to (640,640) by letterbox
- // BGR->RGB, u8(0-255)->f32(0.0-1.0), HWC->NCHW
- cv::Mat blob = cv::dnn::blobFromImage(resized_img, 1 / 255.0, cv::Size(640, 640), cv::Scalar(0, 0, 0), true);
- // -------- Step 5. Feed the blob into the input node of YOLOv5 -------
- // Get input port for model with one input
- auto input_port = compiled_model.input();
- // Create tensor from external memory
- ov::Tensor input_tensor(input_port.get_element_type(), input_port.get_shape(), blob.ptr(0));
- // Set input tensor for model with one input
- infer_request.set_input_tensor(input_tensor);
- // -------- Step 6. Start inference --------
- infer_request.infer();
- // -------- Step 7. Get the inference result --------
- auto detect = infer_request.get_output_tensor(0);
- auto detect_shape = detect.get_shape();
- std::cout << "The shape of Detection tensor:"<< detect_shape << std::endl;
- auto proto = infer_request.get_output_tensor(1);
- auto proto_shape = proto.get_shape();
- std::cout << "The shape of Proto tensor:" << proto_shape << std::endl;

1.3.4 推理结果进行后处理
后处理工作主要是从”detect ”输出张量中拆解出检测框的位置和类别信息,并用cv::dnn::NMSBoxes()过滤掉多于的检测框;从”detect ”输出张量的后32个字段与”proto”输出张量做矩阵乘法,获得每个检测目标的形状为160x160的掩码输出,最后将160x160的掩码映射回原始图像完成所有后处理工作。
完整的代码实现,请下载:https://gitee.com/ppov-nuc/yolov5_infer/blob/main/yolov5seg_openvino_dGPU.cpp
1.4 总结
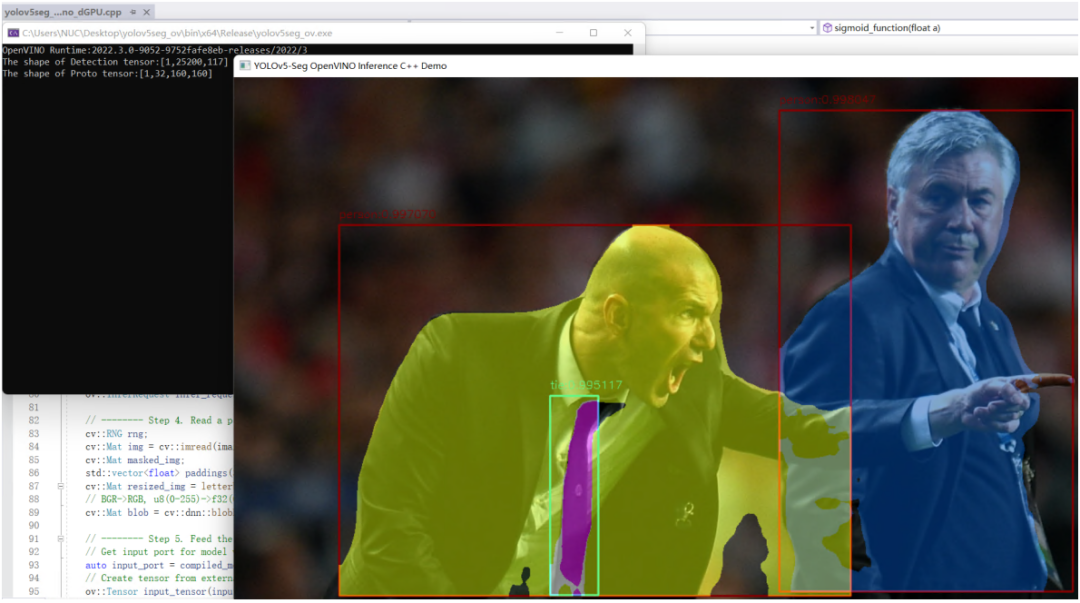
配置OpenVINO C++开发环境后,可以直接编译运行yolov5seg_openvino_dGPU.cpp,结果如下图所示。使用OpenVINO Runtime C++ API函数开发YOLOv5推理程序,简单方便,并可以任意部署在英特尔CPU、集成显卡和独立显卡上。
- 下载1:OpenCV-Contrib扩展模块中文版教程
-
- 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
-
-
- 下载2:Python视觉实战项目52讲
- 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
-
-
- 下载3:OpenCV实战项目20讲
- 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
-
-
- 交流群
-
- 欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

