
- 1前端可视化数据大屏(1)_dv-full-screen-container
- 22015年蓝桥杯省赛B组C/C++(试题+答案)_第十五届蓝桥杯软件赛省赛c/c++b 组题解
- 3ARINC818(FC-AV)协议详解
- 4ERROR [IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序
- 5uniapp微信小程序v-for循环绑定事件传值为undefined_uniapp for内绑定事件报错
- 6数据结构的终极boss:AVL树的详细讲解及代码实现
- 7linux普通用户命令权限,Linux(CentOS7)赋予普通用户执行root命令权限(sudo)
- 8Oracle数据库-03 PL/SQL编程、游标、存储过程_oracle 存储过程 动态sql 游标
- 9基于springboot实现在线考试系统项目【项目源码+论文说明】_springboot在线考试系统
- 10香蕉派 BPI-M2 Berry 四核开源单板计算机, 全志R40/allwinner V40芯片设计
R+python︱XGBoost极端梯度上升以及forecastxgb(预测)+xgboost(回归)双案例解读
赞
踩
目录
2、one-hot encode 独热编码——独有的数据结构
延伸一:来看看LightGBM和XGboosting的差异:
XGBoost不仅仅可以用来做分类还可以做时间序列方面的预测,而且已经有人做的很好,可以见最后的案例。
应用一:XGBoost用来做预测
一、XGBoost来历
xgboost的全称是eXtreme Gradient Boosting。正如其名,它是Gradient Boosting Machine的一个c++实现,作者为正在华盛顿大学研究机器学习的大牛陈天奇。他在研究中深感自己受制于现有库的计算速度和精度,因此在一年前开始着手搭建xgboost项目,并在去年夏天逐渐成型。xgboost最大的特点在于,它能够自动利用CPU的多线程进行并行,同时在算法上加以改进提高了精度。它的处女秀是Kaggle的希格斯子信号识别竞赛,因为出众的效率与较高的预测准确度在比赛论坛中引起了参赛选手的广泛关注,在1700多支队伍的激烈竞争中占有一席之地。随着它在Kaggle社区知名度的提高,最近也有队伍借助xgboost在比赛中夺得第一。
为了方便大家使用,陈天奇将xgboost封装成了python库。我有幸和他合作,制作了xgboost工具的R语言接口,并将其提交到了CRAN上。也有用户将其封装成了julia库。python和R接口的功能一直在不断更新,大家可以通过下文了解大致的功能,然后选择自己最熟悉的语言进行学习。
(非本博客主,详细可见参考文献)
————————————————————————————————————————————
二、优势、性价比
大致其有三个优点:高效、准确度、模型的交互性。
1、高效
xgboost借助OpenMP,能自动利用单机CPU的多核进行并行计算
Mac上的Clang对OpenMP的支持较差,所以默认情况下只能单核运行
xgboost自定义了一个数据矩阵类DMatrix,会在训练开始时进行一遍预处理,从而提高之后每次迭代的效率
它类似于梯度上升框架,但是更加高效。它兼具线性模型求解器和树学习算法。因此,它快速的秘诀在于算法在单机上也可以并行计算的能力。这使得xgboost至少比现有的梯度上升实现有至少10倍的提升。它提供多种目标函数,包括回归,分类和排序。
2、准确性
准确度提升的主要原因在于,xgboost的模型和传统的GBDT相比加入了对于模型复杂度的控制以及后期的剪枝处理,使得学习出来的模型更加不容易过拟合。
由于它在预测性能上的强大但是相对缓慢的实现,"xgboost" 成为很多比赛的理想选择。它还有做交叉验证和发现关键变量的额外功能。在优化模型时,这个算法还有非常多的参数需要调整。
3、模型的交互性
能够求出目标函数的梯度和Hessian矩阵,用户就可以自定义训练模型时的目标函数
允许用户在交叉验证时自定义误差衡量方法,例如回归中使用RMSE还是RMSLE,分类中使用AUC,分类错误率或是F1-score。甚至是在希格斯子比赛中的“奇葩”衡量标准AMS
交叉验证时可以返回模型在每一折作为预测集时的预测结果,方便构建ensemble模型。
允许用户先迭代1000次,查看此时模型的预测效果,然后继续迭代1000次,最后模型等价于一次性迭代2000次
可以知道每棵树将样本分类到哪片叶子上,facebook介绍过如何利用这个信息提高模型的表现
可以计算变量重要性并画出树状图
可以选择使用线性模型替代树模型,从而得到带L1+L2惩罚的线性回归或者logistic回归
————————————————————————————————————————————
三、用R语言实现Xgboost案例
1、如何实现?
看到在Python和R上都有自己的package。
R中直接install.packages即可。也可以从github上调用:
devtools::install_github('dmlc/xgboost',subdir='R-package')
但是,注意!! XGBoost仅适用于数值型向量。是的!你需要使用中区分数据类型。如果是名义,比如“一年级”、“二年级”之类的,需要变成哑变量,然后进行后续的处理。
XGBoost有自己独有的数据结构,将数据数值化,可以进行稀疏处理。极大地加快了运算。这种独特的数据结构得着重介绍一下。
2、one-hot encode 独热编码——独有的数据结构
这个词源于数字电路语言,这意味着一个数组的二进制信号,只有合法的值是0和1。
在R中,一个独热编码非常简单。这一步(如下所示)会在每一个可能值的变量使用标志建立一个稀疏矩阵。稀疏矩阵是一个矩阵的零的值。稀疏矩阵是一个大多数值为零的矩阵。相反,一个稠密矩阵是大多数值非零的矩阵。
sparse_matrix <- Matrix::sparse.model.matrix(response ~ .-1, data = campaign)现在让我们分解这个代码如下:
-
sparse.model.matrix这条命令的圆括号里面包含了所有其他输入参数。 -
参数“反应”说这句话应该忽略“响应”变量。
-
“-1”意味着该命令会删除矩阵的第一列。
-
最后你需要指定数据集名称。
其中这个-1很有意思,response代表因变量,那么为什么还要“-1”,删去第一列?
答:这个根据题意自己调整,此时的-1可能是需要分拆的变量,比如此时第一列变量名称是“治疗”,其中是二分类,“治疗”与“安慰剂治疗”。此时的-1代表把这个变量二分类变成两个变量,一个变量为“是否治疗”,另外一个是“是否安慰剂治疗”,那么就由一个名义变量转化成了0-1数值型变量了。
想要转化目标变量,你可以使用下面的代码:
output_vector = df[,response] == "Responder"代码解释:
-
设 output_vector 初值为0。
-
在 output_vector 中,将响应变量的值为 "Responder" 的数值设为1;
-
返回 output_vector。
3、XGBoost数之不尽的参数
XGBoost的参数超级多,详情可以看:官方解释网站
它有三种类型的参数:通用参数、辅助参数和任务参数。
-
通用参数为我们提供在上升过程中选择哪种上升模型。常用的是树或线性模型。
-
辅助参数取决于你选择的上升模型。
-
任务参数,决定学习场景,例如,回归任务在排序任务中可能使用不同的参数。
让我们详细了解这些参数。我需要你注意,这是实现xgboost算法最关键的部分:
一般参数
-
silent : 默认值是0。您需要指定0连续打印消息,静默模式1。
-
booster : 默认值是gbtree。你需要指定要使用的上升模型:gbtree(树)或gblinear(线性函数)。
-
num_pbuffer : 这是由xgboost自动设置,不需要由用户设定。阅读xgboost文档的更多细节。
-
num_feature : 这是由xgboost自动设置,不需要由用户设定。
辅助参数
具体参数树状图:
-
eta:默认值设置为0.3。您需要指定用于更新步长收缩来防止过度拟合。每个提升步骤后,我们可以直接获得新特性的权重。实际上 eta 收缩特征权重的提高过程更为保守。范围是0到1。低η值意味着模型过度拟合更健壮。
-
gamma:默认值设置为0。您需要指定最小损失减少应进一步划分树的叶节点。更大,更保守的算法。范围是0到∞。γ越大算法越保守。
-
max_depth:默认值设置为6。您需要指定一个树的最大深度。参数范围是1到∞。
-
min_child_weight:默认值设置为1。您需要在子树中指定最小的(海塞)实例权重的和,然后这个构建过程将放弃进一步的分割。在线性回归模式中,在每个节点最少所需实例数量将简单的同时部署。更大,更保守的算法。参数范围是0到∞。
-
max_delta_step:默认值设置为0。max_delta_step 允许我们估计每棵树的权重。如果该值设置为0,这意味着没有约束。如果它被设置为一个正值,它可以帮助更新步骤更为保守。通常不需要此参数,但是在逻辑回归中当分类是极为不均衡时需要用到。将其设置为1 - 10的价值可能有助于控制更新。参数范围是0到∞。
-
subsample: 默认值设置为1。您需要指定训练实例的子样品比。设置为0.5意味着XGBoost随机收集一半的数据实例来生成树来防止过度拟合。参数范围是0到1。
-
colsample_bytree : 默认值设置为1。在构建每棵树时,您需要指定列的子样品比。范围是0到1。
-
colsample_bylevel:默认为1
-
max_leaf_nodes:叶结点最大数量,默认为2^6
线性上升具体参数
-
lambda and alpha : L2正则化项,默认为1、L1正则化项,默认为1。这些都是正则化项权重。λ默认值假设是1和α= 0。
-
lambda_bias : L2正则化项在偏差上的默认值为0。
-
scale_pos_weight:加快收敛速度,默认为1
任务参数
-
base_score : 默认值设置为0.5。您需要指定初始预测分数作为全局偏差。
-
objective : 默认值设置为reg:linear。您需要指定你想要的类型的学习者,包括线性回归、逻辑回归、泊松回归等。
-
eval_metric : 您需要指定验证数据的评估指标,一个默认的指标分配根据客观(rmse回归,错误分类,意味着平均精度等级
-
seed : 随机数种子,确保重现数据相同的输出。
4、具体案例——官方案例 discoverYourData
案例的主要内容是:服用安慰剂对病情康复的情况,其他指标还有年龄、性别。
(1)数据导入与包的加载
操作时对包的要求,在加载的时候也会一些报错。后面换了版本就OK了。
- require(xgboost)
- require(Matrix)
- require(data.table)
- if (!require('vcd')) install.packages('vcd')
-
- data(Arthritis)
- df <- data.table(Arthritis, keep.rownames = F)
接下来对数据进行一些处理。
- head(df[,AgeDiscret := as.factor(round(Age/10,0))]) #:= 新增加一列
- head(df[,AgeCat:= as.factor(ifelse(Age > 30, "Old", "Young"))]) #ifelse
- df[,ID:=NULL]
首先看一下这个代码写的很棒,比如:ifelse的用法,以及:=用法(直接在[]框中对数据进行一定操作)
(2)生成特定的数据格式
sparse_matrix <- sparse.model.matrix(Improved~.-1, data = df) #变成稀疏数据,然后0变成.,便于占用内存最小
生成了one-hot encode数据,独热编码。Improved是Y变量,-1是将treament变量(名义变量)拆分。
(3)设置因变量(多分类)
output_vector = df[,Improved] == "Marked" (4)xgboost建模
- bst <- xgboost(data = sparse_matrix, label = output_vector, max.depth = 4,
- eta = 1, nthread = 2, nround = 10,objective = "binary:logistic")
其中nround是迭代次数,可以用此来调节过拟合问题;
nthread代表运行线程,如果不指定,则表示线程全开;
objective代表所使用的方法:binary:logistic是以非线性的方式,分支。reg:linear(默认)、reg:logistic、count:poisson(泊松分布)、multi:softmax
(5)特征重要性排名
- importance <- xgb.importance(sparse_matrix@Dimnames[[2]], model = bst)
- head(importance)
会出来比较多的指标,Gain是增益,树分支的主要参考因素;cover是特征观察的相对数值;Frequence是gain的一种简单版,他是在所有生成树中,特征的数量(慎用!)
(6)特征筛选与检验
知道特征的重要性是一回事儿,现在想知道年龄对最后的治疗的影响。所以需要可以用一些方式来反映出来。以下是官方自带的。
- importanceRaw <- xgb.importance(sparse_matrix@Dimnames[[2]], model = bst, data = sparse_matrix, label = output_vector)
-
- # Cleaning for better display
- importanceClean <- importanceRaw[,`:=`(Cover=NULL, Frequence=NULL)] #同时去掉cover frequence
- head(importanceClean)
比第一种方式多了split列,代表此时特征分割的界线,比如特征2: Age 61.5,代表分割在61.5岁以下治疗了就痊愈了。同时,多了RealCover 和RealCover %列,前者代表在这个特征的个数,后者代表个数的比例。
绘制重要性图谱:
xgb.plot.importance(importance_matrix = importanceRaw)
需要加载install.packages("Ckmeans.1d.dp"),其中输出的是两个特征,这个特征数量是可以自定义的,可以定义为10族。
变量之间影响力的检验,官方用的卡方检验:
c2 <- chisq.test(df$Age, output_vector)
检验年龄对最终结果的影响。
(7)疑问?
- #Random Forest™ - 1000 trees
- bst <- xgboost(data = train$data, label = train$label, max.depth = 4, num_parallel_tree = 1000, subsample = 0.5, colsample_bytree =0.5, nround = 1, objective = "binary:logistic")
- #num_parallel_tree这个是什么?
-
- #Boosting - 3 rounds
- bst <- xgboost(data = train$data, label = train$label, max.depth = 4, nround = 3, objective = "binary:logistic")
- #???代表boosting
话说最后有一个疑问,这几个代码是可以区分XGBoost、随机森林以及boosting吗?
(8)一些进阶功能的尝试
作为比赛型算法,真的超级好。下面列举一些我比较看中的功能:
1、交叉验证每一折显示预测情况
挑选比较优质的验证集。
- # do cross validation with prediction values for each fold
- res <- xgb.cv(params = param, data = dtrain, nrounds = nround, nfold = 5, prediction = TRUE)
- res$evaluation_log
- length(res$pred)
交叉验证时可以返回模型在每一折作为预测集时的预测结果,方便构建ensemble模型。
2、循环迭代
允许用户先迭代1000次,查看此时模型的预测效果,然后继续迭代1000次,最后模型等价于一次性迭代2000次。
- # do predict with output_margin=TRUE, will always give you margin values before logistic transformation
- ptrain <- predict(bst, dtrain, outputmargin=TRUE)
- ptest <- predict(bst, dtest, outputmargin=TRUE)
3、每棵树将样本分类到哪片叶子上
- # training the model for two rounds
- bst = xgb.train(params = param, data = dtrain, nrounds = nround, nthread = 2)
4、线性模型替代树模型
可以选择使用线性模型替代树模型,从而得到带L1+L2惩罚的线性回归或者logistic回归。
- # you can also set lambda_bias which is L2 regularizer on the bias term
- param <- list(objective = "binary:logistic", booster = "gblinear",
- nthread = 2, alpha = 0.0001, lambda = 1)
——————————————————————————————————————————————————
四、用Python实现XGBoost
官方文档路径:Python API Reference,作者使用的是python3,跟py2的一些code可能有些区别
- !pip3 install xgboost
-
- import xgboost as xgb
即可对付多分类也可以对付回归。如果是分类的话,就是: xgb.XGBClassifier(),其他基本没差。
主要尝试了回归,就来简单说说回归,主要参数:
XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True, objective='reg:linear', booster='gbtree', n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)可以看到objective='reg:linear'代表线性回归。
1、XGBoost回归案例
其中一个简单模型拟合案例:
- from sklearn.metrics import confusion_matrix, mean_squared_error
- import xgboost as xgb
- gbm = xgb.XGBRegressor().fit(data.ix[:,25:], data['y'])
- predictions = gbm.predict(data.ix[:,25:])
- actuals = data['y']
- print(mean_squared_error(actuals, predictions))
data就是一个普通的dataframe格式,其中'y'就是因变量,然后可以直接fit拟合函数。
最后,输出mean_squared_error平方误差,衡量模型预测好坏。
2、画出XGBoost节点图
如果y是分类变量,可以直接画出节点图:
- from matplotlib import pyplot
- from xgboost import plot_tree
- plot_tree(gbm, num_trees=0, rankdir='LR')
- pyplot.show()
可以直接通过plot_tree画出节点图,但是plot_tree很丑,很模糊!
一种解决方案,参考https://github.com/dmlc/xgboost/issues/1725:
- xgb.plot_tree(bst, num_trees=2)
- fig = matplotlib.pyplot.gcf()
- fig.set_size_inches(150, 100)
- fig.savefig('tree.png')
于是乎,就需要来一张清晰一些的图片还有一种画法如下:
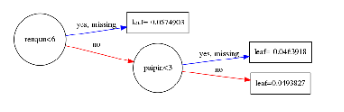
xgb.to_graphviz(gbm, num_trees=80, rankdir='LR')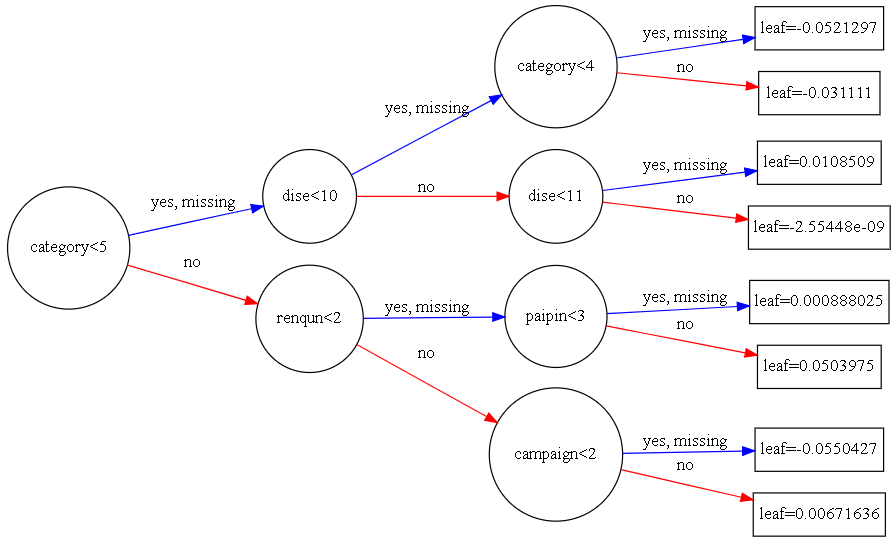
来观察一下图型:
其中分支代表,category<5,两条路,代表条件成立,yes;条件不成立,no
每个节点都带有节点名,但是圆圈的大小,有人说是样本量越大,圆圈越大,也有可能是根据节点名称的多少来划定。
如何把图形输出出来:from graphviz import Digraph(参考:如何画XGBoost里面的决策树(decision tree))
参数界面:https://xgboost.readthedocs.io/en/latest/python/python_api.html
3、模型中指标的重要性输出
XGBoost模型中的三种重要性:Gain是增益,树分支的主要参考因素; cover是特征观察的相对数值; Frequence是gain的一种简单版,他是在所有生成树中,特征的数量
'weight' - the number of times a feature is used to split the data across all trees. 'gain' - the average gain of the feature when it is used in trees 'cover' - the average coverage of the feature when it is used in trees
直接画出:
- from xgboost import plot_importance
- from matplotlib import pyplot
- plot_importance(gbm,importance_type = 'cover')
- pyplot.show()
其中importance_type = 'cover',也可以等于'weight'以及'gain'
但是这输出的是图片,如何获得重要性的List数值?

——应用get_socre()
gbm.booster().get_score(importance_type='gain')还有:
- model.get_booster().get_score(importance_type='cover')
-
- len(model.get_booster().feature_names)
- # 重要性特征的名字
- len(model.feature_importances_)
- Counter(dict(zip(model.get_booster().feature_names,model.feature_importances_))).most_common(10)
4、调参工具
本节来源:Kaggle 神器 xgboost 和 XGBoost超参数调优实战
GridSearchCV 来进行调参会更方便一些,
调参刚开始的时候,一般要先初始化一些值:
- learning_rate: 0.1
- n_estimators: 500
- max_depth: 5
- min_child_weight: 1
- subsample: 0.8
- colsample_bytree:0.8
- gamma: 0
- reg_alpha: 0
- reg_lambda: 1
可以调的超参数组合以及顺序,可参考:
最佳迭代次数:n_estimators
min_child_weight以及max_depth
gamma
subsample以及colsample_bytree
reg_alpha以及reg_lambda
最后就是learning_rate,一般这时候要调小学习率来测试
- from sklearn.model_selection import GridSearchCV
- from sklearn.model_selection import StratifiedKFold
设定要调节的 learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
和原代码相比就是在 model 后面加上 grid search 这几行:
- model = XGBClassifier()
- learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
- param_grid = dict(learning_rate=learning_rate)
- kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
- grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
- grid_result = grid_search.fit(X, Y)
最后会给出最佳的学习率为 0.1
Best: -0.483013 using {'learning_rate': 0.1}
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
我们还可以用下面的代码打印出每一个学习率对应的分数:
- means = grid_result.cv_results_['mean_test_score']
- stds = grid_result.cv_results_['std_test_score']
- params = grid_result.cv_results_['params']
- for mean, stdev, param in zip(means, stds, params):
- print("%f (%f) with: %r" % (mean, stdev, param))
- -0.689650 (0.000242) with: {'learning_rate': 0.0001}
- -0.661274 (0.001954) with: {'learning_rate': 0.001}
- -0.530747 (0.022961) with: {'learning_rate': 0.01}
- -0.483013 (0.060755) with: {'learning_rate': 0.1}
- -0.515440 (0.068974) with: {'learning_rate': 0.2}
- -0.557315 (0.081738) with: {'learning_rate': 0.3}
-
一些整理比较规范的代码:
Complete Guide to Parameter Tuning in XGBoost with codes in Python
- def modelfit(alg, dtrain, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
-
- if useTrainCV:
- xgb_param = alg.get_xgb_params()
- xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
- cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
- metrics='auc', early_stopping_rounds=early_stopping_rounds, show_progress=False)
- alg.set_params(n_estimators=cvresult.shape[0])
-
- #Fit the algorithm on the data
- alg.fit(dtrain[predictors], dtrain['Disbursed'],eval_metric='auc')
-
- #Predict training set:
- dtrain_predictions = alg.predict(dtrain[predictors])
- dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
-
- #Print model report:
- print "\nModel Report"
- print "Accuracy : %.4g" % metrics.accuracy_score(dtrain['Disbursed'].values, dtrain_predictions)
- print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['Disbursed'], dtrain_predprob)
-
- feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
- feat_imp.plot(kind='bar', title='Feature Importances')
- plt.ylabel('Feature Importance Score')

其他版本问题:
这里有一个 问题,就是`xgboost.XGBRegressor`,在causalml默认是xgboost = 1.4.2版本的,但是这个版本会出现报错:
```
AttributeError: type object 'cupy.core.core.broadcast' has no attribute '__reduce_cython__'
```
也就是这里需要注意,如果是cpu调用,需要`Predictor = 'cpu_predictor'`,但是,好像causalML封装的有些问题,`from causalml.inference.meta import XGBTRegressor`,所以一直会报上面的错,只能回退xgboost版本到1.3.1就正常了。
> 20211213更新一个神奇的bug
> xgboost.XGBClassifier( predictor = 'cpu_predictor') ,在1.3.1 版本下,第一次运行可以正常,第二次再次model.fit()的时候,还是会出现` '__reduce_cython__'`,
> 笔者经过多轮尝试,回退到1.2.1,终于恢复正常
> 奇怪的是,1.3.1版本下,`xgboost.XGBRegressor` 多轮运行是正常的,具体原因未知... 且在其他window系统下,`XGBClassifier`在1.3.3 也是正常的,非常奇怪。。
————————————————————————————————————————————————————————————
应用一:XGBoost用来做预测
R语言中XGBoost用来做预测的新包,forecastxgb来看看一个简单的案例。
devtools::install_github("ellisp/forecastxgb-r-package/pkg")
以上是包的加载,是在github上面的。
一个官方的案例是:
library(forecastxgb)
model <- xgbts(gas)
summary一下就可以看到以下的内容:
summary(model)
Importance of features in the xgboost model:
Feature Gain Cover Frequence
1: lag12 4.866644e-01 0.126320210 0.075503356
2: lag11 2.793567e-01 0.049217848 0.035234899
3: lag13 1.044469e-01 0.037102362 0.030201342
4: lag24 7.987905e-02 0.150929134 0.080536913
5: time 2.817163e-02 0.125291339 0.077181208
6: lag1 1.190114e-02 0.131002625 0.152684564
7: lag23 5.306595e-03 0.015685039 0.018456376
8: lag2 7.431663e-04 0.072188976 0.063758389
9: lag14 5.801733e-04 0.014152231 0.021812081
10: lag6 4.071911e-04 0.013480315 0.031879195
11: lag18 3.345186e-04 0.026120735 0.021812081
12: lag5 2.781746e-04 0.023244094 0.043624161
13: lag16 2.564357e-04 0.012262467 0.020134228
14: lag17 2.067079e-04 0.011128609 0.021812081
15: lag21 1.918721e-04 0.015769029 0.023489933
16: lag4 1.698715e-04 0.012703412 0.036912752
17: lag22 1.417012e-04 0.019485564 0.025167785
18: lag19 1.291178e-04 0.009511811 0.016778523
19: lag20 1.188570e-04 0.005312336 0.010067114
20: lag8 1.115240e-04 0.016629921 0.023489933
21: lag9 1.051375e-04 0.021375328 0.026845638
22: lag10 1.035566e-04 0.036829396 0.035234899
23: season7 1.008707e-04 0.006950131 0.008389262
24: lag7 8.698124e-05 0.007097113 0.021812081
25: lag3 7.582023e-05 0.006740157 0.038590604
26: lag15 6.305601e-05 0.006677165 0.013422819
27: season4 5.440121e-05 0.001805774 0.003355705
28: season5 7.204729e-06 0.002918635 0.008389262
29: season8 3.280837e-06 0.003422572 0.003355705
30: season6 2.090122e-06 0.008923885 0.005033557
31: season10 1.287062e-06 0.007307087 0.001677852
32: season12 5.436832e-07 0.002414698 0.003355705
Feature Gain Cover Frequence
36 features considered.
476 original observations.
452 effective observations after creating lagged features.
建好模之后就是进行预测:
fc <- forecast(model, h = 12)
plot(fc)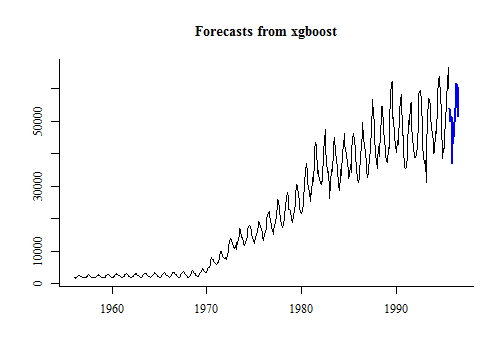
如果有额外的自变量需要加入:
library(fpp)
consumption <- usconsumption[ ,1]
income <- matrix(usconsumption[ ,2], dimnames = list(NULL, "Income"))
consumption_model <- xgbts(y = consumption, xreg = income)
Stopping. Best iteration: 20
预测以及画图:
income_future <- matrix(forecast(xgbts(usconsumption[,2]), h = 10)$mean,
dimnames = list(NULL, "Income"))
Stopping. Best iteration: 1
plot(forecast(consumption_model, xreg = income_future))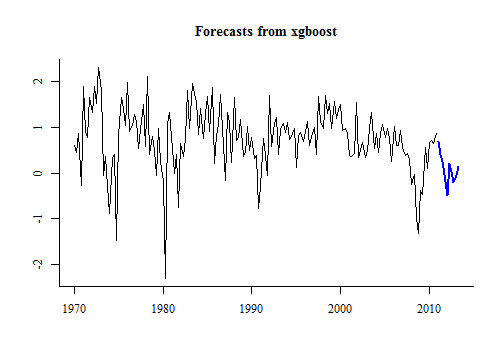
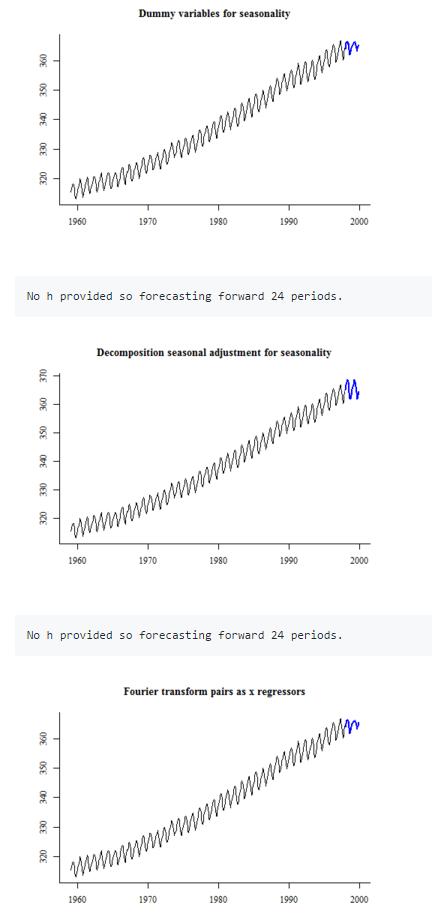
季节调整
三种处理季节的方式。
第一种:把季节效应变成哑变量处理;
第二种:季节调整方式,乘法效应(计量中还有加法效应)。
第三种:傅里叶变换后的变量当做X,作为变量
来看看具体效果,不过三款模型都不好,因为存在趋势项,没有做平稳处理。
类似BOX-COX数据变换
在negative数据上使用数据变换,默认值为BoxCox.lambda(abs(y))
不过,目前为止数据转换并没有很好地强化模型的性能
非平稳的情况
较多使用ARIMA来进行趋势预测
- model <- xgbar(AirPassengers, trend_method = "differencing", seas_method = "fourier")
- plot(forecast(model, 24))

未来的进展:
一些特殊时间点的加入,交易日、复活节
加入向量自回归模型
更好的封装,譬如傅里叶变换等
——————————————————————————————————————
参考文献
xgboost: 速度快效果好的boosting模型
[译]快速上手:在R中使用XGBoost算法
XGBoost的PPT材料:https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
——————————————————————————————————————
延伸一:来看看LightGBM和XGboosting的差异:
XGBoost是一款经过优化的分布式梯度提升(Gradient Boosting)库,具有高效,灵活和高可移植性的特点。基于梯度提升框架,XGBoost实现了并行方式的决策树提升(Tree Boosting),从而能够快速准确地解决各种数据科学问题。
LightGBM(Light Gradient Boosting Machine)同样是一款基于决策树算法的分布式梯度提升框架。
1. 速度:速度上xgboost 比LightGBM在慢了10倍
2. 调用核心效率:随着线程数的增加,比率变小了。这也很容易解释,因为你不可能让线程的利用率是100%,线程的切入切出以及线程有时要等待,这都需要耗费很多时间。保持使用逻辑核心创建一定量的线程,并且不要超过该数。不然反而速度会下降。
3. 内存占用:xgboost:约 1684 MB;LightGBM: 1425 MB,LightGBM在训练期间的RAM使用率较低,但是内存中数据的RAM使用量增加


