
- 1Ubuntu中安装rabbitMQ
- 2无人车系统(七):Udacity ‘s无人驾驶仿真环境(社区介绍)_基于深度学习的udacity无人驾驶系统介绍
- 3机器学习中的数据预处理指南_机器学习 预处理
- 4python合并ts视频(三种方法)_ts合并
- 5【软件工具】Zotero+手机端_zotero安卓版
- 6Day 11 ElementUI VUE后台管理系统 参数管理 商品列表 商品添加_element ui 列表参数
- 7spring boot pom打包配置+linux启动脚本 提高打包部署速度_spring boot 如何提高打包速度
- 8【Java】线程安全问题
- 9android设置背景颜色渐变,Android背景渐变色(shape,gradient)
- 10MathType+Word报错:The MathType DLL cannot be found问题快速解决_word2019 mathtype dll cannot be found
【深度学习】图像超分辨
赞
踩
案例 7:图像超分辨
相关知识点:生成对抗网络、图像处理(PIL)和可视化(matplotlib)
1 任务目标
1.1 任务和数据简介
本次案例将使用生成对抗网络来实现 4 倍图像超分辨任务,输入一张低分辨率图像,生成器会生成一张 4 倍超分辨率的图像,如图 1 所示。生成对抗网络选用 SRGAN 结构[1]。本案例训练集使用 DIV2K 数据集[2],包含有800张2K左右高分辨率的图像和 800 张对应的低分辨率图像;测试集使用 DIV2K 验证集[2]、 Set5 、 Set14 、 B100 、 Urban 100五个数据集,分别包括高分辨率图像和对应的低分辨率图像。训练集和测试集中的所有低分辨图像都是由高分辨率图像下采样得到,下采样方法为使用 Matlab 中的 resize 函数, scalefactor 为 0.25 ,其余为默认参数(双三次插值)。

本案例使用 PSNR 与 SSIM 两个评价指标来衡量生成的高分辨率图像的质量,但指标的高低并不能直接反应图像质量的好坏,因此最终结果评价会加入人工评价,具体见第 4 部分的要求
1.2 方法描述
-
模型结构
案例使用 [1] 中提出的 SRGAN 结构,生成器和判别器的结构与原论文保持一致,本案例要求自行实现 SRGAN 网络结构
-
内容损失函数
本案例涉及到两种内容损失函数,第一种为图像像素空间的MSE损失,第二种为图像特征空间的MSE损失。
设 I L R I^{LR} ILR, I H R I^{HR} IHR 分别表示输入的低分辨图像和作为标签的高分辨图像, G ( ⋅ ) G(·) G(⋅) 表示生成器, D ( ⋅ ) D(·) D(⋅) 表示判别器。图像像素空间的 MSE 损失表示
L M S E S R = M S E ( G ( I L R ) , I H R ) L^{SR}_{MSE}=MSE(G(I^{LR}),I^{HR}) LMSESR=MSE(G(ILR),IHR)
图像特征空间的 MSE 损失也被称为 VGG 损失,是基于预训练好的 VGG 提取图像特征来计算的。设 φ i , j ( ⋅ ) \varphi_{i,j}(·) φi,j(⋅) 表示获取 VGG19 网络中第 j 层卷积(包含激活 函数)之后,第 i 层最大池化层前的特征图。VGG 损失表示
L V G G / i , j S R = M S E ( φ i , j ( G ( I L R ) ) , φ i , j ( I H R ) ) L_{VGG/i,j}^{SR}=MSE(\varphi_{i,j}(G(I^{LR})),\varphi_{i,j}(I^{HR})) LVGG/i,jSR=MSE(φi,j(G(ILR)),φi,j(IHR)) -
对抗损失函数
对抗学习中,生成器生成的高分辨图像要尽可能接近真实的高分辨率图像,能够欺骗判别器识别为真实的高分辨率图像;判别器则要尽可能对生成的高分辨图像和真实的高分辨图像做出区分。因此生成器的对抗损失函数为
L G e n S R = − l o g D ( G ( I L R ) ) L^{SR}_{Gen}=-\mathop{logD}(G(I^{LR})) LGenSR=−logD(G(ILR))
再加上内容损失 L X S R ( X = MSE o r VGG / i , j ) L_X^{SR}(X=\text{MSE}\ or\ \text{VGG}/i,j) LXSR(X=MSE or VGG/i,j) 生成器的训练损失函数为
L G S R = L X S R + 1 0 − 3 L G e n S R L_G^{SR}=L_X^{SR}+10^{-3}L_{Gen}^{SR} LGSR=LXSR+10−3LGenSR
判别器是一个二分类器,训练损失函数为交叉熵损失函数。
1.3 参考程序及使用说明
本案例提供了部分代码供使用,各程序简介如下:
-
create_data_lists.py: 下载好训练集和测试集后,根据提供的数据集地址来生成案例训练测试所需要的 csv 文件。 -
datasets.py: 定义符合 pytorch 标准的 Dataset 类,供读入数据,注意训练阶段每张图片采样了100个 patch 来扩充训练集。 -
imresize.py: 用python实现了matlabresize函数,用于图像下采样。目前 python 第三方包中尚未有能得到与matlabresize函数一样结果的函数。 -
solver.py: 定义了一个 epoch 的训练过程。 -
models.py: 定义 SRGAN 模型结构,需要自行实现。 -
train.ipynb: 用于训练的 jupyter 文件,其中超参数需要自行调节,训练过程中可以看到模型损失的变化,每个 epoch 训练后都会进行模型保存。 -
test.ipynb: 加载指定的训练好的模型文件,在5个测试集上进行测试,计算并报告各个数据集上的 PSNR 和 SSIM 指标数值。 -
super_resolution.ipynb: 加载指定的训练好的模型文件,针对单个图片进行4倍超分辨,并对结果进行可视化。 -
utils.py: 定义了一些可能会用到的函数,如图像数值格式转换等。
环境要求:python 包 pytorch, torchvision, numpy, csv, PIL, matplotlib, easydict, tqdm等。
使用说明:
- 下载训练集和测试集[5],更改
create_data_lists.py中数据集存放的位置, 指定输出文件夹,运行该文件生成案例所需的 csv 文件; - 按照 SRGAN 网络结构完成
models.py; - 运行
train.ipynb训练网络,现在的训练模式为初始化生成器和判别器后,对生成器和判别器进行交替更新。这样的训练模式只能得到一个表现很差的模型。案例要求自行设计训练模式,如加入生成器的预训练等[4],更改solver.py和train.ipynb训练出一个性能好的模型; - 运行
test.ipynb对训练的模型进行测试,现在是对 5 个测试集进行 PSNR 和 SSIM 的计算。其中包含了 DIV2K 数据集中的验证集,这个验证集也可以作为训练时用于调整参数的验证集(如需验证请自行修改train.ipynb实现,不做要求); - 模型训练好之后运行
super_resolution.ipynb生成供人工测评的图片。
1.4 要求与建议
- 完成
models.py文件,可参考原论文[1]; - 调节
train.ipynb中的超参数,使网络结构与原论文保持一致。运行train.ipynb使案例可以跑通基础模式的训练; - 设计生成器和判别器的训练方式,可参考[4]中的训练方式,修改
solver.py和
train.ipynb训练出性能更好的模型; - 运行
test.ipynb对模型在5个测试集上进行测试,记录 PSNR 与 SSIM 结果; - 运行
super_resolution.ipynb,为 Set5 测试集中的每一张低分辨图片生成相应的高分辨图片,保留结果供人工评价; - 完成一个实验报告,内容包括生成器和判别器的训练方式说明、模型最佳参数和对应的测试集结果、 Set5 测试集图片生成结果、自己所做的尝试和改进;
- 提交所有的代码文件,注意 jupyter 文件保留结果,请不要提交模型文件;
- 禁止任何形式的抄袭,借鉴开源程序务必加以说明。
1.5 参考材料
[1] Ledig, Christian, et al. “Photo-realistic single image super-resolution using a generative adversarial network.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. https://arxiv.org/abs/1609.04802
[2] https://data.vision.ee.ethz.ch/cvl/DIV2K/
[3] https://zhuanlan.zhihu.com/p/50757421
[4] https://github.com/tensorlayer/srgan
[5] 数据集下载链接
训练集:http://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_HR.ziphttp://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_LR_bicubic_X4.zip
测试集:http://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_valid_HR.ziphttp://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_valid_LR_bicubic_X4.ziphttps://cloud.tsinghua.edu.cn/d/d97daf4c4b394abf86ec/
2 模型构造
2.1 图像超分辨原理
图像超分辨率(Super-Resolution, SR)是计算机视觉和图像处理领域的一个重要研究方向,旨在从低分辨率(Low-Resolution, LR)图像中恢复出高分辨率(High-Resolution, HR)图像。
-
传统超分辨方法
-
最近邻上采样(Nearest Neighbour Upsampling)
最近邻插值是最简单的插值方法。在这种方法中,每个新生成的像素(在上采样过程中)直接复制其最近的原始像素值。这种方法的优点是速度快,但缺点是可能导致图像块状和锯齿状,因为它不考虑像素之间的任何空间关系。
-
双线性插值(Bilinear Interpolation)
双线性插值是一种更平滑的插值方法。对于每个新像素,它考虑了水平和垂直方向上最近的四个像素值,并根据新像素与这些邻居像素的距离进行加权平均。这种方法比最近邻插值产生更自然、更少块状的图像,但在某些情况下可能仍然缺乏锐度和细节。
-
双三次插值(Bicubic Interpolation)
双三次插值是双线性插值的扩展,它使用16个最近邻居像素值而不是4个。这些像素值通过一个三次多项式函数进行加权和组合,以生成新像素的值。双三次插值通常比双线性插值产生更平滑、更详细的图像,但计算成本也更高。
-
-
神经网络超分辨率(Neural Super-Resolution)
与传统的“简单”图像上采样相比,超分辨率的目标是从低分辨率版本创建高分辨率、高保真度、视觉上令人愉悦、可信的图像。
当图像被降低到较低分辨率时,细微的细节将不可挽回地丢失。同样,升级到更高分辨率需要添加新的信息。一个为超分辨率训练的神经网络可能会识别出,例如,我们上面低分辨率图像中的黑色对角线需要在放大的图像中被复制为一个平滑但锐利的黑色对角线。

-
SRResNet (Super-Resolution Residual Network)
SRResNet是一种深度残差网络(ResNet),它利用残差连接来解决深度神经网络中的梯度消失问题,使得网络可以成功训练更深的层次结构。

SRResNet由以下操作组成 :
-
首先,低分辨率图像与一个核大小为 9 × 9 9\times9 9×9、步长为 1 1 1 的卷积层进行卷积,产生一个具有相同分辨率但有 64 64 64 个通道的特征图。应用参数化 ReLU(PReLU)激活函数。
-
这个特征图通过 16 16 16 个 残差块,每个残差块由一个核大小为 3 × 3 3\times3 3×3、步长为 1 1 1 的卷积层、批量归一化和 PReLU 激活函数、另一个相似的卷积层以及第二个批量归一化组成。在每个卷积层中保持分辨率和通道数不变。
-
来自一系列残差块的结果通过一个核大小为 3 × 3 3\times3 3×3、步长为 1 1 1 的卷积层进行处理,并进行批量归一化。保持分辨率和通道数不变。除了每个残差块中的跳跃连接(根据定义),还有一个更大的跳跃连接跨越所有残差块和这个卷积层。
-
2 2 2 个 子像素卷积块,每个块将维度放大 2 2 2 倍(随后进行 PReLU 激活),总共实现 4 4 4 倍放大。保持通道数不变。
-
最后,在这个更高分辨率上应用一个核大小为 9 × 9 9\times9 9×9、步长为 1 1 1 的卷积,结果通过 Tanh 激活函数处理,产生 具有 RGB 通道的超分辨率图像,其值范围在 [ − 1 , 1 ] [-1, 1] [−1,1] 之间。
-
-
SRGAN(Super-Resolution Generative Adversarial Network)
SRGAN由一个生成器网络和一个鉴别器网络组成。
生成器的目标是学会足够真实地超分辨率图像,鉴别器被训练来识别这种人工来源的蛛丝马迹,生成器和鉴别器两个网络同时训练,训练目标便是令生成器生成的图片,不能再被鉴别器区分。
生成器在架构上与SRResNet完全相同。鉴别器是一个卷积网络,作为一个二元图像分类器。

2.2 SSResNet
以下类共同构成了SRResNet模型的基本结构,每个类都负责处理图像的不同部分,最终协同工作以生成高质量的超分辨率图像。通过这种方式,SRResNet能够有效地恢复低分辨率图像中的细节,并提高图像的视觉质量。
-
ConvolutionalBlock类该类表示一个包含卷积层、批量归一化(Batch Normalization, BN)和激活函数的基本卷积块。它接受输入和输出通道数、卷积核大小、步长、是否包含BN层以及激活函数类型作为参数。在前向传播中,它将输入图像通过定义好的层序列进行处理,并输出结果。
class ConvolutionalBlock(nn.Module): """ 一个卷积块,包括卷积层、批量归一化层和激活层。 """ def __init__(self, in_channels, out_channels, kernel_size, stride=1, batch_norm=False, activation=None): """ :param in_channels: 输入通道数 :param out_channels: 输出通道数 :param kernel_size: 卷积核大小 :param stride: 步长 :param batch_norm: 是否包含批量归一化层? :param activation: 激活函数类型;如果没有则为None """ super(ConvolutionalBlock, self).__init__() if activation is not None: activation = activation.lower() assert activation in {'prelu', 'leakyrelu', 'tanh'} # 用于保存这个卷积块中的层的容器 layers = list() # 一个卷积层 layers.append( nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=kernel_size // 2)) # 如果需要,加入批量归一化(BN)层 if batch_norm is True: layers.append(nn.BatchNorm2d(num_features=out_channels)) # 如果需要,加入激活层 if activation == 'prelu': layers.append(nn.PReLU()) elif activation == 'leakyrelu': layers.append(nn.LeakyReLU(0.2)) elif activation == 'tanh': layers.append(nn.Tanh()) # 将卷积块的层按顺序组合起来 self.conv_block = nn.Sequential(*layers) def forward(self, input): """ 前向传播。 :param input: 输入图像,尺寸为 (N, in_channels, w, h) 的张量 :return: 输出图像,尺寸为 (N, out_channels, w, h) 的张量 """ output = self.conv_block(input) # (N, out_channels, w, h) return output- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
-
SubPixelConvolutionalBlock类这个类实现了一个子像素卷积块,它包含一个卷积层、一个像素重排层(
PixelShuffle)和PReLU激活函数。子像素卷积是一种上采样技术,可以在不增加像素值计算量的情况下增加图像的分辨率。这个块通过卷积层增加通道数,然后通过像素重排层上采样图像,最后通过PReLU激活函数进行非线性变换。class SubPixelConvolutionalBlock(nn.Module): """ 一个子像素卷积块,包括卷积层、像素重排层和PReLU激活层。 """ def __init__(self, kernel_size=3, n_channels=64, scaling_factor=2): """ :param kernel_size: 卷积核大小 :param n_channels: 输入和输出通道数 :param scaling_factor: 沿两个维度缩放输入图像的因子 """ super(SubPixelConvolutionalBlock, self).__init__() # 一个卷积层,通过缩放因子的平方增加通道数,然后是像素重排和PReLU self.conv = nn.Conv2d(in_channels=n_channels, out_channels=n_channels * (scaling_factor ** 2), kernel_size=kernel_size, padding=kernel_size // 2) # 这些额外的通道被重排以形成额外的像素,每个维度通过缩放因子进行上采样 self.pixel_shuffle = nn.PixelShuffle(upscale_factor=scaling_factor) self.prelu = nn.PReLU() def forward(self, input): """ 前向传播。 :param input: 输入图像,尺寸为 (N, n_channels, w, h) 的张量 :return: 缩放后的输出图像,尺寸为 (N, n_channels, w * 缩放因子, h * 缩放因子) 的张量 """ output = self.conv(input) # (N, n_channels * 缩放因子的平方, w, h) output = self.pixel_shuffle(output) # (N, n_channels, w * 缩放因子, h * 缩放因子) output = self.prelu(output) # (N, n_channels, w * 缩放因子, h * 缩放因子) return output- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
-
ResidualBlock类残差块包含两个卷积块,并通过一个跳跃连接(residual connection)将输入直接添加到输出。这种设计有助于解决深度神经网络中的梯度消失问题,并允许网络学习更有效的特征表示。在这个类中,第一个卷积块后面跟着PReLU激活函数,而第二个卷积块后面没有激活函数。
class ResidualBlock(nn.Module): """ 一个残差块,包含两个卷积块并通过残差连接。 """ def __init__(self, kernel_size=3, n_channels=64): """ :param kernel_size: 卷积核大小 :param n_channels: 输入和输出通道数(相同,因为输入必须加到输出上) """ super(ResidualBlock, self).__init__() # 第一个卷积块 self.conv_block1 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size, batch_norm=True, activation='PReLu') # 第二个卷积块 self.conv_block2 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size, batch_norm=True, activation=None) def forward(self, input): """ 前向传播。 :param input: 输入图像,尺寸为 (N, n_channels, w, h) 的张量 :return: 输出图像,尺寸为 (N, n_channels, w, h) 的张量 """ residual = input # (N, n_channels, w, h) output = self.conv_block1(input) # (N, n_channels, w, h) output = self.conv_block2(output) # (N, n_channels, w, h) output = output + residual # (N, n_channels, w, h) return output- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
-
SRResNet类这个类定义了整个SRResNet模型的结构。它由几个主要部分组成:第一个卷积块、一系列残差块、另一个卷积块、多个子像素卷积块,以及最后一个卷积块。这个模型接受低分辨率图像作为输入,并输出高分辨率图像。在初始化函数中,它设置了模型的参数,如卷积核大小、通道数、残差块数量和上采样因子。在前向传播中,它将输入图像通过定义好的层序列进行处理,并输出最终的超分辨率图像。
class SRResNet(nn.Module): """ SRResNet,如论文中定义的。 """ def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=4): """ :param large_kernel_size: 输入和输出转换时的第一个和最后一个卷积的卷积核大小 :param small_kernel_size: 所有中间卷积的卷积核大小,即残差块和小像素卷积块中的卷积 :param n_channels: 中间通道数,即残差块和小像素卷积块的输入和输出通道数 :param n_blocks: 残差块的数量 :param scaling_factor: 在小像素卷积块中沿两个维度缩放输入图像的因子 """ super(SRResNet, self).__init__() # 缩放因子必须是2、4或8 scaling_factor = int(scaling_factor) assert scaling_factor in {2, 4, 8}, "缩放因子必须是2、4或8!" # 第一个卷积块 self.conv_block1 = ConvolutionalBlock(in_channels=3, out_channels=n_channels, kernel_size=large_kernel_size, batch_norm=False, activation='PReLu') # 一系列残差块,每个块中包含一个跨块的跳跃连接 self.residual_blocks = nn.Sequential( *[ResidualBlock(kernel_size=small_kernel_size, n_channels=n_channels) for i in range(n_blocks)]) # 另一个卷积块 self.conv_block2 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels, kernel_size=small_kernel_size, batch_norm=True, activation=None) # 通过子像素卷积进行上采样,每个这样的块上采样因子为2 n_subpixel_convolution_blocks = int(math.log2(scaling_factor)) self.subpixel_convolutional_blocks = nn.Sequential( *[SubPixelConvolutionalBlock(kernel_size=small_kernel_size, n_channels=n_channels, scaling_factor=2) for i in range(n_subpixel_convolution_blocks)]) # 最后一个卷积块 self.conv_block3 = ConvolutionalBlock(in_channels=n_channels, out_channels=3, kernel_size=large_kernel_size, batch_norm=False, activation='Tanh') def forward(self, lr_imgs): """ 前向传播。 :param lr_imgs: 低分辨率输入图像,尺寸为 (N, 3, w, h) 的张量 :return: 超分辨率输出图像,尺寸为 (N, 3, w * 缩放因子, h * 缩放因子) 的张量 """ output = self.conv_block1(lr_imgs) # (N, 3, w, h) residual = output # (N, n_channels, w, h) output = self.residual_blocks(output) # (N, n_channels, w, h) output = self.conv_block2(output) # (N, n_channels, w, h) output = output + residual # (N, n_channels, w, h) output = self.subpixel_convolutional_blocks(output) # (N, n_channels, w * 缩放因子, h * 缩放因子) sr_imgs = self.conv_block3(output) # (N, 3, w * 缩放因子, h * 缩放因子) return sr_imgs- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
2.3 SRGAN
SRGAN(Super-Resolution Generative Adversarial Network)模型是基于生成对抗网络(GAN)的框架,专门用于图像超分辨率任务。SRGAN的目标是将低分辨率(Low-Resolution, LR)图像转换为高分辨率(High-Resolution, HR)图像,同时保持或增强图像的细节和质量。
-
Generator类这是SRGAN中的生成器部分,它的架构与SRResNet相同。生成器的目标是将低分辨率图像上采样并生成高分辨率图像。
class Generator(nn.Module): """ SRGAN中的生成器,与论文中定义的SRResNet架构相同。 """ def __init__(self, config): # 初始化函数 super(Generator, self).__init__() # 从配置中获取生成器的参数 n_channels = config.G.n_channels # 生成器中的通道数 n_blocks = config.G.n_blocks # 残差块的数量 large_kernel_size = config.G.large_kernel_size # 生成器中卷积层的大核大小 small_kernel_size = config.G.small_kernel_size # 生成器中卷积层的小核大小 scaling_factor = config.scaling_factor # 上采样因子 # 生成器实际上是一个SRResNet self.net = SRResNet(large_kernel_size=large_kernel_size, small_kernel_size=small_kernel_size, n_channels=n_channels, n_blocks=n_blocks, scaling_factor=scaling_factor) def initialize_with_srresnet(self, srresnet_checkpoint): """ 初始化生成器,使用预训练的SRResNet权重。 :param srresnet_checkpoint: 预训练模型的检查点文件路径 """ # 加载预训练模型 srresnet = torch.load(srresnet_checkpoint)['model'] # 将预训练权重加载到生成器中 self.net.load_state_dict(srresnet.state_dict()) # 打印加载权重的信息 print("\n已加载预训练SRResNet的权重。\n") def forward(self, lr_imgs): """ 前向传播。 :param lr_imgs: 低分辨率输入图像,尺寸为 (N, 3, w, h) 的张量 :return: 超分辨率输出图像,尺寸为 (N, 3, w * 上采样因子, h * 上采样因子) 的张量 """ # 通过生成器网络进行前向传播 sr_imgs = self.net(lr_imgs) # (N, n_channels, w * 上采样因子, h * 上采样因子) return sr_imgs # 返回超分辨率图像- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
-
Discriminator类这是SRGAN中的鉴别器部分,用于区分生成的高分辨率图像和真实的高分辨率图像。鉴别器通过一系列卷积层和全连接层来提取特征并进行分类。
class Discriminator(nn.Module): """ SRGAN中的鉴别器,与论文中定义的架构相同。 """ def __init__(self, config): # 初始化函数 super(Discriminator, self).__init__() # 从配置中获取鉴别器的参数 kernel_size = config.D.kernel_size # 卷积核大小 n_channels = config.D.n_channels # 通道数 n_blocks = config.D.n_blocks # 卷积块的数量 fc_size = config.D.fc_size # 全连接层的大小 in_channels = 3 # 输入通道数 # 一系列卷积块 # 奇数卷积块增加通道数但保持图像大小不变 # 偶数卷积块保持通道数不变但将图像大小减半 # 第一个卷积块特殊,因为它不使用批量归一化 conv_blocks = list() for i in range(n_blocks): out_channels = (n_channels if i is 0 else in_channels * 2) if i % 2 is 0 else in_channels conv_blocks.append( ConvolutionalBlock(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=1 if i % 2 is 0 else 2, batch_norm=i is not 0, activation='LeakyReLu')) in_channels = out_channels # 更新通道数 self.conv_blocks = nn.Sequential(*conv_blocks) # 将卷积块序列化为一个模型 # 一个自适应池化层,将输出调整为标准大小 # 对于默认输入大小96和8个卷积块,这不会有任何效果 self.adaptive_pool = nn.AdaptiveAvgPool2d((6, 6)) self.fc1 = nn.Linear(out_channels * 6 * 6, fc_size) # 全连接层 self.leaky_relu = nn.LeakyReLU(0.2) # LeakyReLU激活函数 self.fc2 = nn.Linear(1024, 1) # 最后一个全连接层 # 不需要sigmoid层,因为sigmoid操作由PyTorch的nn.BCEWithLogitsLoss()执行() def forward(self, imgs): """ 前向传播。 :param imgs: 需要被分类为高分辨率或超分辨率图像的张量,尺寸为 (N, 3, w * 上采样因子, h * 上采样因子) :return: 高分辨率图像的得分(logit),尺寸为 (N,) """ batch_size = imgs.size(0) # 获取批量大小 output = self.conv_blocks(imgs) # 通过卷积块进行前向传播 output = self.adaptive_pool(output) # 通过自适应池化层 output = self.fc1(output.view(batch_size, -1)) # 通过第一个全连接层 output = self.leaky_relu(output) # 通过LeakyReLU激活函数 logit = self.fc2(output) # 通过第二个全连接层获取logit return logit # 返回logit- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
-
TruncatedVGG19类这是一个截断的VGG19模型,用于计算生成器和鉴别器之间的感知损失。它通过截断VGG19网络的一部分来实现,只使用到指定的卷积层和激活函数。这个类通常用于实现感知损失,通过比较生成的图像和真实图像在VGG19网络中的特征来评估图像质量。
class TruncatedVGG19(nn.Module): """ 截断的VGG19模型,用于生成器和鉴别器之间的感知损失计算。 """ def __init__(self, i, j, weights_path): # 初始化函数 super(TruncatedVGG19, self).__init__() # 加载预训练的VGG19模型 vgg19 = torchvision.models.vgg19(pretrained=False) maxpool_counter = 0 # 最大池化层计数器 conv_counter = 0 # 卷积层计数器 truncate_at = 0 # 截断点 # 遍历VGG19的卷积部分("features") for layer in vgg19.features.children(): truncate_at += 1 # 计算每个最大池化层后的最大池化层和卷积层的数量 if isinstance(layer, nn.Conv2d): conv_counter += 1 if isinstance(layer, nn.MaxPool2d): maxpool_counter += 1 conv_counter = 0 # 如果达到第i个最大池化后的第j个卷积层,则中断 if maxpool_counter == i - 1 and conv_counter == j: break # 检查条件是否满足 assert maxpool_counter == i - 1 and conv_counter == j, "VGG19的i=%d和j=%d的选择无效!" % (i, j) # 截断到第i个最大池化前的第j个卷积层(+激活) self.truncated_vgg19 = nn.Sequential(*list(vgg19.features.children())[:truncate_at + 1]) # 加载本地预训练权重 state_dict = torch.load(weights_path, map_location=torch.device('cuda')) self.truncated_vgg19.load_state_dict(state_dict, strict=False) # 冻结截断VGG19的参数 for param in self.truncated_vgg19.parameters(): param.requires_grad = False def forward(self, input): """ 前向传播。 :param input: 输入图像,尺寸为 (N, feature_map_channels, feature_map_w, feature_map_h) 的张量 :return: 输出特征图 """ # 通过截断的VGG19模型进行前向传播 output = self.truncated_vgg19(input) # (N, feature_map_channels, feature_map_w, feature_map_h) return output # 返回输出特征图- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
3 项目训练
3.1 环境配置
本次训练依然是通过云平台进行训练,采用 GPU Pytorch1.6 Tensorflow 2.3.0 Python 3.8.5 官方镜像,挂载 Work 目录,使用 T4 GPU 进行训练。
在 train.ipynb 中执行以下指令,安装相应依赖库。
!pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
!pip install easydict
- 1
- 2
3.2 数据集构造
本实验训练集使用 DIV2K 数据集[2],包含有800张2K左右高分辨率的图像和 800 张对应的低分辨率图像;测试集使用 DIV2K 验证集[2]、 Set5 、 Set14 、 B100 、 Urban 100五个数据集,分别包括高分辨率图像和对应的低分辨率图像。训练集和测试集中的所有低分辨图像都是由高分辨率图像下采样得到,下采样方法为使用 Matlab 中的 resize 函数, scalefactor 为 0.25 ,其余为默认参数(双三次插值)。
实验下载的数据集均为高清图像,需要通过 create_data_lists.py 生成案例训练测试所需要的 csv 文件与低分辨图像。
data_root = "/home/mw/input/dataset76853/"
output_folder = '/home/mw/project/SRDataset'
if not osp.exists(output_folder):
os.makedirs(output_folder)
# train images folder
train_HR_folder = data_root + 'DIV2K_train_HR/DIV2K_train_HR'
train_LR_folder = data_root + 'DIV2K_train_HR/DIV2K_train_LR_bicubic/X4'
# valid images folder
valid_HR_folder = data_root + 'DIV2K_valid_HR/DIV2K_valid_HR'
valid_LR_folder = data_root + 'DIV2K_valid_HR/DIV2K_valid_LR_bicubic/X4'
# test images folder
test_Set5_HR_folder = data_root + 'benchmark/benchmark/Set5/HR'
test_Set5_LR_folder = data_root + 'benchmark/benchmark/Set5/LR_bicubic/X4'
test_Set14_HR_folder = data_root + 'benchmark/benchmark/Set14/HR'
test_Set14_LR_folder = data_root + 'benchmark/benchmark/Set14/LR_bicubic/X4'
test_B100_HR_folder = data_root + 'benchmark/benchmark/B100/HR'
test_B100_LR_folder = data_root + 'benchmark/benchmark/B100/LR_bicubic/X4'
test_Urban100_HR_folder = data_root + 'benchmark/benchmark/Urban100/HR'
test_Urban100_LR_folder = data_root + 'benchmark/benchmark/Urban100/LR_bicubic/X4'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
修改代码地址,运行该文件,得到以下csv文件,并生成对应的低分辨图像。
3.3 SSResNet模型训练
本次训练通过修改 train.ipynb 来训练 SSResNet ,构建一个新的 train_ssresnet.ipynb 。
-
训练参数
本次训练采用了20轮的训练,学习率为
1e-4,其他采用默认参数,修改相应路径后,完成参数的配置。# config config = edict() config.csv_folder = '/home/mw/project/SRDataset' config.HR_data_folder = '/home/mw/input/dataset76853/DIV2K_train_HR/DIV2K_train_HR' config.LR_data_folder = '/home/mw/input/dataset76853/DIV2K_train_LR_bicubic_X4/DIV2K_train_LR_bicubic/X4' config.crop_size = 96 config.scaling_factor = 4 # Model parameters large_kernel_size = 9 # kernel size of the first and last convolutions which transform the inputs and outputs small_kernel_size = 3 # kernel size of all convolutions in-between, i.e. those in the residual and subpixel convolutional blocks n_channels = 64 # number of channels in-between, i.e. the input and output channels for the residual and subpixel convolutional blocks n_blocks = 16 # number of residual blocks # Learning parameters config.checkpoint = None # path to model checkpoint, None if none config.batch_size = 16 # batch size config.start_epoch = 0 # start at this epoch config.epochs = 20 config.workers = 4 config.beta = 1e-3 # the coefficient to weight the adversarial loss in the perceptual loss config.print_freq = 50 config.lr = 1e-4 config.grad_clip = None # clip if gradients are exploding # Default device config.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") cudnn.benchmark = True- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
如果要接着之前的训练结果继续训练,可以通过修改过
config.checkpoint路径,与开始结束的 epoch,从保存的模型文件继续训练。 -
模型初始化
利用以上配置文件,通过选择从头开始训练还是继续训练,创建 SSResNet 模型
model。模型采用 Adam 优化器。if config.checkpoint is None: model = SRResNet(large_kernel_size=large_kernel_size, small_kernel_size=small_kernel_size, n_channels=n_channels, n_blocks=n_blocks, scaling_factor=config.scaling_factor) # Initialize the optimizer optimizer = torch.optim.Adam(params=filter(lambda p: p.requires_grad, model.parameters()), lr=config.lr) else: checkpoint = torch.load(config.checkpoint) start_epoch = checkpoint['epoch'] + 1 model = checkpoint['model'] optimizer = checkpoint['optimizer']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
将模型部署到设备上,采用 MSE 作为损失函数。
# Move to default device model = model.to(config.device) criterion = nn.MSELoss().to(config.device)- 1
- 2
- 3
加载训练数据集。
# Custom dataloaders train_dataset = SRDataset(split='train', config=config) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True, num_workers=config.workers, pin_memory=True) # note that we're passing the collate function here- 1
- 2
- 3
- 4
-
模型训练
通过
train()训练,加载数据、执行模型训练、计算损失和更新模型权重。通过这种方式,模型在每个训练周期中逐渐学习如何将低分辨率图像转换为高分辨率图像。def train(train_loader, model, criterion, optimizer, epoch): """ One epoch's training. :param train_loader: DataLoader for training data :param model: model :param criterion: content loss function (Mean Squared-Error loss) :param optimizer: optimizer :param epoch: epoch number """ model.train() # training mode enables batch normalization batch_time = AverageMeter() # forward prop. + back prop. time data_time = AverageMeter() # data loading time losses = AverageMeter() # loss start = time.time() # Batches for i, (lr_imgs, hr_imgs) in enumerate(train_loader): data_time.update(time.time() - start) # Move to default device lr_imgs = lr_imgs.to(config.device) # (batch_size (N), 3, 24, 24), imagenet-normed hr_imgs = hr_imgs.to(config.device) # (batch_size (N), 3, 96, 96), in [-1, 1] # Forward prop. sr_imgs = model(lr_imgs) # (N, 3, 96, 96), in [-1, 1] # Loss loss = criterion(sr_imgs, hr_imgs) # scalar # Backward prop. optimizer.zero_grad() loss.backward() # Update model optimizer.step() # Keep track of loss losses.update(loss.item(), lr_imgs.size(0)) # Keep track of batch time batch_time.update(time.time() - start) # Reset start time start = time.time() # Print status if i % config.print_freq == 0: print('Epoch: [{0}][{1}/{2}]----' 'Batch Time {batch_time.val:.3f} ({batch_time.avg:.3f})----' 'Data Time {data_time.val:.3f} ({data_time.avg:.3f})----' 'Loss {loss.val:.4f} ({loss.avg:.4f})'.format(epoch, i, len(train_loader), batch_time=batch_time, data_time=data_time, loss=losses)) del lr_imgs, hr_imgs, sr_imgs # free some memory since their histories may be stored- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
建立 for 循环,进行制定轮次的训练。
# Epochs for epoch in range(config.start_epoch, config.epochs): # One epoch's training train(train_loader=train_loader, model=model, criterion=criterion, optimizer=optimizer, epoch=epoch) # Save checkpoint torch.save({'epoch': epoch, 'model': model, 'optimizer': optimizer}, 'checkpoint_srresnet.pth.tar')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
训练结果
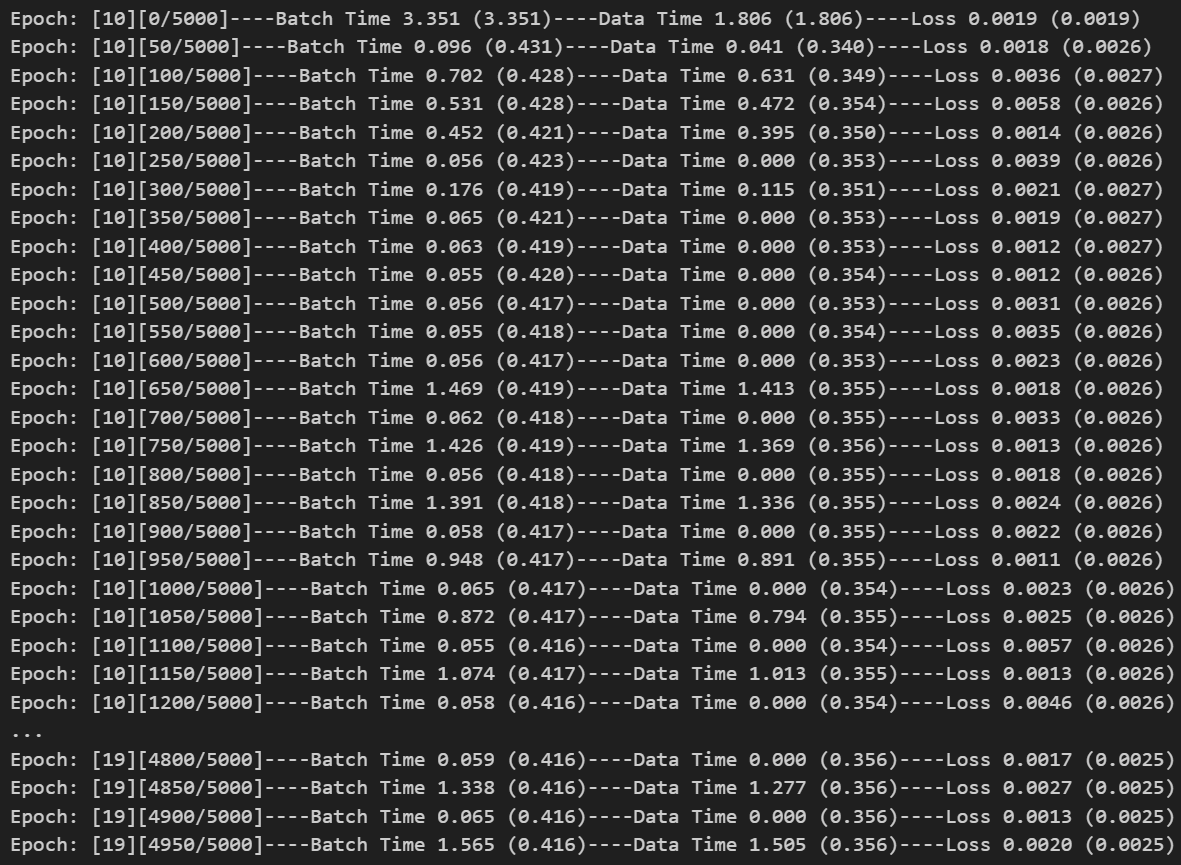
本次训练在云平台分了两次训练,每次分别训练了10个epoch,总训练时长将近12个小时。

从结果可以看到,Loss值一直处于一个很低的值波动,可能有出现过拟合的现象。
3.4 SRGAN模型训练
SRGAN 训练需要训练过的 SRResNet 模型用来初始化 SRGAN 的生成器。
-
参数设置
本次训练采用了20轮的训练,学习率为
1e-4,其他采用默认参数,修改相应路径后,完成参数的配置。# config config = edict() config.csv_folder = '/home/mw/project/SRDataset' config.HR_data_folder = '/home/mw/input/dataset76853/DIV2K_train_HR/DIV2K_train_HR' config.LR_data_folder = '/home/mw/input/dataset76853/DIV2K_train_LR_bicubic_X4/DIV2K_train_LR_bicubic/X4' config.crop_size = 96 config.scaling_factor = 4 # Generator parameters config.G = edict() config.G.large_kernel_size = 9 config.G.small_kernel_size = 3 config.G.n_channels = 64 config.G.n_blocks = 16 srresnet_checkpoint = "/home/mw/project/checkpoint_srresnet.pth.tar" # Discriminator parameters config.D = edict() config.D.kernel_size = 3 config.D.n_channels = 64 config.D.n_blocks = 8 config.D.fc_size = 1024 # Learning parameters config.checkpoint = None # path to model (SRGAN) checkpoint, None if none config.batch_size = 16 config.start_epoch = 0 config.epochs = 20 config.workers = 4 config.vgg19_i = 5 # the index i in the definition for VGG loss; see paper config.vgg19_j = 4 # the index j in the definition for VGG loss; see paper config.beta = 1e-3 # the coefficient to weight the adversarial loss in the perceptual loss config.print_freq = 50 config.lr = 1e-4 # Default device config.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") cudnn.benchmark = True- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
-
模型初始化
利用以上配置文件,通过选择从头开始训练还是继续训练,创建 SRGAN 模型的生成器和鉴别器。模型采用 Adam 优化器。
if config.checkpoint is None: # Generator generator = Generator(config) generator.initialize_with_srresnet(srresnet_checkpoint=srresnet_checkpoint) # Initialize generator's optimizer optimizer_g = torch.optim.Adam(params=filter(lambda p: p.requires_grad, generator.parameters()), lr=config.lr) # Discriminator discriminator = Discriminator(config) optimizer_d = torch.optim.Adam(params=filter(lambda p: p.requires_grad, discriminator.parameters()), lr=config.lr) else: checkpoint = torch.load(config.checkpoint) config.start_epoch = checkpoint['epoch'] + 1 generator = checkpoint['generator'] discriminator = checkpoint['discriminator'] optimizer_g = checkpoint['optimizer_g'] optimizer_d = checkpoint['optimizer_d'] print("\nLoaded checkpoint from epoch %d.\n" % (checkpoint['epoch'] + 1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
将截断的 VGG19 网络用于损失计算,以免每次训练都需要重新下载 VGG19 预训练模型,我选择将模型下载好放入work文件夹里。
# Truncated VGG19 network to be used in the loss calculation weights_path = '/home/mw/work/work_dir/vgg19-dcbb9e9d.pth' truncated_vgg19 = TruncatedVGG19(i=config.vgg19_i, j=config.vgg19_j, weights_path = weights_path) truncated_vgg19.eval()- 1
- 2
- 3
- 4
采用 MSE 作为内容损失函数,二元交叉熵与 logits 结合作为对抗损失函数。
# Loss functions content_loss_criterion = nn.MSELoss() adversarial_loss_criterion = nn.BCEWithLogitsLoss()- 1
- 2
- 3
加载训练数据集。
# Custom dataloaders train_dataset = SRDataset(split='train', config=config) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True, num_workers=config.workers, pin_memory=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
模型训练
通过
solver.py的train()进行指定轮次的训练,每50个条目打印一次训练结果,包括轮次Eopch、批次处理时间Batch Time,加载批次所需时间Data Time,内容损失Cont.Loss,对抗损失Adv.Loss与鉴别器损失Disc.Loss。# Epochs for epoch in range(config.start_epoch, config.epochs): # At the halfway point, reduce learning rate to a tenth if epoch == int(config.epochs / 2 + 1): adjust_learning_rate(optimizer_g, 0.1) adjust_learning_rate(optimizer_d, 0.1) # One epoch's training train(train_loader=train_loader, generator=generator, discriminator=discriminator, truncated_vgg19=truncated_vgg19, content_loss_criterion=content_loss_criterion, adversarial_loss_criterion=adversarial_loss_criterion, optimizer_g=optimizer_g, optimizer_d=optimizer_d, epoch=epoch, device=config.device, beta=config.beta, print_freq=config.print_freq) # Save checkpoint torch.save({'epoch': epoch, 'generator': generator, 'discriminator': discriminator, 'optimizer_g': optimizer_g, 'optimizer_d': optimizer_d}, 'checkpoint_srgan.pth.tar')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
-
训练结果
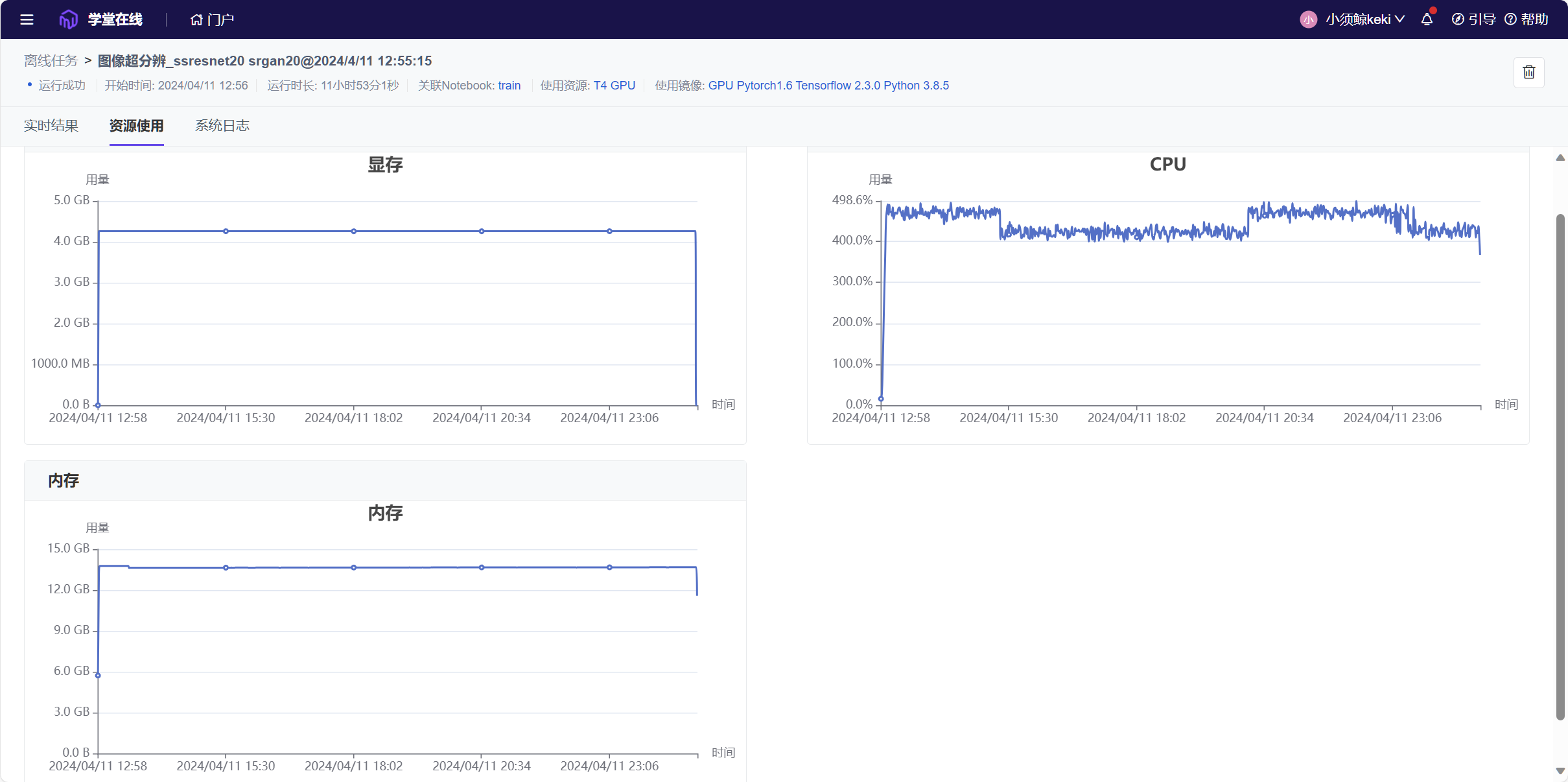
本次训练在云平台进行离线训练,训练20轮次,总训练时长将近12个小时。
训练结果如下。
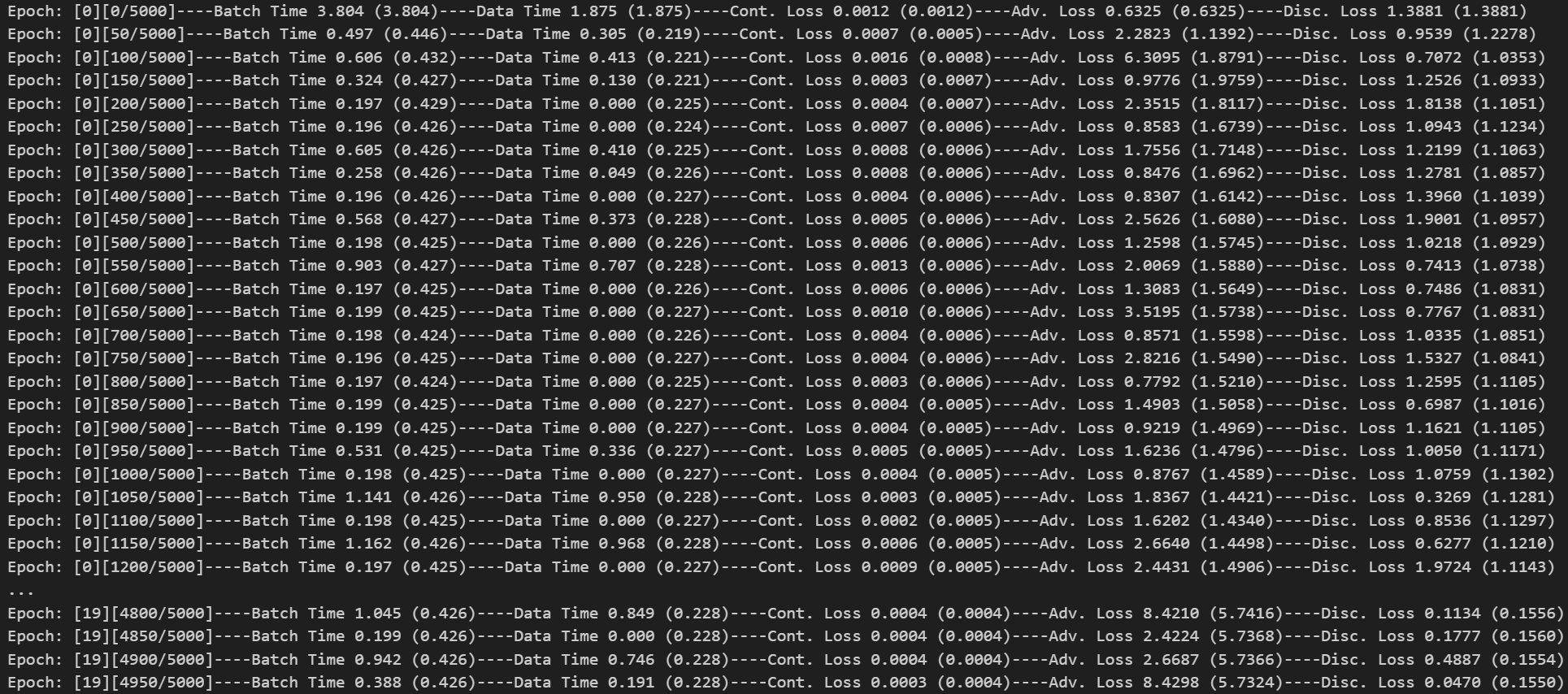
可以看到,模型经过长时间的训练,内容损失
Cont.Loss已经降低到很低的水平,反而对抗损失Adv.Loss却增高不少,鉴别器损失Disc.Loss也有所下降。说明模型正在学习更好地重建高分辨率图像的细节,但是生成器生成的图像质量较差。可能出现了过拟合现象。
4 项目测试
4.1 测试模型PSNR与SSIM值
-
PSNR与SSIM值
PSNR(Peak Signal-to-Noise Ratio,峰值信噪比)和 SSIM(Structural Similarity Index,结构相似性指数)是两种常用的图像质量评估指标,它们在图像处理和计算机视觉领域中用于衡量图像之间的相似性和质量。
-
PSNR(峰值信噪比)
PSNR 是一种基于均方误差(MSE,Mean Squared Error)的图像质量评价指标。MSE 计算两个图像之间的像素级差异的平方的平均值。PSNR 通过将 MSE 与图像的最大可能变化(即信号的最大值与最小值之间的差异)进行比较来衡量图像质量。PSNR 的计算公式如下:
P S N R = 10 ⋅ log 10 ( M A X I 2 M S E ) PSNR = 10 \cdot \log_{10} \left( \frac{MAX_I^2}{MSE} \right) PSNR=10⋅log10(MSEMAXI2)
其中,$ MAX_I $ 是图像可能的最大像素值(例如,对于 8 位图像,$ MAX_I = 255 $), M S E MSE MSE 是两个图像之间的均方误差。PSNR 的值越高,表示两个图像之间的差异越小,通常意味着更好的图像质量。然而,PSNR 主要关注像素级别的差异,可能无法准确反映人眼对图像质量的感知。
-
SSIM(结构相似性指数)
SSIM 是一种更先进的图像质量评价指标,它不仅考虑像素级别的差异,还考虑图像的结构信息。SSIM 通过比较两个图像的亮度、对比度和结构相似性来评估图像质量。SSIM 的计算公式较为复杂,涉及图像的局部区域,并考虑以下三个成分:
- 亮度比较(Luminance Comparison):比较两个图像的亮度均值。
- 对比度比较(Contrast Comparison):比较两个图像的对比度。
- 结构比较(Structure Comparison):比较两个图像的空间结构。
SSIM 的值范围在 0 到 1 之间,其中 1 表示两个图像完全相同,0 表示没有任何相似性。SSIM 更接近于人眼对图像质量的感知,因此在评估图像质量时通常比 PSNR 更为准确和可靠。
-
-
测试结果
通过运行
test.ipynb,测试多个训练的模型,在不同数据集上的PSNR与SSIM值。-
训练10轮的SSResNet
Set5 Set14 B100 Urban100 valid PSNR 8.455 9.588 8.713 9.037 7.840 SSIM 0.507 0.476 0.413 0.445 0.468 -
训练10轮的SRGAN
Set5 Set14 B100 Urban100 valid PSNR 11.928 13.235 13.435 12.385 12.491 SSIM 0.208 0.210 0.206 0.186 0.234 -
在训练10轮的SSResNet基础上,训练20轮的SRGAN
Set5 Set14 B100 Urban100 valid PSNR 19.863 19.130 19.491 17.500 20.813 SSIM 0.579 0.492 0.426 0.455 0.573 -
训练20轮的SSResNet
Set5 Set14 B100 Urban100 valid PSNR 15.881 16.173 16.501 15.129 15.824 SSIM 0.660 0.608 0.566 0.564 0.635 -
在训练20轮的SSResNet基础上,训练20轮的SRGAN
Set5 Set14 B100 Urban100 valid PSNR 20.480 20.490 20.780 18.871 21.118 SSIM 0.613 0.537 0.496 0.498 0.590
可以看到,SRGAN的训练结果明显比SSResNet更好,并且在多轮SSResNet训练模型基础上训练的SRGAN结果更好。
-
4.2 图像超分辨测试
-
猩猩图像测试
这是高清分辨率,尺寸为500×480的原始图像。

这是该图像降低4倍分辨率,尺寸为125×120的图像。

下面给出不同训练模型对该低分辨率图像放大后的结果。
-
SRGAN_10epoch
下面是不采用 SSResNet 作为基础模型,训练10轮的 SRGAN 的超分辨得到的图像。

可以看出,在没有SSResNet作为基础模型的情况下,训练结果十分糟糕。
-
SSResNet_10epoch
下面是训练10轮 SSResNet 的模型超分辨得到的图像。

可以看出,训练10轮的 SSResNet 训练结果相比于 SRGAN 好一些,但是也很糟糕。
-
SSResNet10_SRGAN20
下面是以训练10轮 SSResNet 的模型为基础,训练20轮的 SRGAN 的模型超分辨得到的图像。

相比于训练10轮的 SSResNet ,这个效果明显更好了。
-
SSResNet_20epoch
下面是训练20轮 SSResNet 的模型超分辨得到的图像。

随着训练轮次的增加,图像超分辨的效果有着明显提升。
-
SSResNet20_SRGAN20
下面是以训练20轮 SSResNet 的模型为基础,训练20轮的 SRGAN 的模型超分辨得到的图像。

可以看出,模型对色彩还原的更好,但是会出现彩虹纹等效果。
-
-
Set5 图像测试
这里选取 SSResNet20_SRGAN20 这组训练模型,进行图像测试。
-
baby图像测试结果
-
bird图像测试结果
-
butterfly图像测试结果
-
head图像测试结果
-
woman图像测试结果
-
从以上测试可以看出,最终模型训练的效果并不是那么令人满意。通过github找到的预训练模型[6]效果非常不错,如下图所示,未达到以下结果可能是超参数还需调节,或者训练轮次不够。


