
- 1计算机视觉(AI)面试大全_计算机视觉面试题
- 2html网页制作之简单登入界面_html表格登录界面
- 3AI CC呼叫中心源码_ai呼叫中心源代码
- 4详细讲解axios封装与api接口封装管理_axios api封装
- 5[SQL挖掘机] - 日期函数 - current_date
- 6用实例带你快速玩转git_玩转 git
- 7软件测试工程师应该学Python还是学Java?_电子产品测试学什么语言
- 8RocketMq-主从集群搭建_rocketmq 主从配置
- 9Java 函数方法指南:如何获取给定日期的月份最后一天_java获取指定时间字符串的月份最后一天
- 10树莓派4B 六个串口的开启与使用_raspberry uart3
清华提出ACmix:自注意力和CNN的融合!性能速度全面提升!
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童

On the Integration of Self-Attention and Convolution
论文:https://arxiv.org/abs/2111.14556
代码(即将开源):https://github.com/Panxuran/ACmix
Convolution和Self-Attention是两种强大的表征学习方法,它们通常被认为是两种彼此不同的方法。
在本文中证明了它们之间存在着很强的潜在关系,因为这两个方法的大部分计算实际上是用相同的操作完成的。具体来说:
首先,证明了具有卷积可以分解成个独立的卷积;
然后,进行移位和求和操作;
再然后,将Self-Attention模块中的query、key和value的投影解释为多个卷积,然后计算注意力权重和value的聚合。
因此,两个模块的第一阶段都包含了类似的操作。更重要的是,与第二阶段相比,第一阶段的计算复杂度(通道的平方)占主导地位。
这个观察结果自然地导致了这两个看似不同的范式的优雅集成,即,一个混合模型,它既兼顾Self-Attention和Convolution的优点,同时与Convolution或Self-Attention对应的模型相比,具有更小的计算开销。大量的实验表明,本文方法在图像识别和下游任务上取得了持续改进的结果。
1简介
近年来,卷积和Self-Attention在计算机视觉领域得到了长足的发展。卷积神经网络广泛应用于图像识别、语义分割和目标检测,并在各种基准上实现了最先进的性能。最近,随着Vision Transformer的出现,基于Self-Attention的模块在许多视觉任务上取得了与CNN对应模块相当甚至更好的表现。
尽管这两种方法都取得了巨大的成功,但卷积和Self-Attention模块通常遵循不同的设计范式。传统卷积根据卷积的权值在局部感受野上利用一个聚合函数,这些权值在整个特征图中共享。固有的特征为图像处理带来了至关重要的归纳偏差。
相比之下,Self-Attention模块采用基于输入特征上下文的加权平均操作,通过相关像素对之间的相似函数动态计算注意力权重。这种灵活性使注意力模块能够适应地关注不同的区域,并捕捉更多的特征。
考虑到卷积和Self-Attention的不同和互补性质,通过集成这些模块,存在从两种范式中受益的潜在可能性。先前的工作从几个不同的角度探讨了Self-Attention和卷积的结合。
早期的研究,如SENet、CBAM,表明Self-Attention可以作为卷积模块的增强。最近,Self-Attention被提出作为独立的块来替代CNN模型中的传统卷积,如SAN、BoTNet。
另一种研究侧重于将Self-Attention和卷积结合在单个Block中,如 AA-ResNet、Container,而该体系结构限于为每个模块设计独立的路径。因此,现有的方法仍然将Self-Attention和卷积作为不同的部分,并没有充分利用它们之间的内在关系。
在这篇论文中,作者试图揭示Self-Attention和卷积之间更为密切的关系。通过分解这两个模块的操作表明它们在很大程度上依赖于相同的卷积操作。作者基于这一观察结果开发了一个混合模型,名为ACmix,并以最小的计算开销优雅地集成了Self-Attention和卷积。
具体地说:
首先,通过使用卷积对输入特征进行映射,获得丰富的中间特征集;
然后,按照不同的模式(分别以Self-Attention方式和卷积方式)重用和聚合中间特征。
通过这种方式,ACmix既享受了两个模块的优点,又有效地避免了两次昂贵的投影操作。
主要贡献:
揭示了Self-Attention和卷积之间强大的潜在关系,为理解两个模块之间的联系提供了新的视角,并为设计新的学习范式提供了灵感;
介绍了Self-Attention和卷积模块的一个优雅集成,它享受这两者的优点。经验证据表明,混合模型始终优于其纯卷积或Self-Attention对应模型。
2相关工作
卷积神经网络使用卷积核提取局部特征,已经成为各种视觉任务中最强大和最常规的技术。同时,Self-Attention在BERT和GPT3等广泛的语言任务中也表现出普遍的表现。理论分析表明,当具有足够大的容量时,Self-Attention可以表示任意卷积层的函数类。因此,最近有一项研究探讨了将Self-Attention引入视觉任务的可能性。
主流方法有两种:
一种是将Self-Attention作为网络中的构建块;
另一种是将Self-Attention与卷积作为互补部分。
2.1 Self-Attention only
一些研究表明,Self-Attention可以成为完全替代卷积操作。最近,Vision Transformer表明,只要有足够的数据,就可以将图像视为由256个token组成的序列,并利用Transformer模型来实现图像识别中的竞争性结果。此外,在检测、分割、点云识别等视觉任务中采用了Transformer范式。
2.2 用注意力提升卷积
先前提出的多种图像注意力机制表明,它可以克服卷积网络局部性的局限性。因此,许多研究者探索使用注意力模块或利用更多的关系信息来增强卷积网络功能的可能性。
Squeeze-andExcitation(SE)和Gather-Excite(GE) Reweight每个通道的特征图。
BAM和CBAM Reweight 通道和空间位置,以更好地细化特征映射。
AA-ResNet通过连接来自另一个独立的Self-Attention的注意力map,增强了某些卷积层。
BoTNet用Self-Attention代替卷积。
一些工作旨在通过从更大范围的像素聚集信息,设计一个更灵活的特征提取器。Hu等人提出了一种局部关系方法,根据局部像素的组成关系自适应地确定聚集权值。Wang等人提出了Non-Local网络,通过引入全局像素之间相似性的Non-Local块来增加感受野。
2.3 用卷积提升注意力
随着Vision Transformer的问世,许多基于Transformer的变种已经被提出,并在计算机视觉任务上取得了显著的改进。其中已有的研究主要集中在对Transformer 模型进行卷积运算以引入额外的归纳偏差。
CvT在Token过程中采用卷积,并利用卷积来降低Self-Attention的计算复杂度。
ViT with convolutional stem提出在早期增加卷积以实现更稳定的训练。
CSwin Transformer采用了基于卷积的位置编码技术,并对下游任务进行了改进。
Conformer结合Transformer与一个独立的CNN模型集成这两个功能。
3旧知识回顾
3.1 卷积操作
卷积是现代ConvNets最重要的组成部分之一。首先回顾标准卷积运算,并从不同的角度重新表述它。如图2(a)所示。为简单起见,假设卷积的步长为1。
考虑一个的标准卷积,其中k为kernel size,、是输入和输出通道的大小。
已知输入张量和输出张量,其中H、W表示高度和宽度,让、作为像素分别对应于F和G。则标准卷积可表示为:
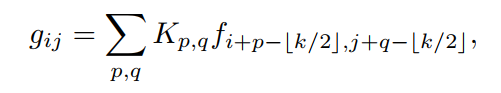
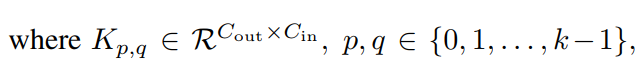
表示kernel position(p,q)的kernel weights。
为方便起见,可以将式(1)改写为来自不同kernel position的feature map的总和:

为了进一步简化公式,定义了Shift操作,
 as
as
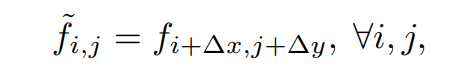
∆x、∆y为水平位移和垂直位移。则式(3)可改写为:
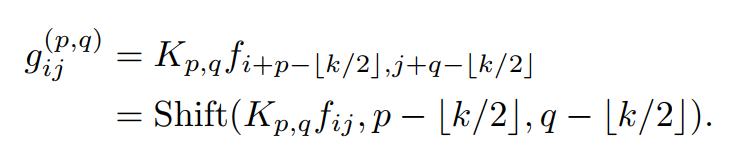
因此,标准卷积可以概括为2个stages:
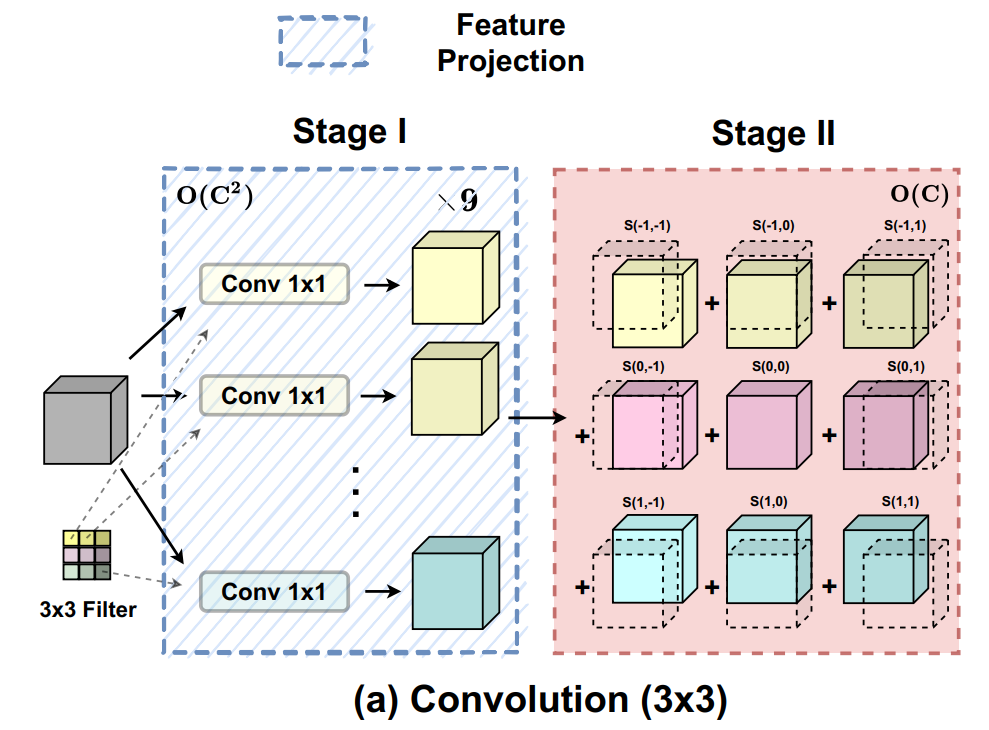
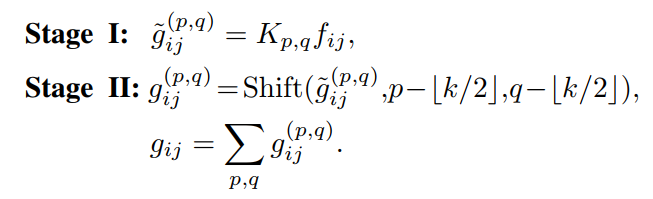
第一阶段:将输入的feature map从某一位置线性投影,这与标准的1×1卷积相同。
第二阶段:将投影的feature map根据kernel position进行移位,最终聚合到一起。可以很容易地观察到,大多数计算代价是在1×1卷积中执行的,而接下来的位移和聚合是轻量级的。
3.2 Self-Attention操作
注意力机制也被广泛应用于视觉任务中。与传统卷积相比,注意力允许模型在更大的范围内聚焦于重要区域。如图2(b)所示。
考虑一个有N个Head的标准Self-Attention模块。令输入张量和输出张量和,其中H、W表示高度和宽度,让、作为像素分别对应于F和G。然后,注意力模块的输出计算为:
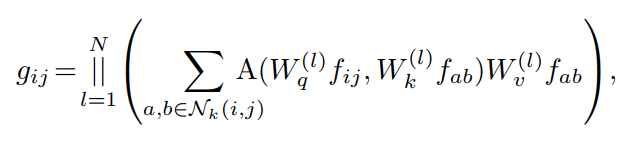
是N个注意力头输出的拼接,,,是query,key和value的投影矩阵。表示像素的局部区域,空间范围k以为中心,是对应于内特征的注意力权重。
对于广泛采用的自注意力模块,注意力权重的计算方法为:
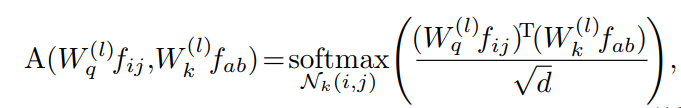
其中d为的特征维数。
此外,多头自注意力可以分解为两个阶段,并重新表述为:
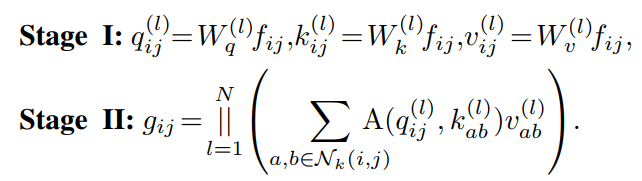
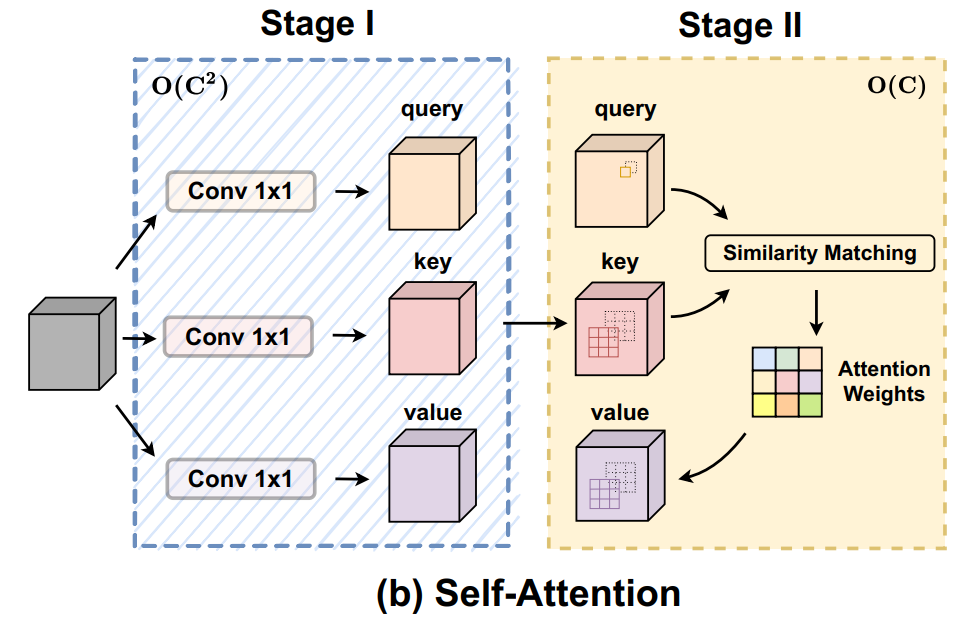
第一阶段:使用1×1卷积将输入特征投影为query、key和value;
第二阶段:包括注意力权重的计算和value矩阵的聚合,即聚集局部特征。与第一阶段相比,相应的计算代价较小,与卷积的模式相同。
3.3 Computational Cost
为了充分了解卷积模块和自注意力模块的计算瓶颈,作者分析了每个阶段的浮点运算(FLOPs)和参数数量,总结如表1所示。
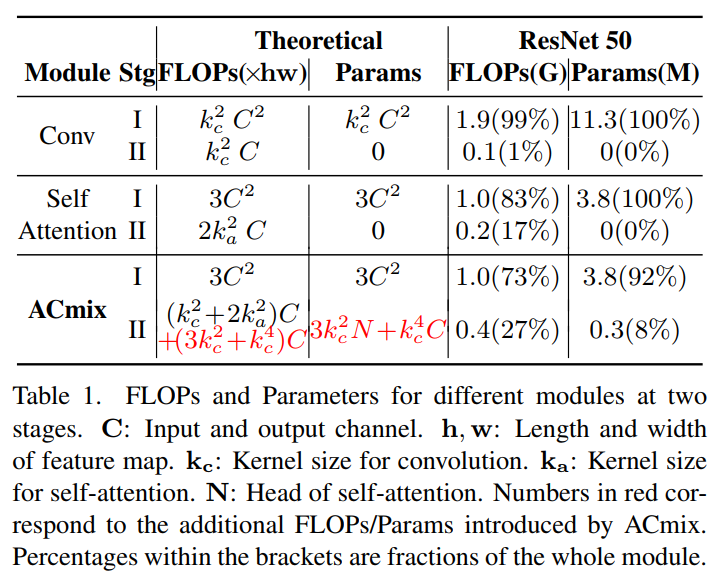
结果表明:
对于卷积模块:卷积阶段一的理论FLOPs和参数相对于通道大小C具有二次复杂度,而阶段二的计算代价为线性C,不需要额外的训练参数。
对于自注意力模块:发现了类似卷积的趋势,所有的训练参数都保留在阶段一。对于理论的FLOPs,考虑了一个正常的情况在一个类似ResNet的模型中,= 7和C=64,128,256,512不同的层深度。结果表明,第一阶段消耗的操作量为,并且这种差异随着通道大小的增长而更加明显。
为了进一步验证分析的有效性,作者还总结了在ResNet50模型中卷积和自注意力模块的实际计算成本。实际上,将所有3×3卷积模块的成本加起来,以从模型的角度反映这种趋势。计算结果表明,99%的卷积计算和83%的自注意力在第一阶段,与理论分析相一致。
4本文方法
4.1 将自注意力与卷积联系起来
前面介绍了对自注意力和卷积模块的分解,从多个角度揭示了更深层次的关系。首先,这两个阶段的作用非常相似。阶段一是一个特征学习模块,两种方法通过执行个卷积来将特征投射到更深的空间,从而共享相同的操作。另一方面,第二阶段对应的是特征聚合的过程。
从计算的角度来看,卷积模块和自注意力模块在第一阶段进行的1 × 1卷积都需要理论浮点数和通道大小参数的二次复杂度C。相比较而言,在第二阶段,两个模块都是轻量级的或几乎不需要计算。
综上所示,上述分析表明:
Convolution和self-attention在通过1×1 convolutions投影输入feature map的操作上实际上是相同的,这也是两个模块的计算开销;
虽然对于捕获语义特征至关重要,但第二阶段的聚合操作是轻量级的,不需要获取额外的学习参数。
4.2 自注意力与卷积的整合
上述的观察自然带来了卷积和自注意力的完美结合。由于两个模块共享相同的1×1卷积操作,因此只能执行一次投影,并将这些中间特征映射分别用于不同的聚合操作。于是本文作者提出了如图2(c)所示的混合模块ACmix。
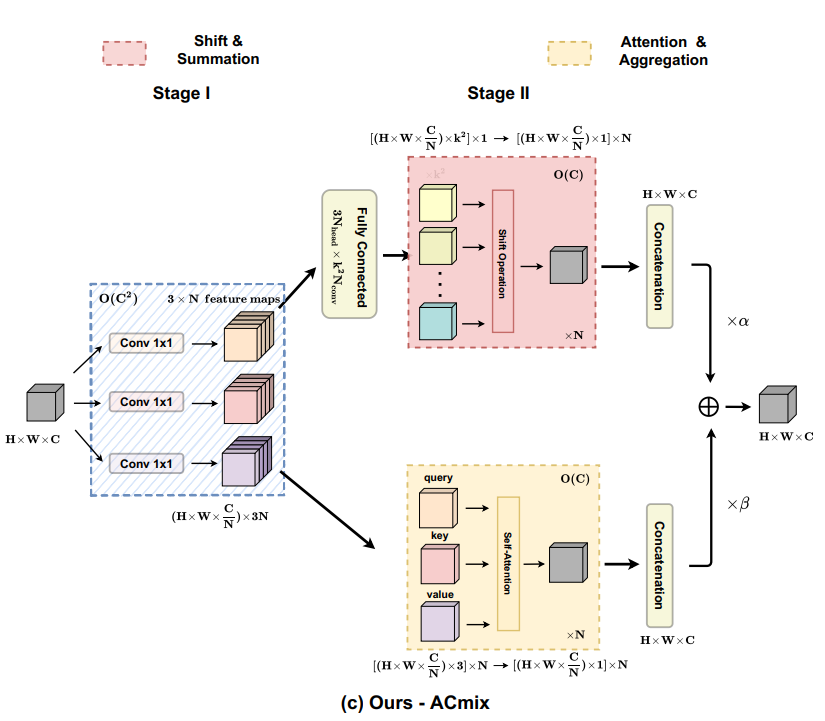
具体来说,ACmix依旧包括两个阶段:
在第一阶段:通过3个1×1卷积对输入特征进行投影,然后reshape为N个Pieces。因此,获得了包含3×N特征映射的一组丰富的中间特征。
在第二阶段:它们遵循不同的范例。对于自注意力路径,将中间特征集合到N组中,每组包含3个特征,每个特征来自1×1卷积。对应的三个特征图分别作为query、key和value,遵循传统的多头自注意力模块。对于kernel size为k的卷积路径,采用轻全连接层,生成个特征映射。因此,通过对生成的特征进行移位和聚合,对输入特征进行卷积处理,并像传统的一样从局部感受野收集信息。
最后,将两个路径的输出相加,其强度由两个可学习标量控制:
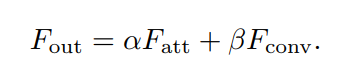
4.3 改进Shift和Summation
如图4.2节和图2所示,卷积路径中的中间特征遵循传统卷积模块中的移位和求和操作。尽管它们在理论上是轻量级的,但向不同方向移动张量实际上破坏了数据局部性,很难实现向量化实现。这可能会极大地损害了推理时的实际效率。
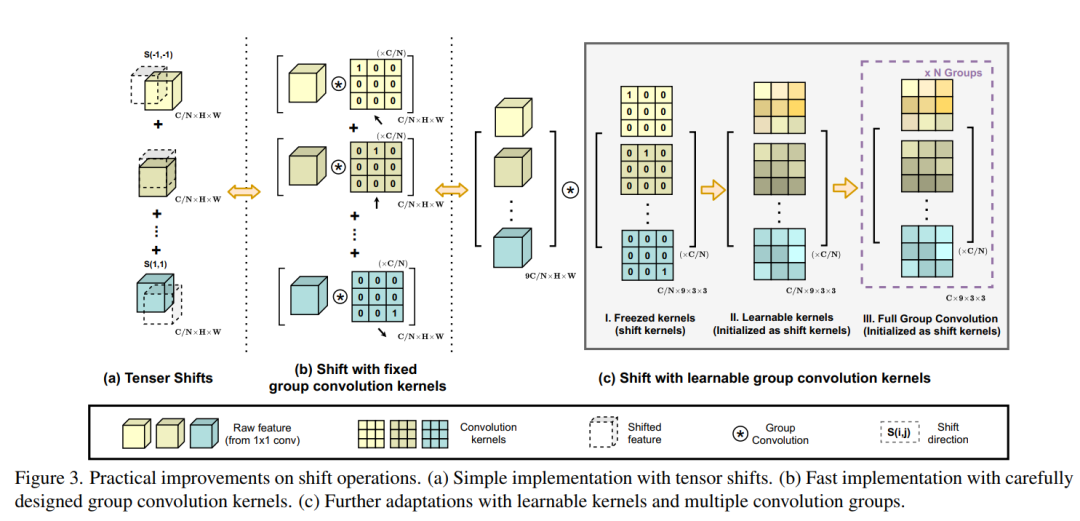
作为补救措施,采用固定kernel的深度卷积来代替低效张量位移,如图3 (b)所示。以移位特征为例,计算为:
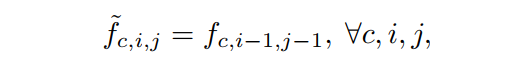
其中c表示每个输入特征的通道。
另一方面,如果表示卷积核(kernel size k = 3)为:
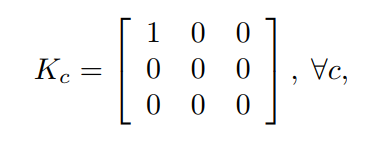
相应的输出可以表示为:
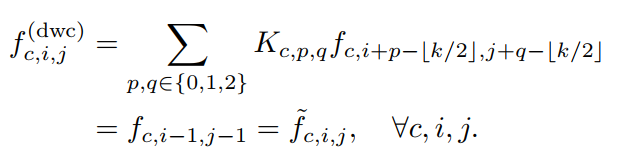
因此,对于特定的位移方向,经过精心设计的kernel weight,卷积输出相当于简单张量位移。为了进一步合并来自不同方向的特征的总和,作者将所有的输入特征和卷积核分别串联起来,将移位运算表示为单群卷积,如图3 (c.I)所示。这一修改使模块具有更高的计算效率。
在此基础上还引入了一些适应性来增强模块的灵活性。所示在图3 (c.II)中,释放卷积核作为可学习权值,以移位核作为初始化。这提高了模型的容量,同时保持了原有的移位操作能力。还使用多组卷积核来匹配卷积的输出通道维数和自注意力路径,如图3 (c.III)所示。
4.4 ACmix的计算成本
为了更好的比较,在表1中总结了ACmix的FLOPs和参数。
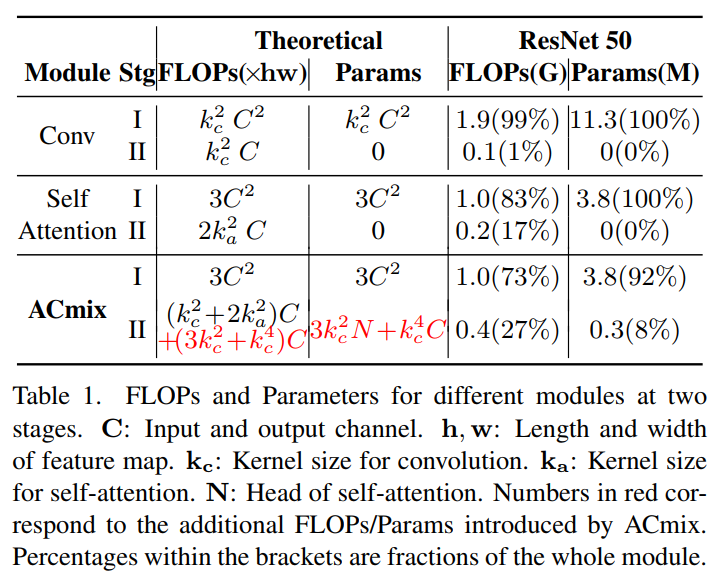
第一阶段的计算成本和训练参数与自注意力相同,且比传统卷积(如3×3 conv)轻。在第二阶段,ACmix引入了额外的计算开销(完全连接层和组卷积),其计算复杂度是线性对通道大小C和相对较小的阶段即实际成本与理论分析ResNet50模型显示了类似的趋势。
4.5 对其他注意力模式的推广
随着自注意力机制的发展,许多研究都集中在探索注意力的变化,以进一步提升模型性能。有学者提出的Patchwise attention将来自局部区域所有特征的信息合并为注意力权重,取代原来的softmax操作。swin-transformer采用的窗口注意力方法在同一局部窗口中保持token的感受字段相同,以节省计算成本,实现快速推理速度。另一方面,ViT和DeiT考虑将长期依赖关系保持在单个层中的全局注意力。在特定的模型体系结构下,这些修改被证明是有效的。
在这种情况下,值得注意的是,提出的ACmix是独立于自注意力公式的,并且可以很容易地应用到上述的变体。具体来说,注意力权重可以概括为:
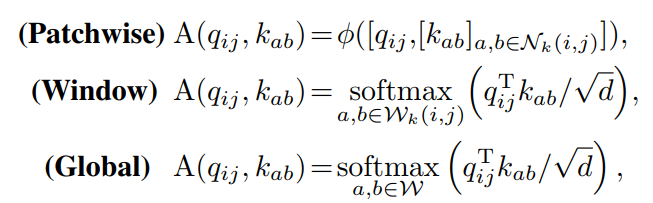
其中[·]表示特征拼接,φ(·)表示具有中间非线性激活的两个线性投影层,Wk(i,j)是每个query token的专门接受字段,W代表整个特征图。然后,计算出的注意力权重可以应用于式(12),并符合一般公式。
5实验
5.1 ImageNet
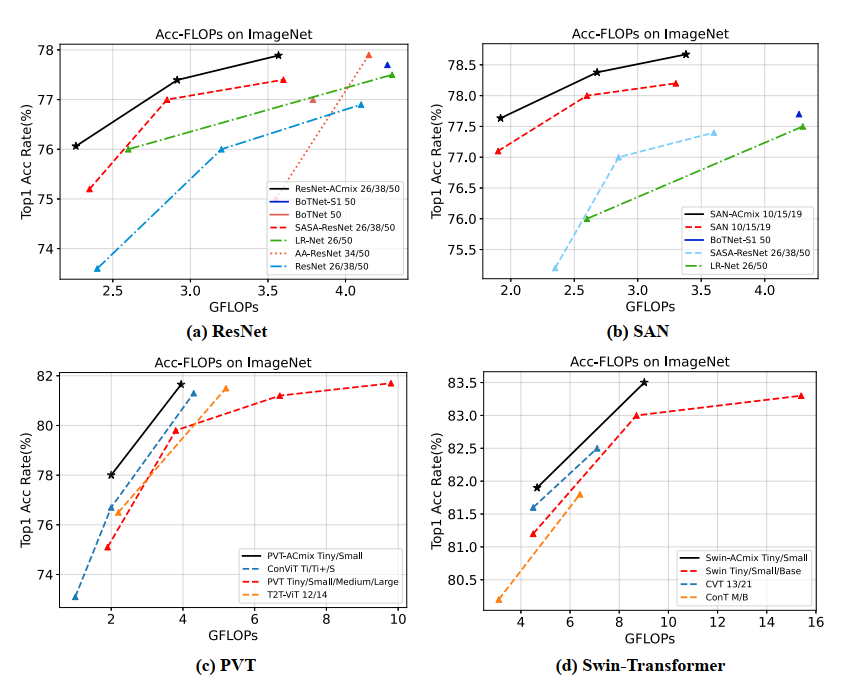

分类结果如上图表所示。对于ResNet-ACmix模型优于所有具有可比较的浮点数或参数的Baseline。
例如,ResNet-ACmix 26实现了与SASA-ResNet 50相同的top-1精度,但执行次数为80%。在类似的FLOPs案例中,本文的模型比SASA的表现好0.35%-0.8%,而相对于其他Baseline的优势甚至更大。
对于SANACmix、PVT-ACmix和Swin-ACmix,本文的模型实现了持续的提升。SAN- acmix 15以80%的FLOPs超过SAN 19。PVT-ACmix-T显示出与PVT-Large相当的性能,只有40%的FLOPs。Swin-ACmix-S以60% FLOPs实现了比Swin-B更高的精度。
5.2 语义分割与目标检测
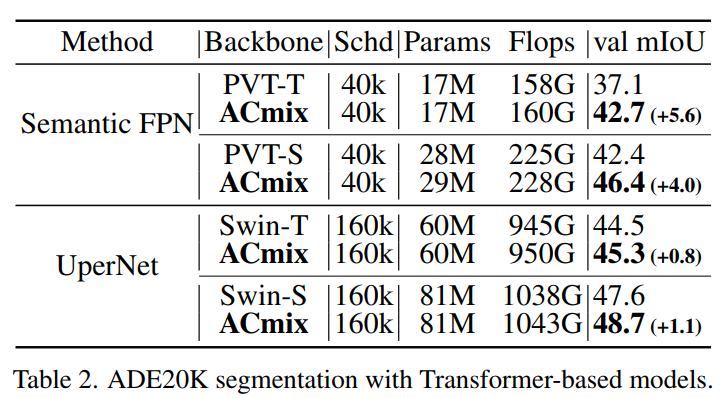
作者在ADE20K数据集中评估了模型的有效性,并在Semantic-FPN 和UperNet两种分割方法上显示结果。在ImageNet-1K上预训练Backbone。事实证明
ACmix在所有设置下都实现了提升。
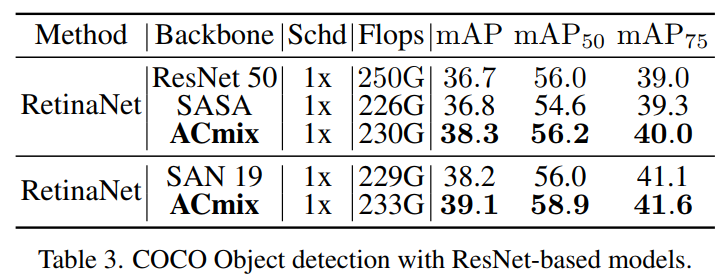
作者也在COCO上进行了实验。
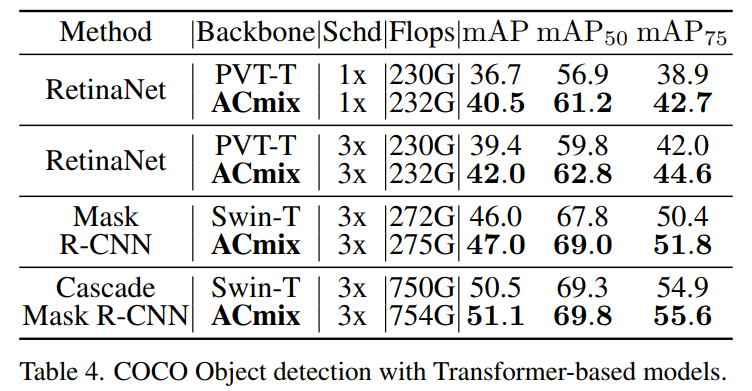
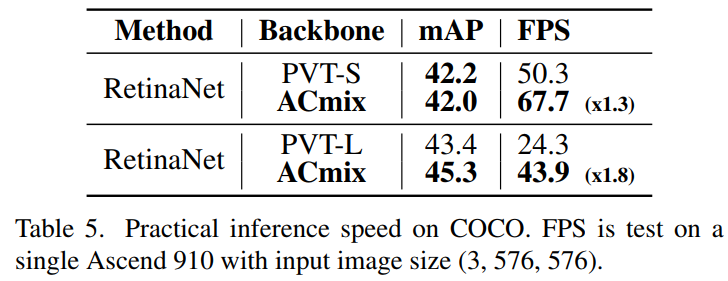
表3和表4显示了基于resnet的模型和基于Transformer的模型在不同检测head情况下的结果,包括RetinaNet、Mask R-CNN 和 Cascade Mask R-CNN。可以观察到ACmix始终优于具有相似参数或FLOPs的Baseline。这进一步验证了将ACmix转移到下游任务时的有效性。
5.3 消融实验
1、结合两个路径的输出

探索卷积和自注意力输出的不同组合对于模型性能的影响。作者采用了多种组合方法进行实验,结果总结如表6所示。通过用传统的3 × 3卷积代替窗口注意,还展示了仅采用一条路径的模型的性能,Swin-T用自注意力,而Conv-Swin-T用卷积。正如所观察到的,卷积和自注意力模块的组合始终优于使用单一路径的模型。固定所有操作符的卷积和自注意力的比例也会导致性能下降。相比之下,使用学习的参数给ACmix带来了更高的灵活性,卷积和自注意力路径的强度可以根据滤波器在整个网络中的位置自适应调整。
2、Group Convolution Kernels
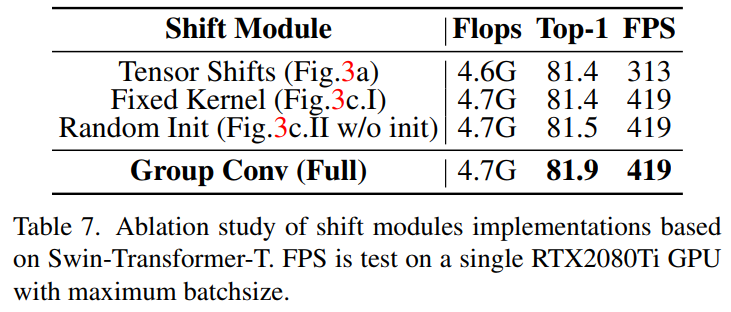
作者还对组卷积核的选择进行了消融实验,在表7中实证地展示了每种适应的有效性,以及它对实际推理速度的影响。用组卷积代替张量位移,大大提高了推理速度。此外,使用可学习的卷积核和精心设计的初始化增强了模型的灵活性,并有助于最终的性能。
5.5 Bias towards Different Paths

同样值得注意的是,ACmix引入了两个可学习标量α、β来合并来自两个路径的输出。这导致了模块的一个副产品,其中α和β实际上反映了模型在不同深度上对卷积或自注意力的偏向。
这里进行了平行实验,图5显示了SAN-ACmix模型和Swin-ACmix 模型中不同层学到的参数α、β。左图和中间图分别显示了自注意力和卷积路径速率的变化趋势。在不同的实验中,速率的变化相对较小,特别是当层更深时。
这个观察结果表明,对于不同的设计模式,深度模型具有稳定的偏好。在右边的图中显示了一个更明显的趋势,其中两个路径之间的比率被明确地表示出来。可以看到:
在Transformer模型的早期阶段,卷积可以作为很好的特征提取器。
在网络的中间阶段,模型倾向于利用两种路径的混合,对卷积的偏向越来越大。
在最后阶段,自注意力表现出比卷积更大的优势。这也与之前作品的设计模式一致,即在最后阶段多采用自注意力来代替原来的3x3卷积,早期的卷积被证明对vision transformer更有效。
通过分析α和β的变化发现在深度模型的不同阶段对卷积和自注意力有不同的偏向。
ACmix论文PDF下载
后台回复:ACmix,即可下载上述论文
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()

