
热门标签
热门文章
- 1【云原生系列CKA备考】Kubernetes架构_一个基础的kubernetes集群包含一个master和多个node
- 2保护IP地址不被窃取的几种方法_黑客是怎么防止别人查自己的ip地址的
- 3java全排列——dfs方法(深度搜索)_java全排列算法dfs
- 4Linux基础——sar 查看网卡流量_linux查看网卡历史
- 56个超级个体正在使用的国内外AI工具聚合网站 原创_聚合ai网站
- 6Android自定义修改打包apk名称_android studio 2023 打包apk名字更改
- 7[蓝桥杯]真题讲解:景区导游(DFS遍历、图的存储、树上前缀和与LCA)
- 8Llama中文大模型-模型预训练_ollama 中文模型
- 9redis学习记录_当
- 10alpine 系统_alpine基于debian吗
当前位置: article > 正文
吴恩达2022机器学习专项课程(一) 第二周课程实验:特征缩放和学习率(多元)(Lab_03)
作者:Gausst松鼠会 | 2024-04-15 19:44:08
赞
踩
吴恩达2022机器学习专项课程(一) 第二周课程实验:特征缩放和学习率(多元)(Lab_03)
备注:笔者只对个人认为的重点代码做笔记,其它详细内容请参考吴恩达老师实验里的笔记。
1.多元特征的训练集
- 调用load_house_data()函数,将训练集数据保存到数组中。
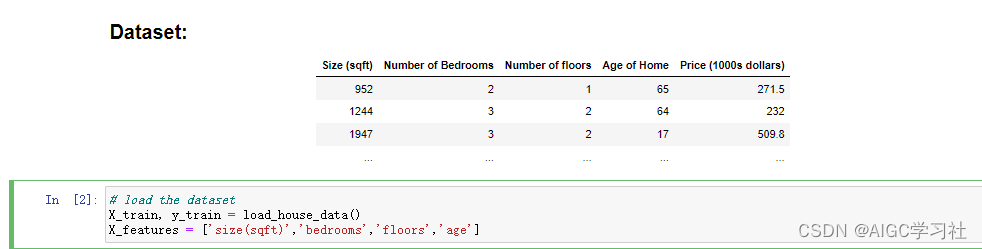
- X,y分别存储所有训练样本的前四列,所有训练样本的第五列

- 详细的训练样本,一共100行,100个训练样本。

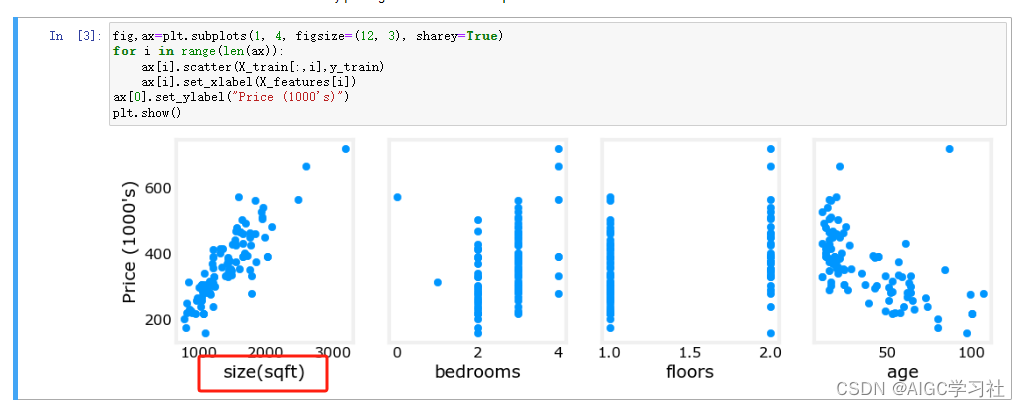
2.特征对房屋价格的影响
不同特征对价格的影响,房子面积越大,数据点的趋势整体上升,因此面积对价格的影响最大,卧室数量和楼层对价格的影响忽上忽下,房屋年龄对价格的影响是整体下降。
3.学习率为9.9e-7,运行梯度下降
- 设置学习率9.9乘10的负7次方,执行梯度下降,学习率设置过大,成本增加,梯度下降没有收敛。

- run_gradient_descent函数,初始化w数组和b,继续调用gradient_descent_houses。

- 重点在于gradient_descent_houses中的导数项计算函数gradient_function。

- gradient_function使用矩阵操作和向量化操作。

- f_wb:存储每行训练样本的预测值y帽。
- e:存储每行训练样本预测值y帽和真实y的误差。
- dj_dw = (1/m) * (X.T @ e) :对应m/1后的公式内容。
- dj_db = (1/m) * np.sum(e) :对应m/1后的公式内容
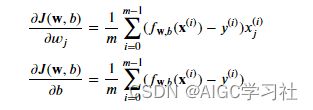
-
dj_dw = (1/m) * (X.T @ e)解析:
- 第1行训练样本的误差乘以第1行训练样本的第1个特征,第1行训练样本的误差乘以第1行训练样本的第1个特征,第100行训练样本的误差乘以第100行训练样本的第1个特征,所有乘积结果累积,然后除以m/1,表示对w1参数求导,结果放入dj_dw数组中的索引0位置。
- 第1行训练样本的误差乘以第1行训练样本的第2个特征,第2行训练样本的误差乘以第2行训练样本的第2个特征,第100行训练样本的误差乘以第100行训练样本的第2个特征,所有乘积结果累积,然后除以m/1,表示对w2参数求导,结果放入dj_dw数组中的索引1位置。
- 依次类推,dj_dw是一个元素数量为4的一维数组,每个元素表示w1~w4的求导结果。
-
dj_db = (1/m) * np.sum(e)解析:对每行训练样本的误差求和即可。
-
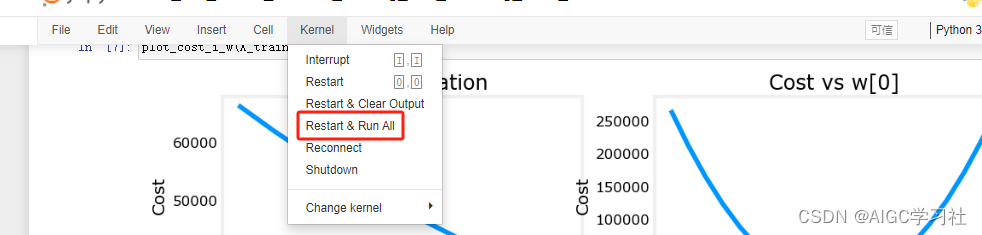
可以自己编写打印结果,更直观的查看。ctrl+s保存。

-
重启内核并运行全部。
-
看到了输出结果。
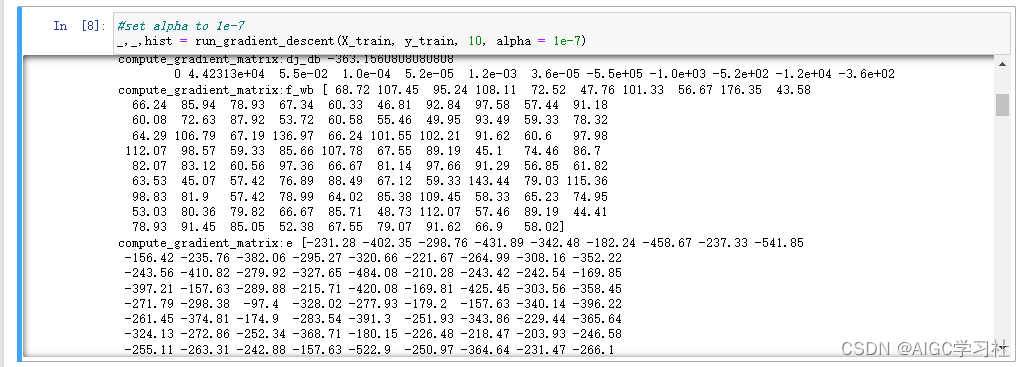
-
由于设置的迭代次数为10,我们抽取某一次来看看格式。
- f_wb存储100个数,这100个数就是每组训练样本计算的预测值。
- e存储100个数,是f_wb的每个元素减去y的每个元素,对应放入e。
- dj_dw是计算一次梯度后,w1~w4参数对应的值。
- dj_db是计算一次梯度后,b对应的值。
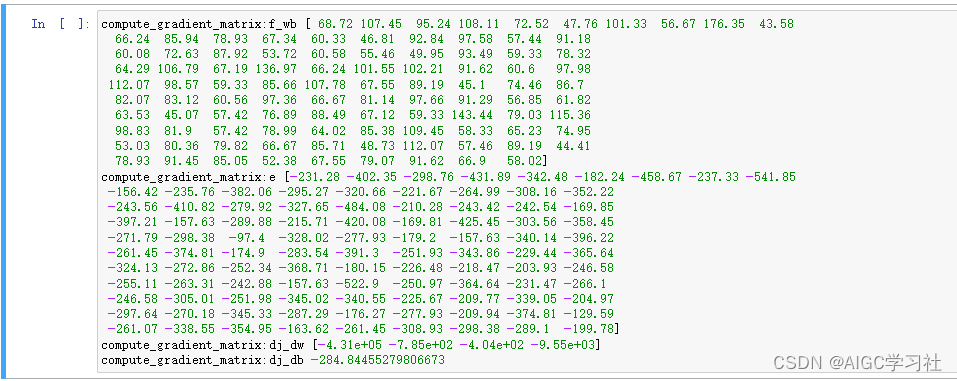
-
回到开始,当学习率为9.9e-7,成本函数一直增加,没有达到最小值。
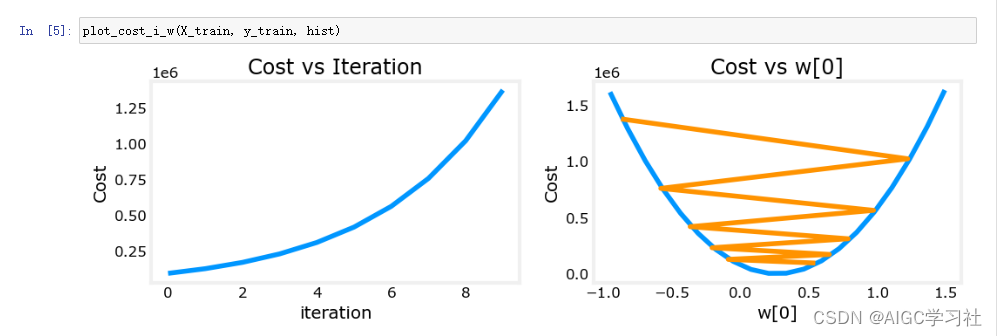
4.学习率为9e-7,运行梯度下降
- 降低学习率,设置为9乘以10的负7次方。成本函数值在减小。
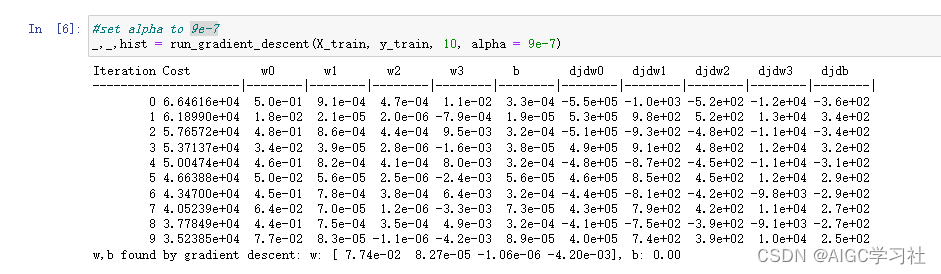
- 迭代次数增加,成本函数在减小,但是仍未到达最小值。
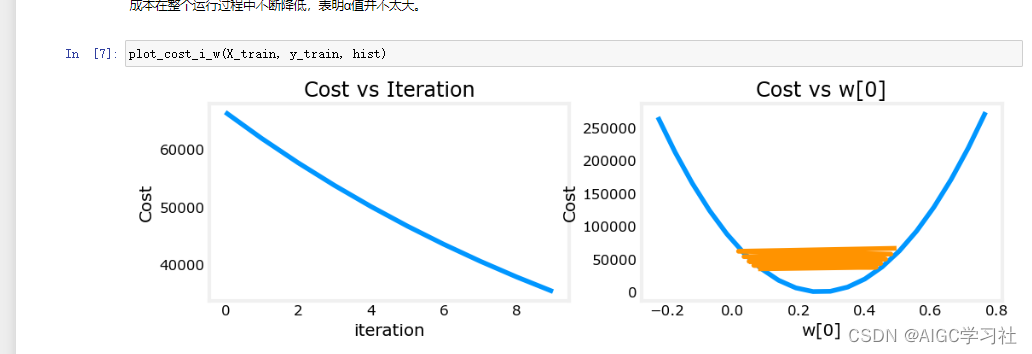
4.学习率为1e-7,运行梯度下降
- 继续降低学习率,1乘10的负7次方。

- 成本函数不断降低且能达到最小值,表示这个学习率选择比较合适。
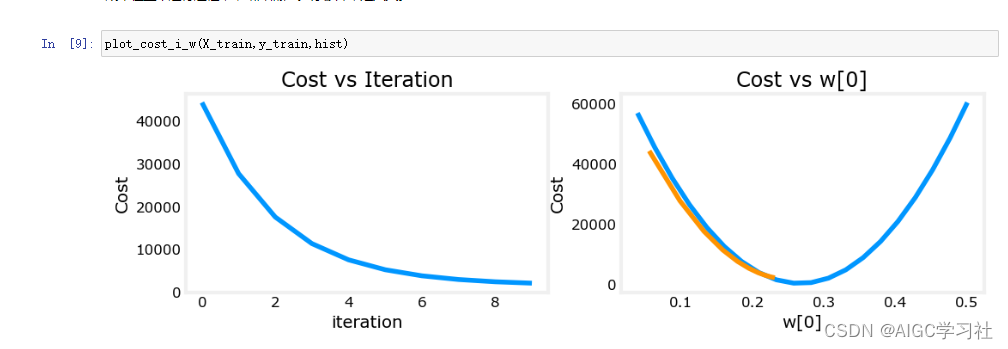
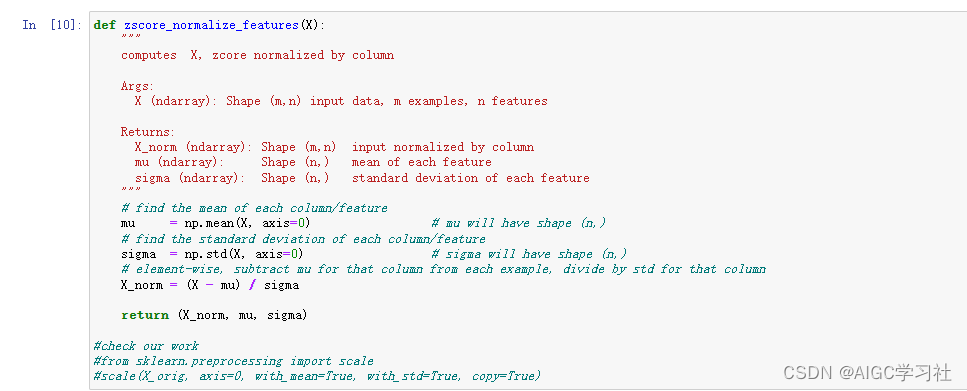
5.特征缩放,Z标准化
- 函数实现Z标准化,计算并返回标准化后的特征矩阵 X_norm,均值 X_mu 和标准差 X_sigma。
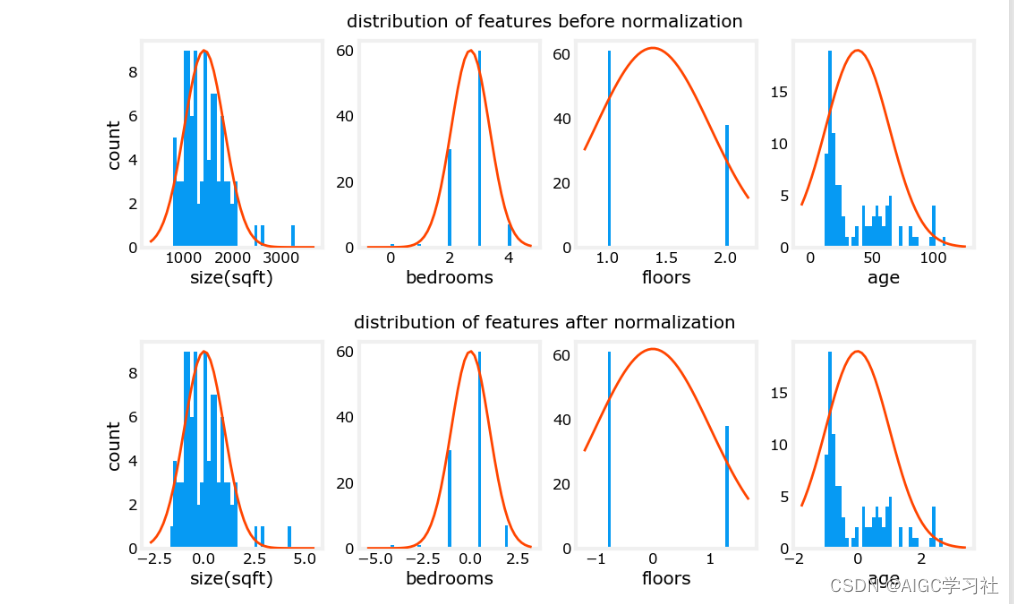
- 绘制图标,经过特征缩放后,房屋的年龄和大小的尺度变得一致,数据分散均匀。
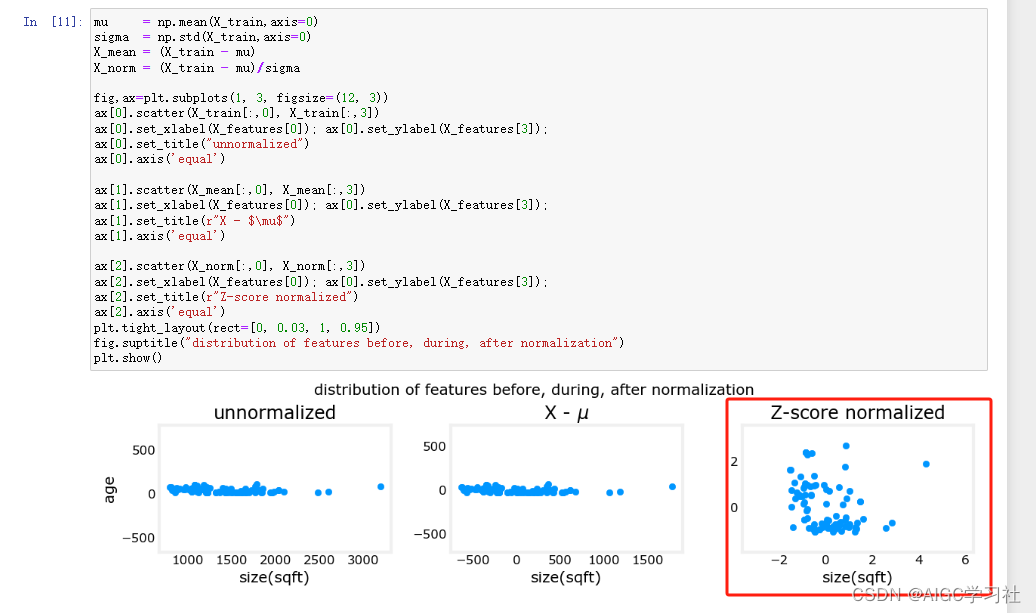
- 未标准化,每列特征最大最小的差距分别为2410,4,1,95。标准化后,每列特征最大值最小值差距为5.85,6.14,2.06,3.69,每个特征之间的尺度被缩小了。
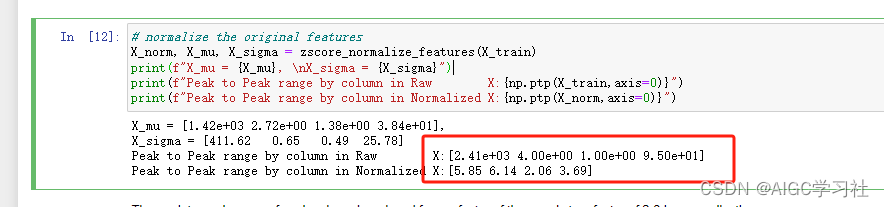
- 注意看x轴,上图未标准化,下图标准化,标准化后的特征,尺度比较接近。
6.特征缩放后运行梯度下降
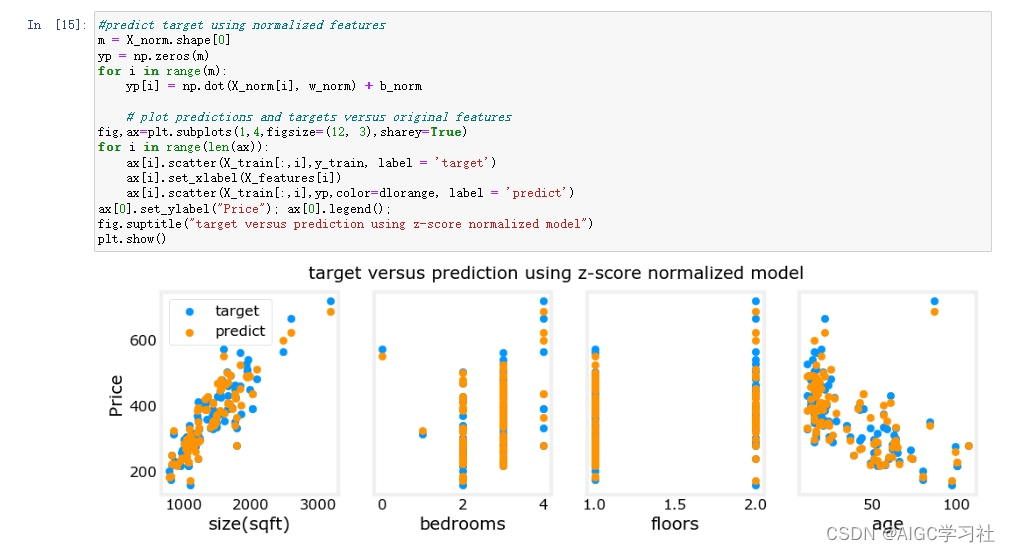
- 学习率可以选择更大,梯度下降更快。

- 橘色为预测值,和蓝色重合度较高,意味着特征缩放后,梯度下降更快且结果更精确。
7.特征缩放后,使用模型预测
- 对x_house_norm的训练集用标准化缩放,然后用线性回归函数预测房价。

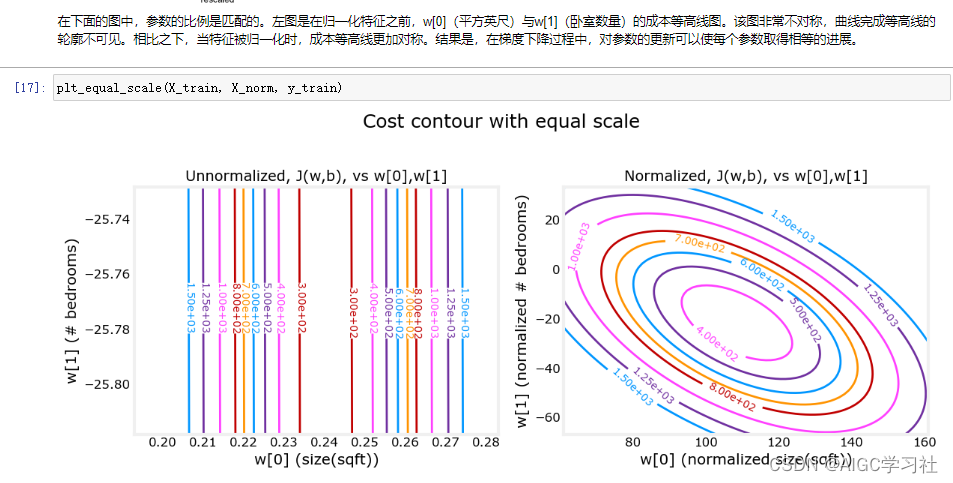
8.等高线图观察特征缩放
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/429721
推荐阅读
相关标签

