
- 1基于SpringBoot+Vue的高校学生宿舍管理系统(可做毕设课设)_基于springboot的宿舍管理系统
- 2FPGA/IC秋招面试题 1(解析版)_fpga题库
- 3YOLOv8最新改进系列:YOLOv8融合SwinTransformer模块,有效提升小目标检测效果!_yolov8小目标优化
- 4【华为OD机试真题 Java语言】407、分配土地 | 机试真题+思路参考+代码解析(C卷)(本题100%)_村庄插旗子 java
- 5属于微型计算机主要性能指示,历年软考程序员考试历年真题重点题
- 6springboot失物招领系统 计算机毕业设计源码70116
- 7【FFmpeg】自定义编码器适配_ffcodec
- 8腾讯云GPU服务器GPU计算型8核GN7性能评测_gpu计算型gn7
- 9010、Python+fastapi,第一个后台管理项目走向第10步:ubutun 20.04下安装ngnix+mysql8+redis5环境
- 10大数据应用除了在体育项目中,还有这些切身感受得到的应用案例_expressscripts应用大数据
面试薄弱点总结_面试薄弱地方
赞
踩
小红书(两轮技术一轮hr oc)
一面
map和forEach的区别?
(1)map()会分配内存空间存储新数组并返回,forEach()不会返回数据。
(2)forEach()允许callback更改原始数组的元素。map()不会改变原数组。
promise的any方法
Promise.any()有一个子实例成功就算成功,全部子实例失败才算失败。和all方法相反
async await原理
async和await其实通过generator生成的
generator生成器
首先,生成器函数需要在function的后面加一个符号:*
其次,生成器函数可以通过yield关键字来控制函数的执行流程:
function* foo() { console.log('函数开始执行'); const value = 10; console.log(value); //如果想有返回值,可以把返回值写在yield后面 yield value const value2 = 20; console.log(value2); yield console.log('结束'); } //调用生成器函数,会给我们返回一个生成器对象,generator本质是一个迭代器,所以可以调用next const generator = foo(); //开始执行第一段代码(第一个yield前面) //打印一下返回值 console.log('1',generator.next()); //开始执行第二段代码(第二个yield前面) console.log('2',generator.next()); //开始执行第三段代码(第二个yield后面) console.log('3', generator.next());

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
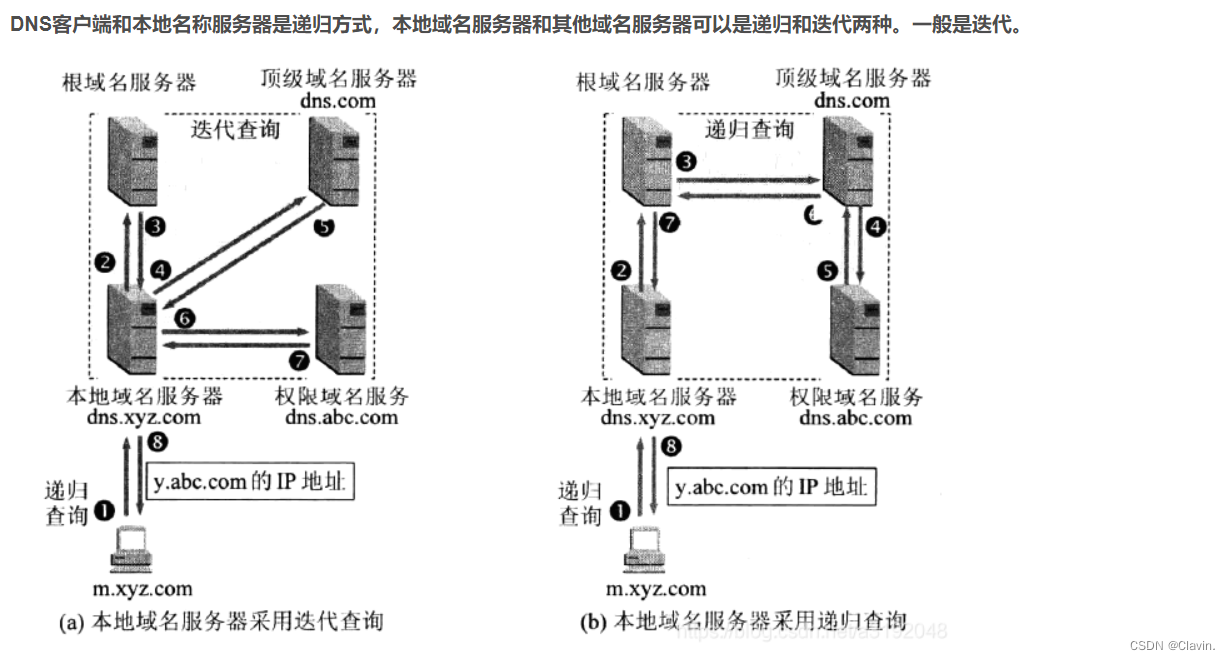
dns迭代查询和递归查询区别
递归查询
在该模式下DNS 服务器接收到客户机请求,必须使用一个准确的查询结果回复客户机。如果DNS 服务器本地没有存储查询DNS 信息,那么该服务器会询问其他服务器,并将返回的查询结果提交给客户机。
迭代查询
DNS 服务器另外一种查询方式为迭代查询,DNS 服务器会向客户机提供其他能够解析查询请求的DNS 服务器地址,当客户机发送查询请求时,DNS 服务器并不直接回复查询结果,而是告诉客户机另一台DNS 服务器地址,客户机再向这台DNS 服务器提交请求,依次循环直到返回查询的结果
为止。
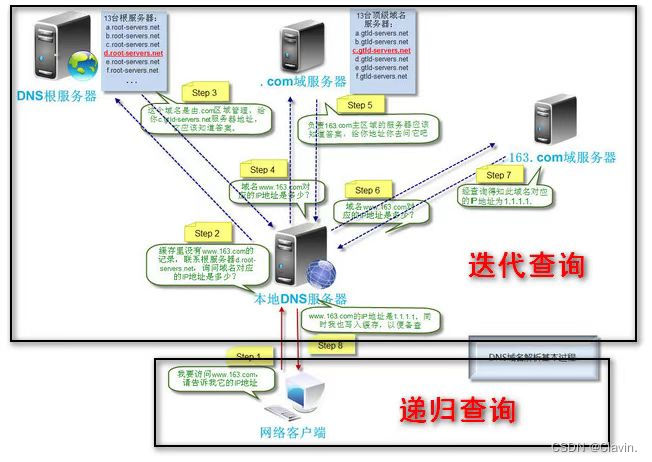
在一个dns查询中递归查询和迭代查询都有
为什么要设计虚拟dom?
第一点是减少回流重绘,将多次操作dom的开销降到最低
第二点
最主要的目的是防止在框架中直接对真实dom进行操作
因为一个项目是很多人写的,大家都操作dom,会引起冲突,写出来的代码,可读性大打折扣,所以性能只是一部分,核心通过这种架构,提升开发效率。
然后这个虚拟dom,可以开发出很多功能,ssr什么的,拥有跨平台的能力。
二面
token的优势?
无状态
token 自身包含了身份验证所需要的所有信息,使得我们的服务器不需要存储 Session 信息,这显然增加了系统的可用性和伸缩性,大大减轻了服务端的压力。
防止CSRF 攻击
CSRF(Cross Site Request Forgery) 一般被翻译为 跨站请求伪造,属于网络攻击领域范围。构成这个攻击的原因,就在于 Cookie + Session 的鉴权方式中,鉴权数据(cookie 中的 session_id)是由浏览器自动携带发送到服务端的,借助这个特性,攻击者就可以通过让用户误点攻击链接,达到攻击效果。而 token 是通过客户端本身逻辑作为动态参数加到请求中的,token 也不会轻易泄露出去,因此 token 在 CSRF 防御方面存在天然优势。
Mysql的索引做什么的?
它相当于书的目录,能加快数据检索速度。
想象一下,如果一个表中的数据有上万、几十万甚至上百万的时候,不加索引全表扫描的效率那会非常的…
//编码
new Buffer(String).toString('base64');
//解码
new Buffer(base64Str, 'base64').toString();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
node怎么开子进程?
exec
execFile
spawn
fork
如何解决 margin“塌陷”?
1、为父盒子设置 border,为外层添加 border 后父子盒子就不是真正意义上的贴合(可以设置成透明:border:1px solid transparent);
2、为父盒子添加 overflow:hidden;
3、为父盒子设定 padding 值;
4、为父盒子添加 position:fixed;
5、为父盒子添加 display:table;
webpack之loader执行顺序
webpack的加载从右往左
webpack有哪些常用plugin?
html-webpack-plugin
const HtmlWebpackPlugin = require('html-webpack-plugin');
const path = require('path');
module.exports = {
entry: 'index.js',
output: {
path: path.resolve(__dirname, './dist'),
filename: 'index_bundle.js',
},
plugins: [new HtmlWebpackPlugin()],
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
由以上代码我们可以看到,其实这个plugin是一个不需要配置就能完成所做的事情的插件,生成的结果就是根据出口自动生成一个index.html文件,然后子啊index.html中去引入我们打包好的js文件
uglifyjs-webpack-plugin
const HtmlWebpackPlugin = require('uglifyjs-webpack-plugin');
optimization: {
minimizer: [
new UglifyJsPlugin()
]
},
- 1
- 2
- 3
- 4
- 5
- 6
uglifyjs-webpack-plugin插件用来缩小(压缩优化)js文件,最低使用版本为:Node v6.9.0/Webpack v4.0.0,一般我们现在的项目都是可以不用操心这个的,毕竟这俩兼容版本已经很低了
这里需要先说一个东西,就是optimization,这个也是webpack的一个配置,作用就是优化,默认的话是uglifyjs-webpack-plugin(webpack自己的)来压缩打包,但是这个我们是可以配置的,用不同的压缩插件来进行自定义,minimizer就是配置我们自定义插件的地方,默认为true
Vite与Wbpack的区别?
1.Webpack先打包生成bundle,再启动开发服务器
Vite先启动开发服务器,利用新一代浏览器的ESM能力,无需打包,直接请求所需模块并实时编译
2.Webpack HMR时需要把改动模块及相关依赖全部编译
Vite HMR时只需让浏览器重新请求该模块,同时利用浏览器的缓存(源码模块协商缓存,依赖模块强缓存)来优化请求。
快手(三轮技术一轮hr,锁hc)
一面
201和403状态码?
201状态码英文名称是Created,该状态码表示已创建。成功请求并创建了新的资源,该请求已经被实现
403 Forbidden是HTTP协议中的一个状态码(Status Code)。可以简单的理解为没有权限访问此站。
function a(name) {
this.name = name
return null
}
let b = new a('123');
console.log(b);
- 1
- 2
- 3
- 4
- 5
- 6
new的时候return null不会影响new返回的对象
算法:翻转二叉树
快手二面
Vite这么火,为什么没有普及?
Vite使用的ESmodule技术很多浏览器版本不支持这个技术。
Chrome 打开一个页面有多少进程?分别是哪些?
浏览器从关闭到启动,然后新开一个页面至少需要:1个浏览器进程,1个GPU进程,1个网络进程,和1个渲染进程,一共4个进程;
多路复用debug的形式?
瀑布流是一个并排的流的形式
快手三面
做题
滴滴
滴滴一面
电商项目中数据分析功能的建表过程
根据商品种类建一张大表,在这个大表中再建一些子表,比如该商品的详细信息(价格,购买人数,时间等)
instanceof的缺点:检查不了number、boolean、string类型
所以用Object.prototype.toString.call()
object转map的方法
var o = {
name: '123',
sge:'123'
}
console.log(new Map(Object.entries(o)))
//Map(2) { 'name' => '123', 'sge' => '123' }
- 1
- 2
- 3
- 4
- 5
- 6
对node的优点和缺点提出看法
优点:
1.基于Javascript,普及门槛低,JavaScript相对其他的企业级编程语言来说也简单一些,这样前端程序员就可以很快上手利用Node做后端的设计
2.Node是基于事件驱动和无阻塞的,所以非常适合处理并发请求,因此构建在Node上的代理服务器相比其他技术实现(如Ruby)的服务器表现要好得多。
缺点:
1、不适合计算密集型应用;
2、不适合大内存的应用;
3、不适合大量同步的应用。
说说node的api
/*__dirname获取当前文件所在的路径 */
/* __filename获取当前文件所在的路径和文件名称 */
console.log(__dirname);
console.log(__filename);
- 1
- 2
- 3
- 4
enents模块
fs模块
path模块
request模块
const fs = require('fs');
const content = '王威是傻逼是我儿子'
//参数1是地址,参数2是内容,参数3是错误时的回调函数,flag:'a'代表往文件里面追加内容
fs.writeFile('./abc.txt', content,{flag:'a'}, err => {
console.log(err);
})
//文件的读取,{encoding:'utf-8'}是读取时的编码
fs.readFile('./abc.txt', {encoding:'utf-8'}, (err, data) => {
console.log(data);
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
货拉拉
vue多次打包后出现浏览器缓存
问题:每次打包更新版本上传到服务器上,会偶尔出现代码没有更新还是旧代码的逻辑,这就代表浏览器存在缓存的问题了。
分析:
第一次打包,生成一个bundle.js,在index.html引入bundle.js文件,页面加载,它会把bundle.js缓存到浏览器本地。
这是浏览器的缓存机制。当我们又重新打包了,由于文件名还是bundle.js,浏览器就可能从缓存中获取,因为浏览器发现这个bundle.js,在浏览器的缓存中有,缓存中有,就走缓存。从缓存中获取上一次打包的结果。
解决:
之所以有缓存是由于文件名或url名是一样的,只有一样了,浏览器才会偷懒,从缓存中获取资源,如果url名或文件名不一样,肯定不会走缓存,浏览器会当成一个新资源。
打包时 指定 出口 文件名每一次都不一样。
在webpack中有一个hash的东西:
hash可以保存每一次的值都是不一样的。
filename:“bundle.[hash].js”, 这样定,每一次生成的打包后文件名就不一样了。
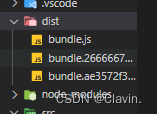
方法2:
在入口文件index.html添加:
<meta http-equiv="Expires" content="0">
<meta http-equiv="Pragma" content="no-cache">
<meta http-equiv="Cache-control" content="no-cache">
<meta http-equiv="Cache" content="no-cache">
- 1
- 2
- 3
- 4
升级时缓存问题倒解决了,但直接导致了用户每次访问你的程序时都要重新请求服务器,所有的静态资源都无法用缓存了,浪费流量,网络压力变大。
方法3:
如果你用Ngnix:
增加如下配置即可
location = /index.html {add_header Cache-Control "no-cache, no-store";
}
- 1
- 2
单点登录系统中如何共享cookie
在同域情况下:
使用cookie的两个属性
domain-域
通过设置这个属性可以使多个web服务器共享cookie。domain属性的默认值是创建cookie的服务器的主机名。不能将一个cookie的域设置成服务器所在的域之外的域。
path-路径
表示创建该cookie的服务器的哪些路径下的文件有权限读取该 cookie,默认为/,就是创建该cookie的服务器的根目录。
举个例子:
让位于a.taotao.com的服务器能够读取b.taotao.com设置的cookie值。如果b.taotao.com的页面创建的cookie把 它的path属性设置为”/”,把domain属性设置成”.taotao.com”,那么所有位于b.taotao.com的网页和所有位于a.taotao.com的网页,以及位于taotao.com域的其他服务器上的网页都可以访问(或者说是得到)这个cookie。
在不同域情况下:
如果是不同域的情况下,Cookie是不共享的,这里我们可以部署一个认证中心,用于专门处理登录请求的独立的 Web服务
第一次登录a项目,发现a项目里的sessionstorage里面没有token,跳转到认证中心,认证中心发现用户尚未登录,则返回登录页面,等待用户登录,登录成功后,认证中心记录用户的登录状态,并将 token 写入 Cookie(注意这个 Cookie是认证中心的,应用系统是访问不到的),然后认证中心会跳转回目标 URL,并在跳转前生成一个 Token,拼接在目标URL 的后面,回传给目标应用系统,应用系统拿到 Token之后,将 Token写入sessionstorage,当再访问a发现a项目里的sessionstorage里面有token,就不会跳到认证中心了。
现在访问b项目,因为之前访问a项目已经在认证中心的cookie中存过,所以会直接拿到Token拼接在目标URL 的后面回传回去
此种实现方式相对复杂,支持跨域,扩展性好,是单点登录的标准做法.
第二种方法:
此种实现方式完全由前端控制,几乎不需要后端参与,同样支持跨域
单点登录完全可以在前端实现。前端拿到 Session ID(或 Token )后,除了将它写入自己的 LocalStorage 中之外,还可以通过特postMessage结合iframe将它写入多个其他域下的 LocalStorage 中
// 获取 token var token = result.data.token; // 动态创建一个不可见的iframe,在iframe中加载一个跨域HTML var iframe = document.createElement("iframe"); iframe.src = "http://app1.com/localstorage.html"; document.body.append(iframe); // 使用postMessage()方法将token传递给iframe setTimeout(function () { iframe.contentWindow.postMessage(token, "http://app1.com"); }, 4000); setTimeout(function () { iframe.remove(); }, 6000); // 在这个iframe所加载的HTML中绑定一个事件监听器,当事件被触发时,把接收到的token数据写入localStorage window.addEventListener('message', function (event) { localStorage.setItem('token', event.data) }, false);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
token可以放到cookie中吗?
可以,不过不安全
token的续签
方案一 每次请求都返回新 token
假设一个 token 的签发时间为 12:00,需求为 2h 未进行请求即过期。则设置有效期 2h,那么每次请求都会把一个 token 换成一个有两小时的新token。如果 2h 没有进行请求,那么上一次请求的到的 token 就会过期,需要重新登录。不断签就能一直使用下去。
这种方式实现思路很简单,但开销比较大。
方案二用两个token实现
如图所示,生成两个Token,access_token负责后端业务验证,refresh_token负责续签验证,所以从逻辑上各司其职并不是脱裤子放屁。
登陆
派发access_token、refresh_token,其中access_token过期时间是1小时,而refresh_token过期时间是2小时,且二者负载内容一致。
后续请求
access_token未过期则后端正常执行业务,当access_token过期时再验证refresh_token,如果refresh_token未过期则续签,即派发新的access_token、refresh_token到客户端
ts的缺点
和有些库结合时不是很完美
增加学习成本,写法繁琐
项目使用ts和js库冲突的解决方案
配置ts的配置文件让他忽略对这个库的类型约束
字节-财经部门
一面:
服务治理的概念
应用从单体架构向微服务架构演进的过程中,由于细粒度的微服务应用数量大幅增长,微服务之间的服务发现、负载均衡、熔断限流等服务治理需求显著提高。
重试:
微服务中自动重试也是服务间调用的一项常见配置,当上游服务返回特定类型的错误代码时可重新尝试调用。由于错误可能是暂时的环境抖动引起,一般很快恢复,所以重试是一个有用的策略。重试是解决一些异常请求的直接、简单的方法,尤其是网络质量不稳定的场景下,可提高服务质量。但是重试使用不当也会有问题,特定情况下重试可能一直不成功,反而增加延迟和性能开销。
熔断:
多个服务之间存在依赖调用,如果某个服务无法及时响应请求,故障向调用源头方向传播,可能引发集群的大规模级联故障,造成整个系统不可用。为应对这种情况,可以引入熔断策略。为了防止故障范围的扩大,熔断的基本逻辑就是隔离故障。
限流:
熔断的主要目的是隔离故障,而引起故障的原因除了系统服务内部的问题外,还有可能是请求量超过了系统处理能力的极限,后续新进入的请求会持续加重服务负载,导致资源耗尽发生服务出错。限流的目的就是拒绝过多的请求流量,保证服务整体负载处于合理水平。
微前端和传统b端项目的区别
将 Web 应用由单一的单体应用转变为多个小型前端应用聚合为一的应用。各个前端应用可以独立运行、独立开发、独立部署。(建议先了解微服务)
微前端改造后的优点
1.可以与时俱进,不断引入新技术/新框架,技术栈无关
2.局部/增量升级,一点一点换掉老的应用,同时在不受单体架构拖累的前提下为客户不断提供新功能。
3.更易维护,独立部署
qiankun框架的实现原理
registerMicroApps
registerMicroApps是用来根据传入的子应用的信息数组来注册子应用;start使用启动这些子应用。
registerMicroApps是先遍历注册的子应用数组,然后调用single-spa的注册方法进行注册,资源的加载方式通过html entry的方式进行加载
html entry
TML Entry 是由 import-html-entry 库实现的,通过 http 请求加载指定地址的首屏内容即 html 页面,然后解析这个 html 模版得到 template, scripts , entry, styles然后远程加载 styles 中的样式内容,将 template 模版中注释掉的 link 标签替换为相应的 style 元素。
然后向外暴露一个 Promise 对象,最终通过execScripts来执行js脚本。
{ // template 是 link 替换为 style 后的 template template: embedHTML, // 静态资源地址 assetPublicPath, // 获取外部脚本,最终得到所有脚本的代码内容 getExternalScripts: () => getExternalScripts(scripts, fetch), // 获取外部样式文件的内容 getExternalStyleSheets: () => getExternalStyleSheets(styles, fetch), // 脚本执行器,让 JS 代码(scripts)在指定 上下文 中运行 execScripts: (proxy, strictGlobal) => { if (!scripts.length) { return Promise.resolve(); } return execScripts(entry, scripts, proxy, { fetch, strictGlobal }); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
js的代理沙箱是解决single-spa的污染window属性
string为什么有length的属性?
大家都知道 String() 构造函数可以创建一个字符串的实例, 而这个实例具有length长度
由字面量定义的字符串在使用其length属性时其实做了如下的操作
创建了一个 String 类型的实例
使用实例的属性或方法
销毁实例
js作为单线程怎么实现的异步?
浏览器是多线程的
css手写麻将的五条
flex布局套flex布局,细节是flex切换主轴方向后justify-content和align-items也会切换方向,所以只用给最里面的元素设置justify-content和align-items即可,最外面的main盒子不用设置
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <style> .main { width: 300px; height: 400px; border: 1px solid black; display: flex; } .left { width: 100%; height: 500px; flex: 1; background-color: aqua; display: flex; flex-direction: column; align-items: center; justify-content: center; } .center { width: 100%; height: 500px; flex: 1; background-color: pink; display: flex; flex-direction: column; align-items: center; justify-content: center; } .right { width: 100%; height: 500px; flex: 1; background-color: chartreuse; display: flex; align-items: center; justify-content: center; } .line { width: 10px; height: 100px; background-color: black; margin-bottom: 10px; } </style> </head> <body> <div class="main"> <div class="left"> <div class="line"></div> <div class="line"></div> </div> <div class="center"> <div class="line"></div> <div class="line"></div> </div> <div class="right"> <div class="line"></div> </div> </div> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
flex-grow默认是左右撑开剩余空间,怎么使用flex-grow上下撑开?
writing-mode: vertical-lr;
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <style> .main { width: 500px; height: 500px; display: flex; writing-mode: vertical-lr; } .item { flex: 1; height: 500px; border: 1px solid black; } </style> </head> <body> <div class="main"> <div class="item">111</div> <div class="item">111</div> <div class="item">111</div> </div> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
嘴撕Vue响应式原理(双向绑定)源码
为什么从应用层到网络接口层传输的数据包是越来越大?
因为数据包在从应用层到物理层的过程中,我们叫做数据的封装过程。
udp为什么比tcp快?
tcp有拥塞控制,超时重传,确认应答这些机制要保证数据包的可靠传输。
拥塞控制的算法
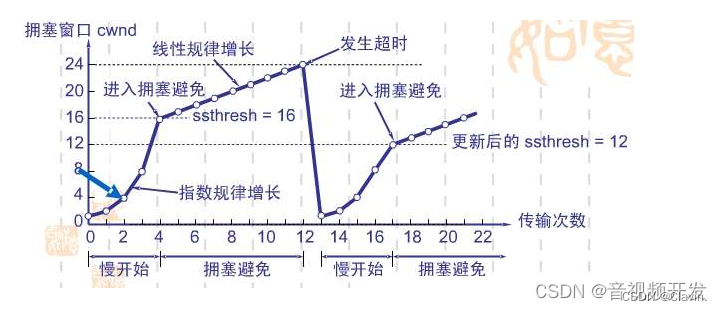
慢启动:意思是刚刚加入网络的连接,一点一点地提速,不要一上来就把路占满。
拥塞避免:当拥塞窗口 cwnd 达到一个阈值时,窗口大小不再呈指数上升,而是以线性上升,避免增长过快导致网络拥塞。
当cwnd(拥塞窗口)小于等于ssthresh门限时TCP采取的是慢启动算法,当突破这个阈值之后TCP会转为拥塞避免算法。
快重传:在丢包发生的情况下,接收端重复发送上一次接受的重复确认,发送方收到了累计3个连续的报文段的重复确认,立即重传之后的报文段
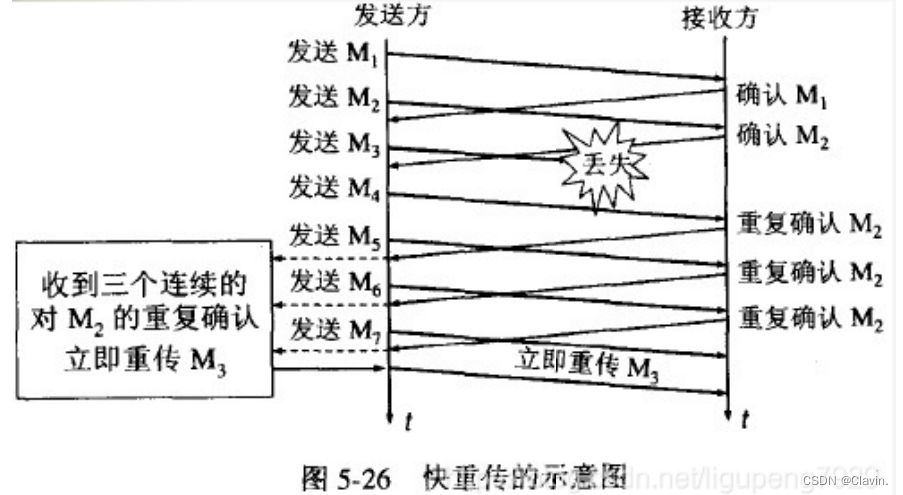
快恢复:收到3个重复确认,不启动慢开始,执行快恢复

门限的值跟什么有关?
当拥塞发生时,sshthresh会被置为当前窗口大小的一半
udp为什么比tcp快?
1.TCP为了可靠性保证,增加了3次握手4次挥手,复杂的拥塞控制,以及流量控制,让网络传输的延迟进一步增加。
2.采用TCP,一旦发生丢包,TCP会将后续的包缓存起来,等前面的包重传并接收到后再继续发送,延时会越来越大,基于UDP对实时性要求较为严格的情况下,采用自定义重传机制,有包就发,能够把丢包产生的延迟降到最低,尽量减少网络延迟。
3.接收方因为需要对保证顺序,因此前面的包没到,不会继续去处理后续的包。
4.TCP头部的大小,进一步增加了,传输的数据量。
二面:
1.项目为什么采用微前端的架构?
直接说老项目是一个基座,我开发了对应的子应用改造方案
2.讲下子应用的加载方式
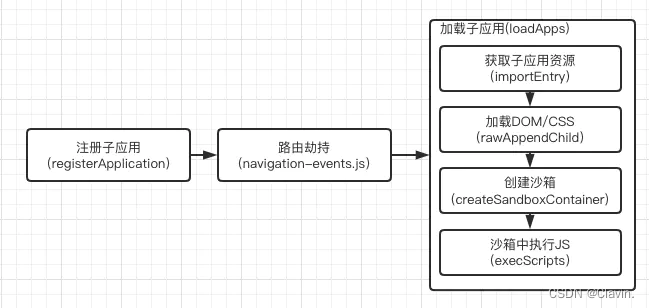
浏览器怎么请求子应用的index.html呢?
子应用和主应用在同一个域吗?会存在跨域问题吗?
本地配置devserver代理解决跨域,追问那线上呢?
3.说到html entry,那讲下代理沙箱怎么实现的?
4.css作用域用的shadow dom是吧,那假如浏览器不支持shadow dom,怎么实现css的隔离
5.子系统和基座的通信怎么做的?
initglonalstate是双向通信吗?
initglonalstate基于什么实现的?
基座和子系统是同一个状态管理吗?
6.jwt的流程
7.session id和cookie的鉴权方式
8.cookie为什么不安全,讲下csrf
既然cookie既然不安全,那为什么很多企业用这种登录方式而不用sessionStorage加token的方式?
9.既然说了session id的方式对于分布式系统认证的问题有缺陷,那你能说说对于分布式系统的解决方案吗?
10.分页功能实现,传什么参数?
后端分页的sql语句怎么写
代码1(全答错了,麻了)
<body>
xxx
<script>
window.onload = function () {
document.body.innerHTML = 'yyy';
alert(document.body.innerHTML);
console.log(document.body.innerHTML)
}
</script>
</body>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
问现在页面显示什么?alert显示什么?console.log()打印什么
代码2
用js实现一个input双向绑定(oninput事件结合defineproproty即可)
11.async和await怎么实现?
代码3
使用async和await和解决回调地狱问题
优化一下代码量,(使用工厂模式创建函数)
代码4
实现一个样式,代码越少越好(一个正方形有三个点,第一个在最左上,第二个的居中,第三个在右下)
考察flex布局的align-self属性和align-items属性
看一张图片,有十几条英文,貌似是一个性能检测图,解释这每条的含义及优化
1.怎么减少httprequest请求?
2.cdn原理
3.缓存,强缓存两个的区别,etag什么时候发生变化?
4.css文件 图片 js文件是xhr请求吗
5.src和herf为什么不能为空?
6.css为什么要写在上面
7.webpack的gizp压缩,压缩什么东西?
8.重绘回流
9.为什么要把css和js做成外链
10.dns解析
11.http请求怎么做重定向
12.如何减少cookie的大小,cookie的优化
13.跨域的解决,假如说客户端有a.com和b.com,服务端是c.com,那么Access-Control-Allow-Origin怎么配?
三面:
学校开了什么课?
1.讲一下tcp协议
2.拥塞控制这么做的?
实际场景在哪会用到拥塞控制?
做过tcp编程吗?
面试官说他发一个消息给我,问我怎么解析出来数据?
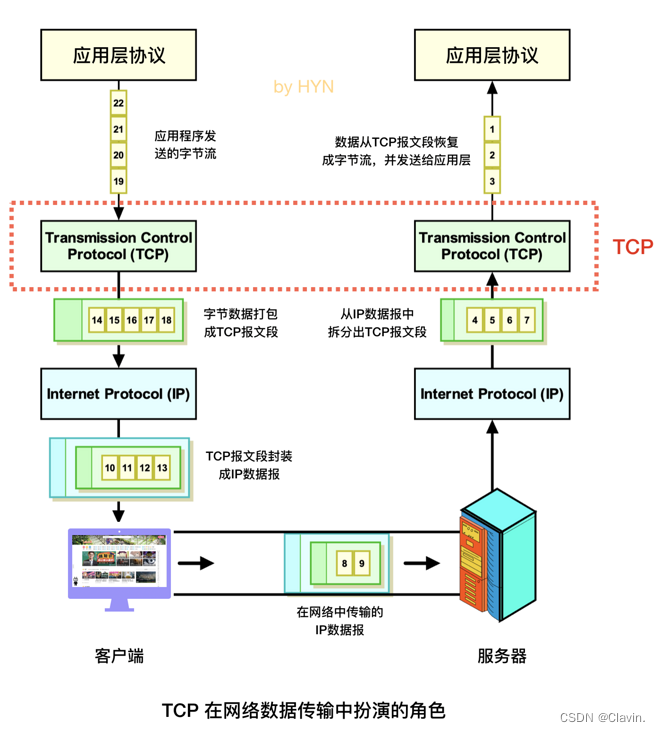
按照图中的流程,比如我们在浏览B站,在 TCP 连接建立之后,客户端的应用层协议可以向 TCP 发送无特殊格式的字节流,TCP 会将这些字节打包成报文段(segment),报文段大小视情况而定,这些报文段会被网络层的 IP 封装成 IP 数据报(IP Datagram),然后经过网络传输给服务器,而接下来服务器的操作相当于客户端的逆操作,先从 IP 数据报中拆分出 TCP 报文段,再把 TCP 报文段还原成字节流并发送给上层的应用层协议。服务器向客户端发送数据的流程也是一样的,发送方和接收方的角色互换即可。
tcp传输的内容是什么形式
3.服务治理的概念?
怎么去做熔断?
4.微前端子应用改造?
render函数怎么改的?
5.讲讲vue router的实现
6.vue文件怎么编译为js
vue-loader:通过 parser 将 .vue 解析成对象 parts, 里面分别有 style, script, template。可以根据不同的 query, 返回对应的部分。
算法:力扣版本号比较
反问
1.部门有多少开发人员
2.这个岗位在工作中会更加侧重运用哪些技能呢
3.如果我能加入团队,公司对于我个人期许,以及对于这个职位未来的发展会有什么样的想法呢
美团-搜索
一面:
30分钟实习内容
八股20min
前端并发请求实现
v-if和v-show的区别
tcp和udp
http
vue生命周期
虚拟dom生成在哪个钩子函数
父子生命周期顺序
关系型数据库的范式
算法:10s
二叉树的最大深度
反问10min
字节-data推荐架构
一面:
自我介绍
微前端改造的背景
改造过程中的最大的挑战
给react项目,改vue
动态渲染路由菜单
qiankun的沙箱
沙箱的实现
代理沙箱的缺点
影子dom的实现
其他css的隔离方案
webpack插件做css的隔离
上线流程
说一个印象最深刻的es6
讲一下sso单点登录
cookie的安全策略
vue setup和options api的区别
nextTick的原理
vue history模式的刷新404
渲染加key的原因
为什么不要用index来当作key
http请求状态码
跨域的解决
分为本地和线上(绕过)
cookie的安全策略
协商缓存
代码1
写一个函数以字符串形式返回当前传入参数的数据类型
代码2
new Array(10).map((item,i)=>i+1)返回什么
在这个基础上改成返回一个1-10的数组
在这个基础上把数组乱序
代码3
把一个对象数组按照score的大小排序
[{age:2,score:88},{age:22,score:45},{age:21,score:95},{age:42,score:52}
代码4
let a = 10;
function foo() { console.log(a) }
function bar() {
let b = 20;
foo()
}
foo()
代码5
字符串全排列(剑指offer38)
二面(50min):
自我介绍
vue2和vue3的区别
vue3兼容vue2的语法吗
服务治理项目介绍(实习内容)
治理的规则有什么?
实习获得的收获
写代码(40min)
代码(15min)
实现一个快排
优化一下
优化了枢纽的选择
解释快排的思路
代码2(25min)
写一个计算器
输入’5+9/2-1045+6’,返回运算结果
写一个带优先级的计算器
输入’5+9/2-10(45+6)',返回运算结果
百度-健康研发提前批
一面
自我介绍
react和vue区别(响应式,数据流,写法,生态)
mvc->mvvm的过渡,对比mvc与mvvm(vm弱化c的概念,并没有替代c,而是在c的基础上抽离业务逻辑,使开发更高效。mvvm是双向数据流,mvc是单向的)
最近做项目中的有挑战和难度的事情
虚拟滚动的实现(offsetTop计算start索引)
为什么不用外接库?
react出现hook的原因
fiber架构出现的原因
react调度器怎么判断事件优先级(lane赛道模型 二进制位运算表示优先级)
兄弟组件通信的方法(context使用,事件总线库,redux,state交由父组件管理)
redux的数据流
中间件的执行时机(dispatch到reducer之前)
react-thunk的原理(对dispatch进行重写升级,支持函数传入,内部判断如果是函数就调动)
口述利用中间件打一个日志
redux的hook(useSelector、useDispatch)
useReducer的使用场景(state计算逻辑比较复杂可以使用useReducer优化)
微前端解决了什么问题(旧的框架类库如何平稳升级?增量升级,技术栈,代码分割,模块解藕)
微前端的实现方式
模块联邦的缺点(迭代时的版本控制需要更多关注,导出一方升级会导致使用方都升级。兼容性)
css实现透明度的方式
算法:开平方跟(整数,小数)
二面
自我介绍
小红书实习做过有难度的事情
说一下在字节中做的项目
长列表性能优化
跨域方式
防抖节流区别,应用场景,怎么实现
介绍一个最熟悉的设计模式
面向对象的原则,说一下多态
学过什么后端语言
写一个生成器函数,返回值是一个生成器对象,内部是一个斐波那契数列
迭代和递归的区别
迭代比递归的好处
工作中的开发流程,每一步有那些人参与,每一步的输出是什么
开放题:如何培养与体现owner意识
反问


