
- 1在Ubuntu中设置中文输入法的步骤
- 2【大语言模型】轻松本地部署Stable Diffusion
- 3剑指Offer刷题记录—链表1_原链表的节点依次作为新链表的尾节点和头节点 c
- 4mini聊天室(Linux下基于UDP实现的群聊系统)_mininet聊天室程序
- 5一款非常棒的单兵渗透系统_单兵渗透测试系统
- 6常用的SQL语句大全总结
- 7金融风控训练营Task03基础知识学习笔记——特征工程_金融风控 task3 特征工程中from sklearn.feature_selection imp
- 8单字段多内容模糊查sql写法
- 9山东大学软件学院计算机网络2022-2023期末考试回忆版_山东大学软件学院计算机网络期末试题
- 10git 统计修改代码数量以及git学习总结_bitbucket代码统计
Grouped Query Attention论文阅读_grouped-query attention
赞
踩
论文:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
1. 背景介绍
Google在2023年发表的一篇关于Transformer Attention的论文,整体论文写的清晰易读,思想简单但很好用。论文名字简写是GQA,但实际分别代表了两种缩写:
- Generalized Multi Query Attention
- Grouped Query Attention
2. 详细介绍
2.1 通用Multi-Query Attention
在之前的Multi-Query Attention【
M
Q
A
MQA
MQA】方法中只会保留一个单独的key-value头,这样虽然可以提升推理的速度,但是会带来精度的损失,这篇论文的第一个思路是基于多个
M
Q
A
MQA
MQA的checkpoint进行finetuning,来得到了一个质量更高的
M
Q
A
MQA
MQA模型。这个过程也被称为Uptraining。
具体分为两步:
- 对多个
M
Q
A
MQA
MQA的checkpoint文件进行融合,融合的方法是通过对key和value的head头进行
mean pooling操作,如下图。 - 对融合后的模型使用少量数据进行finetune训练,重训后的模型大小跟之前一样,但是效果会更好
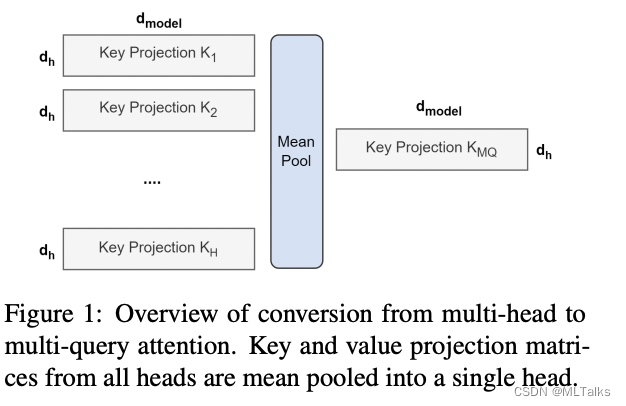
2.2 Grouped-query attention
如下图所示,在一般的attention中是Multi-head多头结构,每个头有自己单独的key-value对;在Multi-query attention结构中只会有一组key-value对;在Grouped-query attention对attention进行分组操作,query被分为N组,每一组分别与一对key-value对进行映射。
在基于Multi-head多头结构变为Grouped-query分组结构的时候,也是采用跟2.1一样的方法,对每一组的key-value对进行mean pool的操作进行参数融合。融合后的模型能力更综合,精度比Multi-query好,同时速度比Multi-head快。
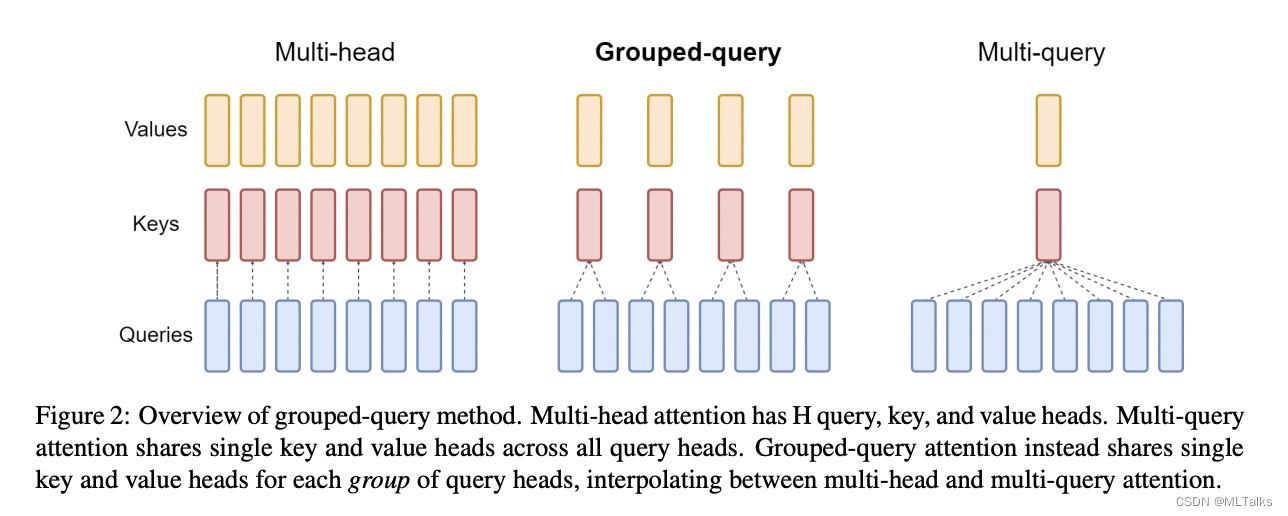
3. 应用
在llama2中有用到GQA, 在推理过程中由于多个query会复用相同的key-value对,所以对于KV-Cache存储会减少对key-value对的存储,减少了 n_heads / n_kv_heads 倍,这里的n_heads是原始Multi-head的头数,n_kv_heads是Grouped-query分组后每组中key-value对的数量。
在实际使用中,会根据从压缩后的key-value对进行还原操作,也就是repeat操作。在llama2中代码如下:
# https://github.com/facebookresearch/llama/blob/4d92db8a1db6c7f663252bf3477d2c4b8bad2385/llama/model.py#L77
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
repeat_kv在github上一个示例如下, 假设repeat 2次操作:
>>> x = torch.rand(1, 2, 3, 4) >>> x tensor([[[[0.1269, 0.8517, 0.4630, 0.1814], [0.3441, 0.1733, 0.3397, 0.5518], [0.2516, 0.6651, 0.1699, 0.0092]], [[0.9057, 0.8071, 0.6634, 0.5770], [0.1865, 0.2643, 0.8765, 0.8715], [0.3958, 0.9162, 0.7325, 0.9555]]]]) >>> n_rep = 2 >>> bs, slen, n_kv_heads, head_dim = x.shape >>> x[:, :, :, None, :].expand(bs, slen, n_kv_heads, n_rep, head_dim).reshape(bs, slen, n_kv_heads * n_rep, head_dim) tensor([[[[0.1269, 0.8517, 0.4630, 0.1814], [0.1269, 0.8517, 0.4630, 0.1814], [0.3441, 0.1733, 0.3397, 0.5518], [0.3441, 0.1733, 0.3397, 0.5518], [0.2516, 0.6651, 0.1699, 0.0092], [0.2516, 0.6651, 0.1699, 0.0092]], [[0.9057, 0.8071, 0.6634, 0.5770], [0.9057, 0.8071, 0.6634, 0.5770], [0.1865, 0.2643, 0.8765, 0.8715], [0.1865, 0.2643, 0.8765, 0.8715], [0.3958, 0.9162, 0.7325, 0.9555], [0.3958, 0.9162, 0.7325, 0.9555]]]])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

