
- 1盘点一下全网最有趣的代码注释_▄█ █●
- 2用MySQL Workbench导出ER图和数据字典_mysql导出er图带注释
- 3安阳旅游地图规划(未完成)
- 4Git配置代理:fatal: unable to access*** github Failure when receiving data from_failure when receiving data from the peer
- 5RabbitMQ, DelayQueue, Redis的介绍以及IDEA的实现
- 6C++:map和set的使用
- 7Mysql之进阶查询语句
- 8【一文详解】知识分享:(MySQL关系型数据库快速入门)_关系型数据库基础
- 9k8s之helm入门
- 10MySql-增删查改及其他语法_mysql增删改查语法
MTGAT:Multimodal Temporal Graph Attention;图卷积网络用于多模态情感分析_基于图神经网络的多模态情感分析
赞
踩
摘要
- 多模态数据呈现复杂的多关系以及时序交互的特点,从这样的数据中学习具有挑战性
- 本文提出了MTGAT。它是基于图以及具有可解释性的神经网络模型,可以利用这个框架解决多模态序列数据
- 主要包括两个部分:构建以及处理。首先将非对齐的多模态序列转换成具有异构型(heterogeneous)节点以及边的图,这个过程可以随着时间的推移捕获到不同模态之间的交互。其次,使用多模态时序注意力以及动态pruning和read-out来有效的对这个图进行处理。
- 通过在流行的benchmark上进行验证,获得了情感分析以及情绪识别上的SOTA效果
引言
- 多模态数据进行建模的时候,面对的主要挑战就是:融合以及对齐。融合的定义,并且在融合之前往往需要先进行对齐。
- 从这以下三个方面来解决融合和对齐的问题:用一种可解释的方法来对异步分布的模态进行对齐。解决短距离和长距离的依赖。在对模态之间的建模的同时保留模态内部的信息。
- 本文提出的MTGAT是对于GAT的延展,它具有灵活性,基于图的解释性以及所使用的参数较少。对于输入的序列,不需要提前进行对齐,在模型的建模过程中,对边进行可视化可以看出模型成功的对三个模态的数据进行融合并且对齐。
模型

-
节点构建
\quad 首先需要对图中的节点进行构建。步骤是这样的:每一个模态的输入特征向量都会经过FFN(Feed-Forward-Netwok)进行转换维度,之后由于这个架构并不是循环的,需要确定每一个节点的位置,因此再加上positional embedding,这样就可以构成一个节点,因此,在一个图中有多个节点,但是总共只有三个类型的节点。 π \pi π ∈ \in ∈ {Audio,Text,Video} -
边构建
\quad 由于没有对齐的前提假设,所以构建构建一个全连接网络,让模型可以寻找可能的对齐空间,因此整个网络都是连接。并且由于在融合阶段,使用到的注意力操作是非对齐的,所以边的构建需要是有向的。本文使用模态类型识别来对边进行定义,其中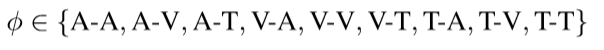
-
图是如何构造的?
\quad 首先需要知道,这篇文章一共一定了三个识别器,分别如下图所示:
modality identifier
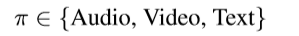
type identifier
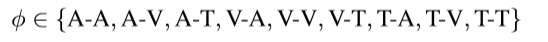
temporal identifier
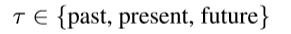
\quad 节点的构造非常的简单,这里要注意边的构造就比较麻烦,它运用到了type identifier以及temporal identifier这两个识别器,由它们两者才能构成一条边,所以边的类型有27种(3*9)(但它们好像不是异构的)
\quad 根据节点和边,则可以构成一张图了。接下来就是对于图的操作了。 -
MTGA (注意力机制)
首先对于所有的节点的特征进行维度的转换,并且将其转换为共有特征空间,这里用到的是线性转换
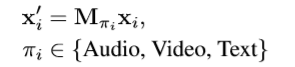
对于每一个节点 i,其周围的节点用 j 表示,我可以根据上面提及的两种识别器,type identifier以及temporal identifier来计算周围节点对于中心节点的注意力。
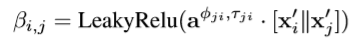
注意这里有一个
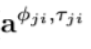
它就是我们根据每一个边的类型学到的。
之后我就可以归一化来得到所有邻居节点的注意力了
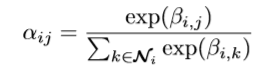
现在,就可以得到一个节点的新的embedding,它是根据周围节点结合注意力来计算的。
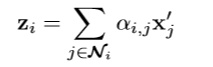
这个时候,这个z就包含了多个模态的信息。并且由于数据的异构特征,文中还使用了多头的注意力的方式,最后的表示是将每一个头都给结合起来
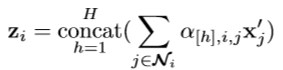
-
Dynamic Edge Pruning
由于构造的图是全连接,会造成:计算量过大,以及边过多,无法聚焦于包含信息多的内容。因此对于上面多头的注意力求平均,将均值少于某一阈值的边给去掉。(这个方法非常的类似于Dropout)

-
Graph Readout
在融合完成之后,需要收集分散在每个节点中的信息,用于分类,这里使用到readout,将整个图转换成一个向量,传入分类的head,进行分类。
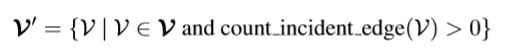
采用的是对于每一节点的输出求平均

