
- 1Wider Face+YOLOV8人脸检测_yolov8人脸识别
- 2在当前文件夹下打开cmd命令_elementary 命令行 显示当前文件夹
- 3什么是CSRF攻击,以及如何防御
- 4【前端素材】推荐优质在线茶叶电商Tea House平台模板(附源码)
- 5Python爬虫天津景点数据可视化和景点推荐系统
- 6解决Expected all tensors to be on the same device, but found at least two devices, cuda:0
- 7顶级白嫖!!!八个python免费自学网站一周搞定python(抓紧收藏)。。_百什么网站可以系统学习python
- 8Bert基础(十二)--Bert变体之知识蒸馏原理解读_bert知识蒸馏
- 9在线客服系统源码,多商户在线客服系统可开机器人自动聊天多商户在线客服
- 10论文推荐:ICCV 无需锚框的目标检测_无锚目标检测 知乎
EasyNLP玩转文本摘要(新闻标题)生成_nlp英文摘要
赞
踩
作者:王明、黄俊
导读
文本生成是自然语言处理领域的一个重要研究方向,具有丰富的实际应用场景以及研究价值。其中,生成式文本摘要作为文本生成的一个重要子任务,在实际应用场景中,包括新闻标题生成、摘要生成、关键词生成等任务形式。预训练语言模型,如BERT、MASS、uniLM等虽然在NLU场景中取得了令人瞩目的性能,但模型采用的单词、子词遮盖语言模型并不适用于文本生成场景中,特别是生成式文本摘要场景。其原因是,生成式文本摘要任务往往要求模型具有更粗粒度的语义理解,如句子、段落语义理解,以此进行摘要生成。为了解决上述问题,PEGASUS模型(PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization)针对文本摘要任务设计了无监督预训练任务(Gap Sentence Generation,简称GSG),即随机遮盖文档中的几个完整句子,让模型生成被遮盖的句子。该预训练任务能够很好地与实际地文本摘要任务匹配,从而使得预训练后的模型经过简单的微调后达到较好的摘要生成效果。因此,我们在EasyNLP框架中集成了PEGASUS算法和模型,使用户能够方便地使用该模型进行文本摘要生成相关任务的训练和预测。
EasyNLP(https://github.com/alibaba/EasyNLP)是阿⾥云机器学习PAI 团队基于 PyTorch 开发的易⽤且丰富的中⽂NLP算法框架,⽀持常⽤的中⽂预训练模型和⼤模型落地技术,并且提供了从训练到部署的⼀站式 NLP 开发体验。EasyNLP 提供了简洁的接⼝供⽤户开发 NLP 模型,包括NLP应⽤ AppZoo 和预训练 ModelZoo,同时提供技术帮助⽤户⾼效的落地超⼤预训练模型到业务。文本生成作为自然语言处理的一大子任务,具有众多的实际应用,包括标题生成、文本摘要、机器翻译、问答系统、对话系统等等。因此,EasyNLP也在逐步增加对文本生成子任务的支持,希望能够服务更多的NLP以及NLG算法开发者和研究者,也希望和社区一起推动NLG技术的发展和落地。
本⽂将提供关于PEGASUS的技术解读,以及如何在EasyNLP框架中使⽤与PEGASUS相关的文本摘要(新闻标题)生成模型。
Pegasus模型详解
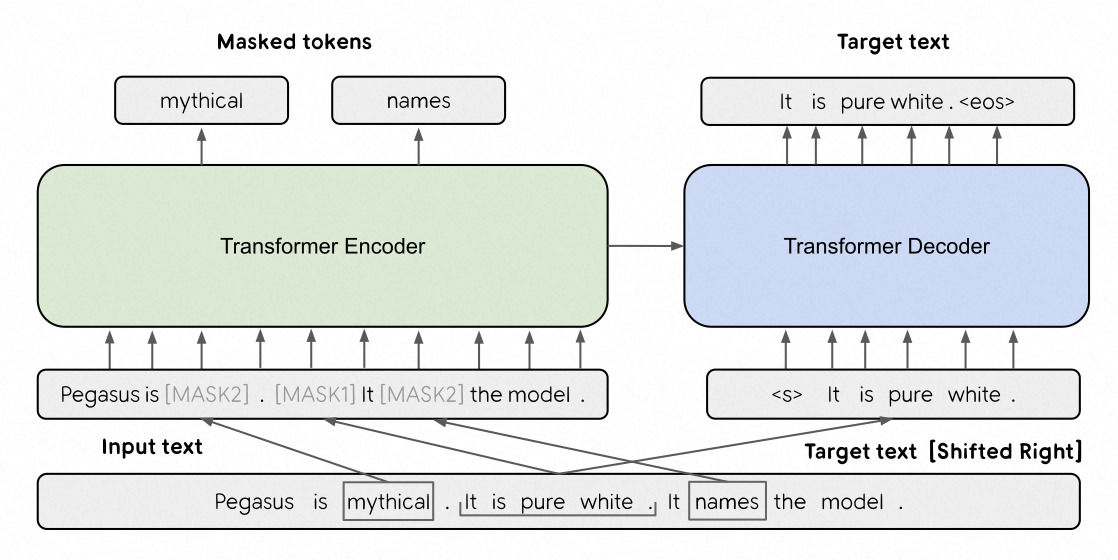
在此之前,文本生成预训练模型T5、BART等模型虽然在众多文本生成任务中取得了明显的性能增益,但是在文本摘要任务中,模型的预训练目标与文本摘要目标还是存在较大的差异。这导致此类预训练模型在迁移至不用领域的摘要任务时,仍然需要较多的训练数据对模型进行微调才能达到较好的效果。为了缓解上述问题,PEGASUS模型在原始的子词遮盖损失的基础上,增加了完整句子遮盖损失,即将输入文档中的随机几个完整句子进行遮盖,让模型复原。
具体地,如上图所示,PEGASUS采用编码器-解码器架构(标准transformer架构)。模型对输入采用两种遮盖,一种是BERT采用的子词遮盖,用【mask2】表示,让模型的编码器还原被遮盖的子词(该类损失在消融实验中被证明对下游任务无性能增益,因此在最终的PEGASUS模型中并未采用)。另一种是GSG,用【mask1】表示,即让解码器生成输入中被遮盖的随机完整句子。针对此损失,作者同时提出三种可选方案,包括Random(随机选择m个句子)、Lead(选择前m个句子)、Ind-Orig(根据重要性分数选择m个句子)。其中,重要性分数具体通过计算每句话与文档中其它句子集合的ROUGE分数得到。可以认为,该策略选择能够很大程度代表文档中其它句子的句子作为遮盖对象。下图展示了三种选句子方案的一个例子,所选句子分别被标记为绿色、红棕色、蓝色。实验表明,采用第三种句子选择策略的模型能够取得最优性能。

文本摘要模型使用教程
以下我们简要介绍如何在EasyNLP框架中使用PEGASUS以及其他文本摘要模型。
安装EasyNLP
用户可以直接参考GitHub(https://github.com/alibaba/EasyNLP)上的说明安装EasyNLP算法框架。
数据准备
在具体的文本摘要场景中,需要用户提供下游任务的训练与验证数据,为tsv文件。对于文本摘要任务,这一文件包含以制表符\t分隔的两列数据,第一列是摘要列,第二列为原文列。样例如下:
湖北:“四上企业”复工率已达93.8% 央视网消息:4月1日,记者从湖北省新冠肺炎疫情防控工作新闻发布会上获悉,在各方面共同努力下,湖北省复工复产工作取得了阶段性成效。截至3月31日,湖北省“四上企业”包括规模以上工业、规模以上服务业法人单位等的复工率已达93.8%,复岗率69.3%。武汉市的复工率、复岗率也分别达到了85.4%、40.4%。责任编辑:王诗尧下列文件为已经完成预处理的新闻标题生成训练和验证数据,可用于测试:
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/generation/title_gen.zip中文新闻标题生成
由于PEGASUS原文产出的模型仅支持英文,为了方便中文社区用户的使用,我们基于mT5的模型架构预训练了一个针对中文新闻标题摘要的模型mT5,并将其集成进EasyNLP的模型库中。同时,我们还集成了IDEA机构预训练的文本摘要中文模型Randeng(可以认为是中文版的PEGASUS),便于用户探索不同模型的性能。以下汇总了EasyNLP中可用的模型,并对比模型在上述数据集上的性能表现。推荐用户选择前两个模型进行文本摘要,后三个模型进行新闻标题生成。
| 中文 | 新闻标题(Rouge1/2/L) | 论文标题摘要(Rouge1/2/L) |
| hfl/randeng-238M-Summary-Chinese | 59.66/46.26/55.95 | 54.55/39.37/50.69 |
| hfl/randeng-523M-Summary-Chinese | 62.86/49.67/58.89 | 53.83/39.17/49.92 |
| alibaba-pai/mt5-title-generation-zh-275m | 62.35/48.63/58.96 | 54.28/40.26/50.55 |
| alibaba-pai/randeng-238M-Summary-Chinese-tuned | 64.31/51.80/60.97 | 58.83/45.28/55.72 |
| alibaba-pai/randeng-523M-Summary-Chinese-tuned | 64.76/51.65/61.06 | 59.27/45.58/55.92 |
在新闻标题生成任务中,我们采用以下命令对模型进行训练。用户可以根据超参数‘save_checkpoint_steps’来决定保存模型的步数,框架在此时会对训练的模型进行评测,会根据模型在验证集上的表现决定是否更新保存的模型参数。其中,运行的main.py文件在EasyNLP/examples/appzoo_tutorials/sequence_generation目录下,同时需要将训练和验证集数据放到该目录下。可以在‘user_defined_parameters’超参数下的‘pretrain_model_name_or_path’指定上述表格中的模型
- python main.py \
- --mode train \
- --app_name=sequence_generation \
- --worker_gpu=1 \
- --tables=./cn_train.tsv,./cn_dev.tsv \
- --input_schema=title_tokens:str:1,content_tokens:str:1 \
- --first_sequence=content_tokens \
- --second_sequence=title_tokens \
- --label_name=title_tokens \
- --checkpoint_dir=./finetuned_zh_model \
- --micro_batch_size=8 \
- --sequence_length=512 \
- --epoch_num=1 \
- --save_checkpoint_steps=150 \
- --export_tf_checkpoint_type none \
- --user_defined_parameters 'pretrain_model_name_or_path=alibaba-pai/mt5-title-generation-zh language=zh copy=false max_encoder_length=512 min_decoder_length=12 max_decoder_length=32 no_repeat_ngram_size=2 num_beams=5 num_return_sequences=5'

另外,用户可以利用以下命令使用模型进行摘要生成,模型的路径由‘checkpoint_dir’指定。用户可以通过‘append_cols’指定在输出文件中添加输入列,如果不指定则填none。
- python main.py \
- --mode=predict \
- --app_name=sequence_generation \
- --worker_gpu=1 \
- --tables=./cn_dev.tsv \
- --outputs=./cn.preds.txt \
- --input_schema=title:str:1,content:str:1,title_tokens:str:1,content_tokens:str:1,tag:str:1 \
- --output_schema=predictions,beams \
- --append_cols=content,title,tag \
- --first_sequence=content_tokens \
- --checkpoint_dir=./finetuned_zh_model \
- --micro_batch_size=32 \
- --sequence_length=512 \
- --user_defined_parameters 'language=zh copy=false max_encoder_length=512 min_decoder_length=12 max_decoder_length=32 no_repeat_ngram_size=2 num_beams=5 num_return_sequences=5'
以下为模型对近期热点事件预测的几条样例,每条样例包含5列数据(以制表符\t隔开),分别为预测的摘要列(新闻标题)、beam search的5条候选(用||隔开)、输入的原文、输入的新闻标签。其中后三列是从对应的输入数据中直接拷贝过来。由于新闻文本过长,以下仅展示每条样例的前四列结果。
- **费德勒告别信:未来我还会打更多的网球** 费德勒告别信:未来我还会打更多的网球||费德勒告别信:未来我还会打更多网球||费德勒告别信:未来我还会打更多网球但不是在大满贯或巡回赛||费德勒告别信:未来我还会打更多的网球||详讯:费德勒宣布退役,并告别信 **一代传奇落幕!网球天王费德勒宣布退役** 央视网消息:北京时间9月15日晚,网球天王罗杰-费德勒在个人社媒上宣布退役。41岁的费德勒是男子网坛历史最伟大球员之一,曾103次斩获单打冠军,大满贯单打夺冠20次(澳网6冠、法网1冠、温网8冠、美网5冠),共计310周位于男单世界第一。附费德勒告别信:在这些年网球给我的所有礼物中,最棒的毫无疑问是我一路上所遇到的人:我的朋友、我的竞争对手、以及最重要的球迷,是他们给予了这项运动生命。今天,我想和大家分享一些消息。正如你们中的许多人所知道的,过去三年中,我遇到了受伤和手术的挑战。......
- **台风“梅花”将在大连沿海登陆将逐步变性为温带气旋** 台风“梅花”将在大连沿海登陆将逐步变性为温带气旋||台风“梅花”将在大连沿海登陆后逐渐变性为温带气旋||台风“梅花”将在大连沿海登陆将逐渐变性为温带气旋||台风“梅花”将在大连沿海登陆后变性为温带气旋||台风“梅花”将在大连沿海登陆后逐渐变性 **台风“梅花”将于16日傍晚前后在辽宁大连沿海登陆** 记者9月16日从辽宁省大连市气象部门获悉,今年第12号台风“梅花”将于16日傍晚前后在大连市旅顺口区至庄河市一带沿海登陆,之后逐渐变性为温带气旋。 受台风“梅花”影响,14日8时至16日10时,大连全市平均降雨量为132毫米,最大降雨量出现在金普新区大李家街道正明寺村,为283.6毫米;一小时最大降雨量出现在长海县广鹿岛镇,为49.4毫米......
英文文本摘要
EasyNLP模型库中同样集成了英文文本摘要模型,包括PEGASUS和BRIO。以下表格展示了两个模型在英文文本摘要数据上的性能表现。用户同样可以使用上述代码对模型进行训练和预测。需要注意的是,EasyNLP默认的是对中文的处理,因此,当需要处理英文文本时,需要在‘user_defined_parameters’中指定language为en,如不提供,则默认为中文(zh)。
| 英文 | 文本摘要(Rouge1/2/L) |
| alibaba-pai/pegasus-summary-generation-en | 37.79/18.69/35.44 |
| hfl/brio-cnndm-uncased | 41.46/23.34/38.91 |
训练过程如下:
- wget http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/generation/en_train.tsv
- wget http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/generation/en_dev.tsv
-
- python main.py \
- --mode train \
- --app_name=sequence_generation \
- --worker_gpu=1 \
- --tables=./en_train.tsv,./en_dev.tsv \
- --input_schema=title:str:1,content:str:1 \
- --first_sequence=content \
- --second_sequence=title \
- --label_name=title \
- --checkpoint_dir=./finetuned_en_model \
- --micro_batch_size=1 \
- --sequence_length=512 \
- --epoch_num 1 \
- --save_checkpoint_steps=500 \
- --export_tf_checkpoint_type none \
- --user_defined_parameters 'language=en pretrain_model_name_or_path=alibaba-pai/pegasus-summary-generation-en copy=false max_encoder_length=512 min_decoder_length=64 max_decoder_length=128 no_repeat_ngram_size=2 num_beams=5 num_return_sequences=5'
预测过程如下:
- python main.py \
- --mode=predict \
- --app_name=sequence_generation \
- --worker_gpu=1 \
- --tables=./en_dev.tsv \
- --outputs=./en.preds.txt \
- --input_schema=title:str:1,content:str:1 \
- --output_schema=predictions,beams \
- --append_cols=title,content \
- --first_sequence=content \
- --checkpoint_dir=./finetuned_en_model \
- --micro_batch_size 32 \
- --sequence_length 512 \
- --user_defined_parameters 'language=en copy=false max_encoder_length=512 min_decoder_length=64 max_decoder_length=128 no_repeat_ngram_size=2 num_beams=5 num_return_sequences=5'
以下展示了模型对一篇热点科技新闻稿的摘要预测结果:
- With the image generator Stable Diffusion, you can conjure within seconds a potrait of Beyoncé as if painted by Vincent van Gogh, a cyberpunk cityscape in the style of 18th century Japanese artist Hokusai and a complex alien world straight out of science fiction. Released to the public just two weeks ago, it’s become one of several popular AI-powered text-to-image generators, including DALL-E 2, that have taken the internet by storm. Now, the company behind Stable Diffusion is in discussions to raise $100 million from investors, according to three people with knowledge of the matter. Investment firm Coatue expressed initial interest in a deal that would value the London-based startup Stability AI at $500 million, according to two of the people. Lightspeed Venture Partners then entered talks — which are still underway — to invest at a valuation up to $1 billion, two sources said. Stability AI, Coatue and Lightspeed declined requests for comment. The London-based startup previously raised at least $10 million in SAFE notes (a form of convertible security popular among early-stage startups) at a valuation of up to $100 million, according to one of the sources. An additional fourth source with direct knowledge confirmed Stability AI’s previous round. Much of the company’s funds came directly from founder and CEO Emad Mostaque, a former hedge fund manager. News of the prior financing was previously unreported. By nature of being open source, Stability AI’s underlying technology is free to use. So far, the company does not have a clear business model in place, according to three of the sources. However, Mostaque said in an interview last month with Yannic Kilcher, a machine learning engineer and YouTube personality, that he has already penned partnerships with “governments and leading institutions” to sell the technology. “We’ve negotiated massive deals so we’d be profitable at the door versus most money-losing big corporations,” he claims. The first version of Stable Diffusion itself cost just $600,000 to train, he wrote on Twitter — a fraction of the company’s total funding. Mostaque, 39, hails from Bangladesh and grew up in England. He received a master’s degree in mathematics and computer science from Oxford University in 2005 and spent 13 years working at U.K. hedge funds. In 2019, he launched Symmitree, a startup that aimed to reduce the cost of technology for people in poverty; it shuttered after one year, according to his LinkedIn profile. He then founded Stability AI in late 2020 with the mission of building open-source AI projects. According to its website, text-to-image generation is only one component of a broader apparatus of AI-powered offerings that the company is helping to build. Other open-source research groups it backs are developing tools for language, audio and biology. Stable Diffusion — created in collaboration with RunwayML, a video editing startup also backed by Coatue, and researchers at the Ludwig Maximilian University of Munich — has generated by far the most buzz among the company’s projects. It comes as AI image generators entered the zeitgeist this year, with the release of OpenAI’s DALL-E 2 in April and independent research lab Midjourney’s eponymous product in July. Google also revealed a text-to-image system, Imagen, in May, though it is not available to the public. Mostaque and his peers have said that the existing technology only represents the tip of the iceberg of what AI art is capable of creating: Future use cases could include drastically improved photorealism, video and animation. These image generators are already facing controversy: Many of them have been trained by processing billions of images on the internet without the consent of the copyright holder, prompting debate over ethics and legality. Last week, a testy debate broke out online after a Colorado fine arts competition awarded a top prize to an AI-generated work of art. Moreover, unlike DALL-E and Midjourney, which have restrictions in place to prevent the generation of gory or pornographic images, Stable Diffusion’s open source nature allows users to bypass such a block. On 4chan, numerous threads have appeared with AI-generated deepfakes of celebrity nudes, while Reddit has banned at least four communities that were dedicated to posting “not safe for work” AI imagery made using Stable Diffusion. It’s a double-edged sword for Stability AI, which has accumulated community goodwill precisely due to its open source approach that gives its users full access to its code. The company’s website states that the company is “building open AI tools,” a mission that mirrors the initial intent of OpenAI to democratize access to artificial intelligence. OpenAI was launched as a nonprofit research organization by prominent technologists including Sam Altman and Elon Musk, but upon accepting a $1 billion investment from Microsoft in 2019, it became a for-profit business. The move led it to focus on commercializing its technology rather than making it more widely available, drawing criticism from the AI community — and Musk himself. Stability AI has been a for-profit corporation from its inception, which Mostaque has said is meant to allow the open source research to reach more people. In an interviewwith TechCrunch last month, he said that the company was fully independent. “Nobody has any voting rights except our 75 employees — no billionaires, big funds, governments or anyone else with control of the company or the communities we support,” he said. At a $1 billion valuation, Mostaque would be ceding up to 10% of the company to the new financiers. Venture capital investors who take significant stakes in startups typically ask for board positions so they can influence the decisions the company is making using their money. Lightspeed, which manages $10 billion of assets, and Coatue, which is in charge of $73 billion, both have a track record of taking board seats, though it’s unclear if that will be the case with Stability AI. Follow me on Twitter. Send me a secure tip.
-
针对上述新闻原稿,以下为两个最新模型的摘要生成结果:
stable Diffusion is in discussions to raise $100 million from investors, three people say. The image generator is one of several popular AI-powered text-to-image generators.company behind the popular image generator Stable Diffusion is in talks to raise $100 million from investors, according to sources以上是如何利用EasyNLP进行文本摘要模型训练和预测的全部过程,更详细的使用教程可加入以下课程进行学习。标题党速成班:基于机器学习PAI EasyNLP的中文新闻标题生成
未来展望
在未来,我们计划在EasyNLP框架中集成面向知识的中⽂预训练模型,覆盖各个常⻅的NLU和NLG中⽂领域,敬请期待。我们也将在EasyNLP框架中集成更多SOTA模型(特别是中⽂模型),来⽀持各种NLP和多模态任务。此外, 阿⾥云机器学习PAI团队也在持续推进中文文本生成和中⽂多模态模型的⾃研⼯作,欢迎⽤户持续关注我们,也欢迎加⼊ 我们的开源社区,共建中⽂NLP和多模态算法库!
Github地址:https://github.com/alibaba/EasyNLP
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. arXiv
- Zhang, Jingqing, et al. "Pegasus: Pre-training with extracted gap-sentences for abstractive summarization." International Conference on Machine Learning. PMLR, 2020.
- Xue, Linting, et al. "mT5: A massively multilingual pre-trained text-to-text transformer." arXiv preprint arXiv:2010.11934(2020).
- Lewis, Mike, et al. "Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension." arXiv preprint arXiv:1910.13461 (2019).
- Song, Kaitao, et al. "Mass: Masked sequence to sequence pre-training for language generation." arXiv preprint arXiv:1905.02450 (2019).
- Dong, Li, et al. "Unified language model pre-training for natural language understanding and generation." Advances in Neural Information Processing Systems 32 (2019).
- Yixin Liu, Pengfei Liu, Dragomir Radev, and Graham Neubig. 2022. BRIO: Bringing Order to Abstractive Summarization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2890–2903, Dublin, Ireland. Association for Computational Linguistics.

