
- 1c++随机数_c++算法训练随机数(蓝桥杯)--足球比赛
- 2iOS开发高级分享 - MacOSCatalina和Xcode 11 的快速UI预览_macos catalina xcode
- 3DappRadar x BGA 7月链游报告:链游占行业用量近60%,融资额降至3亿美元
- 4RabbitMQ配置SSL_rabbitmq ssl
- 5NLP经典论文复现_自然语言处理论文复现
- 6用vscode对ROS进行debug_vscode ros debug
- 7Java实现 LeetCode N皇后(回溯+dfs)_n皇后问题dfs回溯java
- 8【前端】代码警告处理Parsing error: Unexpected token <eslint或Parsing error: Unexpected token =eslint_parsing error: unexpected token <
- 9Pycharm中安装pytorch_pycharm安装pytorch
- 10Python爬虫超详细讲解(零基础入门,老年人都看的懂)
PE-YOLO: Pyramid Enhancement Network for Dark Object Detection——论文笔记
赞
踩
摘要(Abstract):
当前,目标检测模型在许多基准数据集上取得了良好的结果,但是在暗光条件下检测物体仍然是一大挑战。为解决这一问题,我们提出了一个金字塔增强网络(pyramid enhanced network, PENet),将其与YOLOv3结合,建立了一个名为PE-YOLO的暗目标检测框架。首先,PENet使用拉普拉斯金字塔(Laplacian pyramid)从图片中分解出四个不同分辨率的分量。值得一提的是,我们提出了一个细节处理模块(detail processing module, DPM)去提升图像的细节,其由上下文分支(context branch)和边缘分支(edge branch)两个分支组成。此外,我们还提出了一个低频增强滤波器(low-frequency enhancement filter, LEF)来获取低频语义信息和避免高频噪声。PE-YOLO采用端到端的训练模式并只使用普通的检测损失,以简化训练过程。我们通过在低照度目标检测数据集ExDark上实验,证明了所提出方法的有效性。实验结果表明,与其他的暗光检测器和低照度增强模型相比,PE-YOLO实现了最优的结果——78.0%mAP和53.6FPS,并可以适应各种不同低照度环境下的目标检测。
Keywords: Object detection; Low-light perception; Pyramid enhancement
关键词:目标检测;低照度感知;金字塔增强
filter和kernel的区别:https://blog.csdn.net/weixin_38481963/article/details/109906338
1、引言(Introduction)
近年来,卷积神经网络的出现促进了目标检测的发展。大量的检测器被提出,并且在基准数据集上取得了良好的结果。然而,现有目标检测器的研究对象多为正常环境下的高质量图片。在真实环境下,经常会存在诸如夜晚、暗光和曝光等光照条件不好的情况,导致图片的质量下降从而影响检测器的性能。视觉感知模型使得自动系统能够理解环境,并为诸如路径规划等下游任务奠定基础,但这需要一个鲁棒的目标检测或语义分割模型。图1为暗目标检测的样例。由图可知,如果适当地增强图片,并根据环境状况重建更多原本模糊物体的潜在信息,则目标检测模型可被应用于不同的低照度场景,这也是模型在实际应用中的一个巨大挑战。

图1:暗目标检测示例。在暗光条件下,PE-YOLO可以恢复目标的更多潜在信息以获得更好的检测结果。
当前,许多方法被提出以解决暗光场景下的鲁棒性问题。许多低照度增强模型被提出用于重建图片细节并减少暗光带来的影响。然而,低照度增强模型的网络结构复杂,在增强图片后降低了检测器的实时性。此外,大多数方法无法与检测器一起进行端到端的训练,并且有监督学习需要配对的暗光-正常光图像对。暗光条件下的目标检测也可以被看作为域适应问题。一些研究者使用对抗学习将模型域从正常光迁移到暗光。但是,他们专注于匹配域间的数据分布,而忽略了包含在低照度图像中的潜在信息。在过去的几年里,有些研究者提出了使用可微图像处理模块(differentiable image processing, DIP)的方法去增强图像和以端到端的形式训练检测器。然而,DIP是诸如白平衡这样的传统方法,对图像的增强效果有限。
域适应(domain adaptation):域自适应的理解(简单易懂)_疯狂java杰尼龟的博客-CSDN博客
可微图像处理模块(differentiable image processing, DIP):
为解决上述问题,我们提出了一种金字塔增强网络(PENet),可用于增强低照度图像和获取目标的潜在信息。我们联合PENet和YOLOv3以建立一个端到端的暗目标检测框架PE-YOLO。在PENet 中,我们首先使用拉普拉斯金字塔(Laplacian pyramid)从图像中分解出多个不同分辨率的分量。针对金字塔中每一个尺度的分量,我们提出了细节处理模块(DPM)和低频增强滤波器(LEF)以增强这些分量。细节处理模块(DPM)由上下文分支和边缘分支组成。上下文分支通过获取远距离依赖来从全局增强分量,而边缘分支则是增强分量的纹理特征。LEF使用动态低通滤波器来获取低频语义信息和防止高频噪声,从而丰富特征信息。在训练过程中,我们仅仅使用普通的检测损失函数以简化训练过程,并且不需要图像的ground truth。我们在低照度目标检测数据集ExDark上验证了我们方法的有效性,结果表明,与其他的暗光检测器和低照度增强模型相比,PE-YOLO实现了最优的结果,达到了78.0%mAP和53.6FPS,可以在暗光条件下进行目标检测。
低通滤波器(low-pass filter):【计算机视觉】图像分割与特征提取——频域增强(低通滤波&高通滤波)_赵四司机的博客-CSDN博客
我们的贡献如下:
1、我们建立了金字塔增强网络(PENet)用于增强不同的低照度图像。并提出了细节处理模块(DPM)和低频增强滤波器用于增强分量。
2、通过联合PENet和YOLOv3,我们提出了一个端到端训练的暗目标检测框架PE-YOLO,以适应暗光环境。在训练中,我们只使用了普通的检测损失函数。
3、与其他的暗检测器和低照度增强模型相比,PE-YOLO在ExDark数据集上实现了最优的结果和可观的准确率及速度。
2、相关工作(Related Work)
2.1 目标检测(Object Detection)
目标检测模型可以分为三类:单阶段模型、两阶段模型和基于anchor-free的模型。Faster RCNN没有通过选择性搜索来获得推荐区域,而是通过区域推荐网络。它能使候选区域推荐、特征提取、分类和回归在同一个网络中进行端到端的训练。蔡等人提出了Cascade RCNN,它级联多个检测头,并且当前级别可以改善上一级的回归、分类结果。YOLOv3提出了新的特征提取网络DarkNet-53。受特征金字塔网络启发(FPN),YOLOv3采用多尺度特征融合。此外,最近基于anchor-free的检测器出现,他们放弃了锚点,改为基于关键点检测。
2.2 低照度增强(Low-light Enhancement)
低照度增强任务的目标是通过重建图像细节和校正色彩失真以提升人们的视觉感知以及为诸如目标检测这样的高级视觉任务提供高质量的图像。张等人提出了Kind,它可以通过不同照明等级的图像对进行训练,不需要ground truth。郭等人提出了Zero DCE,它将低照度增强任务转换为特定图像曲线估计问题。吕等人提出了多分支低照度增强网络——MBLLEN,它可以提取不同层级的特征,并通过多分支融合来生成输出图片。崔等人提出照明适应Transformer(IAT),通过动态查询学习来构建了一个端到端的Transformer。通过低照度增强模型重建图像细节后,检测器的效果得到了提升。然而,大部分的低照度增强模型是复杂的,它们对检测器的实时性能有极大的影响。
2.3 恶劣环境下的目标检测(Object Detection in Adverse Condition)
在恶劣条件下进行目标检测对机器人的鲁棒感知是至关重要的。针对某些恶劣条件下的鲁棒目标检测模型已经提出。有些研究者通过无监督的域适应将检测器从源域转换到目标域,以让模型适应恶劣的环境。刘等人提出IA-YOLO,它可以自适应地增强图片以提升检测性能。他们针对恶劣环境提出了可微图像处理(DIP)模块并使用一个小的卷积神经网络(CNN-PP)来调节DIP的参数。基于IA-YOLO,Kalwar等人提出了GDIP-YOLO。GDIP通过门控机制实现多个DIP进行并行操作。秦等人提出了检测驱动的增强网络(DENet)用于在恶劣天气下进行目标检测。崔等人针对暗目标检测提出了多任务自动编码转换,探索照明变化后的潜在空间。
3、方法(Method)
由于受暗光干扰,低照度图片具有低可见度。为解决这一问题,我们提出了金字塔增强网络(PENet)并联合YOLOv3建立了暗目标检测框架PE-YOLO,其整体框架如图2。
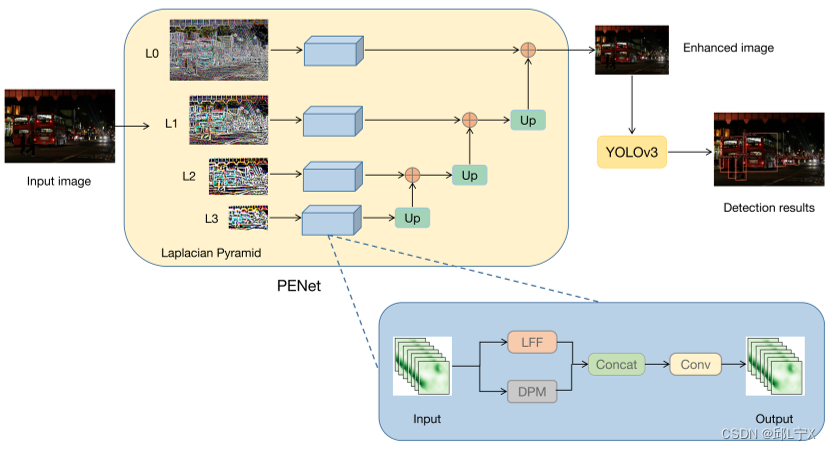
图2:PE-YOLO框架。我们使用细节处理模块(DPM)和低频增强滤波器(LEF)来增强图像。
3.1 PE-YOLO概述
PENet通过拉普拉斯金字塔将图像分解为不同分辨率的分量。在PENet中,我们通过DPM和LEF增强不同尺度的分量。
定义图像作为输入,我们可以通过高斯金字塔来获得不同分辨率的子图像。
(1)
其中,Down 为下采样,Gaussian 为高斯滤波器,高斯核的尺寸为5*5。在经过每一次高斯金字塔操作后,图像的宽高都会减半,也意味着图像的分辨率会下降为原始的1/4。显而易见,高斯金字塔的下采样操作是不可逆的。为能在下采样后恢复原始的高分辨率图像,需要这些丢失的信息,而这些丢失的信息构成了拉普拉斯金字塔(Laplacian pyramid)。拉普拉斯金字塔可定义为:
(2)
为拉普拉斯金字塔的第
层,
为拉普拉斯金字塔的第
层,Up 为双边上采样操作。当需要重建图片时,我们只需要执行公式(2)的逆操作即可重建高分辨率的图片。
如图3所示,我们可以通过拉普拉斯金字塔来获得不同尺度的四个分量。我们发现拉普拉斯金字塔自底向上会将更多的注意力放在全局的信息上,相反自顶向下会更专注于局部的细节。这四个分量是图片下采样过程中丢失的全部信息,也是我们PENet增强的目标。我们通过DPM和LEF对这些分量进行增强,DPM和LEF的操作是并行的。我们将会在下一部分对DPM和LEF进行介绍。通过分解和重建拉普拉斯金字塔,PENet可以做到轻量但有效,有助于提升PE-YOLO的性能。

图3:拉普拉斯金字塔每一层的可视化结果。第二至第五列为拉普拉斯金字塔的组件,从左往右分辨率递减。
疑问:
重建高分辨率图像为公式(2)的逆过程,即:
图2中,拉普拉斯金字塔将
作为输入,进行增强、上采样和拼接,是否是未显式画出将
进行拼接的过程。
3.2 细节增强(Detail Enhancement)
我们提出了细节处理模块(DPM)去增强拉普拉斯金字塔中的各分辨率的分量(),DPM可分为上下文分支和边缘分支。DPM的细节如图4所示。上下文分支通过捕获远距离依赖以获得上下文信息,从而从全局增强各分量。边缘分支使用两个Sobel算子计算图像不同方向的梯度以获取边缘信息和增强各分量的纹理特征。
上下文分支(Context branch):
在获取远距离依赖前后,我们使用残差块来处理特征,残差块学习可以使得丰富的低频信息通过跳跃连接传递。第一个残差块将特征通道数由3改为32,第二个残差块将特征通道数由32改为3。获取全局信息被证实对诸如低照度增强这样的低级视觉任务是有益的。图4展示了上下文分支的结构,其定义如下:
(3)
其中,,
是卷积核为3*3的卷积层,
是Leaky ReLU,
是Softmax函数。
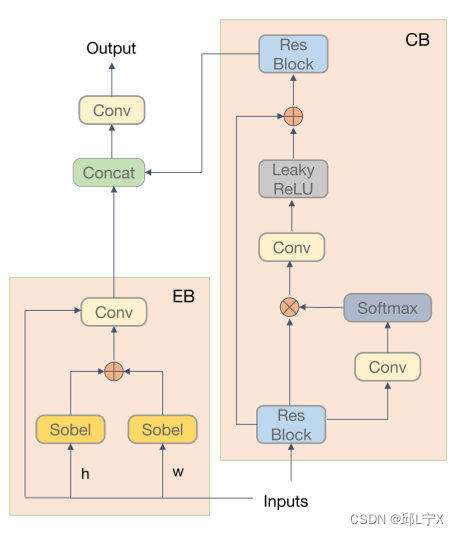
图4:DPM细节,包含上下文分支和边缘分支。
边缘分支(Edge branch):
Sobel算子是一个同时使用高斯滤波器和微分推导的可分离算子,可以通过计算梯度的近似值来找到图像中物体的边缘。我们在水平和垂直两个方向上使用Sobel算子并通过卷积滤波器以再次提取边缘信息,且通过残差来增强信息流。这一过程可以表示为:
(4)
其中,、
分别代表垂直和水平方向上的Sobel算子。
Sobel算子(Sobel operator):https://baike.baidu.com/item/%E7%B4%A2%E8%B4%9D%E5%B0%94%E7%AE%97%E5%AD%90/15805328
3.3 低频增强滤波器(low-frequency enhancement filter, LEF)
在每个尺度的分量中,低频分量包含最多的图像语义信息,它们是检测器预测的关键信息。为丰富重建图像中的语义信息,我们提出低频增强滤波器来获取分量中的低频信息。LEF的细节如图5所示。假设分量 ,我们首先通过卷积层将其转换为
。我们使用动态低通滤波器来获取低频信息,然后通过平均池化来过滤特征,使得低于阈值的信息可以通过。不同语义信息的低频阈值是不同的。借鉴Inception的多尺度结构,我们使用1*1,2*2,3*3,6*6的自适应池化,并在不同尺度分支的最后使用上采样,以将特征重建至原始尺寸。使用不同尺的寸卷积核进行平均池化,就形成了低通滤波器。我们通过通道分离,将
分为四部分,名为
。每部分由不同尺度的池化层处理,定义为:
(5)
其中, 是
进行通道分离后的某一部分,Up 是双边插值采样,
是s*s大小尺寸的自适应平均池化层。最后,在对
进行张量拼接后,我们将其重建为
。

图5:LEF细节。LEF由不同尺寸的自适应平均池化层组成以截取低频分量。
4、实验(Experiments)
4.1 数据集和实施细节
数据集:
我们使用ExDark来验证PE-YOLO的有效性。ExDark是用于研究目标检测和图像增强的低照度目标检测数据集。它总共收集了10种不同照明条件下(从极暗的光到黄昏)的共7363张图像,图像中有12个物体的边界框标注。我们将数据集的80%用于训练,20%用于测试。具体的划分与IAT和MAET保持一致。
IAT论文地址:https://arxiv.org/abs/2205.14871
MAET论文地址:https://arxiv.org/abs/2205.03346
细节:
所有的训练、测试图像被裁剪为608*608大小,在训练中采用了诸如随机裁剪、翻转和多尺度裁剪的数据增广方法。批处理大小设置为8,优化器采用SGD,初始学习率设置为0.001,权重衰减设置为0.0005。在单张RTX3090GPU上训练30个epoch。深度学习框架采用Pytorch,我们使用mmdetection来完成我们的模型。
评价指标:
我们使用mAP和FPS作为验证模型有效性的评价指标。mAP是检测模型中所有类别的平均检测精度,值越大意味着模型的准确率越高。mAP可表示为:
(6)
其中, 是所有种类的数量,
是每个种类的平均准确率,由Precision Recall曲线的面积计算得来。FPS是模型每秒检测的图片数量,FPS越大意味着模型检测速度越快。
4.2 实验结果
为验证PE-YOLO的有效性,我们在ExDark数据集上进行了多个实验。首先,我们将PE-YOLO与其他低照度增强模型进行比较。由于低照度增强模型缺乏检测能力,我们使用与PE-YOLO一致的检测器在所有的增强图片上。我们设置mAP的IoU阈值设置为0.5,对比结果如表1所示。我们发现,直接在YOLOv3前使用低照度增强模型不能显著的提高检测性能。PE-YOLO相较于MBLLEN和Zero-DCE分别高出1.2%和1.1%,达到了最优。
表1:PE-YOLO和其他低照度增强模型的性能对比。展示了mAP和每个类别的AP。加粗的数字为每列的最大值。

如图6所示,我们展示了所有低照度模型的检测结果。我们发现尽管MBLLEN和Zero DCE显著提升了图像的亮度,但同时也放大了图像噪声。PE-YOLO主要捕获了低照度图像中目标的显著信息,同时也抑制了高频分量中的噪声,因此PE-YOLO有最好的检测性能。

图6:PE-YOLO和其他低照度增强模型检测结果。
表2:PE-YOLO和其他暗检测器的性能对比。粗体为每列的最大值。

如表2所示,我们比较了PE-YOLO与其他暗检测器的性能。如图7所示,我们展示了PE-YOLO和其他暗检测器的检测结果,可直观的看出PE-YOLO具有更好的检测准确率。PE-YOLO较在LOL上进行预训练后的DENet和IAT-YOLO,在mAP上分别高出0.7%和0.2%,并且具有最高的FPS。由上述数据可知PE-YOLO更适合在暗光环境下进行目标检测

图7:PE-YOLO和其他暗检测器的检测结果。
4.3 消融实验
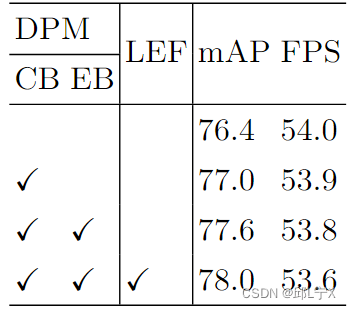
为分析PE-YOLO中各组件的有效性,我们进行了消融实验,结果如表3所示。采用上下文分支后,PE-YOLO的mAP由76.4%提升至77.0%,意味着获取远距离依赖对于增强是有效的。采用边缘分支后,mAP由77.0%提升至77.6%,意味着边缘分支可以增强分量的纹理特征并增强图片的细节。采用LEF后,mAP由77.6%提升至78.0%,意味着获取低频分量有利于获取图像的潜在信息,最终,我们模型在FPS仅仅降低0.4的情况下,mAP由76.4%提升至78.0%。
表3:PE-YOLO消融实验。“CB”代表上下文分支,“EB”代表边缘分支,“LEF”代表低频增强滤波器。
5、结论(Conclusion)
为实现更加鲁棒的暗目标检测,我们提出了一个金字塔增强网络(pyramid enhancement network, PENet),其可实现细节重建并获取图片中的潜在信息。通过结合PENet和YOLOv3,我们建立了一个名为PE-YOLO的暗目标检测框架。我们首先通过拉普拉斯金字塔(Laplacian pyramid)从图像中分解出四个不同分辨率的分量,然后提出一个细节处理模块(detail processing module, DPM)和低频增强滤波器(low-frequency enhancement filter, LEF)进行分量增强。另外,PE-YOLO通过端到端的方式训练,没有使用额外的损失函数。我们在ExDark数据集上进行实验,结果表明,与其他的低照度增强模型和暗检测器相比,PE-YOLO实现了最优的结果并可以有效的在暗光环境下检测。然后,我们的模型还应研究更多的检测器,使其在保持轻量的前提下进一步提升性能。

