
《NoSQL实战:企业级大数据应用开发入门、实战与进阶》
参考资料
https://db-engines.com/en/ranking
数据简史

数据库的诞生
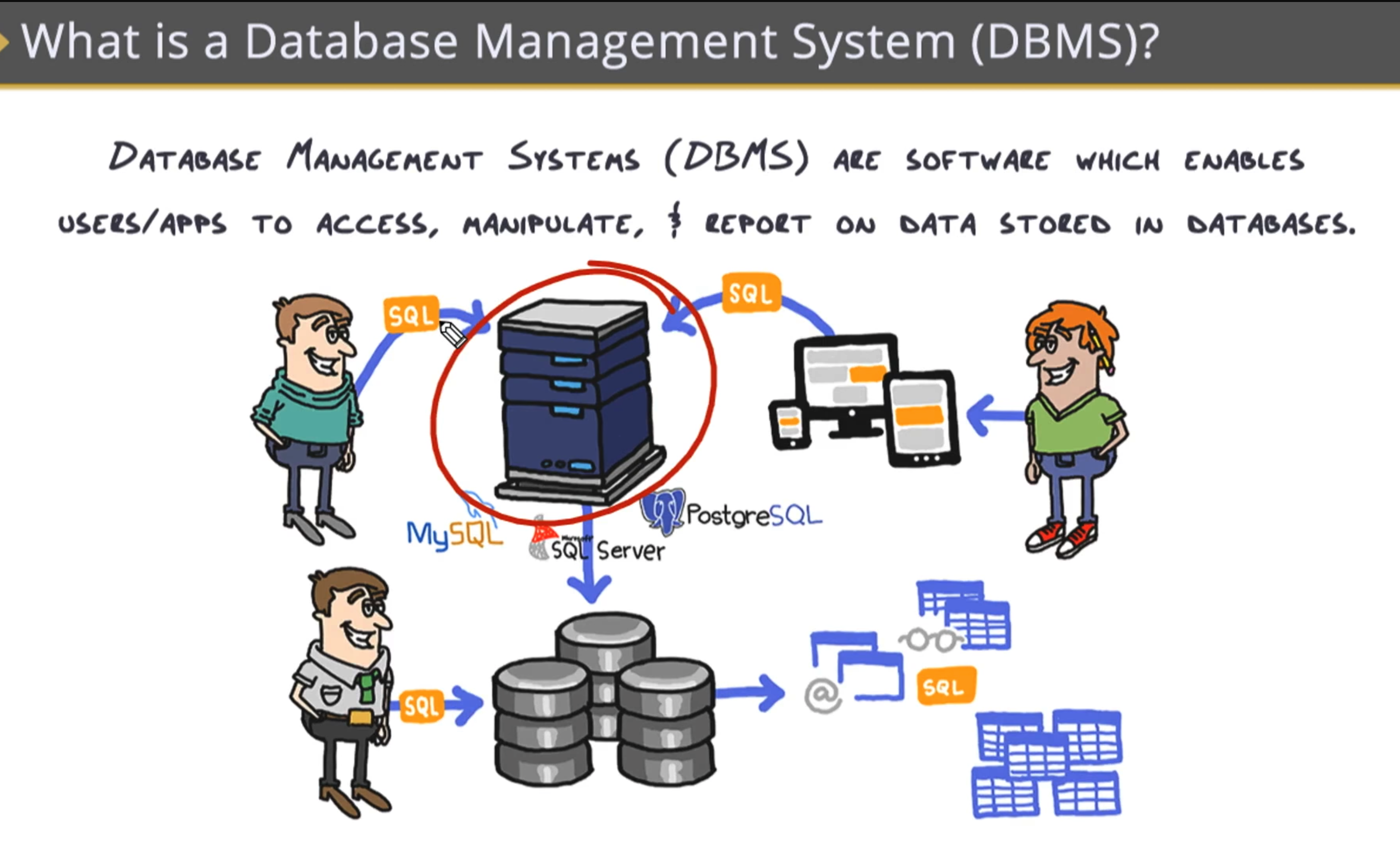
数据库王者:关系数据库与SQL
大数据时代:NoSQL横空出世
如何学习和使用NoSQL数据库
数据存储基础知识
事务
ACID
并发操作与锁
CAP
BASE
NoSQL:创造数据世界新秩序
NoSQL是什么
NoSQL特性
NoSQL数据库分类
NoSQL使用场景
NoSQL生态
NoSQL在国内使用案例介绍
NoSQL在国外使用案例介绍
基于内存键值数据库Redis实现分布式锁和缓存

Redis简介
Redis概述
Redis特性
Redis基本用法
Redis适用场景
项目实战一:实现分布式锁
项目实战二:实现分布式缓存
基于OLAP数据库ClickHouse实现DMP用户标签圈选洞察平台
ClickHouse简介
ClickHouse概述
ClickHouse特性
ClickHouse基本用法
ClickHouse适用场景
基于宽列存储数据库HBase实现在线数据查询服务

HBase简介
HBase概述
宽列式数据库,基于Apache Hadoop和BigTable的概念。
Apache HBase是一种NoSQL键/值存储系统,它在Hadoop分布式文件系统(HDFS)上运行。
HBase特性
不像Hive,HBase操作在数据库上,而不是MapReduce作业上实时运行。
HBase分成表,表又细分成列族(column family)。列族必须在模式中加以声明,它将某一组列(列不需要模式定义)分为小组。比如说,“message”列族可能包括以下这几列:“to”、“from”、“date”、“subject”和“body”。HBase中的每个键/值对被定义为一个单元(cell),每个键含有行键、列族和时间戳。HBase中的行是一组键/值映射,由行键来识别。HBase可以使用Hadoop的基础设施,并使用现成服务器实现横向扩展。
HBase的工作方式是,将数据存储为键/值。它支持四种主要的操作:添加或更新行的put,检索一组单元的scan,返回某个指定行的单元的get,以及从表上删除行、列或列版本的delete。拥有版本控制功能,那样可以获取数据的之前值(历史记录可以通过HBase压缩时不时删除,以释放空间)。虽然HBase包括表,但只有表和列族才需要模式,列不需要模式,它还包括增量/计数器功能。
HBase基本用法
HBase查询用一种需要学习的自定义语言来编写。可以通过Apache Phoenix,获得类似SQL的功能,不过其代价是需要维护模式。此外,HBase并不完全符合ACID,不过它确实支持某些属性。最后但并非最不重要的是,为了运行HBase,就需要ZooKeeper――这是面向分布式协调的服务器,比如配置、维护和命名。
HBase最适合大数据的实时查询。Facebook将它用于消息传递和实时分析。Facebook甚至将它用于计数Facebook点赞。
Hbase有集中式架构, Master服务器负责监控集群中的所有RegionServer(负责服务和管理区域)实例,它也是查看所有元数据变化的界面。它提供了CAP原理中的CP(一致性和可用性)。
HBase针对读取操作进行了优化,得到单次写入master的支持,支持因而获得的严格一致性模型,以及使用支持行扫描的顺序分区(Ordered Partitioning)。HBase很适合执行基于范围的扫描。
线性可扩展性,支持大表和范围扫描--由于顺序分区,HBase很容易横向扩展,同时仍支持行键范围扫描。
辅助索引--Hbase并不直接支持辅助索引,但触发器的一个使用场合是,“put”方面的触发器会自动确保辅助索引是最新版本,因而并不给应用程序(客户端)添加负担。
简单聚合--Hbase Co Processors支持HBase中的即开即用的简单聚合。SUM、MIN、MAX、AVG和STD。如果定义java类,就可以构建其他聚合,从而执行聚合操作。
实际应用:Facebook Messanger
HBase适用场景
搭建开发环境
基于搜索引擎 ElasticSearch 实现商品搜索
ElasticSearch简介
ElasticSearch概述
ElasticSearch特性
ElasticSearch基本用法
ElasticSearch适用场景
搭建开发环境
基于文档数据库MongoDB实现商品评论管理

https://developer.aliyun.com/article/64352https://www.zhihu.com/question/32071167
MongoDB简介
MongoDB概述
MongoDB特性
MongoDB基本用法
MongoDB适用场景
MongoDB项目实战
搭建开发环境
基于宽列存储数据库Cassandra实现在线交易系统

Cassandra简介
https://cassandra.apache.org/_/index.htmlhttps://developer.aliyun.com/article/713847https://www.cnblogs.com/datastax/p/14160683.html
Cassandra(卡珊德拉)是希腊神话中特洛伊国王普里阿摩斯的女儿,她是一个具有预言能力的先知,却因受到阿波罗诅咒,其预言永远不得被人们相信。Cassandra预见到了特洛伊城的毁灭,却因无人相信而无力阻止。
有人曾这样评述卡珊德拉:她和古希伯来的众先知一样直视事理的真相,不论过去、现在或未来;但是她的明晰无误的眼力,和她心中负荷的宇宙事理的可怖奥秘,却使她隔绝于正常的人生,使她在世人眼中成了个疯子。这便是古来先知们一再遭遇的命运。
虽然Cassandra作为先知不被人相信,但是作为一种面向未来的技术,越来越多的开发者和科技公司已经看到了Cassandra的价值并且从中受益。
Cassandra简介
Apache Cassandra是一种开源的、分布式的NoSQL数据库。它最早是由Facebook内部开发,后来于2008年7月公开了源码。
Cassandra不仅具有现代应用所要求的持续可用性(没有宕机时间)、高性能以及线性扩展的特点,其操作也十分简易,而且可以便捷地跨数据中心和跨区域进行数据复制。
Cassandra可以支持PB级别的信息处理,也可以负载每秒上百万条的并发操作。强大的功能使得Cassandra能够帮助企业和组织在多云及混合云架构中处理巨量的数据。
作为一个在Cassandra这项技术上深耕十余年的企业,DataStax致力于同开源社区一起开创属于Cassandra的世代,并巩固其在云原生应用数据库中的领先地位。

Cassandra最早是由Facebook工程师Avinash Lakshman和Prashant Malik开发,用于提高Facebook邮件收件箱的搜索功能。通过使用Cassandra,用户可以更快地找到他们需要的邮件和内容。
Cassandra的架构结合了亚马逊Dynamo论文中提出的分发模型和Google BigTable论文中描述的日志结构存储引擎(log-structured storage engine),从而实现了在不同节点间的横向拓展。其结果是Cassandra作为一种高可拓展性的数据库,能搞定大多数数据量巨大及性能密集型的使用场景。
2008年7月,Facebook公开了Cassandra的源码。2009年3月,Cassandra成为了Apache孵化器的开源项目。之后在2010年4月,Cassandra从Apache孵化器毕业,成为了Apache基金会的最高级别项目之一。时至今日,Cassandra在Apache许可证2.0版本下可自由使用。
https://www.infoq.cn/article/j0mfq1cntskbk5rbdpvl
在《Cassandra The Definitive Guide》这本书里,有一段概括性的描述,即用 50 个 word 描述 Cassandra。它归纳了 Cassandra 的几大特性,依次为:开源、分布式、去中心化、可扩展性、高可用、容错性、可配置的一致性、行存储。
我把这几大特性分为四类:
第一类开源,这个不需要讨论。其余的三类 7 个特性,就是选讲的核心提纲。
第二类是高可用、容错性、可配置的一致性,这是围绕着多节点冗余数据的特性,换句话说,如果 Cassandra 的数据,每一行数据只有一份而没有副本,那么第二类特点就是不存在的。
第三类是分布式、去中心化、可扩展性,这三个特点围绕的是数据库的可拆分性,且各节点可以独立运行的能力。若只装一个单机的 Cassandra,那这一类特点就不存在。
第四类是行存储,是描述数据库底层存放数据的最基本的存储结构特征,也是我切入的第一个特征。
Cassandra概述
宽列式数据库,基于BigTable和DynamoDB的概念。
Apache Cassandra是一种主要的NoSQL分布式数据库管理系统,它支撑着如今的许多现代商务应用系统,它提供了持续可用性、高扩展性和高性能、强安全性和操作简单性,同时降低了总体拥有成本。
Cassandra特性
https://www.infoq.cn/article/j0mfq1cntskbk5rbdpvl
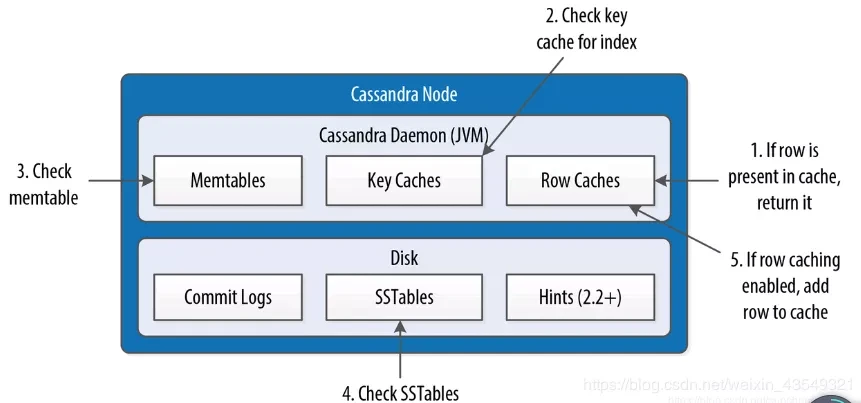
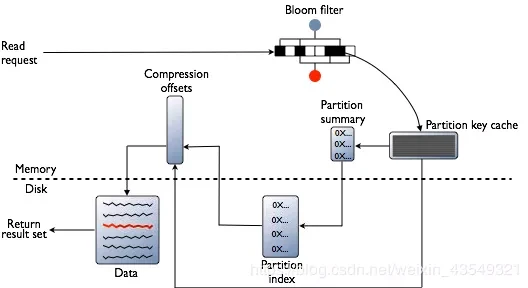
Cassandra基本用法
Cassandra适用场景
Cassandra项目实战
搭建开发环境
https://cassandra.apache.org/_/quickstart.html

