
- 1数据结构与算法——排序算法_用两个栈实现冒泡排序
- 2斯坦福大学-自然语言处理入门 笔记 第九课 信息抽取(information extraction)_information extraction model
- 3【JavaScript】手写Promise
- 4基于FPGA的数字信号处理3.7开平方运算分析_fpga开根号
- 5Windows配置Java环境_java windows
- 6SPI读写SD卡速度有多快?_sd卡spi读写速度
- 7pycharm + conda 安装tensorflow 与 keras环境_from keras.utils import np_utils要加什么包
- 8从零搭建SpringCloud服务(史上最详细)_springcloud搭建
- 9git本地init初始化后怎样和远程仓库(码云或github)同步_git同步远程仓库
- 10数据结构与算法 - 基础:LinkedHashMap
网络爬虫基本原理_网络爬虫它们分别是怎么实现的
赞
踩
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网络爬虫的框架如图所示:
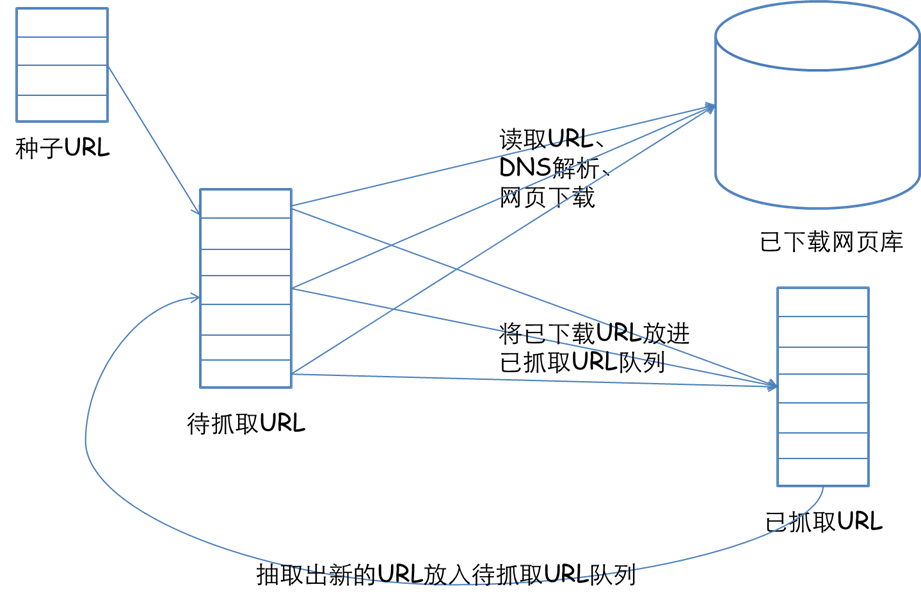
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
二、从爬虫的角度对互联网进行划分
对应的,可以将互联网的所有页面分为五个部分:
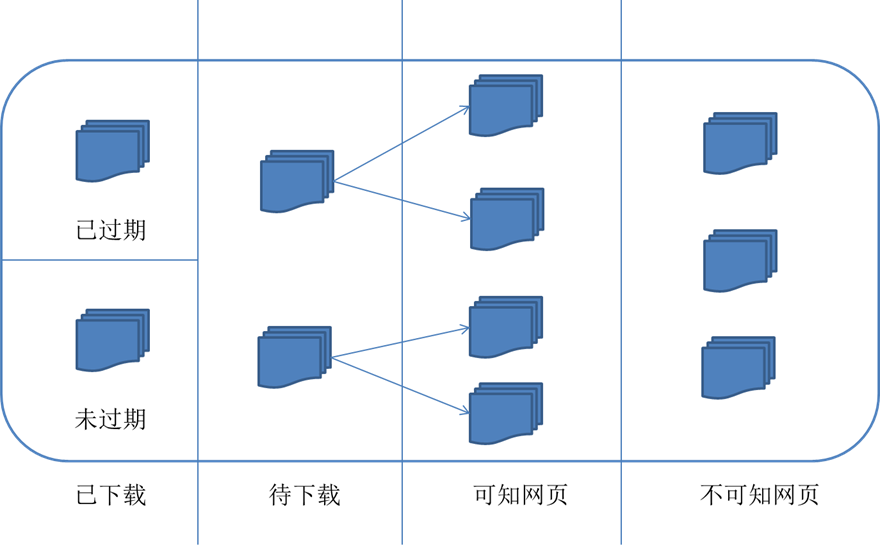
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容已经发生了变化,这时,这部分抓取到的网页就已经过期了。
3.待下载网页:也就是待抓取URL队列中的那些页面
4.可知网页:还没有抓取下来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或者待抓取URL对应页面进行分析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是无法直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:

遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
四 反爬虫常用的手段
1 使用不同的user-agent 发送请求
2 使用动态代理
相信很多人都用过代码写过不同的爬虫程序吧,来获取互联网上自己需要的信息,这比自己手动的去一个一个复制来的容易。但是,居然是用程序来获取某个网站里面的信息,可以知道,在很短的时间内,这个程序会访问某个网站很多次,很多网站都会对这样的情况进行屏蔽;比如,隔几分钟才能正常访问。这对于我们的爬虫程序来说是个大麻烦。我们知道,当我们访问一个网站的时候,对方服务器是会记下我们电脑的IP地址,有没有方法来动态改变自己的IP地址呢?答案是有的,那就是用代理。这样我们就可以在程序中加入代理功能,只要对方服务器屏蔽了我们的IP,我们就用程序自动的去换别的IP地址嘛,这样不就可以不断的访问某个服务器吗?可以利用Java的HttpClient包,来加入动态代理功能。
好了,说了这么多,程序怎么实现呢?具体的思路是:当我们可以正常访问一个页面的时候(给服务器发送一条HTTP请求),服务器一般是会返回2XX的HTTP响应码给我们。当服务器返回诸如403(被禁止访问了;当然,这个页面正常情况下是可以访问的,正常情况下都返回403 的代码,那就是人家本来就不让你访问的啦,我也哀莫能及)HTTP相应码的时候,我们就可以知道,服务器是把我们屏蔽了。这时候,当我们的程序检测到返回的403代码的时候,就可以换一个IP地址,再重新请求刚刚被屏蔽的页面不就实现了动态代码的程序吗?
第一步:先声明一个代理类
package com.wyp.utils; |
/** |
* @author 过往记忆 |
* Create Data: 2012-8-10 |
* Email: wyphao.2007@163.com |
* Blog: http://www.iteblog.com |
* 版权所有,翻版不究,但在修改本程序的时候必须加上这些注释! |
* 仅用于学习交流之用 |
* |
* 代理服务器IP以及端口 |
*/ |
public class proxyServer { |
public static String proxyIP [] = {"ec2-23-22-95-3.compute-1.amazonaws.com", "211.68.70.169", "202.203.132.29", |
"218.192.175.84", "ec2-50-16-197-120.compute-1.amazonaws.com","50.22.206.184-static.reverse.softlayer.com",}; |
public static int proxyPort[] = {8000, 3128, 3128, 3128, 8001, 8080}; |
} |
这个代理类很简单吧,就加了几个代理的IP和端口。注意,proxyPort中的端口号要一一对应proxyIP中的IP地址。
第二步:声明一个HttpClient 对象,设置好超时时间。
HttpClient httpClient = null; |
httpClient = new HttpClient(); |
// 设置 Http 连接超时 5s |
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000); |
第三步:设置代理
/** |
* 设置代理 |
*/ |
private void setProxy(String proxyIP, int hostPort) { |
System.out.println("正在设置代理:" + proxyIP + ":" + hostPort); |
// TODO Auto-generated method stub |
httpClient.getHostConfiguration().setHost(Hosturl, hostPort, "http"); |
httpClient.getParams().setCookiePolicy(CookiePolicy.BROWSER_COMPATIBILITY); |
httpClient.getHostConfiguration().setProxy(proxyIP, proxyPort); |
Credentials defaultcreds = new UsernamePasswordCredentials("", ""); |
httpClient.getState().setProxyCredentials(new AuthScope(proxyIP, proxyPort, null), defaultcreds); |
} |
第四步:测试当前的代理是否有用
/** |
* @param string |
* @param i |
* |
* 测试代理服务器的可用性 |
* |
* 只有返回HttpStatus.SC_OK才说明代理服务器有效 |
* 其他的都是不行的 |
*/ |
private int testProxyServer(String url, String proxyIp, int proxyPort) { |
// TODO Auto-generated method stub |
setProxy(proxyIp, proxyPort); |
GetMethod getMethod = setGetMethod(url); |
if(getMethod == null){ |
System.out.println("请求协议设置都搞错了,所以我无法完成您的请求"); |
System.exit(1); |
} |
try { |
int statusCode = httpClient.executeMethod(getMethod); |
if (statusCode == HttpStatus.SC_OK) { //2XX状态码 |
return HttpStatus.SC_OK; |
}else if(statusCode == HttpStatus.SC_FORBIDDEN){ //代理还是不行 |
return HttpStatus.SC_FORBIDDEN; |
}else{ // 其他的错误 |
return 0; |
} |
} catch (HttpException e) { |
// 发生致命的异常,可能是协议不对或者返回的内容有问题 |
System.out.println("Please check your provided http address!"); |
System.exit(1); |
} catch (IOException e) { |
// 发生网络异常 |
System.exit(1); |
} finally { |
// 释放连接 |
getMethod.releaseConnection(); |
} |
return 0; |
} |
第五步:得到服务器是否对我们进行屏蔽,如果返回的是SC_FORBIDDEN,代表被屏蔽的,那么我们就一个一个代理去试,也就是调用第四步的函数去判断当前的代理是否有用。
if(statusCode == HttpStatus.SC_FORBIDDEN){ //访问被人家限制了就设置代理 |
//代理服务器的个数 |
int proxySize = proxyServer.proxyIP.length; |
int i = 0; |
for(; i < proxySize; i++){ |
//我们一个一个测试代理服务器的有用性 |
System.out.println("正在测试代理:" + proxyServer.proxyIP[i] + ":" + proxyServer.proxyPort[i]); |
int status = testProxyServer(url, proxyServer.proxyIP[i], proxyServer.proxyPort[i]); |
if(status == HttpStatus.SC_OK){//代理服务器找到了 |
break; |
}else{ //其他情况你就继续去代理吧 |
continue; |
} |
} |
if(i >= proxySize){ |
System.out.println("唉,我把你设置的代理服务器都测试了,好像没有发现有效的代理,我只有退出了!"); |
return null; |
} |
System.out.println("代理:" + proxyServer.proxyIP[i] + ":" + proxyServer.proxyPort[i] + "目前可用"); |
proxyIP = proxyServer.proxyIP[i]; |
proxyPort = proxyServer.proxyPort[i]; |
经过上面几步,我们就可以不要担心程序被人家屏蔽了。
参考书目:
1.《这就是搜索引擎——核心技术详解》 张俊林 电子工业出版社
2.《搜索引擎技术基础》 刘奕群等 清华大学出版社
3 http://blog.csdn.net/wypblog/article/details/8751268

