
- 1软件测试理论知识(入门篇)_测试基础
- 22018腾讯暑假实习生后台开发岗线上笔试编程题题解_开发岗笔试题 编程
- 3基于stm32智能取药柜物联网嵌入式软硬件开发单片机毕业源码案例设计_stm32自动取药系统
- 4git cherry-pick命令使用
- 5ElementUI三级菜单checkBox全选实现_vue三级全选checkbox
- 6OfficeToolPlus工具分享
- 7Centos7安装RabbitMQ3.8.11_centos rabbitmq 3.11.18 安装
- 8大数据入门系列 5:全网最全,Hadoop 实验——熟悉常用的 HDFS 目录操作和文件操作_hdfs目录操作_向hdfs中上传任意文本文件,如果指定的文件在hdfs
- 9AI绘画做图在线对话二合一源码系统 直接输入文字就可以在线生成视频 带完整的安装包以及搭建教程
- 10简单讲解jQuery中的子元素过滤选择器_jquery
使用StarRocks遇到的问题汇总 FAQ_starrocks key columns should be a ordered prefix o
赞
踩
日常记录 不断更新
导入
insert into
问题:
insert的时候报这个错:
sql:ssb-flat_insert.flat insert error. Msg: (1064, ‘index channel has intoleralbe failure’)
问题截图:

解决方式:
streaming_load_rpc_max_alive_time_sec=2400
tablet_writer_open_rpc_timeout_sec=120
be/conf/be.conf 配置中这两个项目改大写
改大一些 可以在SRManager页面修改的
stream load
- stream load的时候报错: {“status”:“FAILED”,“msg”:“There is no 100-continue header”}
解决方案:
setHeader(HttpHeaders.EXPECT, “100-continue”),设置下请求头,发送文件大于1024字节,必须询问服务器的时候接受数据才可以发送数据
问题原因:
需要设置下请求头,发送文件大于1024字节,必须询问服务器的时候接受数据才可以发送数据
- stream load导入csv 报错

解决方案:
查看errurl后边链接的内容,发现是字段中包含分隔符,导致分割出来的列和schema对不上,-H ‘column_separator=,’,目前SR的column_separator不支持多个字符,只支持单个字符。
问题原因:
目前SR column_separator 不支持多个字符,只支持单个字符。(sr官方:column_separator设置后续会支持多个字符)
- stream load的时候报错:all partitions have no load data

解决方案:
分区设置的有问题,导入的数据不在建表的分区里面,
问题原因:
是自己分区的问题,csv的数据在SR的分区范围之外
- type:ETL_RUN_FAIL; msg:No source file in this table(bi_all_report).

解决方案:
更改配置路径到文件 s3a://xx/xx/all_pq/date=2021-04-26/*这种格式
问题原因:
配置的是文件夹 data infile (“s3a://xx/xx/all_pq/date=2021-04-26/”),需要指定到文件 s3a://xx/xx/all_pq/date=2021-04-26/*这种格式,所属路径中必须是文件, 不能是目录
StarRocks如何去查看分区分桶是否生效:通过查看profile来获取分区分桶数看是否生效
SR目前还不支持DTS.
SR是支持udf的,但目前在重构当中,不支持使用,官方:2.2版本会发出新的一版,以前只支持c++,2.2会支持java等
安装部署
- 安装的时候遇到的问题是:我现在有3台fe ,两台FOLLOW,一台OBSERVER。这时候我停掉FOLLOWER中的MASTER ,另一台follower 会自动切换成master吗?
确认为:不会的 ,奇数个才会选举的,OBSERVER是不参与选主的

建议部署三台follower,奇数个follower为高可用集群,Observer节点作用是能够增加FE集群的读负载能力, 时效性要求比较宽松的话可以部署成observer节点
SR升级到1.19.0后有个小问题,help 用不了了!

官方:缺少依赖包,去之前的lib找一个help-resource.zip 放到新的lib里,官方目前在重构,后面版本会有的
数据导入
-
支持从人大金仓数据库导入到StarRocks吗?
确认后为:用datax去做,自己把人大金仓的依赖jar丢到lib目录下 -
用来判断_op的字段type一定要在表里面吗?

确认结果:是的
查询执行
- be报错:W1115 19:54:41.135861 5800 delta_writer.cpp:92] Fail to init delta writer. tablet=10061.795111493.87428e006f272bc1-f638453c2bd401be, version count=1001, limit=1000,如何修改 tablet version参数 。
回答:这个问题一般是导入频率太高,导致后台数据版本合并不过来。现在的writer是基于Stream Load攒微批导入的,可以采用更新插件+攒批降低导入频率
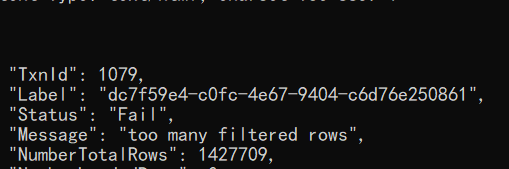
- 377493 W1013 11:31:55.291406 10404 stream_load.cpp:130] Fail to handle streaming load, id=c8429599f0e52892-08b15d1cfdb2e3b8 errmsg=too many filtered rows
解决方案: 这个是由于数据质量带来的问题,查看errorURL里面的具体 的内容,看了一下错误的原因,如果要忽略错误数据,可以在原有的curl语句中加入 -H “max_filter_ratio:0.1”,来过滤脏数据。例如这样:curl --location-trusted -u root -T /mnt/tpch-kit/dbgen/orders.tbl.8 -H “max_filter_ratio:0.1” -H “column_separator:|” http://192.186.0.21:8030/api/tpch/orders/_stream_load,max_filter_ratio:最大容忍可过滤(数据不规范等原因而过滤)的数据比例。默认零容忍。数据不规范不包括通过 where 条件过滤掉的行。
-
spark load没法导入数组吗?我是写成orc文件的,同一份文件spark load报错,broker load就进去了,版本是1.8的
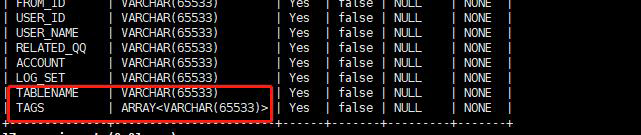

官方: 确认字段,发现TAGS是array类型的数据,目前spark load 还不支持array类型的导入 ~ 后续会支持 -
从mysql外部表通过insert into 插入到内部表中,出现 1064 - all partitions have no load data, Time: 7.307000s
官方:确定下导入的数据和StarRocks建表的分区范围,看看导入的数据是不是在这个范围内,导入数据数量为0,你也可以看下文件是不是空的,或者是数据格式不对,亦或者是所有的数据都被过滤掉了,您可以排查下。
-
1064 - Execute timeout > 时间: 300.066s,这个是在哪里设定时间呢?
官方:set global query_timeout = xxx ; 命令行设置就行 -
请教下,之前用kudu时,分区分桶多了会有tablet过多导致性能下降问题,请问StarRocks是否也有此类问题?因为官方文档推荐多建分桶来充分利用多线程,但不知道分区分桶建多了是否有副作用。
官方:分桶的数量会影响查询的并行度,最佳实践是计算一下数据存储量,将每个tablet设置成 100MB ~ 1GB 之间。您可以参考下相关的文档,合理地去进行分区分桶,https://docs.starrocks.com/zh-cn/main/quick_start/Test_faq#%E5%A6%82%E4%BD%95%E9%80%89%E6%8B%A9%E7%A1%AC%E4%BB%B6%E5%92%8C%E4%BC%98%E5%8C%96%E9%85%8D%E7%BD%AE
是这样,我们有很多不同的业务要建表,很多表要分区分桶,想问下每台机器是否也有管理tablet的上限,多了会有什么影响,而且我们的表都不大,但业务想要查的快,就导致tablet不大但是多
SR:StarRocks支持千万级别的tablet数
-
Starrocks表数据变化后,分桶数能不能做调整?
官方:分区表可以修改分区的分桶数。

-
我把9010和9030端口都修改了,不影响后续使用吧?

官方:不影响,fe只需要http_port一致即可 -
StarRocks怎么看系统目前跑的查询语句
StarRocks:SHOW PROCESSLIST; -
明细模型表,想使用动态分区,同时不想删除老分区,如何做呢?
StarRocks:您可以在建表的时候把star改为很大的值,参考:https://docs.starrocks.com/zh-cn/main/table_design/Data_model#%E6%9B%B4%E6%96%B0%E6%A8%A1%E5%9E%8B
其他
- 请问这个错误是什么问题,通过mysql命令能连接,但是通过客户端连接工具不行

StarRocks:show proc ‘/backends’ \G; 检查下是不是没有启动be
-
为了避免GC建议16G以上,StarRocks的元数据都在内存中保存,官网提到元数据保存到内存中,这个需要人为手工配置嘛?
StarRocks:可以修改fe的配置把jvm调大到16G -
编译jar的时候,是否要添加这个依赖,我添加之后,mvn clean package报这个依赖的错了,我看github上面是叉叉叉


StarRocks:要把xx.x换成1.1.10 -
StarRocks 1.18.1 这个参数不支持?

StarRocks:系统变量 您直接set就成 参考:https://docs.starrocks.com/zh-cn/main/reference/System_variable#%E8%AE%BE%E7%BD%AE -
这个smt.tar解压在flink下面还是starrocks目录下面呀?

StarRocks:任意目录都可以 -
这个error是代表fe成功还是失败呀?

StarRocks:\G和;不能同时用, 这你相同于两条SQL了 -
新版本2.0支持 flink 读取 StarRocks吗?
StarRocks:2.0会支持的! -
我想咨询下:starrocks里字段类型varchar的计算与mysql不一样是吧?
the length of input is too long than schema. column_name: city; input_str: [伊犁哈萨克自治州] schema length: 20; actual length: 24
伊犁哈萨克自治州8个字,mysql字段是varchar(20),starrocks要求是varchar(24)
StarRocks: 
-
primary key模型不能加索引
StarRocks: 支持的 创建的时候可以加 但你要是ALTER TABLE的时候还不行 ALTER TABLE的后续官方会支持~ -
flinksql运行报连接被拒绝这是啥原因?

StarRocks: 目前只能sink,不能select -
你好,我想问一下,如果只有一台fe且状态是UNKNOWN.的话,能否有命令指定自己为master
StarRocks: 可以但不推荐您使用这种方式 您可以参考下 这种方式可能会丢失元数据,慎重使用 @雪碧 https://docs.starrocks.com/zh-cn/main/administration/Metadata_recovery -
请教下,存储一个字符的话 varchar255 和varchar 2 在Starrocks里面 字段类型有啥区别 吗 ?
StarRocks: 没有的 , SR是变长的 -
Key columns should be a ordered prefix of the schema 建表的时候提示这个是为什么?
StarRocks: 建表的问题,排序的键放前面,key列包含的字段应该顺序声明在建表最前列 -
StarRocks支持修改字段名吗?
StarRocks: 可以的 参考:https://docs.starrocks.com/zh-cn/main/sql-reference/sql-statements/data-definition/ALTER%20TABLE
StarRocks的社区小伙伴很给力的! 加油,StarRocks会越来越好!

