
- 1TF-IDF算法讲解和Java实现_java实现tf-idf
- 2联合阿里在职测开工程师耗时一个星期写的 【接口测试+自动化接口接口测试详解]
- 3【C#】.NET Core配置系统_c# 配置文件
- 4FastAPI项目uvicorn-gunicorn-fastapi服务端docker容器平滑重启及Docker仓库中python web接口服务器端Fastapi-gunicorn-server镜像包_fastapi做到项目平滑重启
- 5无监督异常检测(MVTec)
- 62020工商银行信息技术岗校招笔试经历_工商银行 it笔试
- 75G-NR复用与信道编码_kr code block size for ul-sch
- 8人工智能与内容生成:AIGC技术的未来展望
- 9KAFKA学习_kafka多个消费者消费一个topic
- 10业界首家720p/1080p移动端实时超分,打造抖音极致画质体验
生成式AI原理技术详解(一)——神经网络与深度学习
赞
踩

本文主要介绍了生成式AI的最新发展,提到了GPT-5和AI软件工程师在行业中的影响,指出AI技术进步对国家竞争和个人职业发展的潜在影响。

未来已来
最近有两则新闻:
sam altman自曝GPT-5细节,公开宣称GPT-5提升将非常大,任何小看它的公司都会被碾压。并发推暗示OpenAI今年的产品会改变人类历史。
关于首个AI软件工程师的新闻,里面AI软件工程师表现已经相当出众,具备了整体规划、DevOp、全项目扫描等能力,离真正程序员已经不远。
虽然一切都在意料之中,但是还是感觉来得快了点。
个人觉得,当前AI技术的进展,至少有两个方面的影响:
大到国家竞争层面,有了AI的加持,之前中国对美国的一大优势—优秀高校毕业生的人数,已经不复存在。后面谁能胜出,就看谁犯的错误更少。
小到个人饭碗层面,预计2-5年,生产方式就会发生变革,如果没有跟上,可能会遭受降维打击。作为一个码农,抓紧学习AI底层原理,或者参与AI相关应用实践,才是硬道理。

AI不是黑盒
在开始之前,我想强调一下:AI不是黑盒,它的一切元素、一切过程都是确定的、可解释的。
我希望能用程序员好懂的方式把AI的原理给撸一遍。希望感兴趣的同学读了这篇文章,能够跟我一样,打破AI很复杂、AI是黑盒这样的迷思。
本文会从神经网络和深度学习开始,按下面三部分进行解释:
通过一个非常简单的网络解释神经网络和深度学习的基本原理。
再通过一个真实的神经网络实操给大家一些体感。
最后通过一个常见问题引出后面文章要介绍的复杂神经网络。

神经网络基本原理
本章重点提示:
神经网络通过“学习”并存储训练集的一般规律,来解决训练集外的问题。
存储是确定的。神经网络分为多层,每层有多个神经元,每个神经元上有N+1个参数(其中N等于连接到神经元的输入个数)。“学习”到的一般规律,就存储在(所有神经元的)这些参数里。
过程也是确定的。因为“学习”过程是从高维参数空间(所有神经元的X个参数)的任意一点(参数的初始值是随机给出的)出发,逐步回归到损失最低的一点,是一个逐步调整参数的过程。所以如果调整参数的公式确定,则“学习”的过程就是确定的。是的,调整参数的公式是确定的:模型编译时,每一层每个神经元每个参数的调整公式,就能根据偏导数的传递性,早早被确定了。
▐ 神经网络能做什么
神经网络和深度学习能解决没有明确规则或者规律复杂的问题,比如图像识别(不好写if else)
▐ 为什么神经网络能解决复杂问题
复杂问题往往不可穷举(比如不同的猫猫图),所以没有一套规则来套用它们所有的实例。唯一的办法就是抽象出它们的一般规律,或者说特征,或者说模式(pattern)。
举个例子,为什么text embedding能够用来做自然语言处理,因为它没有(也不可能)记录全部的文本组合,而是通过一个向量来记录的单个文字或token的模式,这个向量就是对这个文字的抽象。如果两个文字的向量有部分相似,这种相似性可能对应于它们在特定上下文中的共同特征。具体哪一个向量值代表什么特征,这些更像是语言文字的元数据,我们并不关心。
假设经过训练,得到king的向量表征是[0.3, 0.5, ..., 0.9],queen是[0.8, 0.5, ..., 0.2],prince是[0.3, 0.7, ..., 0.5],在某一个上下文中,比如 xx is ruling the kingdom,xx可以被king或者queen填充,那它们有可能就是由向量的第2个元素,那个共同的0.5决定的,在另一个上下文,比如 xx is a man,xx可以king或者prince填充,这有可能是由第一个元素决定的。
下面会讲到,神经网络也有一套机制用来计算和存储这些抽象出来的模式,所以神经网络非常适合解决涉及抽象概念的复杂问题。
▐ 神经网络如何实现
就像我上面说过的,AI不是黑盒。神经网络和一般程序一样,也是由数据和计算构成,并且它的存储和计算都是非常确定的。
举个例子,我们要解决一个通过x推导y的线性回归问题。观察到x=1时y=3,x=2时y=5,现在要求x=3时y=多少。问题本身比较简单,我们甚至可以直接算出回归方程式为y = mx + b,其中m = 2, b = 1。
(线性回归链接:http://www.stat.yale.edu/Courses/1997-98/101/linreg.htm)
问题是,如果我们通过一个单一输入是x、只有一层、该层只有一个神经元、神经元的输出是y的神经网络,会以怎样的方式和过程来“学出”这个结果呢?
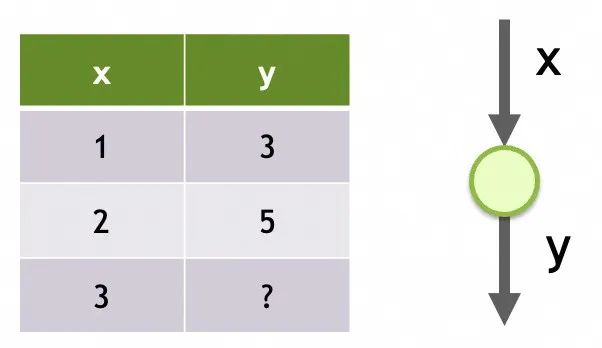
网络1
在了解“学习”过程前,我们先来看看神经网络的存储结构,即什么是模型(model)。
上面的[网络1],它的模型就是由它的结构+它的参数组成。
它的结构是单个输入、只有一层、这层只有一个神经元。
它的参数就是每个神经元上被训练的数据,这里只有一个神经元,它上面有m和b两个参数。
经过训练之后的参数(上例中的m=2,b=1),就是被训练数据集(上例中的x=[1,2,...],y=[3,5,...])的模式,就是对特定问题的抽象。有了这个模式,再灌入别的x,也能算出对应的y。
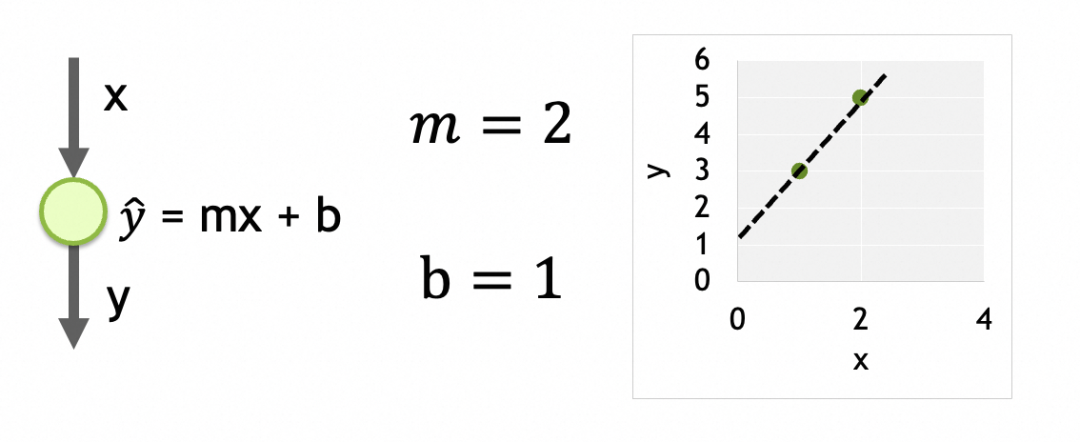
一个各层紧密相连(Dense)的网络,每个节点都和上一层所有节点相连,上层所有节点是下层每个节点的输入。每个节点的输出是其输入的加权和,经过激活函数处理后的结果:output = activation_function(W * X + b),其中,X是输入向量[x1, x2, ..., xn],W是各输入的权重(weights)向量[w1, w2, ..., wn],b是偏置(bias)常量,activation_function是激活函数。当激活函数是linear时,output = W * X + b。当节点有n个输入时,节点有[w1, w2, ..., wn, b]共n+1个参数。网络不同层之间是链的关系,结果会向下传递,直到最后一层输出层。任意层的任意一个神经元的任意一个参数,都会影响最终结果。所以这些参数就是神经网络的存储单元,用来存储抽象出来的模式。
再举一个例子,下图的[网络2]是一个有两个输入、两层、第一层2个元、第二层1个元、各层激活函数是linear的网络。网络第一层参数总数=(输入个数+1) 节点数 = (2 + 1) 2 = 6,第二层的参数总数 = (2 + 1) * 1 = 3,网络参数总数 = 6 + 3 = 9,抽象出来的模式就存储在这些参数里。(下图中的w111,w112,b11,w121,w122,b12,w21,w22,b2)
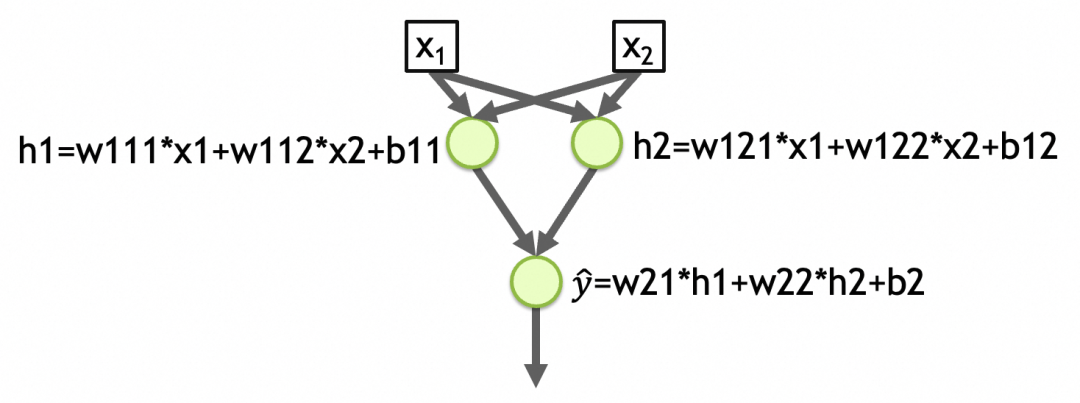
网络2
为什么要有激活函数(activation function)?我们可以看看如果没有特殊的激活函数,比如上面的[网络2],会是什么情况。
可以看到[网络2]每一层都是线性函数,根据线性函数的传导性,最终结果还是一个线性函数。即y_hat=w21*h1+w22*h2+b2=w21*(w111*x1+w112*x2+b11)+w22*(w121*x1+w122*x2+b12)+b2最终可以化简为y_hat=w1'*x1+w2'*x2+b'。而一个线性函数(直线、平面、…)是没法拟合/抽象现实问题的复杂度的。
引入激活函数,主要是为了引入非线性函数,让模型可以拟合/抽象复杂现实问题。
常见的激活函数有:
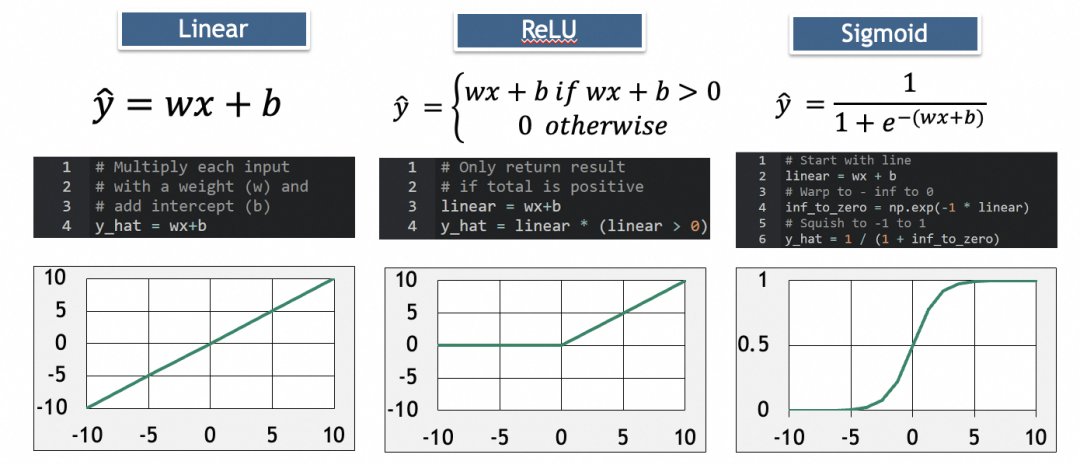

其中,ReLU用于消除负值,Sigmoid用于增加弧度。
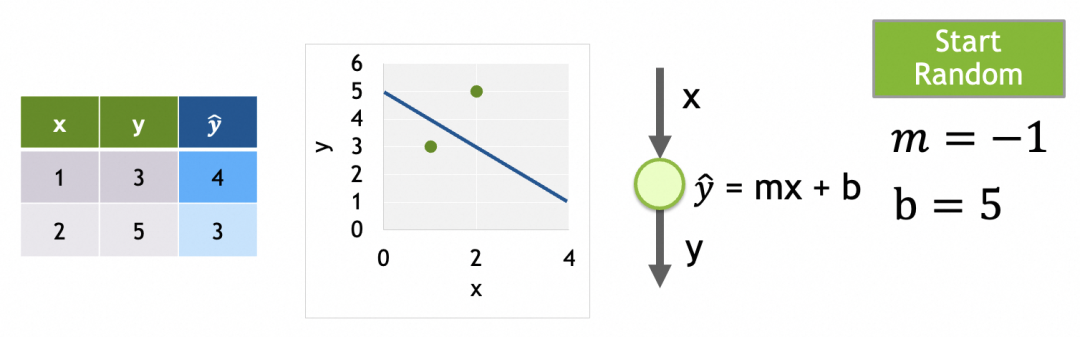
拿上面的[网络1]举例。假设模型已按[网络1]创建,数据集已准备,分为训练集(training)比如 x=[1,2], y=[3,5] 和验证集(validation)比如 x=[3], y=[7]。
深度学习即神经网络训练步骤:
第1步、初始化参数:这里只有一个神经元,m和b两个参数。随机给值就行,假设m=-1,b=5。
第2步、用训练集计算输出y_hat。因为多层网络的计算是从上往下,所以称为前向传播:
第3步、使用损失函数评估输出的好坏(和实际值的差异),这里采用MSE(平均方差):
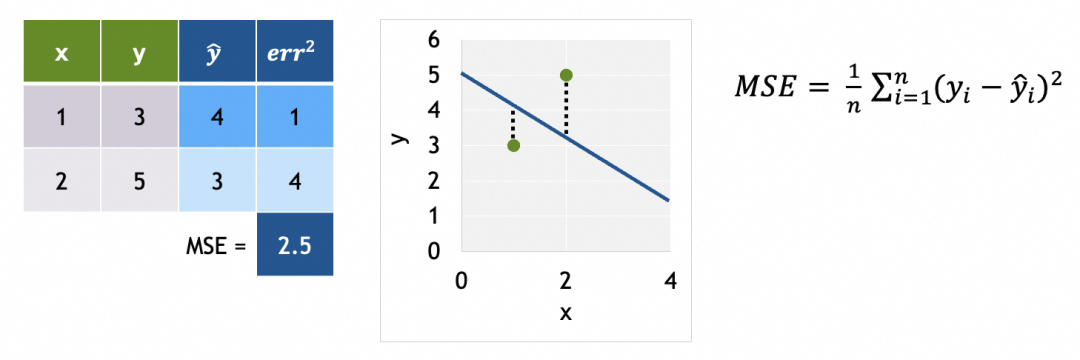
为什么要用平均方差(Mean squared error):比较适合当前问题(偏离预期回归线越远,损失越大)。差的平方(squared error)是为了消除差的负数,并且通过平方扩大差值。取平均值(Mean)是将差值均摊到训练集每个样例。
第4步、通过反向传播算法计算各参数的梯度(gradient)。
各参数的梯度,即单个参数的变化会多大程度影响损失结果的变化。计算各参数的梯度,再将参数往损失结果变小的方向调整,即可在高维参数空间中找到损失最小值点。
为了计算梯度,我们需要先了解损失曲面。
例子中只有m和b两个参数,如果将m和b作为x和y轴,损失函数结果作为z轴,可以得出损失曲面。(如果存在更多参数,形成高维参数空间,道理类似)

我们的目标是找出损失函数结果最小的m和b,这里即m=2,b=1。具体做法是将参数的当前值m=-1,b=5分次进行一定偏移,往m=2,b=1靠拢。
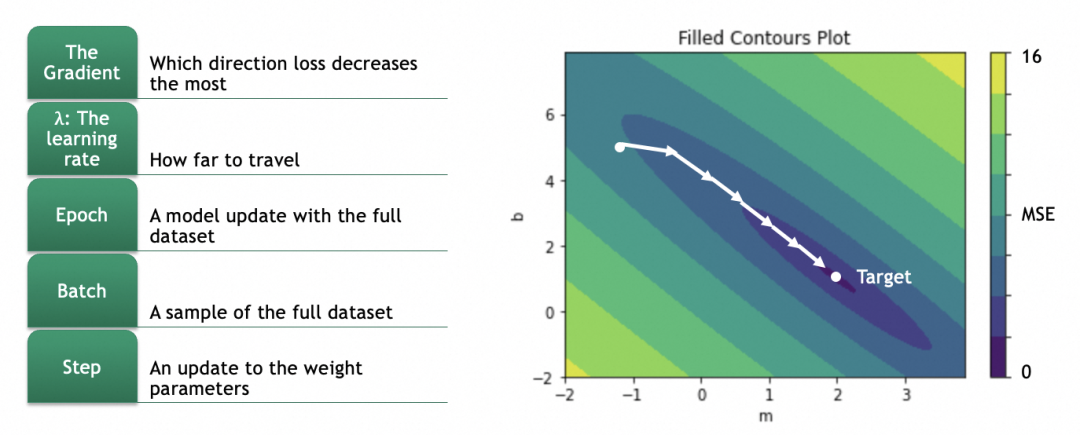
偏移具体怎么算呢?这就涉及到计算梯度,数学上就是计算偏导数。
对于一个曲面,当前在高处,要往低处移动,可以分别计算x、y两个方向(即m和b两个参数),在当前位置的梯度,即偏导数(partial derivative),即几何上的切线斜率,即单个参数的变化会多大程度影响损失结果的变化(注意梯度是向上的,用的话要取反)。
幸运的是,对于任何损失函数,都有对应公式算出对于某个参数的偏导数。例如,激活函数是y_hat = m * x + b,损失函数是L = (1/N) * Σ(y - y_hat)^2,则对于m的偏导数是∂L/∂w = (1/N) * Σ -2x(y - y_hat) = (1/N) * Σ -2x(y - (m * x + b))。这里仅仅是说明能解,因为模型会提供这个能力,所以我们一般不人为关注。
不仅如此,神经网络还有传导性,拿[网络2]举例,如果我们希望算出第一层参数w111的梯度,则可以按∂L/∂w111 = ∂L/∂y_hat * ∂y_hat/∂h1 * ∂h1/∂w111一层一层反向传播算回去,得到w111梯度具体的公式。
第5步、按梯度更新各参数:
因为偏导数是向上的,往低处走、梯度下降要取反。
拿m举例,m的新值m = m - learning_rate * ∂L/∂m。
注意learning_rate的选择,过大会导致越过最低点,过小会导致单次变化太小,训练时间太长。不过一般模型会提供自动渐进式的算法,我们无需人为关注。
第6步、网络的训练过程是迭代的,在每个训练周期(epoch)中,网络将通过梯度下降的方式逐步调整其参数。整个过程会重复多个epoch,直到模型的表现不再显著提高或满足特定的停止条件。
每个训练周期,即会用训练集进行训练,也会用验证集进行验证。通过对比训练集和验证集的结果,能发现是否存在过拟合现象。
关于全局最优解和局部最优解:
如果损失曲面比较复杂,比如有多个低洼,从某个点渐进式移动不一定能找到最低的那个,这种情况会拿到局部最优解而不是全局最优解。
关于训练batch:如果训练集非常大,每个训练周期不一定会拿全部训练集进行训练,而是会随机选一批数据进行。常见的方式有Stochastic Gradient Descent(SGD),一次选一个样例,这样的好处不仅计算量大大减少,还容易从局部最优解跳出,缺点是不太稳定。另一种方式是Mini-Batch Gradient Descent,这种一次选10-几百个样例。具有SGD的优点且比SGD稳定,比较常用。

MNIST数据集深度学习案例
MNIST数据集是深度学习领域的一个经典数据集,它包含了大量的手写数字图像,对于验证深度学习算法的有效性具有标志性意义。
有了前面章节的理论,接下来,我们将通过一个实际案例来展示如何使用神经网络来解决图像分类问题。
下面的操作会用到jupyter平台和tensorflow2深度学习框架,但本文重点解释原理,平台和框架的使用就不多置笔墨了。
加载和观察数据集
在使用图像进行深度学习时,我们既需要图像本身(通常表示为 "X"),也需要这些图像的正确标签(通常表示为 "Y")。此外,我们需要一组X和Y来训练模型,然后还需要一组单独的X和Y来验证训练后模型的表现。因此,MNIST数据集需要分成4份:
x_train:用于训练神经网络的图像y_train:x_train图像的正确标签,用于评估模型在训练过程中的预测结果x_valid:模型训练完成后用于验证模型表现的图像y_valid:x_valid图像的正确标签,用于评估模型训练后的预测结果
我们需要做的第一步,是加载数据集到内存,并通过观察对数据集概貌有一个了解。
通过Keras API加载:

Keras API地址:https://keras.io/
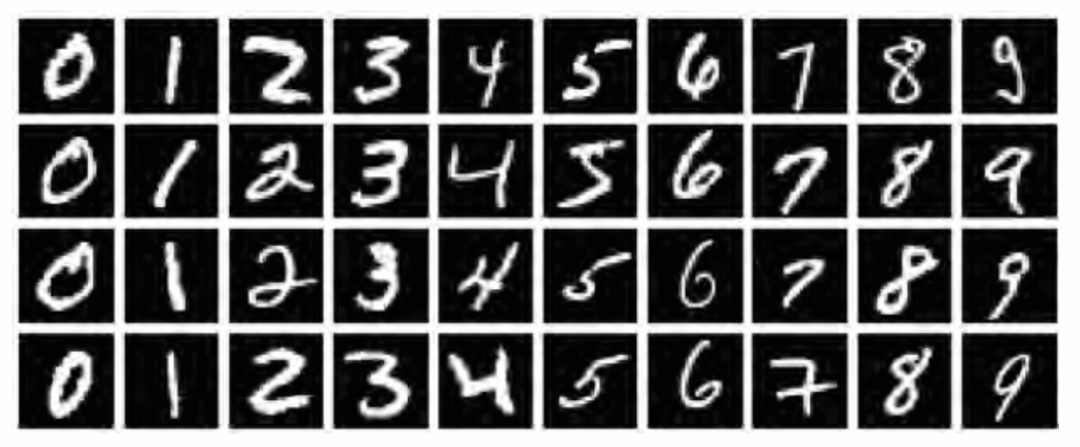
查看训练图像集x_train和验证图像集x_valid:可以看到是分别是60000张和10000张28x28 pixel的灰阶图像(灰度0-255):

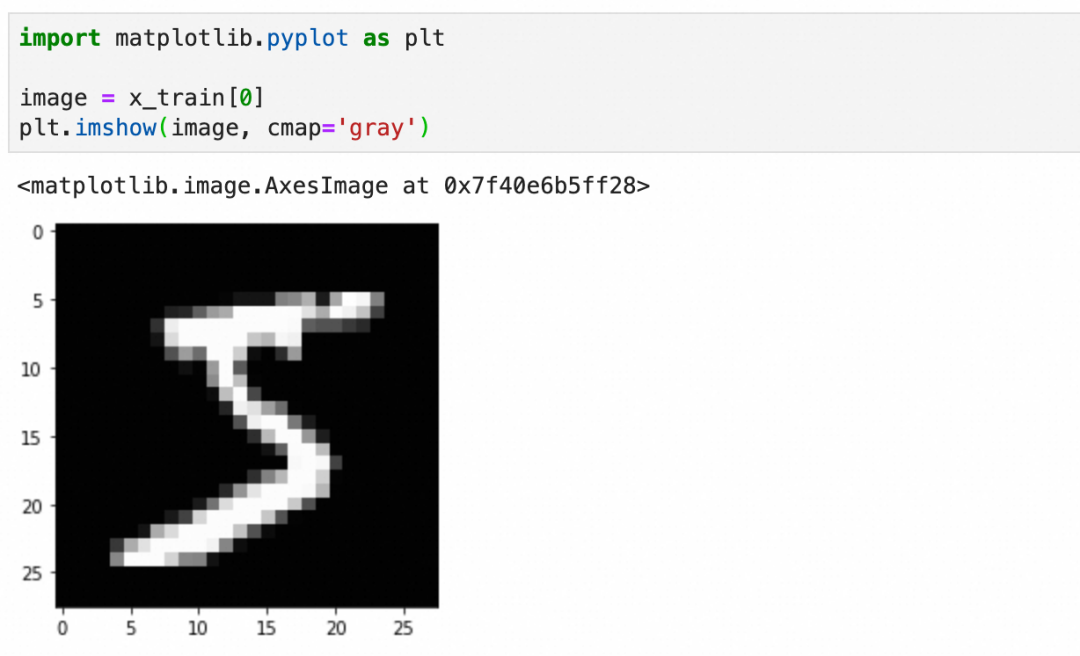
每个图像是一个图像grid的二维数组,下图是二维数组的内容和可视化图像:

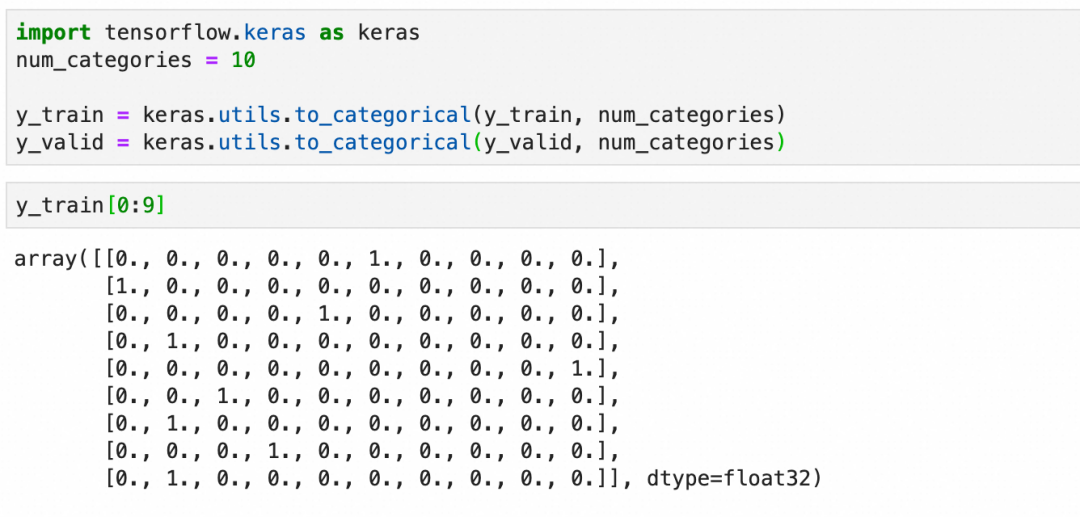
标签y_train比较简单,就是图像对应的数字:

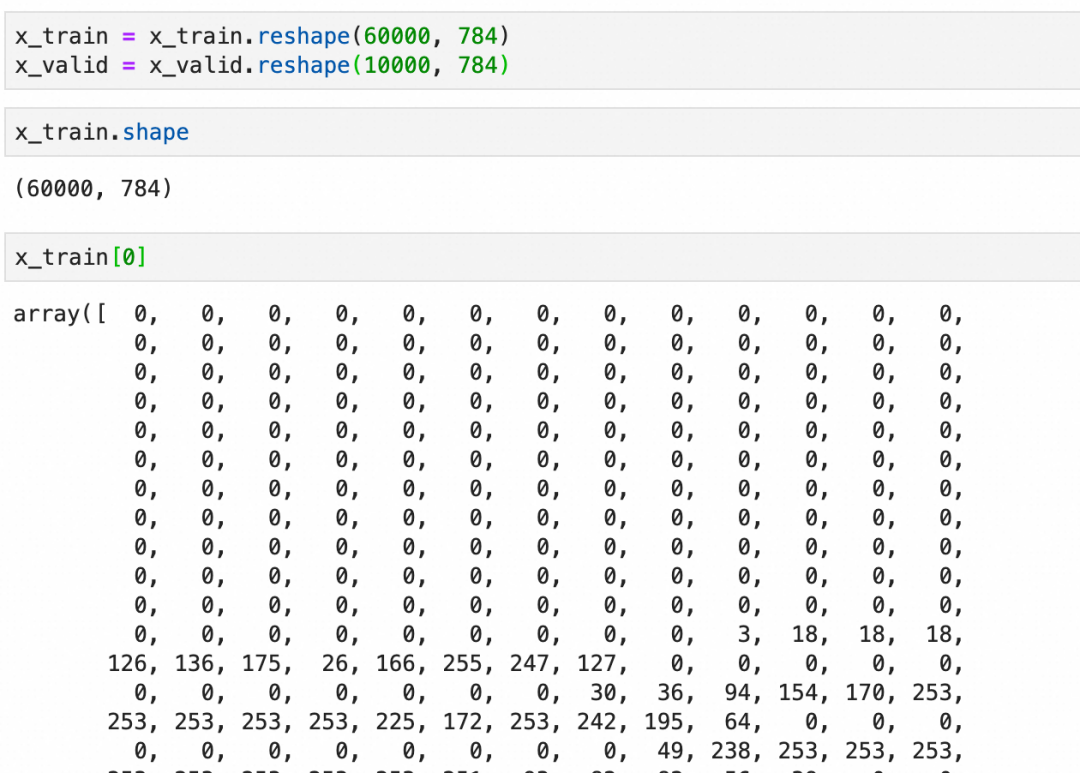
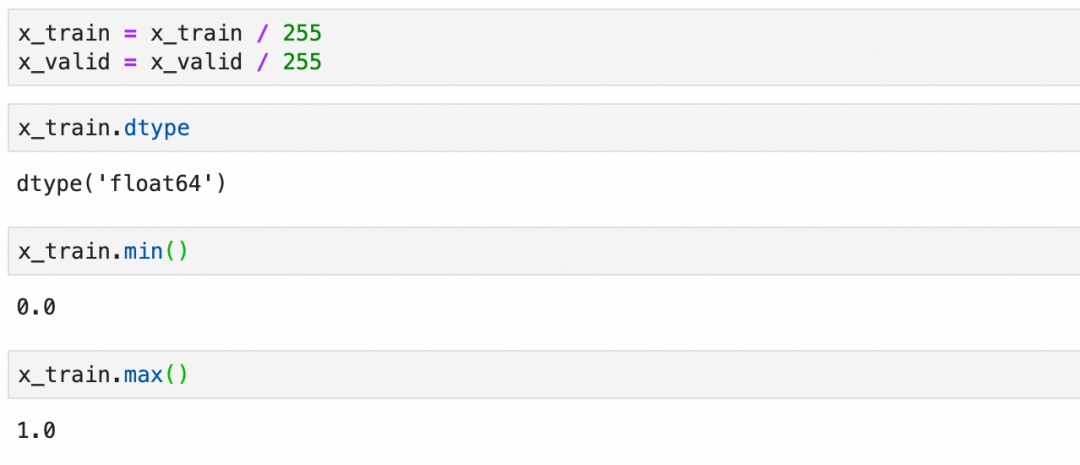
在将数据输入到神经网络之前,通常需要进行一些预处理。这包括将图像数据展平为一维向量,标准化像素值到0-1之间,并将标签转换为适合分类任务的格式,通常是one-hot编码。
展平:
标准化:
one-hot编码:
虽然这里的标签是0-9的连续整数,但不要把问题看作是一个数值问题(考虑一下这种情况,假设我们不是在识别手写0-9的图片,而是在识别各种动物的图片)。
这里本质上是在处理分类,分类问题的输出在深度学习框架里适合用one-hot编码来表达(一个一维向量,长度为总分类数,所属分类的值为1,其它值为0)。

创建模型
创建一个有效的模型通常需要一定的探索或者经验。对于MNIST数据集,一个常见的起点是构建一个包含以下层的网络:
784个输入(对应于28x28像素的输入图像)。
第一层是输入层,有512个神经元,激活函数是ReLU。
第二层隐藏层,使用512个神经元和ReLU激活函数。
第三层是输出层,10个神经元(对应于10个数字类别),使用Softmax激活函数以输出概率分布。
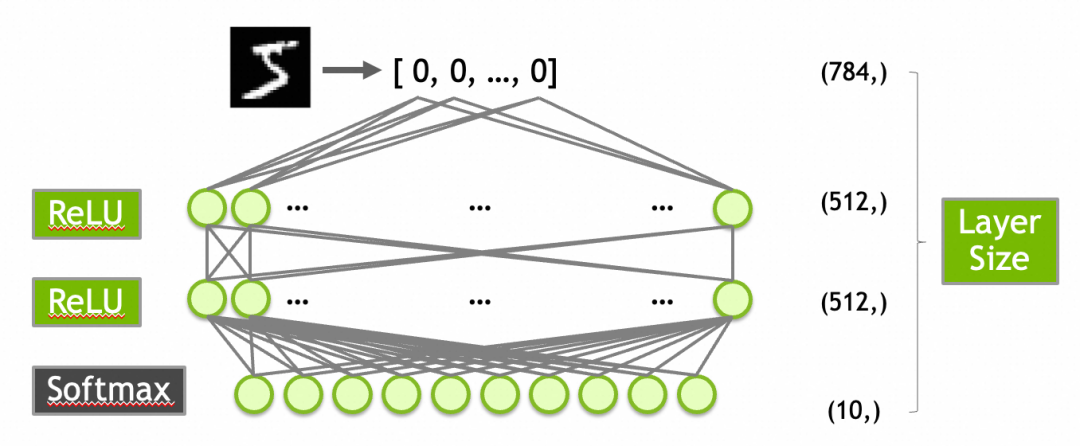
激活函数ReLU上面已经介绍过了,这里的Softmax需要介绍一下:Softmax函数确保输出层的输出值总和为1,从而可以被解释为概率分布。这对于多类分类问题非常有用。例如,输出层的10个输出值为[0.9, 0.0, 0.1, 0.0, ..., 0.0]可以解释为90%概率属于第1类,10%概率属于第3类。
按此创建模型并查看摘要:

可以注意这里的参数数量。
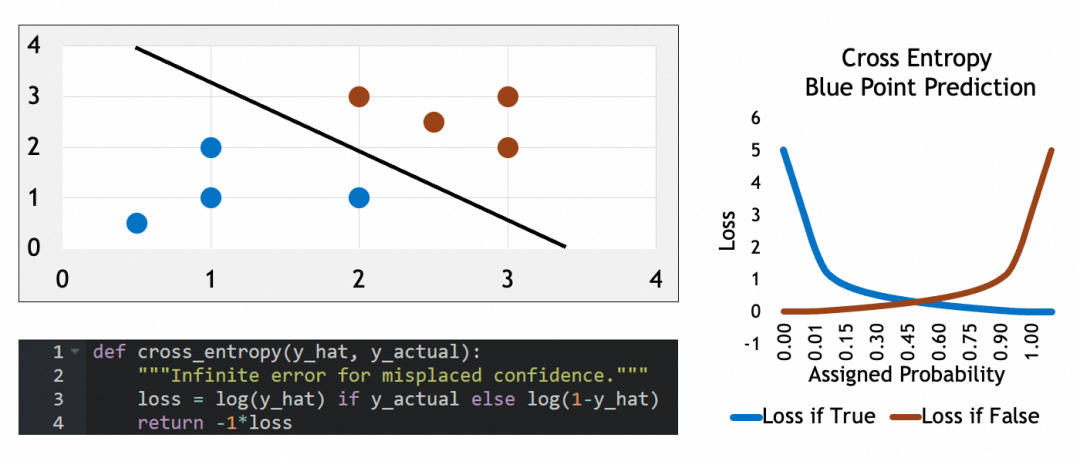
编译模型
模型在编译时需要指定损失函数和优化器。对于多分类问题,损失函数通常选择交叉熵(Categorical Crossentropy),它的特征可以看参考公式:当实际属于某类(y_actual=1)时,损失等于log(y_hat),否则损失等于log(1-y_hat)。这个损失函数会惩罚错误猜测,使其损失接近∞,可以有效地量化预测概率分布与实际分布之间的差距。优化器则负责调整网络参数以最小化损失函数。

训练并观察准确率
训练模型时,我们会在多个训练周期内迭代更新参数,每个训练周期会经历一次完整的前向传递计算输出、损失函数评估结果和后向传递更新参数的过程。我们观察训练集和验证集上的准确率,以评估模型的表现和泛化能力。
注意损失曲面、梯度下降等概念和原理,如果不清楚可以回顾一下【深度学习过程】。
下图中的accuracy是训练集的准确率,val_accuracy是验证集的准确率,准确率符合预期。


过拟合和解决方案
如果模型在训练集上准确率很高,但在验证集上准确率低,可能出现了过拟合现象(overfitting)。过拟合意味着模型过于复杂或训练过度,以至于学习了训练数据中的噪声而非潜在规律。
训练集,左边损失非常小:
验证集,左边损失反而更大:
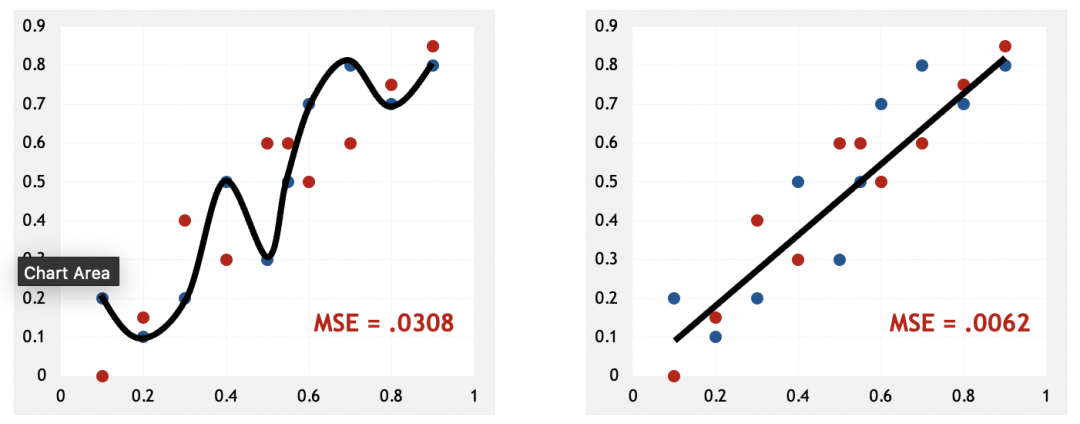
左图可以看到,模型几乎硬套了训练集。和人脑类似,硬套部分实例,说明模型只是在记忆这些实例,只有找出它们的规律、特征、模式,才是真正的抽象。这也应证了我前面的说法,神经网络是在通过抽象解决问题。
从被训练数据来看,过拟合说明训练集可能特征不明显,不容易抽象。比如被识别的图像模糊、亮度不高。
从模型来看,过拟合通常由于模型过于复杂或训练时间过长造成,走向了死记硬背。
AI技术经过多年的发展,现在已经有比较成熟的方案来解决过拟合了,比如卷积神经网络、递归神经网络,这些我会在后面的文章里进行介绍。
本文大部分素材来自Nvidia在线课程Getting Started with Deep Learning。
(Getting Started with Deep Learning地址:https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-01+V1)

团队介绍
天猫国际是中国领先的进口电商平台, 也是阿里巴巴-淘天集团电商技术体系中链路最完整且最为复杂的技术产品之一,也是淘天集团拥有最完整业务形态(平台+直营、跨境、大贸、免税等多业务模式)的业务。在这里我们参与到阿里电商体系的绝大部分核心系统(导购、商家、商品、交易、营销、履约等),同时借助区块链、大数据、AI算法等前沿技术助力业务高速增长。作为贴近业务前沿的技术团队,我们对于电商行业特性、跨境市场研究、未来交易趋势以及未来技术布局等都有着深度的理解。
¤ 拓展阅读 ¤

