
- 1USP技术提升大语言模型的零样本学习能力
- 2大数据与机器学习:结合实践与技术
- 3update 还原到5分钟前_用好这3个公式,即兴演讲前那忐忑的5分钟,我再也不恐慌了...
- 4数据安全分类分级怎么搞?国家标准来了!(附全文)
- 5flink内存调优小记录_flink 内存
- 6机器学习之基于Python多种混合模型的糖尿病预测
- 7最新Ai写作创作系统源码+Ai绘画系统源码+搭建部署教程+支持GPT4.0+支持Prompt预设应用+思维导图生成_写作网 源码
- 8MySQL的卸载与安装(Linux)_linux卸载mysql
- 9hive 常用参数、参数优化_set hive(1)
- 10ARM Linux 下 编译 AWS SDK for C++ S3 连接minio及注意事项_交叉编译 aws sdk for c++ s3
KAFKA学习_kafka多个消费者消费一个topic
赞
踩
kafka(分布式流媒体平台):作为一个集群运行在一个或多个数据中心服务器上,集群以topic(主题)的类别存储记录流,每条记录包含一个键,一个值和一个时间戳,kafka客户端与服务器之间的通信是通过简单,高性能,语言无关的TCP协议完成的
流媒体平台的三个关键功能:1.发布和订阅记录流
2.以容错的持久方式存储记录流
3. 记录发生时处理流
kafka四个核心API:
producer Api:允许应用程序发布记录流到一个或多个kafka topic上
consumer Api:允许应用程序订阅一个或多个topic,并处理他们说产生的数据流
streams Api:允许应用程序充当流处理器,从一个或多个topic消耗输入流,并产生一个输出流到一个或多个topic上,有效变换输入流以输出流
connector Api:允许构建和运行topic连接到现有的应用程序或数据系统中重用生产者或消费者

broker:
已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息
topic:
一个topic可以认为是一类消息,每个topic可被分为多个分区(partition),每个分区在存储面是一个append log文件。kafka主题总是多用户:一个主题可以有零个一个或多个消费者订阅它
NewTopic newTopic = new NewTopic( "topic名称",分区数,副本数);
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的,对于每个topic,Kafka集群都会维护一个分区log
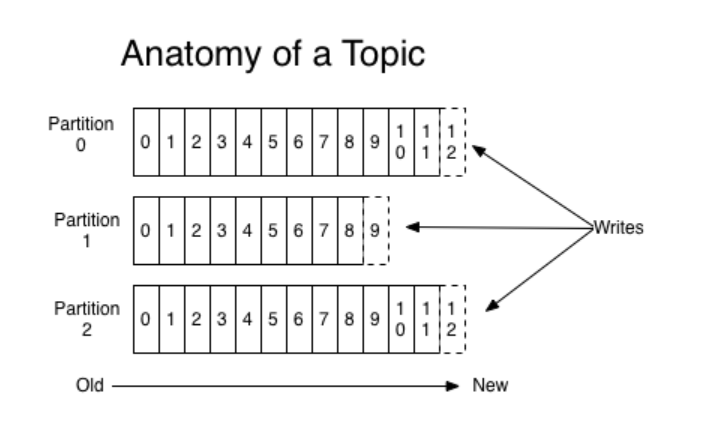
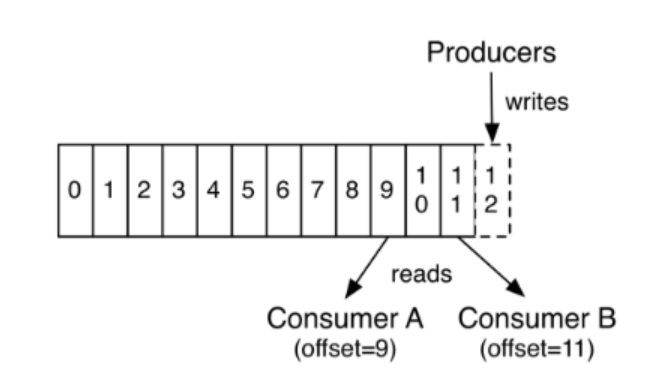
Kafka集群保持所有的消息,直到它们过期(无论消息是否被消费)。实际上消费者所持有的仅有的元数据就是这个offset(偏移量),也就是说offset由消费者来控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更早的位置,重新读取消息。可以看到这种设计对消费者来说操作自如,一个消费者的操作不会影响其它消费者对此log的处理
map.put("cleanup.policy","delete");//清除策略
map.put("retention.ms",Long.toString(topicEntity.getAgingTime()*24*60*60*1000));//设置时间
newTopic.configs(map);
我们也可通过对consumer的配置来设置他的消费策略
properties.setProperty("auto.offset.reset","earliest");
一个topic的多个partition,被分配在kafka集群中的多个server(kafka实例)上,每个server负责partition的消息的读写,还可通过配置partition需要备份的个数(副本replica),将partition被分到多台机器上,提高可用性
kafka中采用分区的设计目的:一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元
分布式:
Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。 每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。 一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理
生产者:
生产者往某个Topic上发布消息。生产者也负责选择发布到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区
消费者:
通常来讲,消息模型可以分为两种, 队列和发布-订阅式。 队列的处理方式是 一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。在发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中,那么这就变成了queue模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。 更通用的, 我们可以创建一些消费者组作为逻辑上的订阅者。每个组包含数目不等的消费者, 一个组内多个消费者可以用来扩展性能和容错
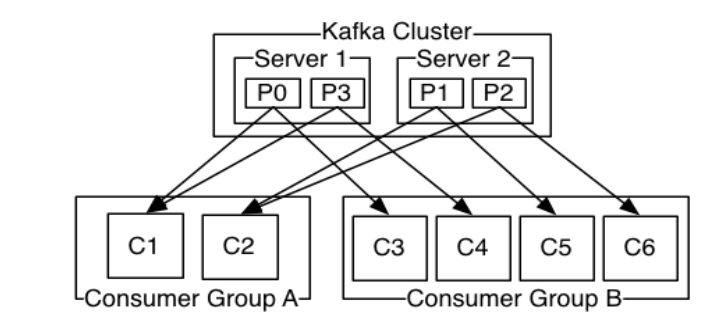
2个kafka集群托管4个分区(P0-P3),2个消费者组,消费组A有2个消费者实例,消费组B有4个
java引入kafka:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.1.0</version>
</dependency>
kafka数据生产过程:
producer.send(new ProducerRecord<>(topicName,partitions,key,value));
对于生产者要写入的一条记录,可以指定四个参数,topic,partition,key,value,其中topic和value是必要的,key和partition可选的
对于一条记录,先对其进行序列化,然后按照topic和partition放进对应的发送队列中。如果partition没填,那么:a,key有填写,按照key进行hash,相同的hash key去同一个partition;b,key没填,Round-Robin(负载均衡算法)来选择partition
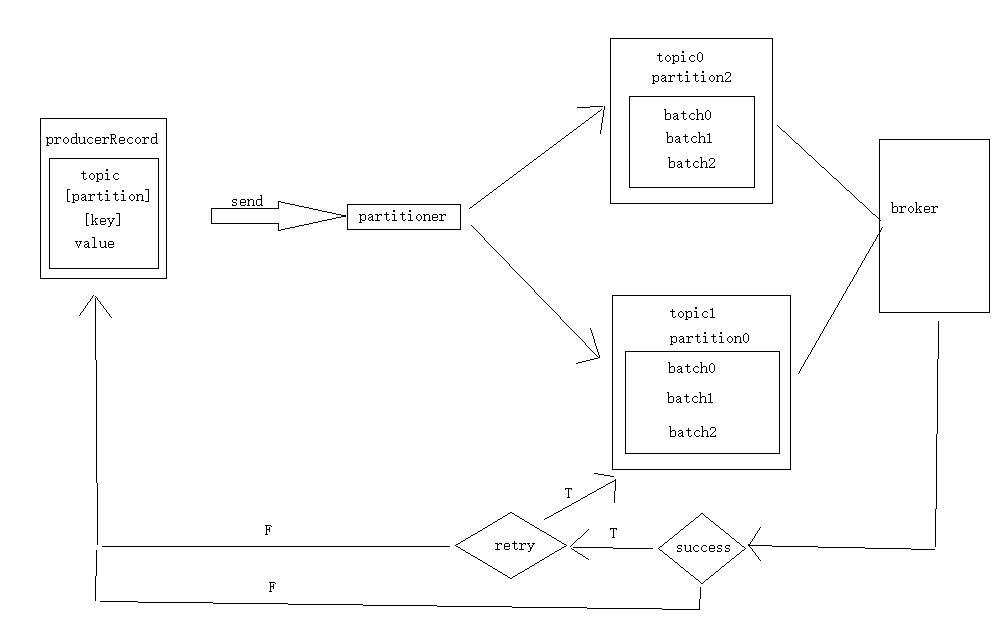
producer将会和topic下所有partition leader保持socket连接,消息由producer直接通过socket发送的broker。其中partition leader的位置注册在zookeeper中,producer作为zookeeper client,已经注册了watch用来监听partition leader的变更事件,因此可以准确的知道谁是当前leader
producer端采用异步发送:将多条消息暂且在客户端buffer起来,并将他们批量发送到broker,小数据的记录太多的话会拖慢整体的网络,所以批量延迟发送实际上提升了效率。
kafka消费数据过程:
consumer.subscribe(Collections.singleton(topicName)); consumer.poll(Duration.ofMillis(1000));
对于消费者,不是以单独的形式存在的,每一个消费者属于一个consumer group,一个group中可以包含多个consumer,需要注意:订阅topic是以一个消费组来订阅的,发送到topic的信息,只会被订阅此topic的每个group中的consumer消费到
如果所有的Consumer都属于一个group,那么就是一对一、点对点的消费,如果每个consumer属于不同的group,那么消息就是广播给所有的消费者。这个实际上是根据partition来分的,一个partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费,消费组里的每个消费者拥有与之对应的一个partition,因此,对于一个topic,同一个group中中不能有多于partition个数的consumer同时消费,否则某些consumer将无法消费到数据。
同一个消费组的两个消费者不会同时消费一个partition
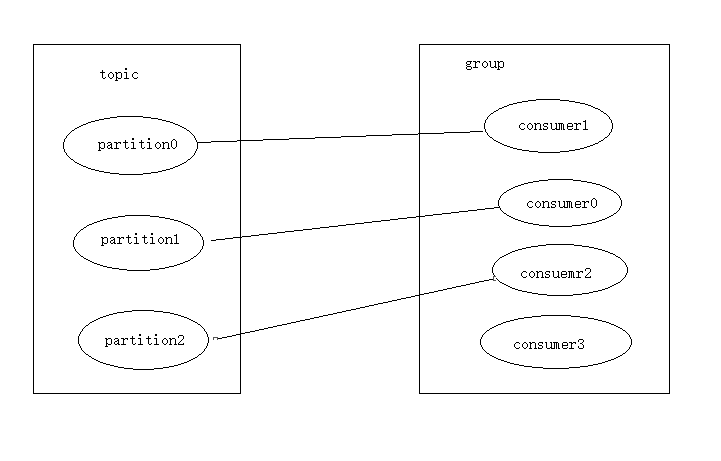
在 kafka 中,采用了 pull 方式,即 consumer 在和 broker 建立连接之后,主动去 pull(或者说 fetch )消息,首先 consumer 端可以根据自己的消费能力适时的去 fetch 消息并处理,且可以控制消息消费的进度(offset)。
发布-订阅流程:
生产者定期向主题发送消息
kafka代理存储为该特定主题配置的分区中的所有信息。它确保消息在分区之间平等分享。如果生产者发送两个消息并且有两个分区,Kafka将在第一分区中存储一个消息,在第二分区中存储第二消息
消费者订阅特定主题
一旦消费者订阅主题,kafka将向消费者提供主题的当前偏移,并且将偏移保存在zookeeper系统中
消费者将定期请求kafka信息
一旦kafka收到来自生产者的信息,它将这些消息转发给消费者
消费者收到信息并处理
一旦消息被处理,消费者向kafka代理发送确认
一旦Kafka收到确认,它将偏移设为新值,并在zookeeper中更新它,由于偏移在zookeeper中维护,消费者可以正确收到下一条记录,即使服务器拥堵期间
以上流程将重复执行直到消费者停止消费
消费者可以随时回退/跳转到所需的主题偏移量,并阅读所有后续消息

