
热门标签
热门文章
- 1Docker - 基本概念、与虚拟机的区别、架构、镜像操作、容器操作、数据卷挂载
- 2mac上配置redis_mac 使用redis
- 3【氮化镓】AlGaN/GaN HEMTs沟道温度测量
- 4MovieWriter imagemagick unavailable. Trying to use pillow instead._moviewriter imagemagick unavailable; using pillow
- 5Android CardView卡片布局详解(八)_androidx.cardview.widget.cardview
- 6kubectl入门命令_如何使用bat执行kubectl
- 7内容为王,推广为后:技术博客文章推广全攻略
- 8时间复杂度计算方法
- 9Docker之查看并获取最新Ubuntu镜像(十)_dockerhub查找镜像
- 10使用Docker部署MinIO并结合内网穿透实现远程访问本地数据_minio访问控制
当前位置: article > 正文
搭建单机版伪分布式Hadoop+Scala+spark
作者:Gausst松鼠会 | 2024-05-05 23:01:12
赞
踩
搭建单机版伪分布式Hadoop+Scala+spark
目录
一.OpenJDK搭建
1.卸载删除自身openjdk
创建用户和删除自身OpenJDK
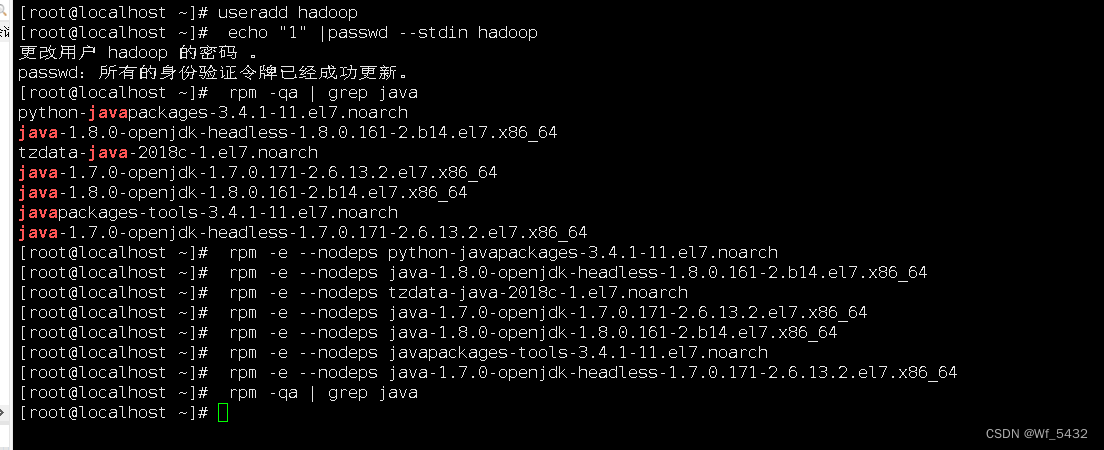
2.安装JDK
[root@localhost software]# tar -zxvf jdk-8u152-linux-x64.tar.gz -C /usr/local/src/
## 解压指定到 /usr/local/src
3.配置Java变量
配置文件位置: /etc/profile
末行添加如下两行内容(版本号相对应同上) source 使设置生效
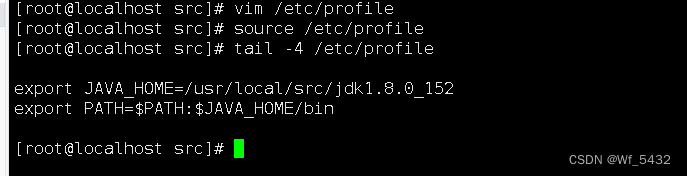
4.检测JAVA是否可用

二.Hadoop搭建
1.解压安装
##将安装包解压到/usr/local/src/目录下
[root@localhost software]# tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local/src/

2.配置Hadoop变量
1.位置:/etc/profile
添加如下内容 并使环境生效

2.位置:hadoop-env.sh
修改如下 /usr/local/src/hadoop-2.7.1/etc/hadoop 中的 hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
3.位置:core-site.xml
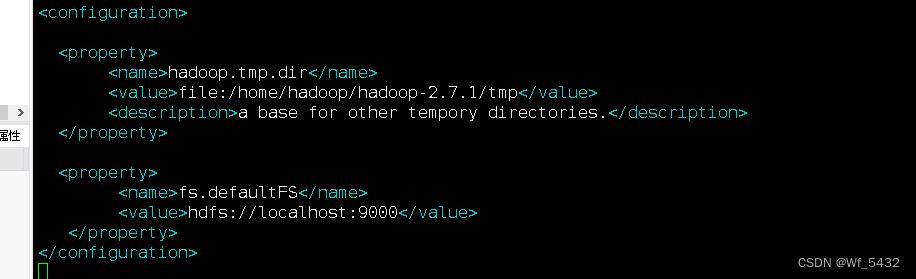
4.位置:hdfs-site.xml
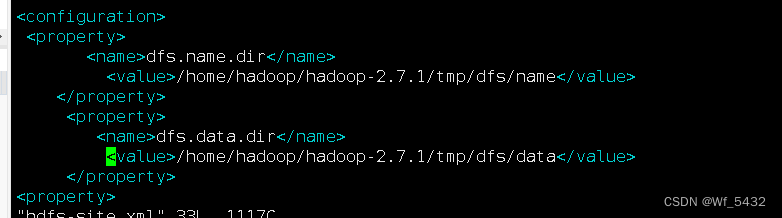
5.位置:mapred-site.xml.template
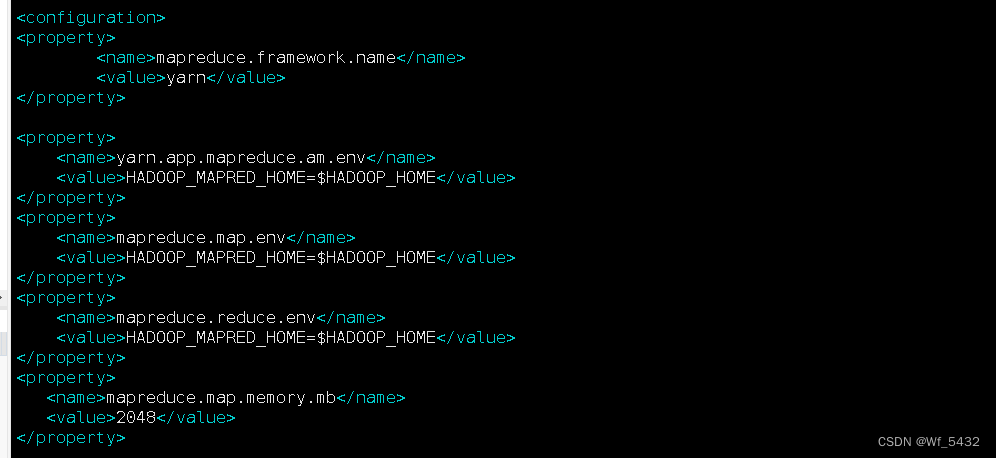
6.位置:yarn-site.xml

3.访问50070
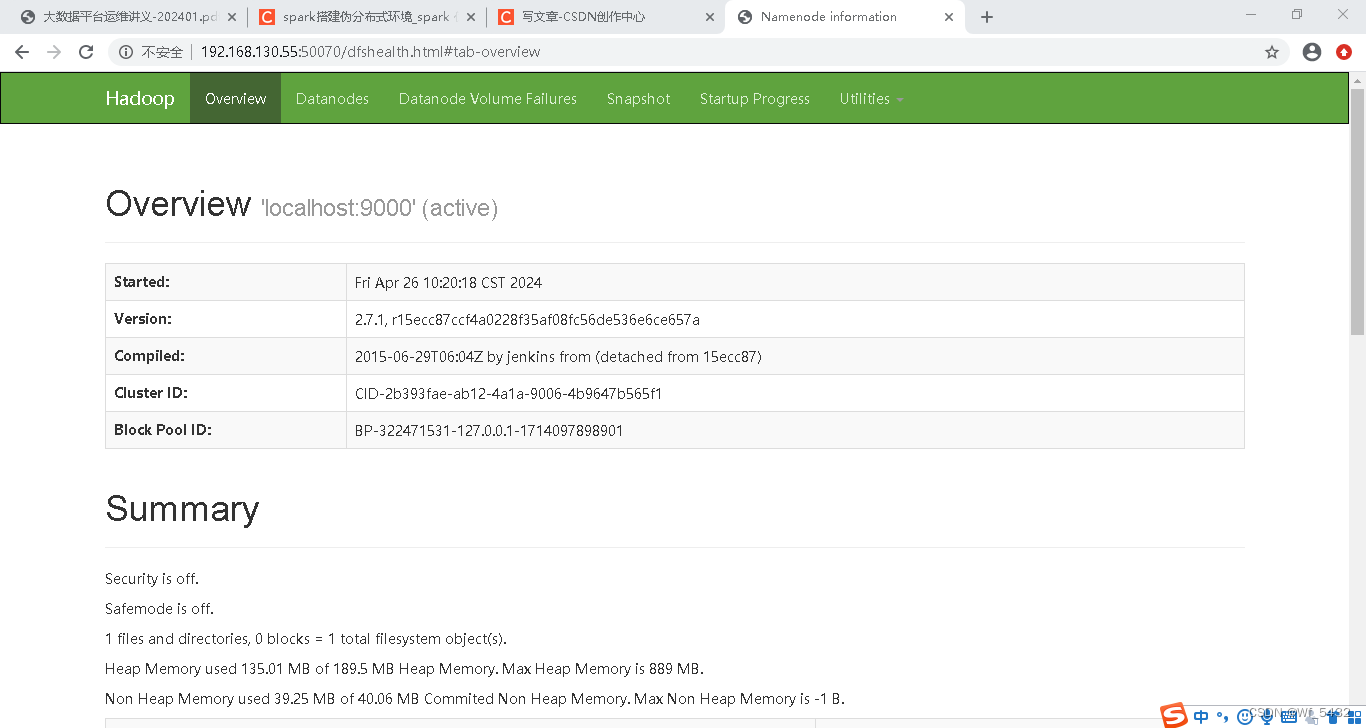
三.spark搭建
1.解压安装
tar -zxvf spark-3.2.1-bin-hadoop2.7.tgz -C /usr/local/src/
2.配置spark环境
1.位置:spark-env.sh.template
/usr/local/src/spark-3.2.1-bin-hadoop2.7/conf 中的spark-env.sh.template
更名 ___[root@localhost conf]# cp spark-env.sh.template spark-env.sh

2.位置:/etc/profile
添加如下

四.scala搭建
1.解压安装
[root@localhost src]# tar -zxvf scala-2.11.8.tgz -C /usr/local/src/
2.配置Scala环境
/etc/profile source /etc/profile 生效
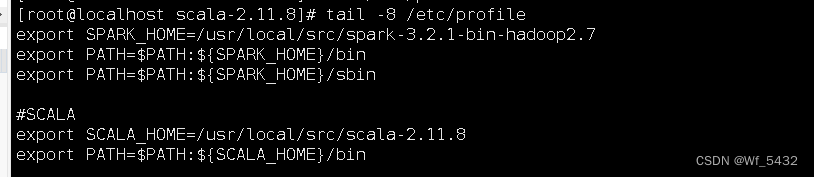
3.Scala

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/541241
推荐阅读
相关标签

