
- 1RedHat本地yum源配置及国内镜像源配置_redhat配置yum源
- 203Vue3-模板语法_vue3模板语法
- 3Linux03:Vim使用及账号用户管理_用户账号退出
- 4AI 绘画工具 Stable Diffusion 本地安装使用
- 5pandas.read_csv utf-8和gbk编码都无法顺利读取csv文件_用gbk和utf-8打开csv都报错
- 65、DNS,防火墙,mysql总结_防火墙设置是否允许 mysql 数据库端口通过。如果防火墙阻止了端口,就需要修改防火
- 7探秘 AssetManage:一款强大的资产管理工具
- 8chatgpt赋能python:Python文件夹备份:保护您的数据
- 9jenkins实现接口自动化持续集成(python+pytest+ Allure+git)_linux搭建jenkins实现接口自动化持续集成
- 100基础如何自学软件测试?并且拿到一份10k的入职offer...
ChatGLM 实践指南_chatglm手册
赞
踩
随着ChatGPT代表的AI大模型的爆火,我一直在想,是否能把大模型的能力用于个人或者企业的知识管理上,打造一个私有的AI助手。它了解你的所有知识,并且不会遗忘,在需要的时候召唤它就能解决问题,就如同钢铁侠的贾维斯。但是受限于硬件成本、学习成本一直未能实践。
如今ChatGLM2-6b、LLama2等越来越多强大的开源模型的出现,成本和安全性越来越可控,私有知识库也就逐渐变得可落地。再加上看到阿里云提供的免费GPU使用,于是便有了这一篇实践指南。
跟着本文的操作步骤,相信你也可以从0到1部署自己的第一个私有大模型。
ChatGLM2-6B概述
ChatGLM2-6B 是清华 NLP 团队于不久前发布的中英双语对话模型,它具备了强大的问答和对话功能。拥有最大32K上下文,并且在授权后可免费商用!
ChatGLM2-6B的6B代表了训练参数量为60亿,同时运用了模型量化技术,意味着用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)
详细介绍(官方git:https://github.com/thudm/chatglm2-6b ):

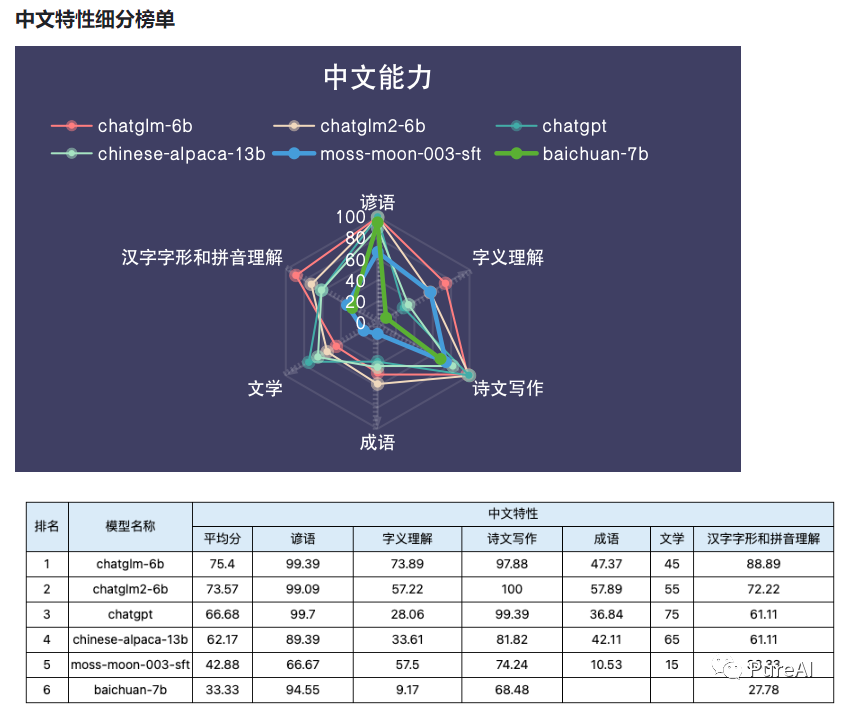
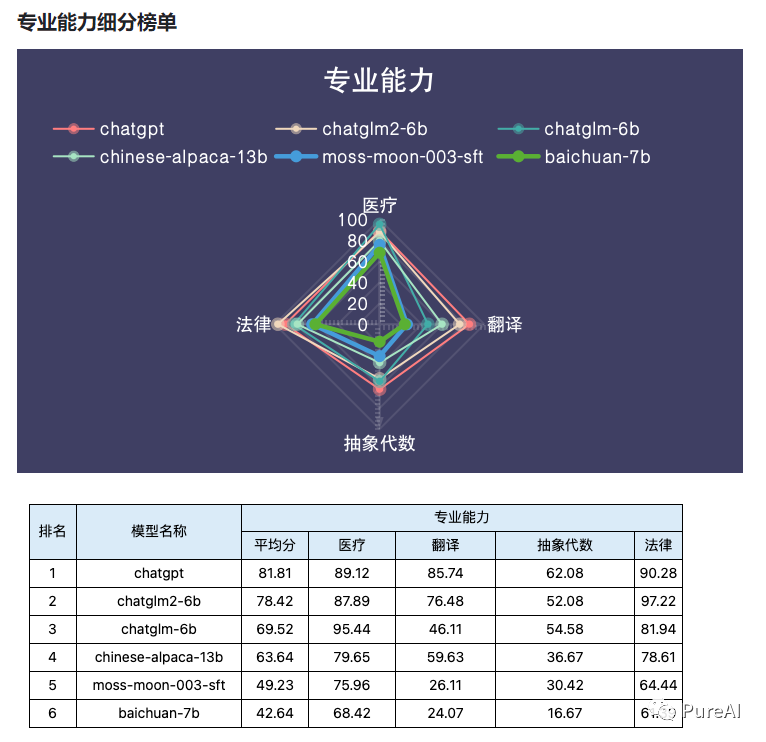
ChatGLM2-6B能力评测
根据专业机构TeSaiFa评测:https://github.com/TeSaiFa/llm-auto-eval ,ChatGLM2-6B模型在基础能力和专业能力方面均接近ChatGPT,中文特性则更胜一筹。数据详情参考:
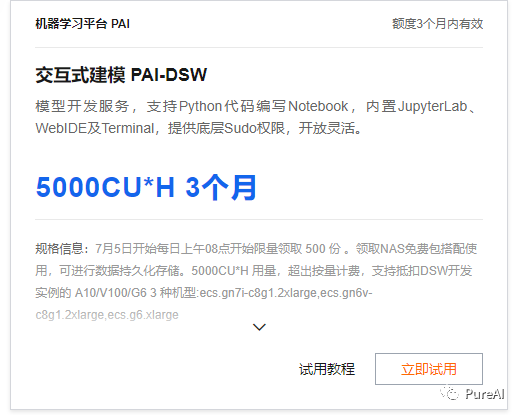
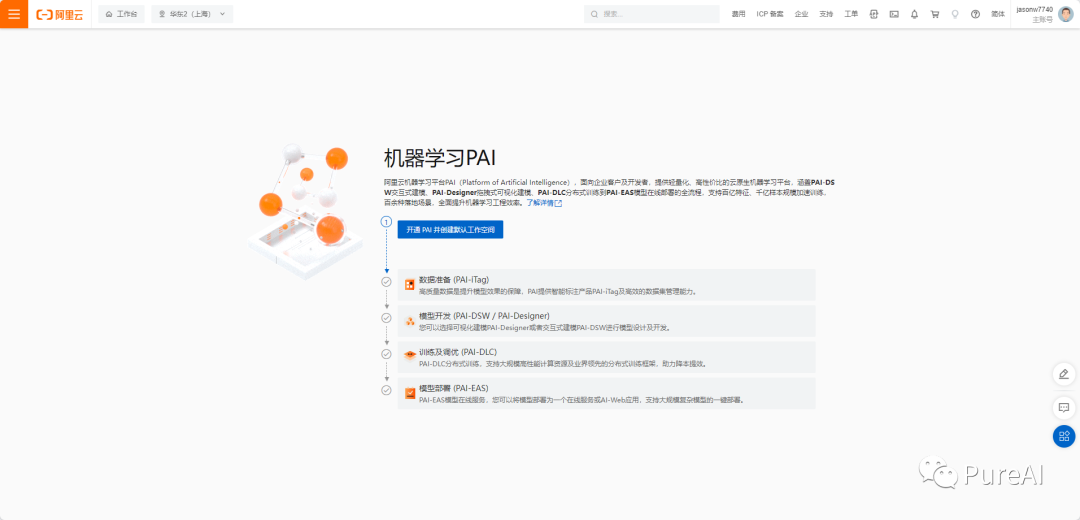
阿里云部署流程
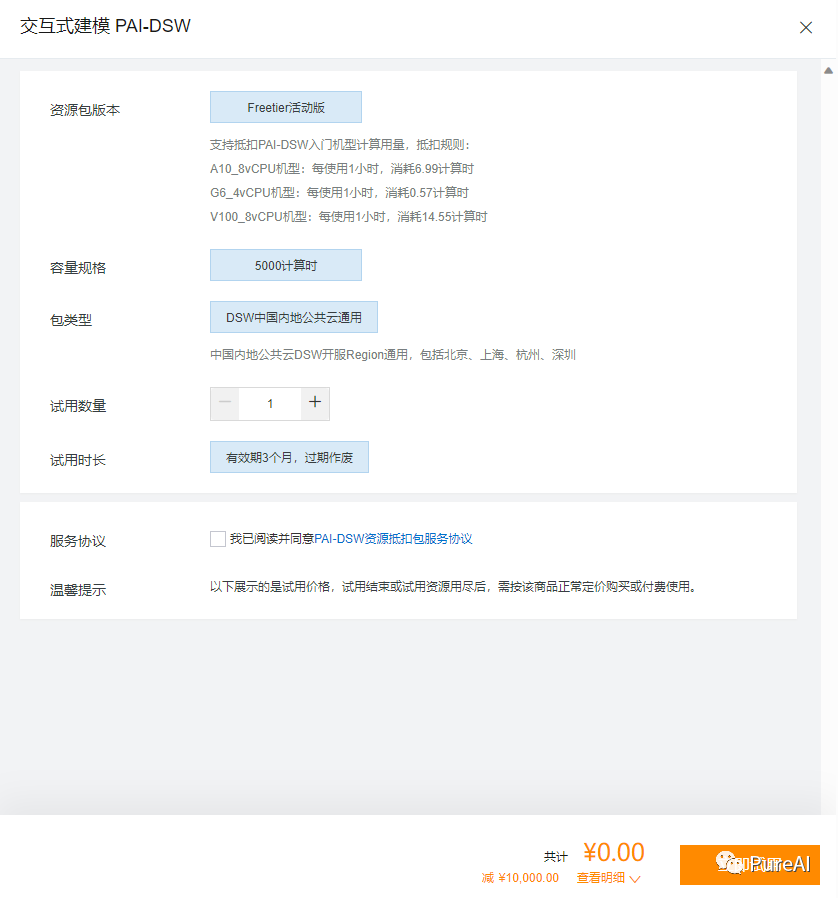
step1,白嫖阿里云的机器学习 PAI -DSW平台, A10 显卡
地址:https://free.aliyun.com/?product=9602825
step2,创建工作空间和DSW实例
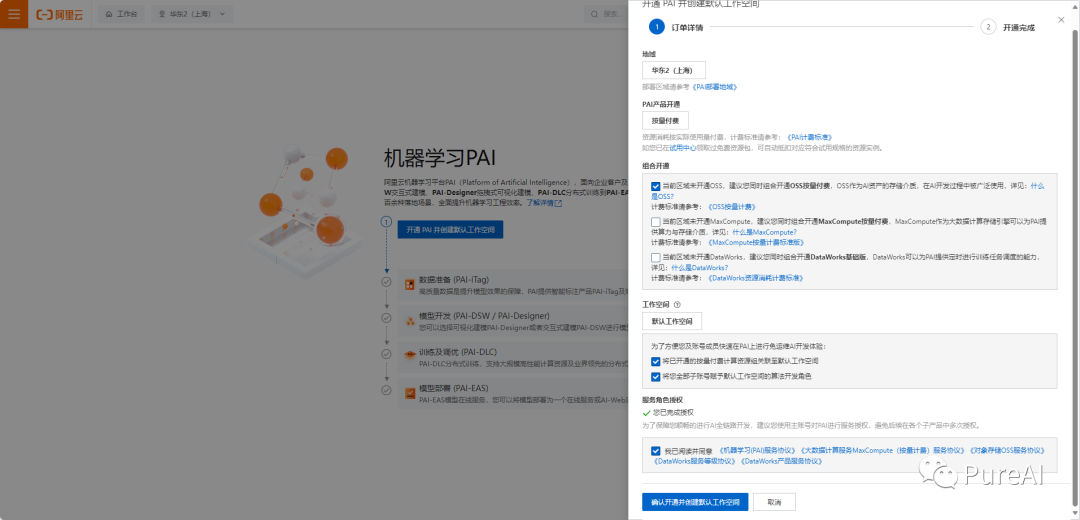
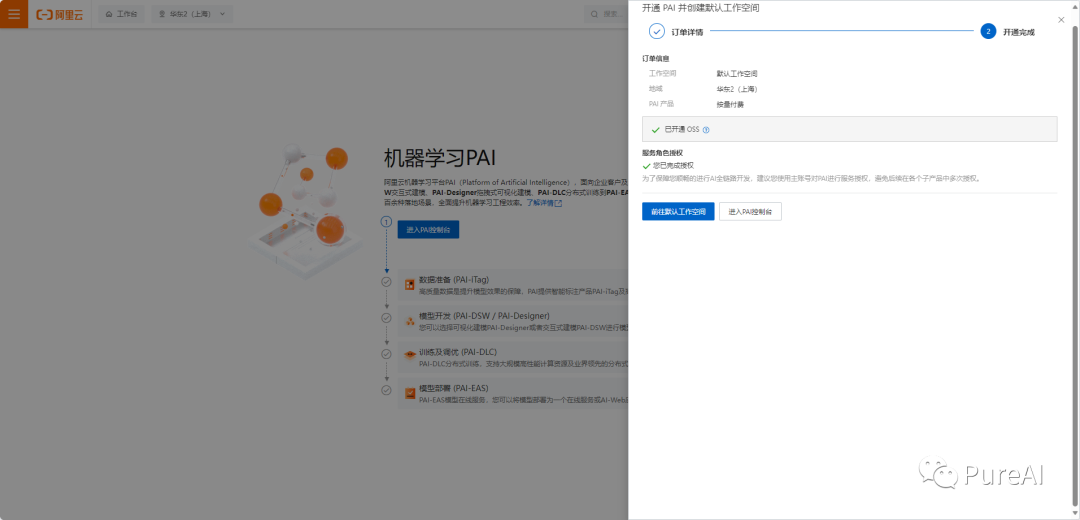
创建DSW实例
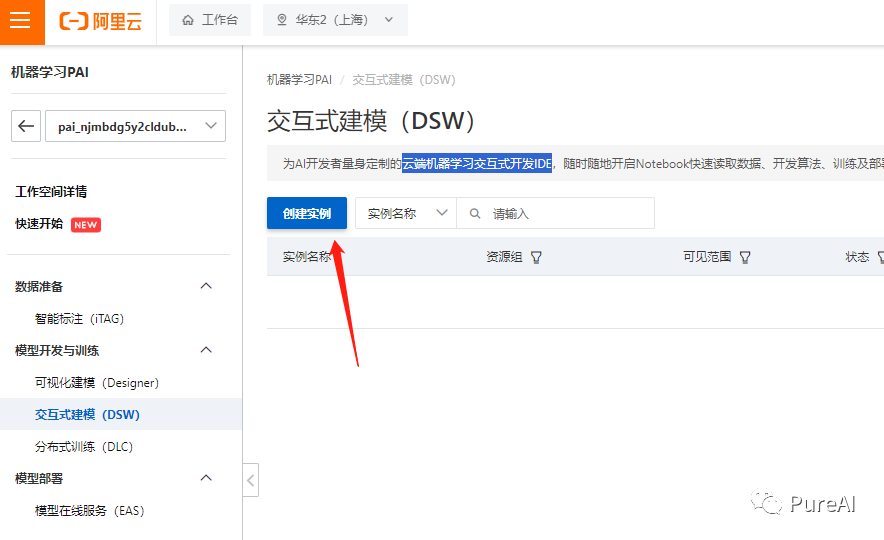
输入实例名称,免费的GPU 只能选择 A10 或者 V100 都行,V100 性能更好但是贵,A10 显卡每小时消耗6.991计算时,如果不关机持续使用大概可以使用30天。这里我们学习使用就选择A10
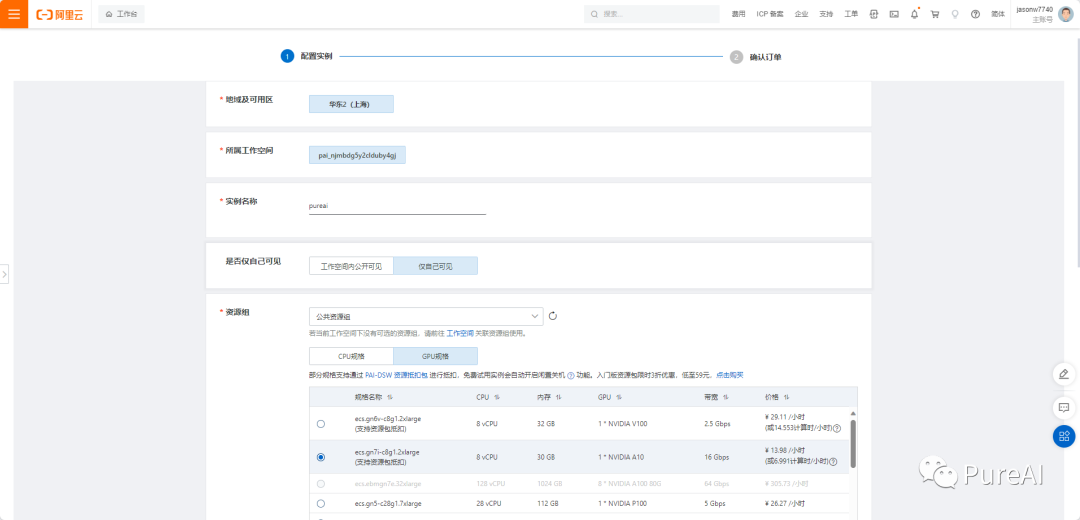
数据集是可选的,如果想闲时关机建议使用数据集,可以把数据保存,不然每次关机后启动都得重新部署。
镜像选择:

step3,构建ChatGLM2-6b环境
打开DSW(Data Science Workshop)实例,打开terminal终端
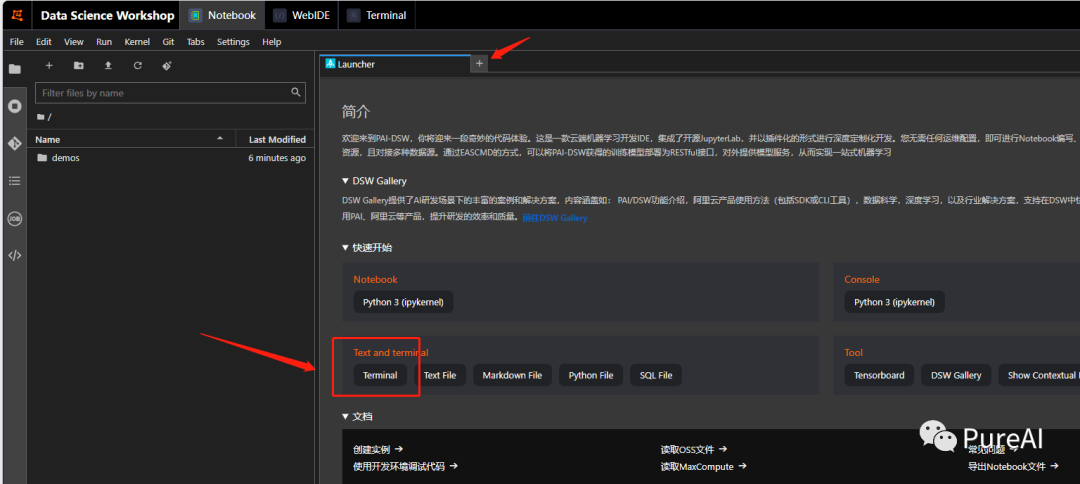
打开终端,依次执行如下命令,更新相关基础工具
apt-get updateapt-get install git-lfs下载模型代码
git clone https://github.com/THUDM/ChatGLM2-6B.git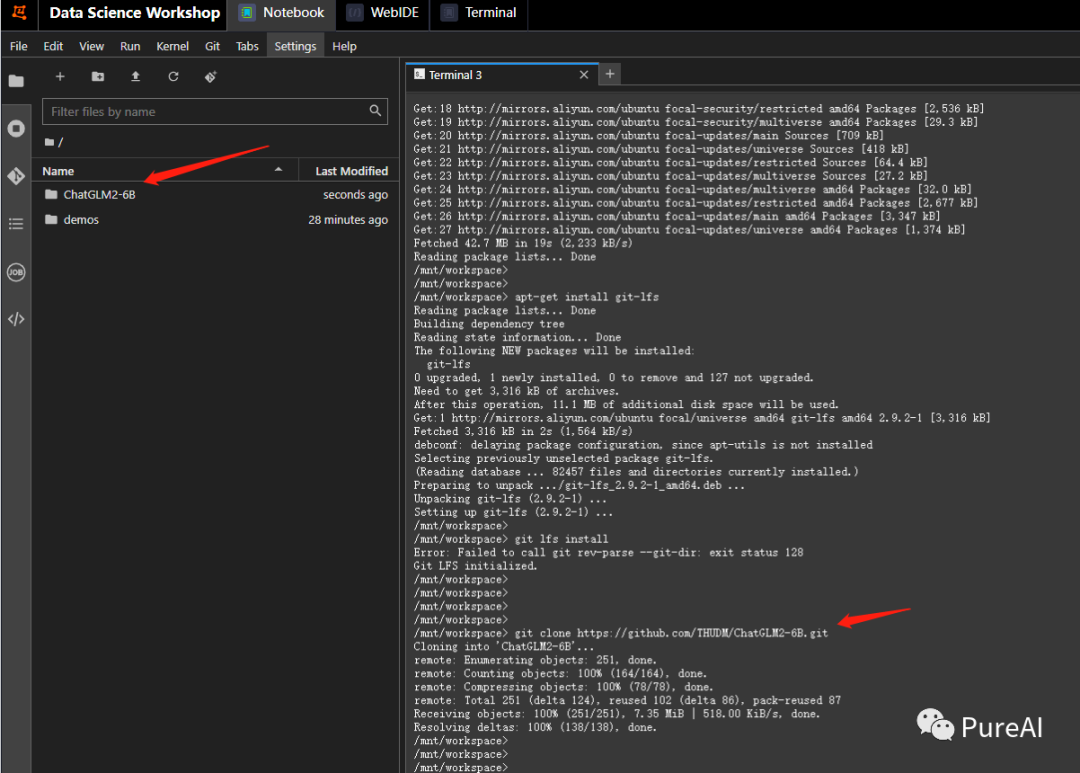
安装依赖
cd ChatGLM2-6Bpip install -r requirements.txt正式下载模型
## 这里我加载到module目录下git clone https://huggingface.co/THUDM/chatglm2-6b module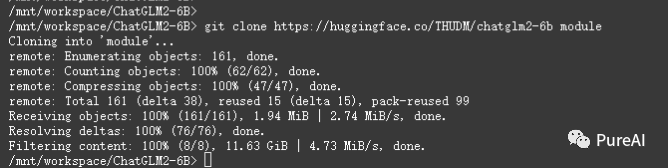
!!!特别注意,这里下载很慢,务必全部下载完成后再进行下一步骤
step4,在DSW中启动WebUI
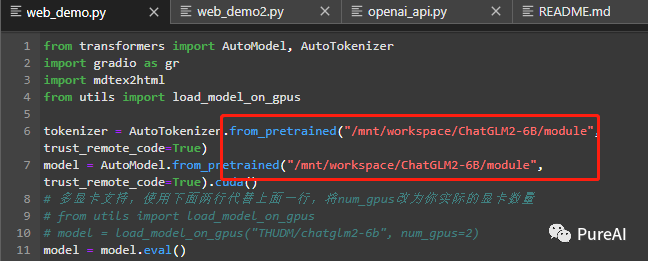
!!!特别注意,务必填写正确的绝对路径地址,不然可能报我这种错误
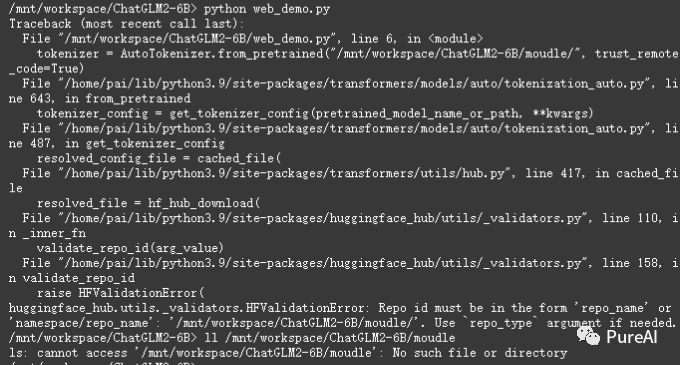
启动web,但是这里不能公网访问python web_demo.py
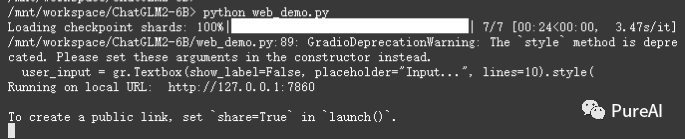
还是在web_demo.py配置share=true开放公网访问。
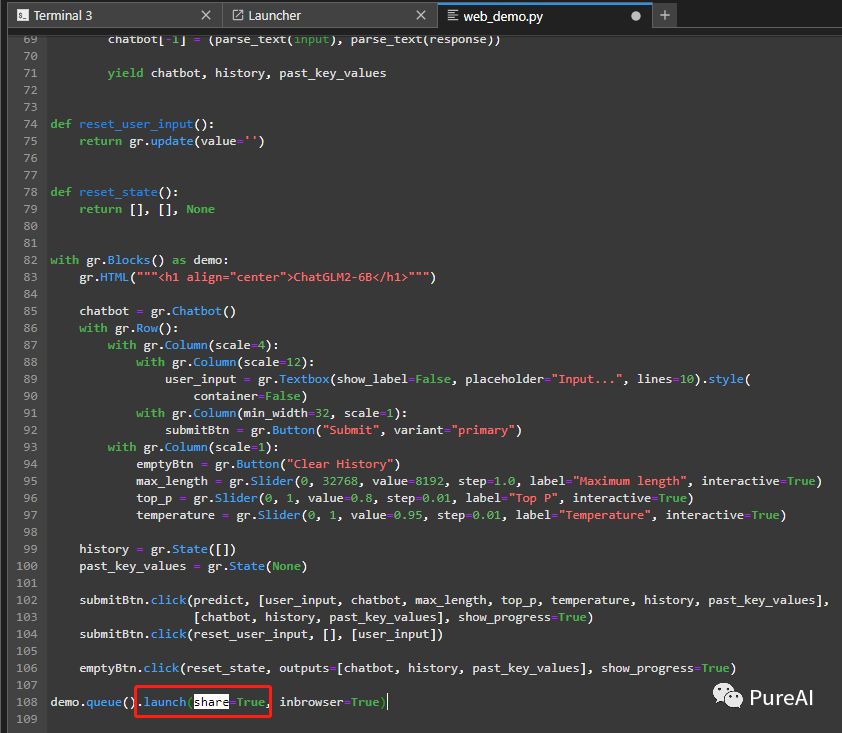
获得公网地址

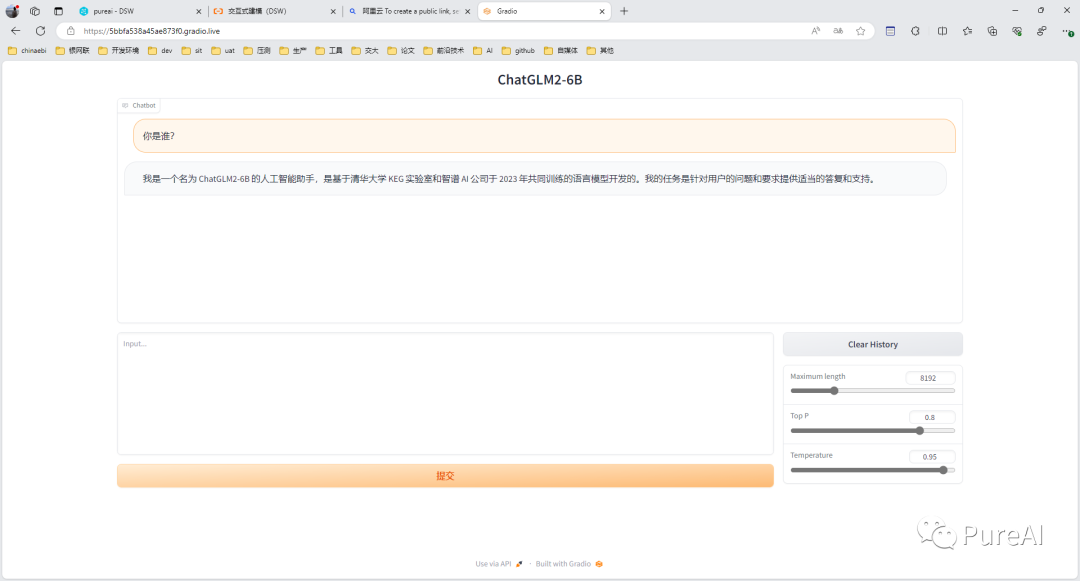
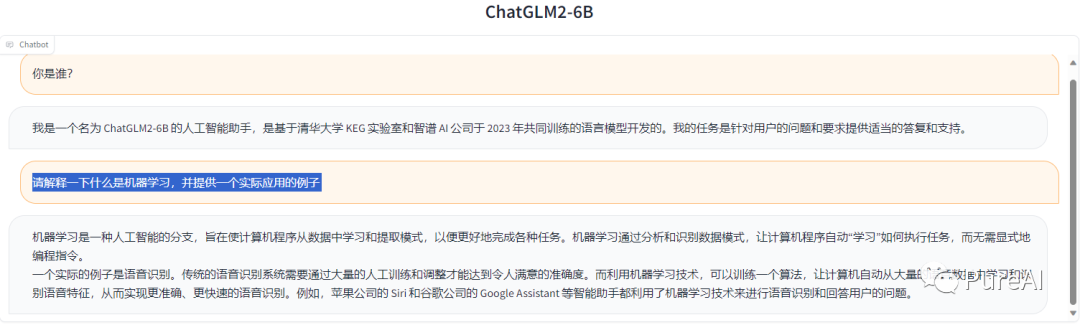
访问成功
写在后面
本篇是开源大模型实践指南系列的第一篇,后续会再更新关于模型的训练微调,基于向量的知识库的搭建等等,欢迎点赞关注,获取最新文章~
本文参考:
ChatGLM官方仓库:https://github.com/thudm/chatglm2-6
模型评测:https://github.com/TeSaiFa/llm-auto-eval
阿里云:https://free.aliyun.com/?product=9602825

