
- 1Python实现图的最短路径算法_python 图 最短路径
- 2单点登录(SSO)看这一篇就够了
- 3修改fstab导致UBUNTU无法启动的解决办法_linux开机显示systemd-fstab-generator failed with exit
- 4性能测试(三)----loadrunner的使用_loadrunner压力测试500并发
- 5如何补丁1个文件(linux diff patch)_patch: **** only garbage was found in the patch in
- 6upload-labs·文件上传(靶场攻略)
- 7安卓开发投屏反控实现方式_android投屏功能开发
- 8NLTK:自然语言处理的巫师,Python中的语言大师!
- 9利用android studio制作简单的QQ的注册、登录、忘记密码的页面_android studio注册qq页面
- 10H5页面在浏览器中跳转APP的方式/URL Scheme/Universal Link_url scheme前端
Paper:《Is GPT-4 a Good Data Analyst?GPT-4是一个好的数据分析师吗?》翻译与解读_gpt data analyst
赞
踩
Paper:《Is GPT-4 a Good Data Analyst?GPT-4是一个好的数据分析师吗?》翻译与解读
导读:该论文提出了一个框架,用来引导GPT-4进行端到端的数据分析任务,包括数据提取、可视化生成以及数据分析。GPT-4 能生成SQL查询来提取相关数据,根据问题绘制合适的图表,并分析数据识别趋势和见解。实验结果表明,在某种程度上GPT-4与人类数据分析师达到相当的水平,虽然在准确性和避免产生幻觉方面仍有改进空间。与人类数据分析师相比,GPT-4 的速度和成本更低。但它缺少背景知识的结合和能力在分析中表达情感。作者指出需要解决的几个问题,才能得出结论认为GPT-4完全可以替换人类数据分析师,例如保证高精度、结合背景假设和收集更多的商业需求。总的来说,虽然根据初步实验GPT-4表现出作为数据分析师很有前途的能力,但还需要进一步的研究,考虑到各种实际问题,才能得出结论认为它完全可以替换人类数据分析师。 该论文提供了有用的启示和前景作业。简而言之,虽然GPT-4展示出部分能力去完成与人类相当水平的数据分析任务,但还需要弥合差距,大型语言模型才能完全替换人类数据分析师。
目录
《Is GPT-4 a Good Data Analyst? GPT-4是一个好的数据分析师吗?》翻译与解读
2.1、Related Tasks and Datasets相关任务和数据集
2.2、Abilities of GPT-3, ChatGPT and GPT-4——GPT-3、ChatGPT和GPT-4的能力
3.1、Background: Data Analyst Job Scope——背景:数据分析师工作范围
4.1、Step 1: Code Generation——第一步:代码生成 第一步的输入
4.2、Step 2: Code Execution第二步:代码执行
4.3、Step 3: Analysis Generation第三步:分析生成
7、Findings and Discussions研究结果与讨论
《Is GPT-4 a Good Data Analyst? GPT-4是一个好的数据分析师吗?》翻译与解读
| 时间 | 2023年5月24日 |
| 作者 | Liying Cheng1 Xingxuan Li ∗ 1,2 Lidong Bing1 1DAMO Academy, Alibaba Group 2Nanyang Technological University, Singapore {liying.cheng, xingxuan.li, l.bing}@alibaba-inc.com |
| 地址 |
Abstract摘要
| As large language models (LLMs) have demon-strated their powerful capabilities in plenty of domains and tasks, including context under-standing, code generation, language generation, data storytelling, etc., many data analysts may raise concerns if their jobs will be replaced by artificial intelligence (AI). This controver-sial topic has drawn great attention in pub-lic. However, we are still at a stage of diver-gent opinions without any definitive conclusion. Motivated by this, we raise the research ques-tion of “is GPT-4 a good data analyst?” in this work and aim to answer it by conducting head-to-head comparative studies. In detail, we regard GPT-4 as a data analyst to perform end-to-end data analysis with databases from a wide range of domains. We propose a frame-work to tackle the problems by carefully de-signing the prompts for GPT-4 to conduct ex-periments. We also design several task-specific evaluation metrics to systematically compare the performance between several professional human data analysts and GPT-4. Experimental results show that GPT-4 can achieve compara-ble performance to humans. We also provide in-depth discussions about our results to shed light on further studies before we reach the conclusion that GPT-4 can replace data ana-lysts. Our code, data and demo are available at: https://github.com/DAMO-NLP-SG/GPT4-as-DataAnalyst. | 随着大型语言模型(LLM)在许多领域和任务中展示了其强大的能力,包括上下文理解、代码生成、语言生成、数据叙事等,许多数据分析师可能会担心他们的工作是否会被人工智能(AI)取代。这个有争议的话题引起了公众的极大关注。然而,我们仍然处于意见分歧的阶段,没有任何明确的结论。出于这个动机,我们在这项工作中提出了“GPT-4是否是一个好的数据分析师?”的研究问题,并通过进行一对一的比较研究来回答这个问题。具体而言,我们将GPT-4视为一个数据分析师,使用来自各个领域的数据库进行端到端的数据分析。我们提出了一个框架来解决这些问题,通过精心设计GPT-4的提示来进行实验。我们还设计了几个任务特定的评估指标,以系统地比较几位专业人员和GPT-4之间的性能。实验结果表明,GPT-4可以达到与人类可比较的性能。我们还对结果进行了深入的讨论,以在我们得出GPT-4可以取代数据分析师的结论之前,为进一步的研究提供启示。我们的代码、数据和演示可以在以下网址找到:https://github.com/DAMO-NLP-SG/GPT4-as-DataAnalyst |
1、Introduction引言
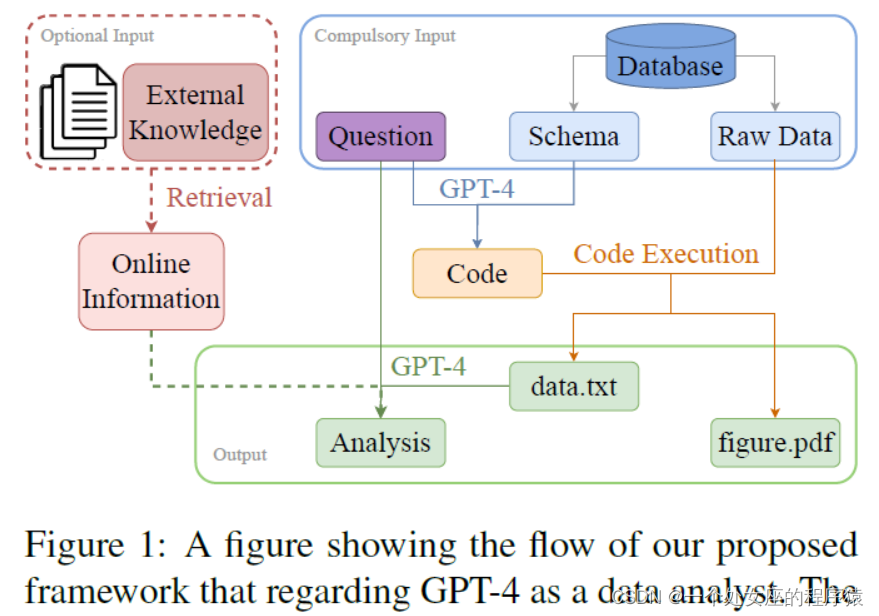
| LLMs such as GPT series have shown their strong abilities on various tasks in natural language pro- cessing (NLP) community, including data anno- tator (Ding et al., 2022), data evaluator (Chiang and Lee, 2023; Luo et al., 2023; Wang et al., 2023; Wu et al., 2023b; Shen et al., 2023), etc. Outside the NLP community, researchers also evaluate the LLM abilities in multiple domains, such as finance(Wu et al., 2023c), healthcare (Han et al., 2023; Li et al., 2023b), biology (Zheng et al., 2023), law (Sun, 2023), psychology (Li et al., 2023a), etc. Most of these researches demonstrate the effec- tiveness of LLMs when applying it to different tasks. However, the strong ability in understanding, reasoning, creativity causes some potential anxiety among certain groups of people. As LLMs are introduced and becoming popu- lar not only in NLP community but also in many other areas, those people in and outside of the NLP community are considering or worrying whether AI can replace certain jobs (Noever and Ciolino, 2023; Wu et al., 2023a). One such job role that could be naturally and controversially “replaced” by AI is data analyst (Tsai et al., 2015; Ribeiro et al., 2015). The main and typical job scopes for a data analyst include extracting relevant data from several databases based on business partners’ requirements, presenting data visualization in an easily understandable way, and also providing data analysis and insights for the audience. The overall process is shown in Figure 1, which a data an- alyst is often asked to fulfill during work. This job involves a relatively routine scope, which may become repetitive at times. It also requires sev- eral technical skills, including but not limited to SQL, Python, data visualization, and data analysis, making it relatively expensive. As this job scope may adhere to a relatively fixed pipeline, there is a heated public debate about the possibility of an AI replacing a data analyst, which attracts significant attention. | 像GPT系列这样的LLM已经在自然语言处理(NLP)社区中展示出了它们在各种任务上的强大能力,包括数据注释(Ding等,2022)、数据评估(Chiang和Lee,2023;Luo等,2023;Wang等,2023;Wu等,2023b;Shen等,2023)等。在NLP社区之外,研究人员还评估了LLM在多个领域中的能力,例如金融(Wu等,2023c)、医疗保健(Han等,2023;Li等,2023b)、生物学(Zheng等,2023)、法律(Sun,2023)、心理学(Li等,2023a)等。这些研究中的大部分都证明了LLM在不同任务中的有效性。然而,理解、推理和创造力方面的强大能力引起了某些人群的潜在焦虑。 随着LLM的引入和在NLP社区以及其他许多领域的流行,NLP社区内外的人们正在考虑或担心人工智能是否可以取代某些工作(Noever和Ciolino,2023;Wu等,2023a)。其中一个可能被人工智能自然而然地“取代”的工作角色是数据分析师(Tsai等,2015;Ribeiro等,2015)。数据分析师的主要和典型工作范围包括根据业务伙伴的要求从多个数据库中提取相关数据,以易于理解的方式呈现数据可视化,并为受众提供数据分析和洞察。整个过程如图1所示,数据分析师通常在工作中需要完成这些任务。这项工作涉及相对固定的范围,有时可能变得重复。它还需要一些技术技能,包括但不限于SQL、Python、数据可视化和数据分析,因此相对昂贵。由于这项工作范围可能遵循一个相对固定的流程,关于AI是否可以取代数据分析师的可能性存在激烈的公开辩论,引起了广泛关注。 |
| In this paper, we aim to answer the following research question: Is GPT-4 a good data analyst? To answer this question, we conduct preliminary studies on GPT-4 to demonstrate its potential capa- bilities as a data analyst. We quantitatively evaluate the pros and cons of LLM as a data analyst mainly from the following metrics: performance, time, and cost. In specific, we treat GPT-4 as a data analyst to conduct several end-to-end data analysis problems. Since there is no existing dataset for such data anal- ysis problems, we choose one of the most related dataset NvBench, and add the data analysis part on top. We design several automatic and human evaluation metrics to comprehensively evaluate the quality of the data extracted, charts plotted and data analysis generated. Experimental results show that GPT-4 can beat an entry level data analyst in terms of performance and have comparable performance to a senior level data analyst. In terms of cost and time, GPT-4 is much cheaper and faster than hiring a data analyst. | 在本文中,我们旨在回答以下研究问题:GPT-4是否是一个好的数据分析师?为了回答这个问题,我们对GPT-4进行初步研究,以展示它作为数据分析师的潜在能力。我们从性能、时间和成本等方面对LLM作为数据分析师的优缺点进行定量评估。具体而言,我们将GPT-4视为一个数据分析师,来解决几个端到端的数据分析问题。由于目前还没有现有的数据集适用于这样的数据分析问题,我们选择了与之相关性最高的数据集NvBench,并在其基础上添加了数据分析部分。我们设计了几个自动化和人工评估指标,全面评估提取的数据、绘制的图表和生成的数据分析的质量。实验结果表明,GPT-4在性能方面可以击败一个初级数据分析师,并且在性能上可以与一位高级数据分析师相媲美。在成本和时间方面,与雇佣一位数据分析师相比,GPT-4更便宜和更快速。 |
| However, since it is a preliminary study on whether GPT-4 is a good data analyst, we pro- vide fruitful discussions on whether the conclu- sions from our experiments are reliable in real life business from several perspectives, such as whether the questions are practical, whether the human data analysts we choose are representative, etc. To sum- marize, our contributions include: We for the first time raise the research question of whether GPT-4 is a good data analyst, and quantitatively evaluate the pros and cons. For such a typical data analyst job scope, we propose an end-to-end automatic framework to conduct data collection, visualization, and analysis. We conduct systematic and professional human evaluation on GPT-4’s outputs. The data analy- sis and insights with good quality can be considered as the first benchmark for data analysis in NLP community. | 然而,由于这只是关于GPT-4是否是一个好的数据分析师的初步研究,我们从多个角度提供了丰富的讨论,以探讨我们实验的结论在实际业务中是否可靠,例如问题是否实用,我们选择的人类数据分析师是否具有代表性等等。总结起来,我们的贡献包括: 我们首次提出了关于GPT-4是否是一个好的数据分析师的研究问题,并进行了定量评估。 对于这种典型的数据分析师工作范围,我们提出了一个端到端的自动化框架,用于进行数据收集、可视化和分析。 我们对GPT-4的输出进行了系统的专业人工评估。具有良好质量的数据分析和洞察可以被视为NLP社区中数据分析的第一个基准。 |
| Figure 1: A figure showing the flow of our proposed framework that regarding GPT-4 as a data analyst. The compulsory input information containing both the busi- ness question and the database is illustrated in the blue box on the upper right. The optional input referring to the external knowledge source is circled in the red dotted box on the upper left. The outputs including the extracted data (i.e., “data.txt”), the data visualization (i.e., “figure.pdf ”) and the analysis are circled in the green box at the bottom. | 图1:展示了我们提出的将GPT-4视为数据分析师的框架的流程图。必需的输入信息包括业务问题和数据库,如右上方的蓝色框所示。可选输入指的是外部知识来源,如左上方的红色虚线框所示。输出包括提取的数据(即"data.txt")、数据可视化(即"figure.pdf")和分析,如底部的绿色框所示。 |
2、Related Work相关工作
2.1、Related Tasks and Datasets相关任务和数据集
| Since our task setting is new in NLP community, there is no existing dataset that is fully suitable for our task. We explore the most relevant tasks and datasets. First, the NvBench dataset (Luo et al., 2021) translates natural language (NL) queries to corresponding visualizations (VIS), which covers the first half of the main job scope of a data an- alyst. This dataset has 153 databases along with 780 tables in total and covers 105 domains, and this task (NL2VIS) has attracted significant atten- tion in both commercial visualization vendors and academic researchers. Another popular subtask of the NL2VIS task is called text-to-sql, which con- verts natural language questions into SQL queries (Zhong et al., 2017; Guo et al., 2019; Qi et al., 2022; Gao et al., 2022). Spider (Yu et al., 2018), SParC (Yu et al., 2019b) and CoSQL (Yu et al., 2019a) are three main benchmark datasets for text-to-sql tasks. Since this work is more focused on imitating the overall process of the job scope of a data analyst, we adopt the NL2VIS task which has one more step forward than the text-to-sql task. | 由于我们的任务设置在NLP社区中是新的,目前没有现有的完全适合我们任务的数据集。我们探索了最相关的任务和数据集。首先,NvBench数据集(Luo等,2021)将自然语言(NL)查询翻译为相应的可视化(VIS),涵盖了数据分析师主要工作范围的前半部分。该数据集总共包含153个数据库和780个表,涵盖了105个领域,该任务(NL2VIS)在商业可视化供应商和学术研究人员中引起了广泛关注。NL2VIS任务的另一个流行子任务称为文本到SQL,它将自然语言问题转换为SQL查询(Zhong等,2017;Guo等,2019;Qi等,2022;Gao等,2022)。Spider(Yu等,2018)、SParC(Yu等,2019b)和CoSQL(Yu等,2019a)是文本到SQL任务的三个主要基准数据集。由于本工作更注重模仿数据分析师工作范围的整个过程,我们采用了比文本到SQL任务更进一步的NL2VIS任务。 |
| For the second part of data analysis, we also ex- plore relevant tasks and datasets. Automatic chart summarization (Mittal et al., 1998; Ferres et al., 2013) is a task that aimed to explain a chart and summarize the key takeaways in the form of natu- ral language. Indeed, generating natural language summaries from charts can be very helpful to infer key insights that would otherwise require a lot of cognitive and perceptual efforts. In terms of the dataset, the chart-to-text dataset (Kantharaj et al., 2022) aims to generate a short description of the given chart. This dataset also covers a wide range of topics and chart types. Another relevant NLP task is called data-to-text generation (Gardent et al., 2017; Duk et al., 2020; Koncel-Kedziorski et al., 2019; Cheng et al., 2020). However, the output of all these existing works are descriptions or sum- maries in the form of one or a few sentences or a short paragraph. In the practical setting of data analytics work, one should highlight the analysis and insights in bullet points to make it clearer to the audience. Therefore, in this work, we aim to gen- erate the data analysis in the form of bullet points instead of a short paragraph. | 对于数据分析的第二部分,我们还探索了相关的任务和数据集。自动图表摘要(Mittal等,1998;Ferres等,2013)是一个旨在解释图表并以自然语言形式总结要点的任务。的确,从图表中生成自然语言摘要对于推断关键见解非常有帮助,否则需要大量的认知和感知努力。在数据集方面,图表到文本数据集(Kantharaj et al., 2022)旨在生成给定图表的简短描述。该数据集还涵盖了广泛的主题和图表类型。另一个相关的NLP任务被称为数据到文本生成(Gardent等人,2017;Duk et al., 2020;Koncel-Kedziorski等人,2019;Cheng等人,2020)。然而,所有这些现存作品的输出都是以一句话或几句话或一小段话的形式进行的描述或总结。在数据分析工作的实际设置中,应该突出要点的分析和见解,使观众更清楚。因此,在这项工作中,我们的目标是以要点的形式生成数据分析,而不是一个简短的段落。 |
2.2、Abilities of GPT-3, ChatGPT and GPT-4——GPT-3、ChatGPT和GPT-4的能力
| Researchers have demonstrated the effectiveness of GPT-3 and ChatGPT on several tasks (Ding et al., 2022; Chiang and Lee, 2023; Shen et al., 2023; Luo et al., 2023; Wang et al., 2023; Wu et al., 2023b; Li et al., 2023a; Han et al., 2023; Li et al., 2023b). Ding et al. (2022) evaluated the performance of GPT-3 as a data annotator. Their findings show that GPT-3 performs better on simpler tasks such as text classification than more complex tasks such as named entity recognition (NER). Wang et al. (2023) treated ChatGPT as an evaluator, used ChatGPT to evaluate the performance of natural language generation (NLG) and study its correlations with human evaluation. They found that the ChatGPT evaluator has a high correlation with humans in most cases, especially for creative NLG tasks. | 研究人员已经证明了GPT-3和ChatGPT在几个任务上的有效性(Ding等,2022;Chiang和Lee,2023;Shen等,2023;Luo等,2023;Wang等,2023;Wu等,2023b;Li等,2023a;Han等,2023;Li等,2023b)。Ding等(2022)评估了GPT-3作为数据标注员的性能。他们的研究结果显示,GPT-3在简单的任务(如文本分类)上的表现优于更复杂的任务(如命名实体识别)。Wang等(2023)将ChatGPT作为评估器,使用ChatGPT评估自然语言生成的性能,并研究其与人类评估的相关性。他们发现,在大多数情况下,ChatGPT评估器与人类的评估具有很高的相关性,特别是在创造性的自然语言生成任务中。 |
| GPT-4 is proven to be a significant upgrade over the existing models, as it is able to achieve more advanced natural language processing capabilities (OpenAI, 2023). For instance, GPT-4 is capable of generating more diverse, coherent, and natural language outputs. It is also speculated that GPT-4 may be more capable for providing answers to com- plex and detailed questions and performing tasks requiring deeper reasoning and inference. These advantages will have practical implications in var- ious industries, such as customer service, finance, healthcare, and education, where AI-powered lan- guage processing can enhance communication and problem-solving. In this work, we regard GPT-4 as a data analyst to conduct our experiments. | GPT-4被证明是现有模型的一次重大升级,因为它能够实现更先进的自然语言处理能力(OpenAI,2023)。例如,GPT-4能够生成更多样化、连贯和自然的语言输出。据推测,GPT-4可能更适合回答复杂和详细的问题,并执行需要更深入推理和推断的任务。这些优势将在各个行业中产生实际影响,如客户服务、金融、医疗保健和教育,其中基于人工智能的语言处理可以增强沟通和问题解决能力。在这项工作中,我们将GPT-4视为一个数据分析师来进行实验。 |
3、Task Description任务描述
3.1、Background: Data Analyst Job Scope——背景:数据分析师工作范围
| The main job scope of a data analyst involves uti- lizing business data to identify meaningful patterns and trends from the data and provide stakeholders with valuable insights for making strategic deci- sions. To achieve their goal, they must possess a variety of skills, including SQL query writing, data cleaning and transformation, visualization genera- tion, and data analysis. To this end, the major job scope of a data analyst can be split into three steps based on the three main skills mentioned above: data collection, data visual- ization and data analysis. The initial step involves comprehending business requirement and deciding which data sources are pertinent to answering it. Once the relevant data tables have been identified, the analyst can extract the required data via SQL queries or other extraction tools. The second step is to create visual aids, such as graphs and charts, that effectively convey insights. Finally, in data analysis stage, the analyst may need to ascertain correlations between different data points, identify anomalies and outliers, and track trends over time. The insights derived from this process can then be communicated to stakeholders through written reports or presentations. | 数据分析师的主要工作范围包括利用业务数据识别有意义的模式和趋势,并为利益相关者提供有价值的洞察,以支持战略决策。为了实现这一目标,他们必须具备多种技能,包括SQL查询编写、数据清洗和转换、可视化生成和数据分析。 基于上述提到的三个主要技能,数据分析师的主要工作范围可以分为三个步骤:数据收集、数据可视化和数据分析。初始步骤涉及理解业务需求并决定哪些数据来源与解答问题相关。一旦确定了相关的数据表,分析师可以通过SQL查询或其他提取工具提取所需数据。第二步是创建图表和图形等可视化工具,有效传达洞察。最后,在数据分析阶段,分析师可能需要确定不同数据点之间的相关性,识别异常值和离群值,并追踪随时间变化的趋势。从这个过程中得出的洞察可以通过书面报告或演示文稿传达给利益相关者。 |
3.2、Our Task Setting我们的任务设置
| Following the main job scope of a data analyst, we describe our task setting below. Formally, as illus- trated in Figure 1, given a business-related question (q) and one or more relevant database tables (d) and their schema (s), we aim to extract the required data (D), generate a graph (G) for visualization and provide some analysis and insights (A). More specifically, according to the given ques- tion, one has to identify the relevant tables and schemes in the databases that contain the necessary data for the chart, and then extract the data from the databases and organize it in a way that is suit- able for chart generation. One example question can be: “Show me about the correlation between Height and Weight in a scatter chart”. As it can be seen, the question also includes the chart type information, thus one also has to choose an appro- priate chart type based on the nature of the data and the question being asked, and to generate the chart using a suitable software or programming language. Lastly, it is required to analyze the data to identify trends, patterns, and insights that can help answer the initial question. | 根据数据分析师的主要工作范围,我们以下面的任务设置来描述我们的任务。形式上,如图1所示,给定一个与业务相关的问题(q)、一个或多个相关的数据库表(d)及其模式(s),我们的目标是提取所需数据(D)、生成可视化的图表(G)并提供一些分析和洞察(A)。 更具体地说,根据给定的问题,我们需要确定包含所需数据的相关表和模式,并从数据库中提取数据,并以适合生成图表的方式组织数据。一个示例问题可以是:“在散点图中显示身高和体重之间的相关性”。可以看到,问题中还包括图表类型的信息,因此我们还需要根据数据的性质和所提出的问题选择适当的图表类型,并使用合适的软件或编程语言生成图表。最后,需要分析数据以确定能够帮助回答初始问题的趋势、模式和洞察。 |
4、Our Framework我们的框架
| To tackle the above task setting, we design an end- to-end framework. With GPT-4’s abilities on con- text understanding, code generation, data story- telling being demonstrated, we aim to use GPT-4 to automate the whole data analytics process, follow- ing the steps shown in Figure 1. Basically, there are three steps involved: (1) code generation (shown in blue arrows), (2) code execution (shown in or- ange arrows), and (3) analysis generation (shown in green arrows). The algorithm of our framework is shown in Algorithm 1. | 为了解决上述任务设置,我们设计了一个端到端的框架。利用GPT-4在上下文理解、代码生成和数据叙事方面的能力,我们旨在使用GPT-4自动化整个数据分析过程,按照图1中显示的步骤进行。基本上,涉及三个步骤:(1)代码生成(蓝色箭头)、(2)代码执行(橙色箭头)和(3)分析生成(绿色箭头)。我们的框架的算法如算法1所示。 |
4.1、Step 1: Code Generation——第一步:代码生成 第一步的输入
| The input of the first step contains a question and database schema. The goal here is to generate the code for extracting data and drawing the chart in later steps. We utilize GPT-4 to understand the questions and the relations among multiple database tables from the schema. Note that only the schema of the database tables is provided here due to the data security reasons. The massive raw data is still kept safe offline, which will be used in the later step. The designed prompt for this step is shown in Table 1. By following the instructions, we can get a piece of python code containing SQL queries. An example code snippet generated by GPT-4 is shown in Appendix A. | 包括一个问题和数据库模式。这里的目标是生成提取数据和绘制图表的代码,为后续步骤提供支持。我们利用GPT-4理解问题和模式中多个数据库表之间的关系。注意,由于数据安全原因,这里只提供数据库表的模式。原始的大量数据仍然安全地离线保存,在后续步骤中将使用。这一步的设计提示示例在表1中显示。按照提示操作,我们可以得到包含SQL查询的Python代码片段。GPT-4生成的示例代码片段在附录A中显示。 |

4.2、Step 2: Code Execution第二步:代码执行
| As mentioned earlier in the previous step, to main- tain the data safety, we execute the code generated by GPT-4 offline. The input in this step is the code generated from Step 1 and the raw data from the database, as shown in Figure 1. By locating the data directory using “conn = sqlite3.connect([database file name])” as shown in Table 1 in the code, the massive raw data is involved in this step. By ex- ecuting the python code, we are able to get the chart in “figure.pdf” and the extracted data saved in “data.txt”. | 如前一步骤中提到的,为了保持数据安全性,我们离线执行由GPT-4生成的代码。这一步的输入是从第一步生成的代码和数据库中的原始数据,如图1所示。通过在代码中使用“conn = sqlite3.connect([数据库文件名])”来定位数据目录,本步骤涉及大量的原始数据。通过执行Python代码,我们能够获得“figure.pdf”中的图表,并将提取的数据保存在“data.txt”中。 |
4.3、Step 3: Analysis Generation第三步:分析生成
| After we obtain the extracted data, we aim to generate the data analysis and insights. To make sure the data analysis is aligned with the original query, we use both the question and the extracted data as the input. Our designed prompt for GPT-4 of this step is shown in Table 2. Instead of generat- ing a paragraph of description about the extracted data, we instruct GPT-4 to generate the analysis and insights in 5 bullet points to emphasize the key takeaways. Note that we have considered the al- ternative of using the generated chart as input as well, as the GPT-4 technical report (OpenAI, 2023) mentioned it could take images as input. However, this feature is still not open to public yet. Since the extracted data essentially contains at least the same amount of information as the generated figure, we only use the extracted data here as input for now. From our preliminary experiments, GPT-4 is able to understand the trend and the correlation from the data itself without seeing the figures. | 在获得提取的数据后,我们的目标是生成数据分析和洞察。为了确保数据分析与原始查询一致,我们将问题和提取的数据作为输入。我们为这一步的GPT-4设计的提示如表2所示。我们指示GPT-4生成5个要点的分析和洞察,以强调关键要点,而不是生成关于提取数据的段落描述。注意,我们也考虑了使用生成的图表作为输入的替代方案,因为GPT-4技术报告(OpenAI,2023)提到它可以接受图像作为输入。然而,这个功能目前仍未向公众开放。由于提取的数据本质上包含至少与生成的图表相同数量的信息,我们目前只使用提取的数据作为输入。根据我们的初步实验,GPT-4能够理解数据本身中的趋势和相关性,而无需查看图表。 |
| In order to make our framework more practical such that it can potentially help human data an- alysts boost their daily performance, we add an option of utilizing external knowledge source, as shown in Algorithm 1. Since the actual data analyst role usually requires relevant business background knowledge, we design an external knowledge re- trieval model g(·) to query real-time online infor- mation (I) from external knowledge source (e.g. Google). In such an option, GPT-4 takes both the data (D) and online information (I) as input to gen- erate the analysis (A). | 为了使我们的框架更实用,潜在地帮助数据分析师提高日常工作效率,我们添加了利用外部知识源的选项,如算法1所示。由于实际的数据分析师角色通常需要相关的业务背景知识,我们设计了一个外部知识检索模型g(·)来查询来自外部知识源(如Google)的实时在线信息(I)。在这种选项中,GPT-4将数据(D)和在线信息(I)作为输入生成分析(A)。 |
5、Experiments实验
5.1、Dataset数据集
| Since there is no exactly matched dataset, we choose the most relevant one, named the NvBench dataset. We randomly choose 100 questions from different domains with different chart types and different difficulty levels to conduct our main ex- periments. The chart types cover the bar chart, the stacked bar chart, the line chart, the scatter chart, the grouping scatter chart and the pie chart. The dif- ficulty levels include: easy, medium, hard and extra hard. The domains include: sports, artists, trans- portation, apartment rentals, colleges, etc. On top of the existing NvBench dataset, we additionally use our framework to write insights drawn from data in 5 bullet points for each instance and evalu- ate the quality using our self-designed evaluation metrics. | 由于没有完全匹配的数据集,我们选择最相关的数据集,称为NvBench数据集。我们随机选择了来自不同领域、具有不同图表类型和不同难度级别的100个问题来进行主要实验。图表类型包括柱状图、堆叠柱状图、折线图、散点图、分组散点图和饼图。难度级别包括:简单、中等、困难和极难。领域包括:体育、艺术家、交通运输、公寓出租、大学等。除了现有的NvBench数据集外,我们还使用我们的框架为每个实例撰写从数据中得出的5个要点的洞察,并使用我们自己设计的评估指标评估质量。 |
5.2、Evaluation评估
| To comprehensively investigate the performance, we carefully design several human evaluation met- rics to evaluate the generated figures and analysis separately for each test instance. | 为了全面调查性能,我们精心设计了几个人工评估指标,分别评估生成的图表和分析。 |
| Figure Evaluation We define 3 evaluation met- rics for figures: information correctness: is the data and infor- mation shown in the figure correct? chart type correctness: does the chart type match the requirement in the question? aesthetics: is the figure aesthetic and clear with- out any format errors? The information correctness and chart type correct- ness are calculated from 0 to 1, while the aesthetics is on a scale of 0 to 3. | 图表评估:我们为图表定义了3个评估指标: 信息正确性:图表中显示的数据和信息是否正确? 图表类型正确性:图表类型是否与问题要求匹配? 美观度:图表是否美观清晰,没有任何格式错误? 信息正确性和图表类型正确性的计分范围是0到1,而美观度的计分范围是0到3。 |
| Analysis Evaluation For each bullet point gener- ated in the analysis and insight, we define 4 evalua- tion metrics as below: correctness: does the analysis contain wrong data or information? alignment: does the analysis align with the question? complexity: how complex and in-depth is the analysis? fluency: is the generated analysis fluent, gram- matically sound and without unnecessary repe- titions? | 分析评估:对于生成的每个分析和洞察要点,我们定义了4个评估指标如下: 正确性:分析中是否包含错误的数据或信息? 对齐度:分析是否与问题一致? 复杂度:分析的复杂程度和深度如何? 流畅度:生成的分析是否流畅,语法正确,没有不必要的重复? |
| We grade the correctness and alignment on a scale of 0 to 1, and grade complexity and fluency in a range between 0 to 3. To conduct human evaluation, 6 professional data annotators are hired from a data annotation company to annotate each figure and analysis bul- let point following the evaluation metrics detailed above. The annotators are fully compensated for their work. Each data point is independently la- beled by two different annotators. | 我们将正确性和对齐度评分范围设置为0到1,将复杂度和流畅度评分范围设置为0到3。 为了进行人工评估,我们从数据注释公司聘请了6名专业数据注释员,按照上述评估指标对每个图表和分析要点进行注释。我们对他们的工作进行了全额补偿。每个数据点由两名不同的注释员独立标注。 |
5.3、Main Results主要结果 GPT-4性能
| GPT-4 Performance Table 3 shows the perfor- mance of GPT-4 as an data analyst on 200 samples. We show the results of each individual evaluator group and the average scores between these two groups. For chart type correctness evaluation, both evaluator groups give almost full scores. This in- dicates that for such a simple and clear instruction such as “draw a bar chart”, “show a pie chart”, etc., GPT-4 can easily understand its meaning and has background knowledge about what the chart type means, so that it can plot the chart in the correct type accordingly. In terms of aesthetics score, it can get 2.73 out of 3 on average, which shows most of the figures generated are clear to audience without any format errors. However, for the information correctness of the plotted charts, the scores are not so satisfied. We manually check those charts and find most of them can roughly get the correct figures despite some small errors. Our evaluation criteria is very strict that as long as any data or any label of x-axis or y-axis is wrong, the score has to be deducted. Nevertheless, it has room for further improvement. | 表3显示了GPT-4作为数据分析师在200个样本上的性能。我们展示了每个评估者组的结果以及这两个组之间的平均分数。对于图表类型正确性评估,两个评估者组都给出了几乎满分的分数。这表明对于诸如“绘制条形图”、“显示饼图”等简单明确的指令,GPT-4能够轻松理解其含义,并具有有关图表类型的背景知识,以便能够按正确的类型绘制图表。就美观度得分而言,平均可达到2.73(满分为3),这表明大多数生成的图表对观众来说清晰无误,没有任何格式错误。然而,对于绘制图表的信息正确性,得分并不如人意。我们手动检查了这些图表,并发现尽管存在一些小错误,但大多数图表基本上能够获得正确的结果。我们的评估标准非常严格,只要任何数据或x轴或y轴的标签有错误,就会扣分。然而,还有改进的空间。 |
| For analysis evaluation, both alignment and flu- ency get full marks on average. It again verifies generating fluent and grammatically correct sen- tences is definitely not a problem for GPT-4. We notice the average correctness score for analysis is much higher than the information correctness score for figures. This is interesting because despite the wrong figure generated, the analysis could be cor- rect. It again verifies our explanation earlier for the information correctness scores of figures. As mentioned, since the figures generated are mostly consistent with the gold figures, thus some of the bullet points can be generated correctly. Only a few bullet points related to the error parts from the figures are considered wrong. In terms of the complexity scores, 2.16 out of 3 on average is rea- sonable and satisfying. | 对于分析评估,平均对齐度和流畅度得满分。这再次验证了GPT-4生成流畅和语法正确的句子绝对不是问题。我们注意到分析的正确性得分平均比图表的信息正确性得分要高得多。这是有趣的,因为尽管生成的图表是错误的,但分析可能是正确的。这再次验证了我们对图表信息正确性得分的先前解释。正如前面提到的,由于生成的图表与真实图表大多保持一致,因此某些要点可以正确生成。只有与图表中错误部分相关的少数要点被认为是错误的。在复杂度评分方面,平均得分2.16(满分为3)是合理且令人满意的。 |
| Comparison between Human Data Analysts and GPT-4 To further answer our research question, we hire professional data analysts to do these tasks and compare with GPT-4 comprehensively. We fully compensate them for their annotation. Table 4 shows the performance of several data analysts of different expert levels from different backgrounds compared to GPT-4. Overall speaking, GPT-4’s performance is comparable to human data analysts, while the superiority varies among different metrics and human data analysts. | 人类数据分析师与GPT-4的比较:为了进一步回答我们的研究问题,我们聘请了专业的数据分析师进行这些任务,并与GPT-4进行全面比较。我们对他们的注释工作进行了全额补偿。表4显示了不同专业水平和背景的几位数据分析师与GPT-4的性能比较。总的来说,GPT-4的性能与人类数据分析师相当,但在不同的评估指标和人类数据分析师之间存在差异。 |
| The first block shows 10-sample performance of a senior data analyst (i.e., Senior Data Analyst 1) who has more than 6 years’ data analysis working experience in finance industry. We can see from the table that GPT-4 performance is comparable to the expert data analyst on most of the metrics. Though the correctness score of GPT-4 is lower than the human data analyst, the complexity score and the alignment score are higher. The second block shows another 8-sample per-formance comparison between GPT-4 and another senior data analyst (i.e., Senior Data Analyst 2) who works in internet industry as a data analyst for over 5 years. Since the sample size is relatively smaller, the results shows larger variance between human and AI data analysts. The human data an-alyst surpasses GPT-4 on information correctness and aesthetics of figures, correctness and complex-ity of insights, indicating that GPT-4 still still has potential for improvement. The third block compares another random 9-sample performance between GPT-4 and a junior data analyst who has data analysis working expe-rience in a consulting firm within 2 years. GPT-4 not only performs better on the correctness of fig-ures and analysis, but also tends to generate more complex analysis than the human data analyst. | 第一个区块显示了一位高级数据分析师(即高级数据分析师1)在10个样本上的表现,他在金融行业拥有超过6年的数据分析工作经验。从表中可以看出,GPT-4在大多数指标上的表现与专业数据分析师相当。尽管GPT-4的正确性得分低于人类数据分析师,但复杂度得分和对齐度得分较高。 第二个区块是GPT-4与另一位资深数据分析师(即高级数据分析师2)在另外8个样本上的表现比较,他在互联网行业担任数据分析师已经超过5年。由于样本量相对较小,人工和人工智能数据分析师之间的结果差异较大。人工数据分析师在图表的信息正确性和美观度以及洞察的正确性和复杂性方面超过了GPT-4,这表明GPT-4仍有改进的潜力。 第三个区块比较了GPT-4与一位在咨询公司工作的初级数据分析师的性能。尽管该初级数据分析师缺乏多年的经验,但与GPT-4相比,他在几乎所有评估指标上都表现得更好。这进一步表明,GPT-4的性能可能受到领域专业知识和经验的影响。 |
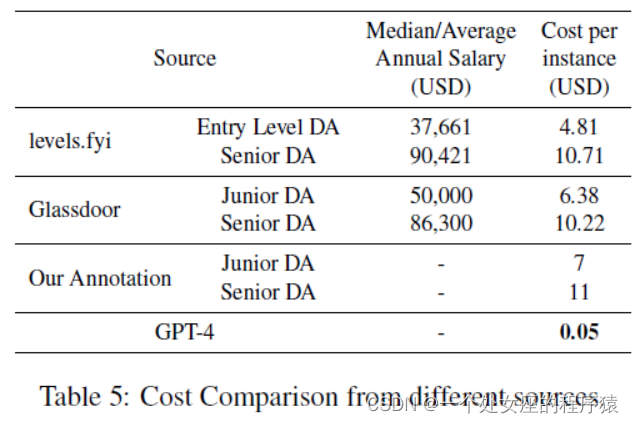
| Apart from the comparable performance be-tween all data analysts and GPT-4, we can notice the time spent by GPT-4 is much shorter than hu-man data analysts. Table 5 shows the cost compari-son from different sources. We obtain the median annual salary of data analysts in Singapore from level.fyi and the average annual salary of data an-alysts in Singapore from Glassdoor. We assume there are around 21 working days per month and the daily working hour is around 8 hours, and cal-culate the cost per instance in USD based on the average time spent by data analysts from each level. For our annotation, we pay the data analysts based on the market rate accordingly. The cost of GPT- 4 is approximately 0.71% of the cost of a junior data analyst and 0.45% of the cost of a senior data analyst. | 除了所有数据分析师与GPT-4之间的可比性之外,我们可以注意到GPT-4花费的时间比人类数据分析师要短得多。表5显示了不同来源的成本比较。我们从水平得到新加坡数据分析师的年薪中位数。还有来自Glassdoor的新加坡数据分析师的平均年薪。我们假设每个月约有21个工作日,每天工作时间约为8小时,并根据每个级别的数据分析师平均花费的时间来计算每个实例的成本,以美元为单位。对于我们的注释,我们根据相应的市场汇率向数据分析师支付报酬。GPT- 4的成本约为初级数据分析师成本的0.71%,高级数据分析师成本的0.45%。 |
6、Case Study案例研究
| In this section, we show a few cases done by GPT-4 and our data analysts. In this section, we show a few cases done by GPT-4 and our data analysts. In the first case as shown in Table 6, GPT-4 is able to generate a python code containing the correct SQL query to extract the required data, and to draw a proper and correct pie chart according to the given question. In terms of the analysis, GPT-4 is capable of understanding the data by conducting proper comparisons (e.g., “most successful”, “less successful”, “diverse range”). In addition, GPT-4 can provide some insights from the data, such as: “indicating their dominance in the competition”. These aforementioned abilities of GPT-4 including context understanding, code generation and data storytelling are also demonstrated in many other cases. Furthermore, in this case, GPT-4 can also make some reasonable guess from the data and its background knowledge, such as: “potentially due to their design, performance, or other factors”. The second case (Table 7) shows another ques- tion addressed by GPT-4. Again, GPT-4 is able to extract the correct data, draw the correct scatter plot and generate reasonable analysis. Although most of the bullet points are generated faithfully, if we read and check carefully, we can notice the numbers of the average height and weight are wrong. Apart from the well-known hallucination issue, we sus- pect that GPT-4’s calculation ability is not strong, especially for those complex calculation. We also notice this issue in several other cases. Although GPT-4 generates the analysis bullet point in a very confident tone, but the calculation is sometimes inaccurate. | 本节中,我们展示了由GPT-4和我们的数据分析师完成的几个案例。 第一个案例如表6所示,GPT-4能够生成包含正确的SQL查询以提取所需数据的Python代码,并根据给定的问题绘制适当和正确的饼图。在分析方面,GPT-4能够通过进行适当的比较(例如,“最成功的”,“不太成功的”,“多样化的范围”)来理解数据。此外,GPT-4还可以从数据中提供一些洞察,例如:“表明他们在竞争中的主导地位”。GPT-4的这些能力,包括上下文理解、代码生成和数据叙述,在许多其他案例中也得到了展示。此外,在这个案例中,GPT-4还可以从数据和其背景知识中做出一些合理的猜测,例如:“可能是由于设计、性能或其他因素”。 第二个案例(表7)展示了GPT-4处理的另一个问题。同样,GPT-4能够提取正确的数据,绘制正确的散点图,并生成合理的分析。虽然大多数要点都被忠实地生成,但如果我们仔细阅读和核对,我们会注意到平均身高和体重的数字是错误的。除了众所周知的幻觉问题外,我们怀疑GPT-4的计算能力不强,尤其是对于那些复杂的计算。我们在其他几个案例中也注意到了这个问题。虽然GPT-4以非常自信的语气生成了分析要点,但计算有时是不准确的。 |
| Table 8 shows an example done by Senior Ana- lyst 2. We can notice that this expert human data analyst can also understand the requirement, write the code to draw the correct bar chart, and ana- lyze the extracted data in bullet points. Apart from this, we can summarize three main differences with GPT-4. First, different from GPT-4, the human data analyst can express the analysis with some personal thoughts and emotions. For example, the data analyst mentions “This is a bit surprising ...”. In real-life business, personal emotions are impor- tant sometimes. With the emotional phrases, the audience can easily understand whether the data is as expected or abnormal. Second, the human data analyst tends to apply some background knowledge. While GPT-4 usually only focuses on the extracted data itself, the human is easily linked with one’s background knowledge. For example, as shown in Table 8, the data analyst mentions “... is commonly seen ...”, which is more natural during a data an-alyst’s actual job. Therefore, to mimic a human data analyst better, in our demo, we add an option of using Google search API to extract real-time online information when generating data analysis. Third, when providing insights or suggestions, a human data analyst tends to be conservative. For instance, in the 5th bullet point, the human data analyst mentions “If there’s no data issue” before giving a suggestion. Unlike humans, GPT-4 will directly provide the suggestion in a confident tone without mentioning its assumptions. | 表8显示了高级数据分析师2完成的一个示例。我们可以注意到这位专家级人类数据分析师也能够理解要求,编写绘制正确条形图的代码,并以要点分析提取的数据。除此之外,我们可以总结出与GPT-4的三个主要差异。首先,与GPT-4不同,人类数据分析师可以用一些个人的思考和情感表达分析。例如,数据分析师提到“这有点令人惊讶...”。在实际的商业环境中,个人情感有时很重要。通过情感词语,听众可以轻松地了解数据是否符合预期或异常。其次,人类数据分析师倾向于应用一些背景知识。而GPT-4通常只关注提取的数据本身,人类则容易与自己的背景知识联系起来。例如,如表8所示,数据分析师提到“...常见...”,这在数据分析师的实际工作中更加自然。因此,为了更好地模仿人类数据分析师,我们在我们的演示中添加了使用Google搜索API提取实时在线信息的选项。第三,在提供洞察或建议时,人类数据分析师倾向于保守。例如,在第5个要点中,人类数据分析师在给出建议之前提到“如果没有数据问题”。与人类不同,GPT-4会直接以自信的语气提供建议,而不提及其假设。 |
7、Findings and Discussions研究结果与讨论
| During our experiments, we notice several phe-nomena and conduct some thinking about them. In this section, we discuss our findings and hope researchers can address some of the issues in future work. Generally speaking, GPT-4 can perform com-parable to a data analyst from our preliminary ex-periments, while there are still several issues to be addressed before we can reach a conclusion that GPT-4 is a good data analyst. First, as illustrated in the case study section, GPT-4 still has hallucination problems, which is also mentioned in GPT-4 tech-nical report (OpenAI, 2023). Data analysis jobs not only require those technical skills and analytics skills, but also requires high accuracy to be guaran-teed. Therefore, a professional data analyst always tries to avoid those mistakes including calculation mistakes and any type of hallucination problems. Second, before providing insightful suggestions, a professional data analyst is usually confident about all the assumptions. Instead of directly giving any suggestion or making any guess from the data, GPT- 4 should be careful about all the assumptions and make the claims rigorous. | 在我们的实验过程中,我们注意到了一些现象,并对它们进行了一些思考。在本节中,我们讨论了我们的研究结果,并希望研究人员能够在未来的工作中解决其中的一些问题。 总的来说,根据我们的初步实验,GPT-4在数据分析方面的表现与数据分析师相当,但在我们能得出GPT-4是一个好的数据分析师之前,仍然有一些问题需要解决。首先,正如案例研究部分所示,GPT-4仍然存在幻觉问题,这也在GPT-4技术报告中提到了(OpenAI,2023)。数据分析工作不仅需要技术和分析技能,还需要高精度的保证。因此,专业的数据分析师始终试图避免那些错误,包括计算错误和任何类型的幻觉问题。其次,在提供深入的建议之前,专业的数据分析师通常对所有假设都有信心。与直接从数据中给出建议或猜测不同,GPT-4应该对所有假设保持谨慎,并使其主张严谨。 |
| The questions we choose are randomly selected from the NvBench dataset. Although the questions indeed cover a lot of domains, databases, difficulty levels and chart types, they are still somewhat too specific according to human data analysts’ feed-back. The questions usually contain the informa-tion such as: a specific correlation between two variables, a specific chart type. In a more practical setting, the original requirements are more general, which require a data analyst to formulate such a specific question from the general business require-ment, and to determine what kind of chart would represent the data better. Our next step is to collect more practical and general questions to further test the problem formulation ability of GPT-4. | 我们选择的问题是从NvBench数据集中随机选择的。尽管这些问题确实涵盖了许多领域、数据库、难度级别和图表类型,但根据人类数据分析师的反馈,它们仍然有些过于具体。这些问题通常包含诸如两个变量之间的具体关联、特定的图表类型等信息。在更实际的设置中,原始需求更加通用,需要数据分析师从一般的业务需求中提出这样一个具体的问题,并确定哪种类型的图表能更好地表示数据。我们的下一步是收集更多实际和通用的问题,以进一步测试GPT-4的问题表达能力。 |
| The quantity of human evaluation and data an-alyst annotation is relatively small due to budget limit. For human evaluation, we strictly select those professional evaluators in order to give better rat-ings. They have to pass our test annotations for several rounds before starting the human evalua-tion. For the selection of data analysts, we are even more strict. We verify if they really had data analy-sis working experience, and make sure they master those technical skills before starting the data anno-tation. However, since hiring a human data analyst (especially for those senior and expert human data analyst) is very expensive, we can only ask them to do a few samples. | 由于预算限制,我们的人类评估和数据分析师注释的数量相对较小。对于人类评估,我们严格选择那些专业的评估人员,以便给出更好的评分。在进行人类评估之前,他们必须通过我们的测试注释进行数轮测试。对于数据分析师的选择,我们更加严格。我们验证他们是否真的有数据分析工作经验,并确保他们在开始数据注释之前掌握了这些技术技能。然而,由于雇佣一个人类数据分析师(尤其是那些高级和专家级的人类数据分析师)非常昂贵,我们只能要求他们做一些样本。 |
8、Conclusions结论
| The potential for large language models (LLMs) like GPT-4 to replace human data analysts has sparked a controversial discussion. However, there is no definitive conclusion on this topic yet. This study aims to answer the research question of whether GPT-4 can perform as a good data ana-lyst by conducting several preliminary experiments. We design a framework to prompt GPT-4 to per-form end-to-end data analysis with databases from various domains and compared its performance with several professional human data analysts us-ing carefully-designed task-specific evaluation met-rics. The results and analysis show that GPT-4 can achieve comparable performance to humans, but further studies are needed before concluding that GPT-4 can replace data analysts. | 大型语言模型(LLM)如GPT-4是否能够取代人类数据分析师引发了一场有争议的讨论。然而,关于这个问题还没有确定性的结论。本研究旨在通过进行几项初步实验回答GPT-4是否能够表现为一个优秀的数据分析师的研究问题。我们设计了一个框架,促使GPT-4执行包括来自不同领域的数据库的端到端数据分析,并使用精心设计的任务特定评估指标与几位专业的人类数据分析师的表现进行比较。结果和分析表明,GPT-4能够达到与人类相当的性能,但在得出GPT-4能够取代数据分析师的结论之前,还需要进一步的研究。 |
Acknowledgements致谢
| We would like to thank our data annotators and data evaluators for their hard work. Especially, we would like to thank Mingjie Lyu for the fruitful discussion and feedback. | 我们要感谢我们的数据注释员和数据评估员的辛勤工作。特别感谢Mingjie Lyu进行了富有成果的讨论和反馈。 |

