
大模型内容分享(十一):大模型高效微调(PEFT)方法大全_大模型peft
赞
踩
目录
PEFT分类
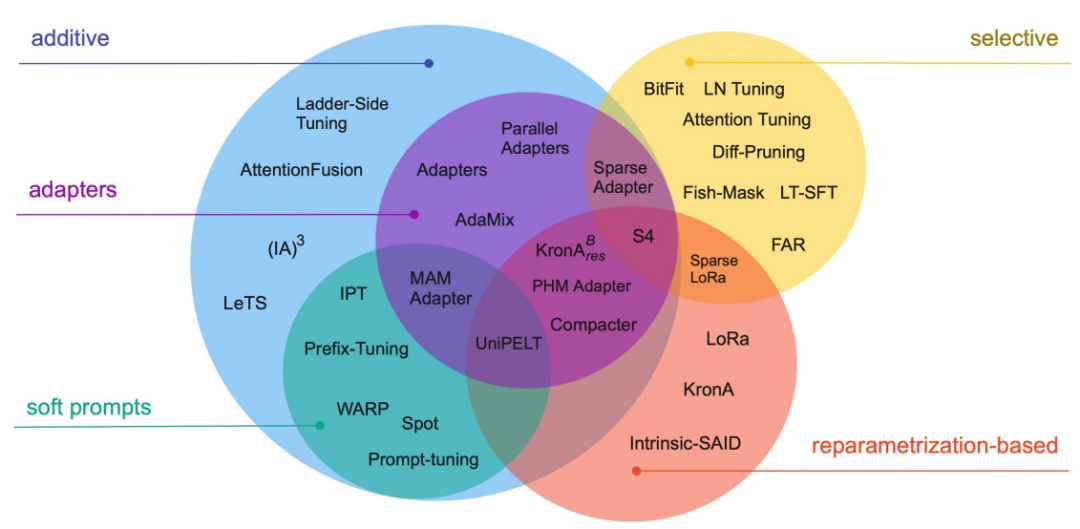
图1. PEFT分类
如上图1,按是否增加了额外参数,PEFT主要分为:
-
Additive类:在预训练模型基础上增加额外的参数或者网络层,微调训练的时候只训练这些新增的参数或层,包含两个子类:
1)Adapter--在Transformer子层后加入小的全连接层,微调只学习新加的全连接层参数。
2)Soft Prompts--常见的Prompts方法是在输入中构造Prompts模板,如何构造是一门学问,Soft Prompts直接在输入的embedding中加向量作为soft prompts,并对这些向量的参数进行微调,避免构造Prompts模板。
-
Selective类:选择模型中的部分层比如最后几层、或偏置项进行微调。
-
Reparametrization-based类:利用低秩表征(low-rank representations)来最小化可训练的参数,本质上就是认为大量的参数中,仅仅一部分起到关键作用,在这个起关键作用的子空间中去寻找参数进行微调。
-
Hybrid类:混合了多种类别的方法。
PEFT方法效率统计
参数效率(Parameter Efficiency,PE)从广泛的概念讲,包括存储、内存、计算和性能的效率,其中计算效率主要包括微调时反向传播的计算和推理的计算效率。下面是对已收集的方法(论文)从这几个维度进行的统计:

表1. 各种方法的效率统计
其中,Type表示该方法属于Additive、Selective、Reparametrization-based哪一类,Storage、Memroy表示该方法和全部参数微调比较是否节约了存储、内存。Backprop表示是否减小了反向传播计算开销,Inference overhead表示推理时是否增加了开销,比如常见的增加了全连接层。
具体方法具体介绍
按Additive、Selective、Reparametrization-based分类介绍,主要方法会介绍细节,其余方法一句话概括。
3.1 Additive类:Adapters
3.1.1 Adapters
论文《Parameter-Efficient Transfer Learning for NLP》,2019年

图2. Adapter结构
结构简洁明了,在Transformer的前馈层后加入上图中右边所示的Adapter层,Adapter是一个bottleneck结构,先把d维特征映射为m维,然后通过一个非线性层,最后映射回d维特征,m<<d,即m远小于d,Adapter包括偏置项的参数量为2md+m+d,由于m很小,起到了限制参数量的作用。模型微调的时候,学习的参数包含上图绿色部分,除了Adapter,还有Transformer本身的Layer Norm层。
Adapters微调训练的参数量、全模型微调参数量和准确率关系如下图。总体上,在BERT Large模型上用0.5-5%的参数微调,基本达到全参数微调性能,差距仅1%以内。在GLUE上,用3.6%的参数微调和全参数微调性能差距仅0.4%。

图3. Adapters微调参数和性能关系
3.1.2 其他方法
AdaMix:使用 mixture-of-experts(MoE)思路,对多个adapters采用模型选择具体的expert adapter。
3.2 Additive类:Soft Prompts
3.2.1 Prefix-Tuning
论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》,2021年
一般的Prompts需要根据任务构造Prompt模板,同一任务不同的Prompts模板可能导致模型性能差别很大,Prefix-Tuning在模型的输入里直接加上前缀向量进行微调,功能类似加Prompts,但加的是向量,让这些向量自行训练,不用人为去构造各种模板。

图4. Prefix-Tuning原理
图4中上面部分是以Transformer结构为例全参数微调的情况,下面部分是Prefix-Tuning的方法,在每层的开头加了Prefix向量,微调只训练这部分对应的参数,其余Transformer固有的参数冻结不变。

图5. Prefix-Tuning添加Prefix的方法
借用稀土掘金社区文章的图5更进一步说明了每层添加Prefix的方法,同一个source经过MLP全连接网络得到Prefix加入每一Transformer block。
用伪代码表示就是:


图6. 自回归和Encoder-Decoder结构的Prefix-Tuning例子
图6 是典型的自回归和Encoder-Decoder结构上进行Prefix-Tuning的方法示例。自回归在开头加上Prefix,输出就是正常的输出,Encoder-Decoder在输入加上Prefix,输出有对应的内容。
微调训练过程中模型原有的损失函数定义不变,不同的任务训练其特有的Prefix,推理时用自己训练得到的Prefix。
作者实验了只在输入的embedding层加入Prefix,性能下降明显。
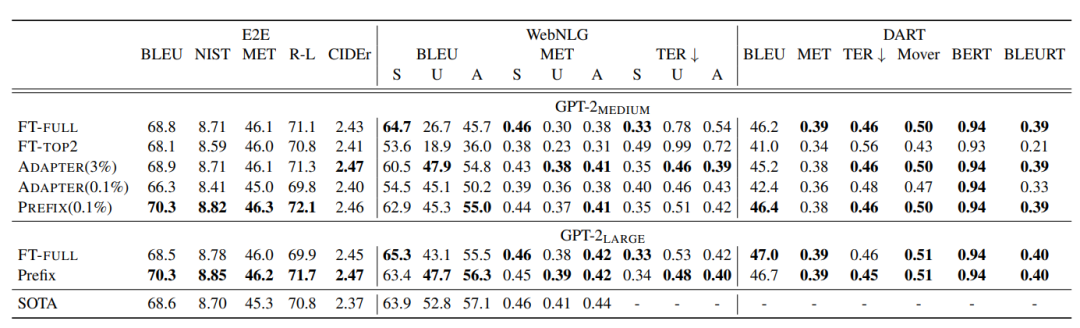
表2. Prefix-Tuning实验结果
表2是Prefix-Tuning在不同任务上微调0.1%参数的效果,和Adapters方法进行比较,同等训练0.1%参数量的情况下,普遍优于Adapters。
总体上,只用微调占模型0.1%的参数,就能得到和全参数微调的媲美的效果。
3.2.2 Prompt Tuning
论文《The Power of Scale for Parameter-Efficient Prompt Tuning》,2021年
一句话概括的话就是上面讲的Prefix-Tuning的简化版,碰巧和Prefix-Tuning同时做的工作,只把soft prompts加到模型的输入,作者研究表明只加到输入层效果就不错了,不必加到中间层。

图7. Prompt Tuning
伪代码如下:

Prompt Tuning是以把各种任务都归纳到text-to-text的T5模型基础上研究的,文章花了很多功夫比较soft prompts的不同初始化方法、不同的prompt长度、不同的预训练方法、不同的LM adaption步数。LM adaption指的是在T5模型上用自监督方法继续训练额外的少量步数。 比较结果如图8。

图8. 不同因素对结果的影响
文章还探索了Prompt Ensembling,Ensembling是机器学习里常用的一个方法,即把多个方法集成在一起,可是使用投票、算平均值等多种方式使用各个方法的结果。即图7所示,同一batch里同时训练多个任务,不同任务当然是用其自身的prompt,但即使是同一个任务,也使用多个prompts。预测的时候用简单的投票方式选prompt,实验表明Ensembling方法好于单个prompt的平均性能,好于或者持平单个prompt的最好性能。
3.2.3 其他方法
Intrinsic Prompt Tuning (IPT):用自编码器压缩和解压soft prompts。
3.3 Selective类
3.3.1 BitFit
论文《BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models》,2022年
BitFit十分简洁明了,在Transformer结构中只微调所有偏置项bias参数。
具体而言,Transformer过程如下,先是Q、K、V的计算:
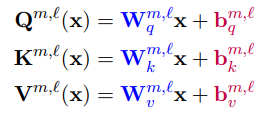
然后根据Q、K、V计算attention:

然后做Layer-Norm:
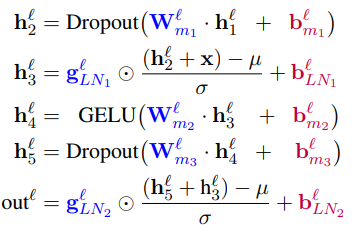
上面的红色部分就是所有的bias项,只选择(Selective)这些bias项参数进行微调。
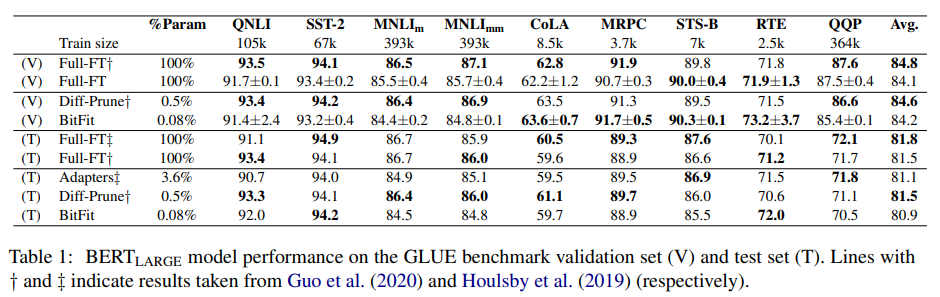
表3. BitFit性能对比
表3显示GLUE上基于BERT Large基座模型,BitFit和全参数训练、Adapters、Diff-Prune(另一个selective方法)性能比较,部分任务上能达到最优。另外,在BERT Base和RoBERT Base上也是同样的趋势。
3.3.2 其他方法
DiffPruning:模型微调的时候学习参数的掩码mask。
3.4 Reparametrization-based类
3.4.1 LoRA
论文《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》,2021年
重点来了,LoRA可能是目前最流行的PEFT方法,受欢迎必须要效果好,而且好懂易用!效果好体现在论文直接在流行的RoBERTa、DeBERTa、GPT-2、GPT-3模型上实验显示微调性能优于或持平全参微调,GPT-3 175B模型参数够大,给大家提前趟水吃个定心丸。后续大家陆续在LLaMA等模型上微调,不仅速度快而且效果好。
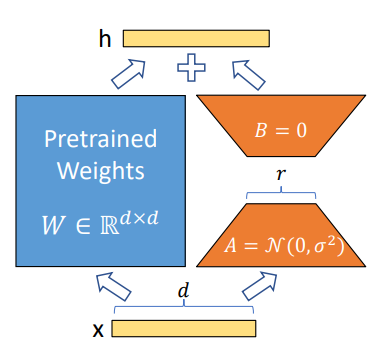
图9. LoRA原理
LoRA的想法很巧妙,如图9,对一个预训练的模型有h=Wx,其中x为输入,W为预训练权重,h为输出。LoRA认为,如果要在特定任务上进行微调,也就是要改变模型的参数权重W,这个改变的部分
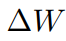
本质上可以压缩到一个很小的子空间,有:

其中,
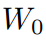
是预训练模型的权重,微调时保持不变,
是微调时要学习的权重,可以分解为两个低维(低秩)的矩阵B和A,维度关系为:
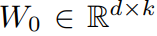
,
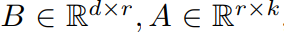
这也是论文为啥叫Low Rank的原因,一般情况下r<<min(d,k)。用深度学习的思路,我们不会真正通过矩阵分解得到矩阵B和A,而是通过数据驱动,用梯度下降反向传播方法计算得到。论文使用随机高斯分布初始化A,B初始化为0,对不同大小的r做了实验对比。
LoRA和之前主要方法比较的优势:
-
和Prefix-Tuning比,由于不用在输入上加额外的prompts,能支持更长的输入;
-
和Adapters比,增加的参数和基座模型计算是并行的,不像Adapters是在网络中加了串行的层,所以推理时没有增加额外的延迟。在生产环境部署时,可以先计算好
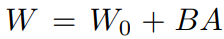
,W的维度没有变化,推理时和原来基座模型计算开始是一样的。对不同的任务,替换对应的

即可,也很方便。
LoRA应用到Transformer时,只尝试了对计算注意力机制和MLP中的权重进行微调。论文对RoBERTa、DeBERTa、GPT-2、GPT-3都做了实验对比,这里我们只列出最大的GPT-3看看:

表4. GPT-3上不同方法微调参数、性能数据对比
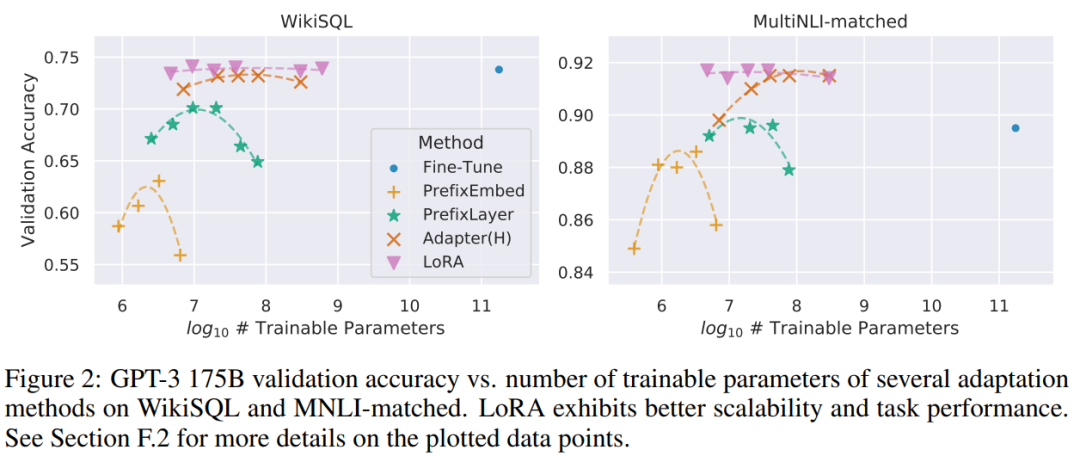
图10. GPT-3上不同方法微调参数、性能可视化对比
一句话总结,就是不仅微调参数小,而且性能还好。
对Transformer不同权重、不同r的情况对比结果如下,说明微调的权重越多越好,但r并不是越大越好。

表5. Transformer上微调不同权重、不同r值的性能比较
最后说一句,LoRA也有劣势,就是不能在同一个batch里训练多个任务的A和B。
3.4.2 其他方法
KronA:和LoRA比,使用Kronecker内积分解矩阵,
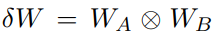
,内积定义如下:
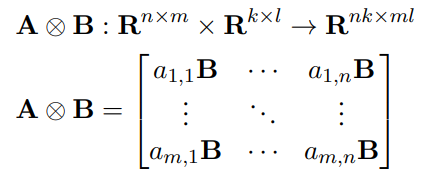
3.5 Hybrid类
只简略说一下主要方法都混合使用了哪些方法。
MAM Adapters:联合了并行的adapters和soft prompts,伪代码如下:

UniPELT:联合了LoRa, Prefix-tuning, and Adapters.
最后
PEFT目前总体就这些了,我还对LoRA最近业界使用的情况、大家总结的经验、通过Huggingface使用PEFT等感兴趣,后续继续学习和实践。

