
- 1java关键字this含义_java的关键字this的意义及作用
- 2华为防火墙SSL VPN隧道连接实验配置_华为防火墙ssl配置
- 3六种方法在云平台和远程桌面中使用Kali_kali gui
- 4如何从0到1搭建一个SpringBoot项目_10分钟从0到1构建一个最基本的spring boot工程项目
- 5Android网络编程常用的三种方法_安卓网络编程
- 6ChatGPT中文LLM与医疗领域相结合的开源资源汇总_tcmllm
- 7Mysql中的information_schema数据库_mysql的information
- 8Rabbit延迟队列实现---插件实现
- 9Yolov5源码详解:数据加载篇(上)_infinitedataloader
- 10如何在群晖Docker运行本地聊天机器人并结合内网穿透发布到公网访问_群晖 docker ai
随着大模型中数据局限问题的严峻化,向量数据库应运而生_好未来发现大模型在面对数学问题时,其表现仍然不够
赞
踩
向量数据库与亚马逊大模型

什么是向量数据库
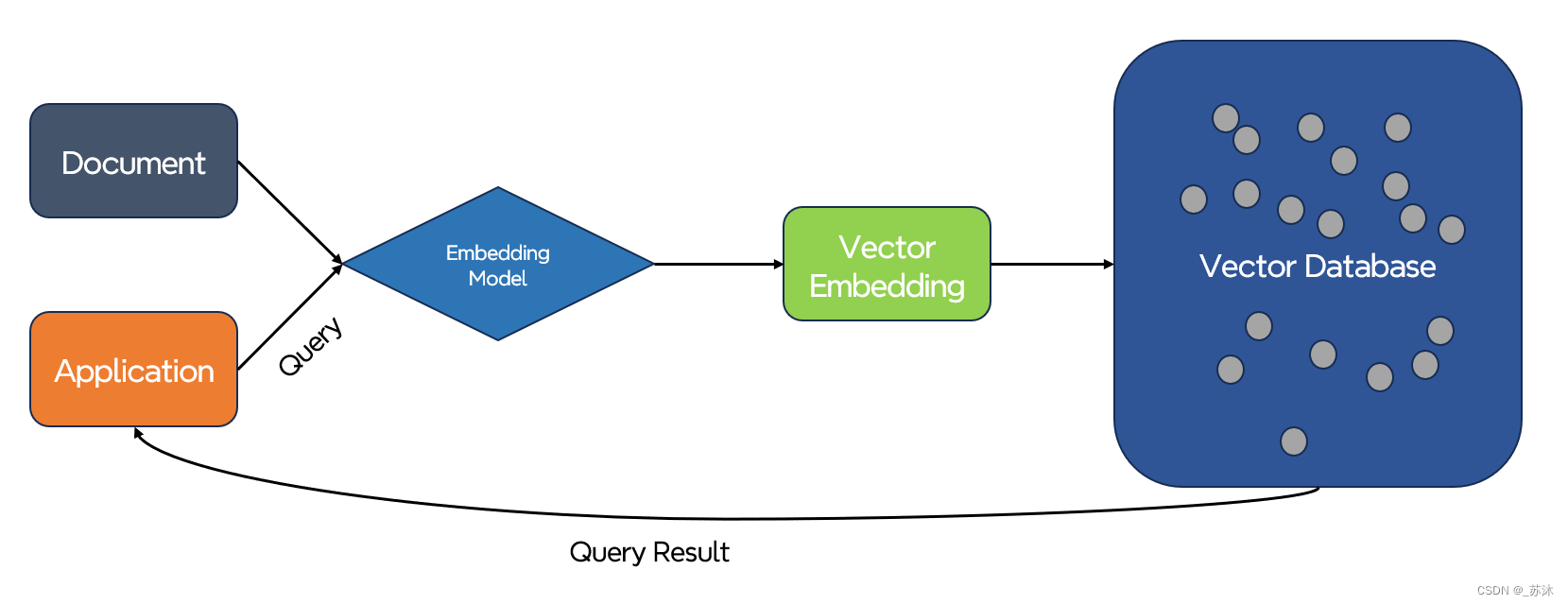
向量嵌入(vector embedding)实际上无处不在。它们构成了众多机器学习和深度学习算法的根基,被广泛运用于搜索引擎、推荐系统和智能助手等各式各样的应用。下图展示的是大模型在推荐系统中的应用。
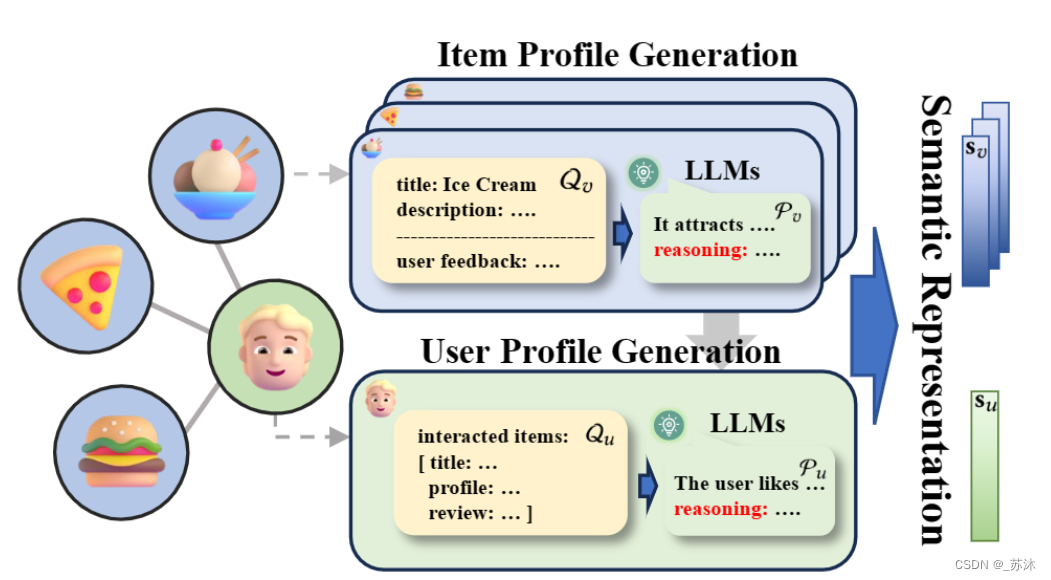
机器学习与深度学习通常会把文本、图像、音频、视频等非结构化数据转化为向量嵌入的形式(如:Embedding)进行储存,并借由向量相似性搜索技术进行语义相关性搜索,如余弦相似度。基于向量的相似性搜索现如今已被大量应用于各类人工智能驱动的应用场景,包括图像检索、视频分析、自然语言理解、推荐系统、定向广告、个性化搜索、智能客服以及欺诈检测等,以推荐系统为例,系统会计算物品向量和用户向量的相似度,将相似度最高的几件物品推荐给用户。在此情景下,对向量数据的管理显得尤为重要,我们需要能够快速地储存、索引和搜索这些向量化的数据。
目前存在的向量数据库大致可分为两类。一类是专门为向量设计的专有向量数据库产品,例如 Pinecone、Weaviate、Qdrant、Chroma、Milvus 等。另一类是在通用的 SQL 或 NoSQL 数据库产品上进行扩展,其中最为人熟知的 SQL 数据库之一 Postgres 通过插件 pgvector 支持了向量索引和搜索;而包括 ClickHouse、Redis、Elasticsearch 和 Cassandra 在内的许多开源数据库最近都增加了对向量索引的原生支持。
越来越多人认为,为了能够提供较佳的搜索性能 专有的向量数据库专门为向量检索设计。支持向量搜索的通用数据库产品则依赖于原有的通用数据库,能够让数据管理和结构化数据查询能力更加完善,这些让向量检索性能有所损失。
大模型面临的“数据”局限
众所周知,在MaaS时代,数据变得异常重要,市场的火热程度在企业层面体现为大量垂直模型的推出、数据库企业融资数量的增加以及数据库使用量的急剧上升。然而,在企业实际应用中,大模型仍然面临一系列未解决的难题。通过观察,我们可以将数据局限对企业构建大模型产生的影响总结为以下三点:
首先是数据的管理和运维。随着对文本、图片、视频等多模态非结构化数据的需求增加,许多企业产生的非结构化数据量高达80%。如果选择采用预训练的方式将数据传递给模型,将会带来难以承受的高成本。一些创业公司,在模型训练和调试中遇到了与此类似的问题。在未使用向量数据库之前,公司一直采用开源方案,如以向量索引为核心。这相当于在训练时为模型准备了一个库级别或算法级别的知识库,这种方法使用简单,采用分布式系统,但随着规模的增长,分布式存储方式迅速遇到瓶颈。此外,由于缺乏成熟的管理工具,百川智能不得不将数据格式组织、数据更新频率安排、新旧数据更迭等问题额外交给工程师处理,大大增加了人员成本。
其次,尽管大模型支持的标记数量不断增加,具备了"短暂记忆"的能力,但依然无法解决"一本正经地胡说八道"的问题。这可能导致敏感内容的出现,稍有不慎就可能带来严重的影响。因此,支持模型训练的数据不仅需要数量多,质量也必须足够高。例如,在大模型与教育行业结合的情况下,虽然模型可以完成一定的推理和解题,但在实际应用中,好未来发现大模型在面对数学问题时表现仍不够出色。要解决这个问题,必须基于庞大且高质量的数据库,例如教程题库和数学错题集,尝试进行启发式内容生成。
第三点是如何确保企业数据的安全性,因为数据在空间和时间上都存在很大的限制。一方面,企业难以将具有核心竞争力的数据用于大模型训练。一些行业专业人士曾指出,许多应用型公司不愿意将微调后的模型贡献到公有版本中与他人共享,而更倾向于训练自己的大模型,然后在本地进行私有化部署。在这一过程中,企业主要难点在于如何将私有化的业务数据与大模型结合。另一方面,企业的业务数据变化速度快,且实时性强,因此私有化部署后的大模型在数据层面也难以实现秒、天级别的更新。
当上述诸多问题横亘于企业和大模型落地之间,学术界和工业界也提出了两种解决方案。 一是采用 Fine-tuning 的方式迭代演进,让大模型学到更多的知识;二是通过 Vector search 的方法,把最新的私域知识存在向量数据库中,需要时在向量数据库中做基于语义的向量检索,这两种方法都可以为大模型提供更加精准的答案。 但是从成本方面来看,行业人士指出,向量数据库的成本仅为 Fine-tuning 的千分之一。向量数据库通过把数据向量化,进行存储和查询可以有效解决大模型预训练成本高、没有“长期记忆”、幻觉、知识更新不及时等问题。 因此,凭借其优势,向量数据库也被视为了加速大模型落地行业场景的关键突破口

亚马逊 OpenSearch Serverless
随着大模型的盛行,曾经在冷清中度过多年的向量数据库再次成为企业和资本市场的焦点。根据公开数据显示,自从2023年4月以来,以向量数据库为代表的人工智能投资领域呈现出明显的增长趋势。多家初创企业,包括Pinecone、Chroma和Weviate等,纷纷获得了上亿美元的融资。
亚马逊云科技在云服务提供商中处于领先地位,为了帮助企业更好地应对数据局限问题,充分释放大模型的潜力,2023 年 8 月 1 日 亚马逊云科技宣布推出Amazon OpenSearch Serverless向量引擎的预览版。这一向量引擎在Amazon OpenSearch Serverless中提供了一种简单、可扩展、高性能的相似性搜索功能,使用户能够轻松构建现代化机器学习(ML)增强的搜索体验和生成式AI应用程序,而无需管理底层向量数据库基础设施。
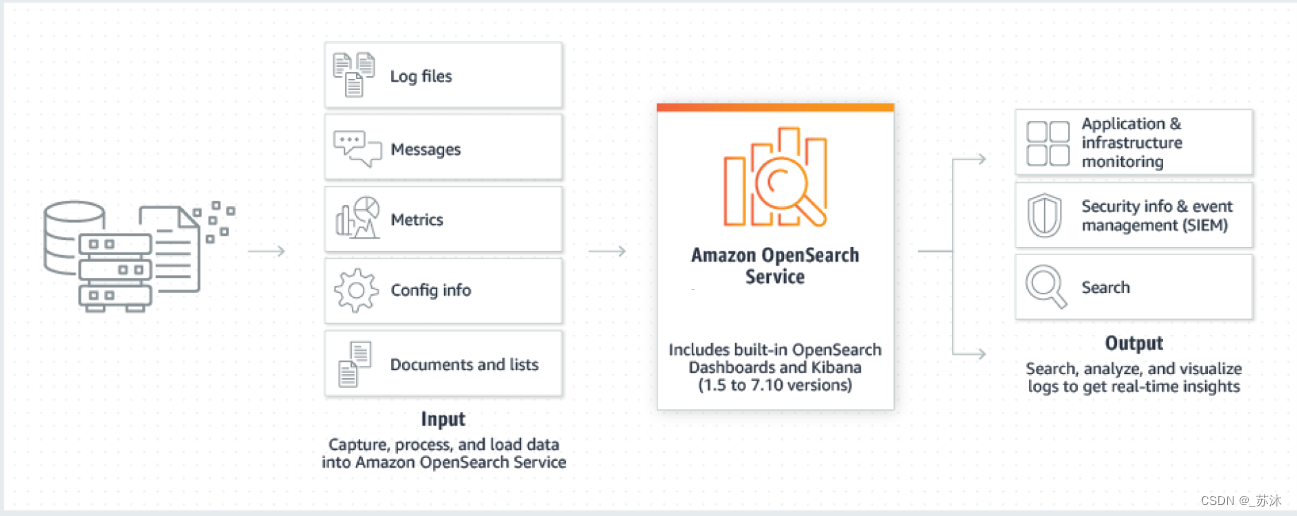
构建于 Amazon OpenSearch Serverless 的向量引擎天然具备鲁棒性。使用向量引擎,用户不必担心后端基础设施的选型、调优和扩展问题。因为大语言模型在处理文本数据时,常常将文本转换为高维向量。这些向量数据规模庞大,传统的数据库系统难以高效存储和查询。向量数据库专为存储和查询向量数据而设计,能够提供高效的数据存储和检索功能。
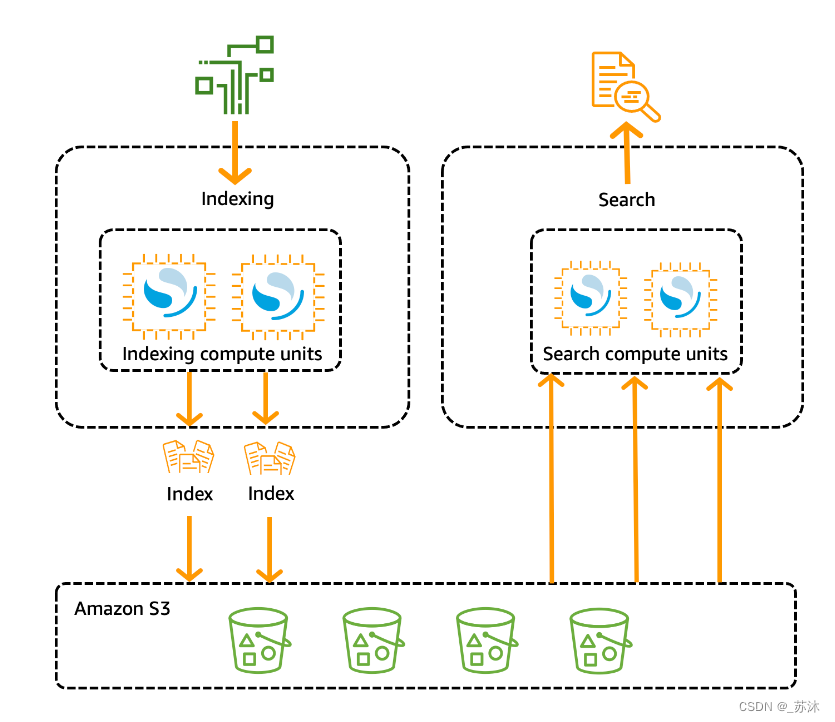
传统 OpenSearch 集群只有一组执行索引和搜索操作的实例,并且索引存储与计算容量紧密结合。相比之下, OpenSearch Serverless 使用云原生架构,将索引(提取)组件与搜索(查询)组件分开,Amazon S3 作为索引的主要数据存储。
这种分离架构使您可以独立扩展搜索和索引功能,并且独立于 S3 中的索引数据。这种架构还为摄取和查询操作提供了隔离,使它们可以同时运行,而不会发生资源争用。
当您将数据写入集合时, OpenSearch Serverless 会将其分发到索引计算单元。索引计算单位将摄取传入数据,并将索引移至 S3。当您对集合数据执行搜索时, OpenSearch Serverless 会将请求路由到保存所查询数据的搜索计算单元。搜索计算单位直接从 S3 下载索引数据(如果这些数据尚未在本地缓存),运行搜索操作,然后执行聚合。
下图阐明了这种分离架构:
在大模型时代的视角中,技术创新仅是第一步。除了大模型技术的创新外,像向量数据库这样的基础设施在数据存储、检索和分析等方面的搭建同样至关重要。亚马逊云科技不仅提供直接的大模型服务,更为关键的是向企业提供了有效、实用的平台工具,就如同提供了适当的“铲子”以应对这一新时代的挑战。
结语
除了上述提到的,亚马逊云科技的向量引擎不仅在大语言模型的“大脑作用”方面发挥重要作用,而且支持相同的OpenSearch开源套件API。通过与LangChain、Amazon Bedrock和Amazon SageMaker的集成,用户能够轻松地将首选的机器学习和人工智能系统与向量引擎整合在一起。
上述功能展示了该向量引擎预览版在性能“鲁棒性”方面的强大表现,以及其在大语言模型中的不可或缺作用。亚马逊云科技还在开发一些新功能,在未来几个月,将会帮助用户实现工作负载暂停与恢复,这项新功能对向量引擎十分有用,因为其中许多用例不需要持续索引数据。 在未来几年,预计亚马逊云科技的向量引擎正式版将问世,届时其在优化向量图性能和内存使用方面,包括改进缓存和合并等功能,将展现出更为强大的能力。让我们拭目以待。

