
- 1Spark大数据技术与应用
- 2Logstash + Kafka + python的分钟级数据实时抽取_kafka数据抽取
- 3Linux:DNS的多向解析配置_b610 dns
- 4L1和L2正则化
- 5关于从git上拉下来的代码左下角有一个黄色的闹钟解决办法
- 6Java 性能瓶颈分析工具 你知道几个?_com.alibaba.dubbo.remoting.exchange.support.defaul
- 7跟随Facebook的足迹:社交媒体背后的探索之旅
- 8基于python的微博情感分析与文本分类系统的设计与实现_微博语言情感分析系统设计的目标与原则
- 9大语言模型(LLMs)综合调研
- 10浅析C#数据结构—ArrayList、List类(三)_c# arraylist 结构体
Spark内核原理groupByKey、reduceByKey算子内部实现原理_请列举spark的groupbykey算子底层实现
赞
踩
一般来说,在执行shuffle类的算子的时候,比如groupByKey、reduceByKey、join等。
其实算子内部都会隐式地创建几个RDD出来。那些隐式创建的RDD,主要是作为这个操作的一些中间数据的表达,以及作为stage划分的边界。
因为有些隐式生成的RDD,可能是ShuffledRDD,dependency就是ShuffleDependency,DAGScheduler的源码,就会将这个RDD作为新的stage的第一个rdd,划分出来。
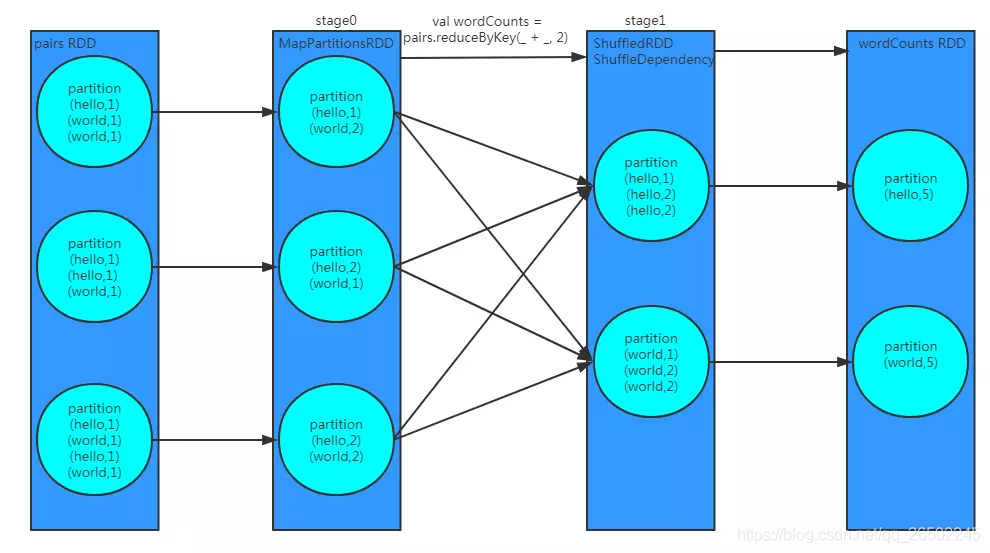
reduceByKey,跟groupByKey有一些异同之处
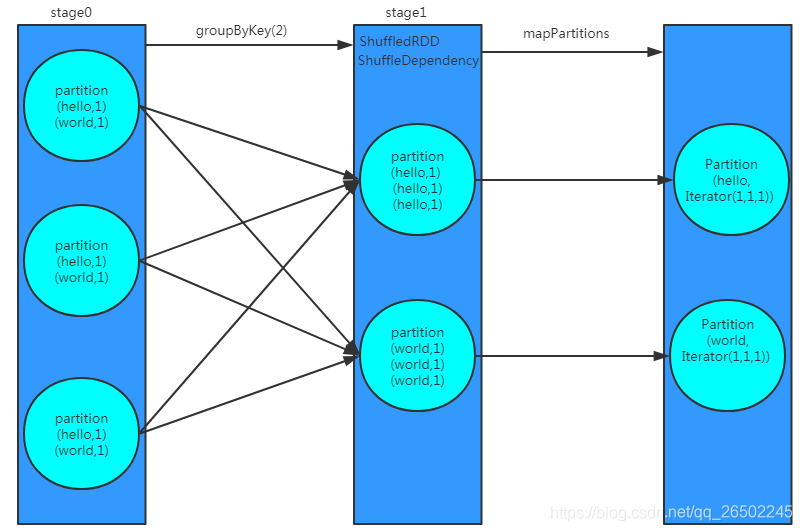
groupByKey等shuffle算子,都会创建一些隐式RDD。比如说这里,ShuffledRDD,作为一个shuffle过程中的中间数据的代表。
依赖这个ShuffledRDD创建出来一个新的stage(stage1)。ShuffledRDD会去触发shuffle read操作。从上游stage的task所在节点,拉取过来相同的key,做进一步的聚合。
对ShuffledRDD中的数据执行一个map类的操作,主要是对每个partition中的数据,都进行一个映射和聚合。这里主要是将每个key对应的数据都聚合到一个Iterator集合中。
不同之处:reduceByKey,多了一个rdd,MapPartitionsRDD,存在于stage0的,主要是代表了进行本地数据归约之后的rdd。所以,要网络传输的数据量,以及磁盘IO等,会减少,性能更高。
相同之处:后面进行shuffle read和聚合的过程基本和groupByKey类似。都是ShuffledRDD,去做shuffle read。然后聚合,聚合后的数据就是最终的rdd。wordCounts rdd。

