
- 1微调预训练模型Bert实现中文文本分类(bert_base_chinese) 1_bert网盘下载
- 2Git第六阶段:Rebase -> 合并多个commit为一个,使提交更为简洁。_rebase onto remote和drop local
- 3ComfyUI 秋叶整合包:工作流界面,解压即用,快速入门AI绘画_comfyui秋叶
- 4李宏毅机器学习笔记一_李宏毅机器学习笔记csdn
- 5huggingface实战bert-base-chinese模型(训练+预测)
- 6IOS 创建CocoaPods远程私有代码库和公开库
- 7No module named ‘cv2‘问题解决方法——亲试好用_no module named 'cv2
- 8Java基于web的问卷调查系统(开题+源码)_基于javaweb的问卷调查系统
- 9机器学习相关的 项目 数据集 源代码_机器学习源码
- 10AI 人工智能基础及应用_医学领域常见的人工智能算法有哪些
✨使用Python进行线性规划求解,高端操作亮瞎你的双眼(文末技术彩蛋)_python自带规划求解器是什么
赞
踩
![]()
各位童鞋们大家好,我是小小明,前几天我给大家分享了一个SMT求解器z3,链接地址见:
https://xxmdmst.blog.csdn.net/article/details/120279521
虽然SMT求解器很强大,能够解逻辑题、解数独、解方程、甚至解决逆向问题,但是有个缺点就是只能找出一个可行解,如果我想要找出可行解的最大值或最小值就不行,无法完成类似Excel的规划求解的功能。
前文中已经提到了scipy这个库可以进行线性规划求解,可惜我在这周的实际测试中发现,不支持整数约束,只能求解出实数。差点放弃写这篇文章,不过后面我又发现了PuLP这个库,简直发现了新大陆,原来有这么个专门进行规划求解的库,于是又花了几天时间专门来研究它。
今天呢,我将首先演示scipy这个库的用法,然后再演示PuLP库如何进行线性规划求解。
当然,PuLP库也不是万能的,虽然可以解决线性规划问题,但是相对Excel的规划求解还有很多难以实现的功能,例如非线性的规划求解。如果真的必须要进行非线性的规划求解时,可以考虑研究一下CVXPY这个库,官网地址是:https://www.cvxpy.org/
当然对于规划求解,95%以上的场景都是线性规划求解,PuLP就足够应对我们需要应对的场景。
认真看看本文噢,这都是近50小时研究,分享出来的精华噢,基本上你花一个小时就能掌握50小时的心血,而且本文文末还有技术彩蛋,带你掌握更多简单高效的技巧。
使用scipy库进行规划求解
scipy与numpy离线文档的下载地址:https://docs.scipy.org/doc/
在线文档地址:https://docs.scipy.org/doc/scipy/reference/
scipy库支持线性规划的函数是scipy.optimize.linprog
函数申明为:
cipy.optimize.linprog(c, A_ub = None, b_ub = None, A_eq = None, b_eq = None, bounds = None, method = ‘interior-point’, callback = None, options = None, x0 = None)
该函数用于在如下约束条件下,寻找目标函数(
c
T
x
c^{T} x
cTx)的最小值:
A
u
b
x
≤
b
u
b
A
e
q
x
=
b
e
q
l
≤
x
≤
u
主要参数说明:
- c:目标函数的未知数系数 {一维数组}
- A_up:不等式约束的未知数系数 {二维数组}
- b_up:不等式约束值的上限 {一维数组}
- A_eq:等式约束的未知数系数 {二维数组}
- B_eq:等式约束值的上限 {一维数组}
- bounds:决策变量的最小值和最大值
示例1:
假设要求目标函数 z = 4 x 1 + 3 x 2 z=4x_1+3x_2 z=4x1+3x2的最大值。
约束条件为:
{
2
x
1
+
x
2
≤
10
x
1
+
x
2
≤
8
x
2
≤
7
x
1
,
x
2
≥
0
\left\{
可以将目标函数理解为求-z的最小值,然后转换为linprog需要的参数传入:
import numpy as np
from scipy import optimize as op
z = np.array([4, 3])
A_ub = np.array([[2, 1], [1, 1]])
b_ub = np.array([10, 8])
# 元组分布表示x1和x2的边界范围
bounds = [0, None], [0, 7]
# 求目标函数取反后的最小值
res = op.linprog(-z, A_ub, b_ub, bounds=bounds)
print(f"目标函数的最大值z={-res.fun:.2f},此时目标函数的决策变量为{res.x.round(2)}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
目标函数的最大值z=26.00,此时目标函数的决策变量为[2. 6.]
- 1
示例2:
目标函数: max z = 2 x 1 + 3 x 2 − 5 x 3 \max z=2 x_{1}+3 x_{2}-5 x_{3} maxz=2x1+3x2−5x3
约束条件:
{
x
1
+
x
2
+
x
3
=
7
2
x
1
−
5
x
2
+
x
3
≥
10
x
1
+
3
x
2
+
x
3
≤
12
x
1
,
x
2
,
x
3
≥
0
\left\{
首先转换一下约束条件为:
{
−
2
x
1
+
5
x
2
−
x
3
≤
−
10
x
1
+
3
x
2
+
x
3
≤
12
x
1
+
x
2
+
x
3
=
7
x
1
,
x
2
,
x
3
≥
0
\left\{
然后编写出如下代码:
z = np.array([2, 3, -5])
A_ub = np.array([[-2, 5, -1], [1, 3, 1]])
b_ub = np.array([-10, 12])
A_eq = np.array([[1, 1, 1]])
b_eq = np.array([7])
# 元组分别表示x1、x2和x3的边界范围
bounds = [0, None], [0, None], [0, None]
# 求目标函数取反后的最小值即目标函数的最大值
res = op.linprog(-z, A_ub, b_ub, A_eq, b_eq, bounds=bounds)
print(f"目标函数的最大值z={-res.fun:.2f},此时目标函数的决策变量为{res.x.round(2)}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果:
目标函数的最大值z=14.57,此时目标函数的决策变量为[6.43 0.57 0. ]
- 1
此时假如需要将变量约束为整数,scipy库就无能为力。
咱们再介绍专门用来进行线性规划的库PuLP的使用:
使用PuLP进行规划求解
PULP是一个线性规划(Linear Programming, LP)问题求解库。它将优化问题描述为数学模型,生成MPS或者LP文件,然后调用LP求解器,如CBC、GLPK、CPLEX、Gurobi等来进行求解。
安装完pulp库默认就拥有了CBC求解器,其他求解器需要额外安装才能使用。
安装pulp库:
pip install pulp
- 1
详见:https://pypi.org/project/PuLP/
官方文档:https://coin-or.github.io/pulp/
使用步骤:
- 通过
pulp.LpProblem建立优化问题:
prob = pulp.LpProblem(name='NoName', sense=LpMinimize)
- 1
参数:
name:在lp文件中写入的问题名称;sense:最大或者最小,可为LpMinimize\LpMaximize二者之一。
- 通过
LpVariable函数创建优化变量:
pulp.LpVariable(name, lowBound=None, upBound=None, cat='Continuous', e=None)
- 1
参数:
name:变量名,会输出到.lp文件;lowBound:变量下界;upBound:变量上界;cat:变量类型,可以为LpInteger\LpBinary\LpContinuous三者之一(整型、二进制或连续);e:指明变量是否在目标函数和约束中存在,主要用来实现列生成算法。
- 通过
+=向优化问题添加目标函数和约束,例如:
prob += x1 + x2 == 100, "目标函数"
prob += 0.100*x1 + 0.200*x2 >= 8.0, "约束1"
- 1
- 2
- 使用求解器求解,默认为CBC:
prob.solve()
- 1
假如本机已经安装其他的LP求解器,就可以指定求解器,例如GLPK求解器:
prob.solve(GLPK(msg = 0))
- 1
GLPK求解器的下载地址:https://sourceforge.net/projects/winglpk/files/latest/download
假如需要使用默认的CBC求解MIP问题,可以指定use_mps=False:
prob.solve(use_mps=False)
- 1
下面我们看看如何使用PuLP解决上面的要求整数约束的一个线性规划问题:
目标函数:
max
z
=
2
x
1
+
3
x
2
−
5
x
3
\max z=2 x_{1}+3 x_{2}-5 x_{3}
maxz=2x1+3x2−5x3
约束条件:
{
x
1
+
x
2
+
x
3
=
7
2
x
1
−
5
x
2
+
x
3
≥
10
x
1
+
3
x
2
+
x
3
≤
12
x
1
,
x
2
,
x
3
≥
0
\left\{
代码如下:
from pulp import *
prob = LpProblem('max_z', sense=LpMaximize)
x1 = LpVariable('x1', 0, None, LpInteger)
x2 = LpVariable('x2', 0, None, LpInteger)
x3 = LpVariable('x3', 0, None, LpInteger)
# 设置目标函数
prob += 2*x1+3*x2-5*x3
# 约束条件
prob += x1+x2+x3 == 7
prob += 2*x1-5*x2+x3 >= 10
prob += x1+3*x2+x3 <= 12
status = prob.solve()
# print("求解状态:", LpStatus[prob.status])
print(f"目标函数的最大值z={value(prob.objective)},此时目标函数的决策变量为:",
{v.name: v.varValue for v in prob.variables()})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果:
目标函数的最大值z=14.0,此时目标函数的决策变量为: {'x1': 7.0, 'x2': 0.0, 'x3': 0.0}
- 1
再举个例子:
生产两种风机(风机A和风机B)
生产风机A,需要工时3小时,用电4千瓦,钢材9吨;
生产风机B,需要工时7小时,用电5千瓦,钢材5吨。
公司可提供的工时为300小时,可提供的用电量为250千瓦,可提供的钢材为420吨。
假设,两种产品的单位利润分别为200万元和210万元。怎样安排两种产品的生产量,所获得的利润最大?
解:设风机A产量为x,风机B产量为y,最大利润为Pmax,则
x,y>=0
3x+7y<=300
4x+5y<=250
9x+5y<=420
Pmax=200x+210y
由于生产量必须为整数,所以必须有整数约束,编码如下:
from pulp import *
prob = LpProblem('myProblem', sense=LpMaximize)
x = LpVariable('x', 0, 100, LpInteger)
y = LpVariable('y', 0, 100, LpInteger)
# 设置目标函数
prob += 200*x+210*y
# 约束条件
prob += 3*x+7*y <= 300
prob += 4*x+5*y <= 250
prob += 9*x+5*y <= 420
status = prob.solve()
# print("求解状态:", LpStatus[prob.status])
print(f"目标函数的最大值z={value(prob.objective)},此时目标函数的决策变量为:",
{v.name: v.varValue for v in prob.variables()})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
目标函数的最大值z=11460.0,此时目标函数的决策变量为: {'x': 30.0, 'y': 26.0}
- 1
可以看到pulp已经在整数约束下求解出了该问题。
关于LpStatus涉及的常量:
LpStatus = { LpStatusNotSolved:"Not Solved", LpStatusOptimal:"Optimal", LpStatusInfeasible:"Infeasible", LpStatusUnbounded:"Unbounded", LpStatusUndefined:"Undefined", }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- Not Solved:还没有调研solve()函数前的状态。
- Optimal:找到了最优解。
- Infeasible:问题没有可行解(比如定义了constraints x <= 1并且x >=2这样的约束)。
- Unbounded:约束条件是无界的(not bounded),最大化会导致无穷大(比如只有一个x >= 3这样的约束)。
- Undefined:最优解可能存在但是没有求解出来。
下面我们多学习编码几个案例巩固所学的知识:
PuLP求解线性规划案例
组合药物配料使总成本最低
某药厂生产A、B、C三种药物,可供选择的原料有甲、乙、丙、丁四种,成本分别是毎公斤5元、6元、7元、8元。每公斤不同原料所能提供的各种药物用量如下。若该药厂每天要生产A药品恰好100克,B药品至少530克,C药品至多160克。怎样选择各种配料才能满足生产又能使总成本最低?
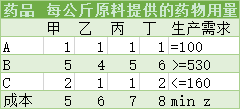
首先,我们计算出目标函数和约束条件。
目标函数:
min
z
=
5
x
1
+
6
x
2
+
7
x
3
+
8
x
4
\min z=5x_{1}+6x_{2}+7x_{3}+8x4
minz=5x1+6x2+7x3+8x4
约束条件:
{
x
1
+
x
2
+
x
3
+
x
4
=
100
5
x
1
+
4
x
2
+
5
x
3
+
6
x
4
≥
530
2
x
1
+
x
2
+
x
3
+
2
x
4
≤
160
x
1
,
x
2
,
x
3
,
x
4
≥
0
\left\{
下面我们使用python进行求解:
from pulp import *
prob = LpProblem('目标函数和约束', sense=LpMinimize)
x1 = LpVariable('x1', 0, None, LpInteger)
x2 = LpVariable('x2', 0, None, LpInteger)
x3 = LpVariable('x3', 0, None, LpInteger)
x4 = LpVariable('x4', 0, None, LpInteger)
# 设置目标函数
prob += 5*x1+6*x2+7*x3+8*x4
# 约束条件
prob += x1+x2+x3+x4 == 100
prob += 5*x1+4*x2+5*x3+6*x4 >= 530
prob += 2*x1+x2+x3+2*x4 <= 160
print(prob)
status = prob.solve(use_mps=True)
print(f"目标函数的最小值z={value(prob.objective)},此时目标函数的决策变量为:",
{v.name: v.varValue for v in prob.variables()})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
结果:
目标函数和约束:
MINIMIZE
5*x1 + 6*x2 + 7*x3 + 8*x4 + 0
SUBJECT TO
_C1: x1 + x2 + x3 + x4 = 100
_C2: 5 x1 + 4 x2 + 5 x3 + 6 x4 >= 530
_C3: 2 x1 + x2 + x3 + 2 x4 <= 160
VARIABLES
0 <= x1 Integer
0 <= x2 Integer
0 <= x3 Integer
0 <= x4 Integer
目标函数的最小值z=670.0,此时目标函数的决策变量为: {'x1': 30.0, 'x2': 0.0, 'x3': 40.0, 'x4': 30.0}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
医院每天护士人数分配
某县新建一家医院,根据各个科室要求需要配备护士,周一到周日分别最小需要34、25、36、30、28、31、32人,按照规定,一个护士一周要连续上班5天。这家医院至少需要多少个护士?
解答:
一个护士一周要连续上班5天,我们假设有从周一开始连续上班的护士人数为x1,周二x2,…,以此类推。对于周一这天,除了从周二和周三开始上班的护士外,其他护士都会在这天上班,其他日期也同理。那么我们就可以用线性规划解决很简单的这个问题:
from pulp import *
# 设周1到周日开始上班的护士人数
x = [LpVariable(f"x{i}", lowBound=0, upBound=18, cat=LpInteger)
for i in range(1, 8)]
min_nums = [34, 25, 36, 30, 28, 31, 32]
prob = LpProblem('目标函数和约束', sense=LpMinimize)
prob += lpSum(x)
for i, num in enumerate(x):
prob += lpSum(x)-x[(i+5) % 7]-x[(i+6) % 7] >= min_nums[i]
status = prob.solve()
print("最少护士人数 z=", value(prob.objective))
print("周1到周日开始上班的护士人数分别为:", [value(x[i]) for i in range(7)])
print("周一到周日上班人数分别为:", [
value(lpSum(x)-x[(i+5) % 7]-x[(i+6) % 7]) for i in range(7)])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
最少护士人数 z= 44.0
周1到周日开始上班的护士人数分别为: [8.0, 0.0, 14.0, 1.0, 12.0, 0.0, 9.0]
周一到周日上班人数分别为: [35.0, 27.0, 36.0, 30.0, 29.0, 31.0, 32.0]
- 1
- 2
- 3
结论上最少需要44个护士,当然护士的分配这并不是唯一解,还有很多种分配方式,上面给出了其中一种可行的分配方式。
数据包络分析(DEA)
数据包络分析方法(Data Envelopment Analysis,DEA)是运筹学、管理科学与数理经济学交叉研究的一个新领域。它是根据多项投入指标和多项产出指标,利用线性规划的方法,对具有可比性的同类型单位进行相对有效性评价的一种数量分析方法。
例如,某银行的某区域有六个分理处,它们的投入产出情况如下:
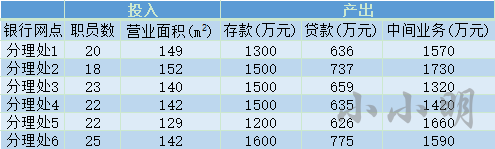
现在需要分析分理处1是否可以通过其他分理处的组合达到投入更少产出更多的效果。
对于这个问题,其实还比较复杂,我们可以先看看如何用Excel解决这个问题。
首先补充Excel表为如下结构:
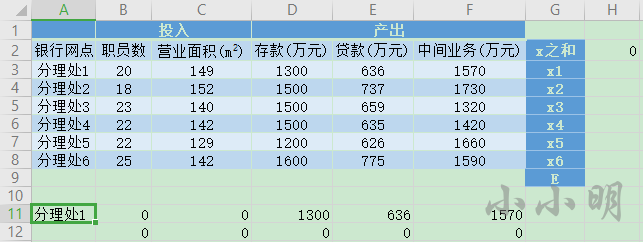
(投入)B11单元格的公式为:=VLOOKUP($A11,$A$3:$F$8,COLUMN(),0)*$H$9
(产出)D11单元格的公式为:=VLOOKUP($A11,$A$3:$F$8,COLUMN(),0)
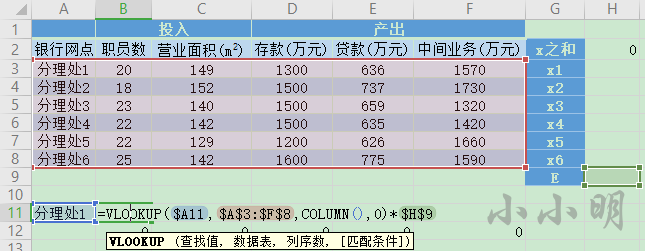
(组合后的投入产出)B12单元格的公式为:=SUMPRODUCT(B$3:B$8,$H$3:$H$8)
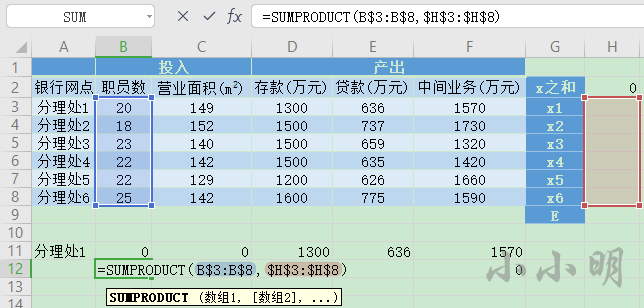
x之和设置为六个分理处的权重之和,H2单元格的公式为:=SUM(H3:H8)
然后设置规划求解参数:

最终结果:
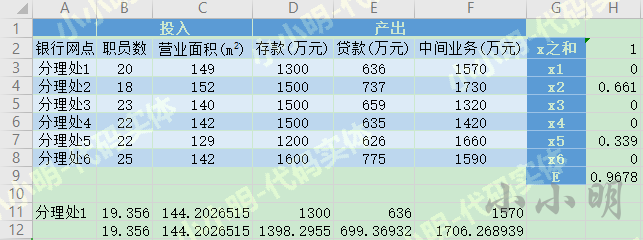
那么我们如何使用Python来解决这个问题:
首先读取数据:
import pandas as pd
import numpy as np
df = pd.read_excel(r"C:\Users\ASUS\Desktop\规划求解.xlsx",
index_col=0, usecols="A:F", sheet_name=1,
skiprows=1, nrows=6)
data = df.values
data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
array([[ 20, 149, 1300, 636, 1570],
[ 18, 152, 1500, 737, 1730],
[ 23, 140, 1500, 659, 1320],
[ 22, 142, 1500, 635, 1420],
[ 22, 129, 1200, 626, 1660],
[ 25, 142, 1600, 775, 1590]], dtype=int64)
- 1
- 2
- 3
- 4
- 5
- 6
然后开始求解:
from pulp import *
prob = LpProblem('目标函数和约束', sense=LpMinimize)
# 定义6个变量
x = [LpVariable(f"x{i}", lowBound=0, upBound=1) for i in range(1, 7)]
# 定义期望E
e = LpVariable("e", lowBound=0, upBound=1)
# 办事处1的数据
office1 = data[0]
# 各办事处的加权平均值
office_wavg = np.sum(data*np.array(x)[:, None], axis=0)
# 定义目标变量,期望存储在e变量中
prob += e
# 权重之和为1
prob += lpSum(x) == 1
# 投入更少
for i in range(2):
prob += office_wavg[i] <= office1[i]*e
# 产出更多
for i in range(2, data.shape[1]):
prob += office_wavg[i] >= office1[i]
print(prob)
status = prob.solve()
print("求解状态:", LpStatus[prob.status])
print(f"目标函数的最小值z={value(prob.objective)},此时目标函数的决策变量为:",
{v.name: v.varValue for v in prob.variables()})
print("组合后的投入和产出:",[f"{value(office_wavg[i]):.2f}" for i in range(data.shape[1])])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
结果:
目标函数和约束:
MINIMIZE
1*e + 0
SUBJECT TO
_C1: x1 + x2 + x3 + x4 + x5 + x6 = 1
_C2: - 20 e + 20 x1 + 18 x2 + 23 x3 + 22 x4 + 22 x5 + 25 x6 <= 0
_C3: - 149 e + 149 x1 + 152 x2 + 140 x3 + 142 x4 + 129 x5 + 142 x6 <= 0
_C4: 1300 x1 + 1500 x2 + 1500 x3 + 1500 x4 + 1200 x5 + 1600 x6 >= 1300
_C5: 636 x1 + 737 x2 + 659 x3 + 635 x4 + 626 x5 + 775 x6 >= 636
_C6: 1570 x1 + 1730 x2 + 1320 x3 + 1420 x4 + 1660 x5 + 1590 x6 >= 1570
VARIABLES
e <= 1 Continuous
x1 <= 1 Continuous
x2 <= 1 Continuous
x3 <= 1 Continuous
x4 <= 1 Continuous
x5 <= 1 Continuous
x6 <= 1 Continuous
求解状态: Optimal
目标函数的最小值z=0.96780303,此时目标函数的决策变量为: {'e': 0.96780303, 'x1': 0.0, 'x2': 0.66098485, 'x3': 0.0, 'x4': 0.0, 'x5': 0.33901515, 'x6': 0.0}
组合后的投入和产出: ['19.36', '144.20', '1398.30', '699.37', '1706.27']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
可以看到求解出来的结果与Excel一致。
当然,针对任何一个分理处进行计算都可以得到一致的结果:
from pulp import *
# 定义6个变量
x = [LpVariable(f"x{i}", lowBound=0, upBound=1) for i in range(1, 7)]
# 定义期望E
e = LpVariable("e", lowBound=0, upBound=1)
# 办事处1的数据
for num, office in enumerate(data, 1):
prob = LpProblem('目标函数和约束', sense=LpMinimize)
# 各办事处的加权平均值
office_wavg = np.sum(data*np.array(x)[:, None], axis=0)
# 定义目标变量,期望存储在e变量中
prob += e
# 权重之和为1
prob += lpSum(x) == 1
# 投入更少
for i in range(2):
prob += office_wavg[i] <= office1[i]*e
# 产出更多
for i in range(2, data.shape[1]):
prob += office_wavg[i] >= office1[i]
status = prob.solve()
print(f"---------办事处{num}----------")
print("求解状态:", LpStatus[prob.status])
print(f"目标函数的最小值z={value(prob.objective)},此时目标函数的决策变量为:",
{v.name: v.varValue for v in prob.variables()})
print("组合后的投入和产出:", [
f"{value(office_wavg[i]):.2f}" for i in range(data.shape[1])])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
---------办事处1----------
目标函数的最小值z=0.96780303,此时目标函数的决策变量为: {'e': 0.96780303, 'x1': 0.0, 'x2': 0.66098485, 'x3': 0.0, 'x4': 0.0, 'x5': 0.33901515, 'x6': 0.0}
组合后的投入和产出: ['19.36', '144.20', '1398.30', '699.37', '1706.27']
---------办事处2----------
目标函数的最小值z=0.96780303,此时目标函数的决策变量为: {'e': 0.96780303, 'x1': 0.0, 'x2': 0.66098485, 'x3': 0.0, 'x4': 0.0, 'x5': 0.33901515, 'x6': 0.0}
组合后的投入和产出: ['19.36', '144.20', '1398.30', '699.37', '1706.27']
---------办事处3----------
目标函数的最小值z=0.96780303,此时目标函数的决策变量为: {'e': 0.96780303, 'x1': 0.0, 'x2': 0.66098485, 'x3': 0.0, 'x4': 0.0, 'x5': 0.33901515, 'x6': 0.0}
组合后的投入和产出: ['19.36', '144.20', '1398.30', '699.37', '1706.27']
---------办事处4----------
目标函数的最小值z=0.96780303,此时目标函数的决策变量为: {'e': 0.96780303, 'x1': 0.0, 'x2': 0.66098485, 'x3': 0.0, 'x4': 0.0, 'x5': 0.33901515, 'x6': 0.0}
组合后的投入和产出: ['19.36', '144.20', '1398.30', '699.37', '1706.27']
---------办事处5----------
目标函数的最小值z=0.96780303,此时目标函数的决策变量为: {'e': 0.96780303, 'x1': 0.0, 'x2': 0.66098485, 'x3': 0.0, 'x4': 0.0, 'x5': 0.33901515, 'x6': 0.0}
组合后的投入和产出: ['19.36', '144.20', '1398.30', '699.37', '1706.27']
---------办事处6----------
目标函数的最小值z=0.96780303,此时目标函数的决策变量为: {'e': 0.96780303, 'x1': 0.0, 'x2': 0.66098485, 'x3': 0.0, 'x4': 0.0, 'x5': 0.33901515, 'x6': 0.0}
组合后的投入和产出: ['19.36', '144.20', '1398.30', '699.37', '1706.27']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
从结果看,所有结果都一致。
旅行商问题
某邮递员每天从邮局(位于A小区)出发需要到7个不同位置的小区送信件,然后从这7个地方的邮筒收集信件回到邮局。通过长时间的观察记录,邮递员对7个区域之间骑车所需的平均时间进行整理,如下表所示。如何规划邮递员一天的路线才能使得路上花费的时间最少?
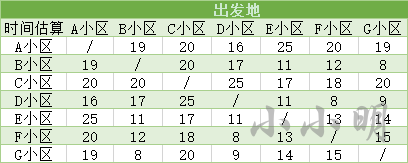
这题用Python可以通过暴力的方式解决,思维也非常直接简单。
不过,今天我们主要的目标是深入讲解Python进行线性规划求解,所以通过这题演示一下线性规划中的二值变量的使用。
首先,我们使用基本的约束尝试一下:
- 不能是对角线
- 出发地唯一性
- 目标唯一性
from pulp import *
import numpy as np
import pandas as pd
distances = np.array([
[0, 19, 20, 16, 25, 20, 19],
[19, 0, 20, 17, 11, 12, 8],
[20, 20, 0, 25, 17, 18, 20],
[16, 17, 25, 0, 11, 8, 9],
[25, 11, 17, 11, 0, 13, 14],
[20, 12, 18, 8, 13, 0, 15],
[19, 8, 20, 9, 14, 15, 0]
])
# 创建二值变量,i表示列(起点),j表示行(目标),xij表示当前路径是否被选中
x = np.array([
[LpVariable(f"{i}{j}", cat=LpBinary)
for i in "ABCDEFG"]
for j in "ABCDEFG"
])
prob = LpProblem('目标函数和约束', sense=LpMinimize)
# 所需时间求最小
z = (distances*x).sum()
prob += z
# 不能是对角线,即自己到自己
for i in range(x.shape[0]):
prob += x[i, i] == 0
# 出发地唯一性
for i in x.sum(axis=0):
prob += i == 1
# 目标唯一性
for i in x.sum(axis=1):
prob += i == 1
status = prob.solve()
print("z=", value(prob.objective))
print("路径选择:")
result = [[int(value(cell)) for cell in row]for row in x]
result = pd.DataFrame(result, index=list("ABCDEFG"), columns=list("ABCDEFG"))
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
结果:
z= 88.0
路径选择:
A B C D E F G
A 0 0 1 0 0 0 0
B 0 0 0 0 0 0 1
C 1 0 0 0 0 0 0
D 0 0 0 0 1 0 0
E 0 0 0 0 0 1 0
F 0 0 0 1 0 0 0
G 0 1 0 0 0 0 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以看到求解的结果路径中出现了,A<->C,B<->G,D->F->E->D这种循环路径的问题。
如何增加约束条件避免循环路径的问题呢?
假设
U
i
U_i
Ui表示第i个小区是第i个到达的,有理论研究(暂不懂其数学原理)表明当约束为:
{
u
i
−
u
j
+
n
x
i
j
≤
n
−
1
1
≤
i
≠
j
≤
n
−
1
\left\{
其中n表示目的地的个数,即7个,
x
i
j
x_{ij}
xij表示指定路径是否被选择,有0或1两种可能。
可以避免上述循环路径的问题,那么我们继续在我们的程序中增加上述约束测试一下:
paths = [LpVariable(f"x{_}", lowBound=0, upBound=6,
cat=LpInteger) for _ in range(7)]
prob += paths[0] == 1
for j in range(1, 7):
for i in range(1, 7):
if i == j:
continue
prob += paths[i]-paths[j]+7*x[j, i] <= 6
status = prob.solve()
print("z=", value(prob.objective))
print("到达顺序:", [int(value(path)) for path in paths])
print("路径选择:")
result = [[int(value(cell)) for cell in row]for row in x]
result = pd.DataFrame(result, index=list("ABCDEFG"), columns=list("ABCDEFG"))
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果:
z= 93.0
到达顺序: [1, 2, 0, 5, 1, 6, 3]
路径选择:
A B C D E F G
A 0 0 0 0 0 1 0
B 0 0 0 0 1 0 0
C 1 0 0 0 0 0 0
D 0 0 0 0 0 0 1
E 0 0 1 0 0 0 0
F 0 0 0 1 0 0 0
G 0 1 0 0 0 0 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
从结果可以看到,最少花费时间为93,路径为A->C->E->B->G->D->F->A。
完整代码为:
from pulp import *
import numpy as np
import pandas as pd
distances = np.array([
[0, 19, 20, 16, 25, 20, 19],
[19, 0, 20, 17, 11, 12, 8],
[20, 20, 0, 25, 17, 18, 20],
[16, 17, 25, 0, 11, 8, 9],
[25, 11, 17, 11, 0, 13, 14],
[20, 12, 18, 8, 13, 0, 15],
[19, 8, 20, 9, 14, 15, 0]
])
# i表示列(起点),j表示行(目标)
x = np.array([
[LpVariable(f"{i}{j}", cat=LpBinary)
for i in "ABCDEFG"]
for j in "ABCDEFG"
])
prob = LpProblem('目标函数和约束', sense=LpMinimize)
# 所需时间求最小
z = (distances*x).sum()
prob += z
# 不能是对角线,即自己到自己
for i in range(x.shape[0]):
prob += x[i, i] == 0
# 出发地唯一性
for i in x.sum(axis=0):
prob += i == 1
# 目标唯一性
for i in x.sum(axis=1):
prob += i == 1
paths = [LpVariable(f"x{_}", lowBound=0, upBound=6,
cat=LpInteger) for _ in range(7)]
prob += paths[0] == 1
for j in range(1, 7):
for i in range(1, 7):
if i == j:
continue
prob += paths[i]-paths[j]+7*x[j, i] <= 6
status = prob.solve()
print("z=", value(prob.objective))
print("到达顺序:", [int(value(path)) for path in paths])
print("路径选择:")
result = [[int(value(cell)) for cell in row]for row in x]
result = pd.DataFrame(result, index=list("ABCDEFG"), columns=list("ABCDEFG"))
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
那么线性规划求解出来的结果是否正确呢?我们可以通过通过程序暴力遍历,获取最准确的最小值对比一下:
import itertools
import pandas as pd
import numpy as np
distances = np.array([
[0, 19, 20, 16, 25, 20, 19],
[19, 0, 20, 17, 11, 12, 8],
[20, 20, 0, 25, 17, 18, 20],
[16, 17, 25, 0, 11, 8, 9],
[25, 11, 17, 11, 0, 13, 14],
[20, 12, 18, 8, 13, 0, 15],
[19, 8, 20, 9, 14, 15, 0]
])
distances = pd.DataFrame(distances, index=list(
"ABCDEFG"), columns=list("ABCDEFG"))
min_time = distances.sum().sum()
min_paths = []
for path in itertools.permutations("BCDEFG", 6):
path = ("A",)+path+("A",)
distance_cur = 0
for src, dest in zip(path[:-1], path[1:]):
distance_cur += distances.at[dest, src]
if min_time > distance_cur:
min_time = distance_cur
min_paths.clear()
if min_time >= distance_cur:
min_paths.append(path)
print("最短路径有:")
for min_path in min_paths:
print("->".join(min_path))
print("最短耗时为:", min_time)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
最短路径有:
A->C->E->B->G->D->F->A
A->F->D->G->B->E->C->A
最短耗时为: 93
- 1
- 2
- 3
- 4
从结果看到线性规则正确的求解出了其中一个正确的答案。
彩蛋:特殊技巧使Z3求解器可以求出多解
感谢还在认真看文的你,赠送一个技巧,让Z3约束求解器也可以获取所有的可行解。
前文在介绍z3求解器(详见文首地址)时,提到z3的一个缺点是只能找到一个可行解,无法找出所有的可行解。但其实只要我们采用一点小技巧,即可实现让z3找出所有的可行解。思路:每找出一个解就将其添加到约束中,不允许结果正好满足这个解,直到再也找不出可行解,就找到了所有的可行解。
以前面的八皇后问题为例进行演示,首先我们先看看普通的回溯算法求解的结果:
result = [0] * 8 # 角标代表皇后所在的行数,值存储皇后所在的列
def print_eight_queen(result):
for column in result:
for i in range(8):
if i == column:
print(end="Q ")
else:
print(end="* ")
print()
n = 1 # 第n个满足条件的情况
def cal8queen(row: int = 0):
global n
if row == 8:
print(f"----------{n}----------")
print_eight_queen(result)
n += 1
for column in range(8):
# 只有在第row行column列放置不与之前已经放置的冲突时才进行放置
if is_ok(row, column):
result[row] = column
cal8queen(row + 1)
def is_ok(row, column):
"""
校验在第row行将皇后放置在第column列是否满足条件
通过校验的条件是第row行前面所有行,都没有与当前列相同的列数,也不在当前列的对角线上
"""
leftup, rightup = column - 1, column + 1
for i in range(row - 1, -1, -1):
if column == result[i] or leftup == result[i] or rightup == result[i]:
return False
leftup -= 1
rightup += 1
return True
cal8queen(0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
截取首尾的结果打印如下:
----------1----------
Q * * * * * * *
* * * * Q * * *
* * * * * * * Q
* * * * * Q * *
* * Q * * * * *
* * * * * * Q *
* Q * * * * * *
* * * Q * * * *
...
----------92----------
* * * * * * * Q
* * * Q * * * *
Q * * * * * * *
* * Q * * * * *
* * * * * Q * *
* Q * * * * * *
* * * * * * Q *
* * * * Q * * *
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
然后我们让z3约束求解器帮我们找出这92个解:
from z3 import *
# 每个皇后必须在不同的行中,记录每行对应的皇后对应的列位置
Q = [Int(f'Q_{i}') for i in range(8)]
# 每个皇后在列 0,1,2,...,7
val_c = [And(0 <= Q[i], Q[i] <= 7) for i in range(8)]
# 每列最多一个皇后
col_c = [Distinct(Q)]
# 对角线约束
diag_c = [If(i == j,
True,
And(Q[i] - Q[j] != i - j, Q[i] - Q[j] != j - i))
for i in range(8) for j in range(i)]
def print_eight_queen(result):
for column in result:
for i in range(8):
if i == column:
print(end="Q ")
else:
print(end="* ")
print()
s = Solver()
s.add(val_c + col_c + diag_c)
n = 1 # 第n个满足条件的情况
while s.check() == sat:
result = s.model()
result = [result[Q[i]].as_long() for i in range(8)]
print(f"----------{n}----------")
print_eight_queen(result)
s.add(Not(And([qx == p for qx, p in zip(Q, result)])))
n += 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
----------1----------
* * * Q * * * *
* Q * * * * * *
* * * * * * * Q
* * * * * Q * *
Q * * * * * * *
* * Q * * * * *
* * * * Q * * *
* * * * * * Q *
...
----------92----------
* * * * * * Q *
* Q * * * * * *
* * * * * Q * *
* * Q * * * * *
Q * * * * * * *
* * * Q * * * *
* * * * * * * Q
* * * * Q * * *
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
可以看到也是92的解,虽然顺序不一样,但这92个解都找出来了。

