
热门标签
热门文章
- 1Oracle又裁员!_oracle裁员
- 2KeeperErrorCode = ConnectionLoss 问题解决
- 37 Series FPGAs Integrated Block for PCI Express IP核基本模式配置详解
- 4If you want an embedded database (H2, HSQL or Derby), please put it on the classpath.
- 5python数组求和函数_python数据分析之Numpy数据库第三期数组的运算
- 6第三阶段应用层——1.7 数码相册—电子书(2)—编写通用的Makefile_在主目录下创建dianzi1和dianzi2两个文件夹,在dianzi1文件夹中创建file1 fi
- 7<网络安全>《70 微课堂<第11课 0day、1day、nday(精华版)>》_0day、1day、n day
- 8计算机领域顶级会议归纳(计算机视觉CV、机器学习ML、人工智能AI)_wacv
- 9RabbitMQ消费者Consumer实现_java rabbitmq consumer
- 10CKA 06_Kubernetes 工作负载与调度 Pod 管理 yaml 资源清单 标签 Pod 生命周期 容器探针_kubernetes工作负载 yaml
当前位置: article > 正文
Hadoop3.3.3集群安装_hadoop 3.3 安装
作者:Gausst松鼠会 | 2024-05-27 16:45:09
赞
踩
hadoop 3.3 安装
一、虚拟机准备
本机配置:
主机 hadoop0: 4c8g ip配置为192.168.147.155
从机 hadoop1:1c1g ip配置为192.168.147.156
从机 hadoop2:1c1g ip配置为192.168.147.157
Vmware 配置一台主机,使用CentOS-7-x86_64-DVD-1810.iso镜像,采用最小化安装,
主机8GB内存,4个处理器,硬盘最好给多点,200G-300G,看本机的资源情况分配
1.主机hadoop0配置
#主机hadoop0系统配置
#安装vim工具
yum install -y vim
#关闭防火墙(线上勿操作)
systemctl stop firewalld
systemctl disable firewalld
#禁用安全策略
vim /etc/selinux/config 设置SELINUX=disabled
#ip配置,根据自己网卡定(主机安装就可以设置ip,已设置则无需再次修改)
vim /etc/sysconfig/network-scripts/ifcfg-ens32
#更改主机名称(主机安装时可以直接设置,已设置则无需变更),需要重启reboot
hostnamectl set-hostname hadoop0
#配置hosts文件
vim /etc/hosts
#配置jdk,下载安装包jdk-8u221-linux-x64.rpm(自己选择版本,最低版本jdk8),默认安装目录/usr/java
rpm -ivh jdk-8u221-linux-x64.rpm
#配置jdk环境变量
vim /etc/profile
----------------------------------
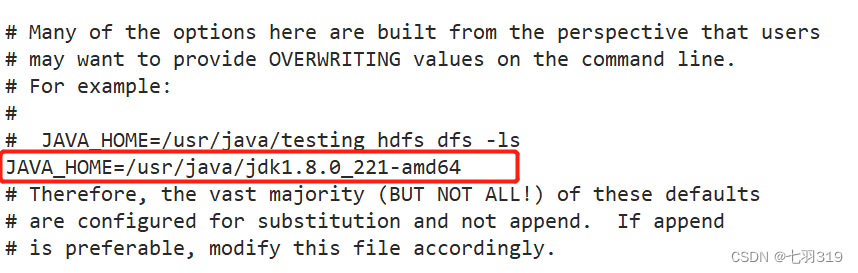
JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/jconsole.jar
export CLASSPATH PATH JAVA_HOME
----------------------------------
source /etc/profile # 使环境变量立即生效
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

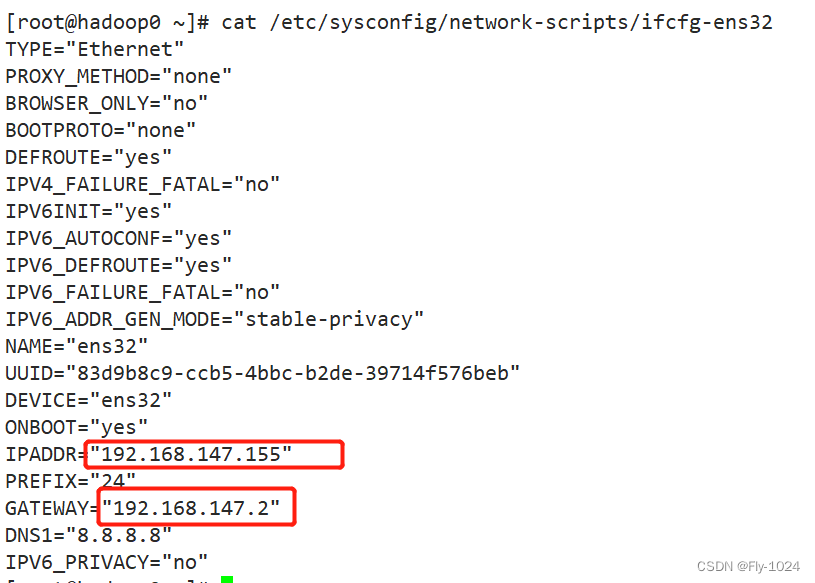


2.克隆两台从机,更改ip和主机名称
根据主机克隆两台从机,资源依据自己的情况定,主要调整一下从机的ip和主机名称。
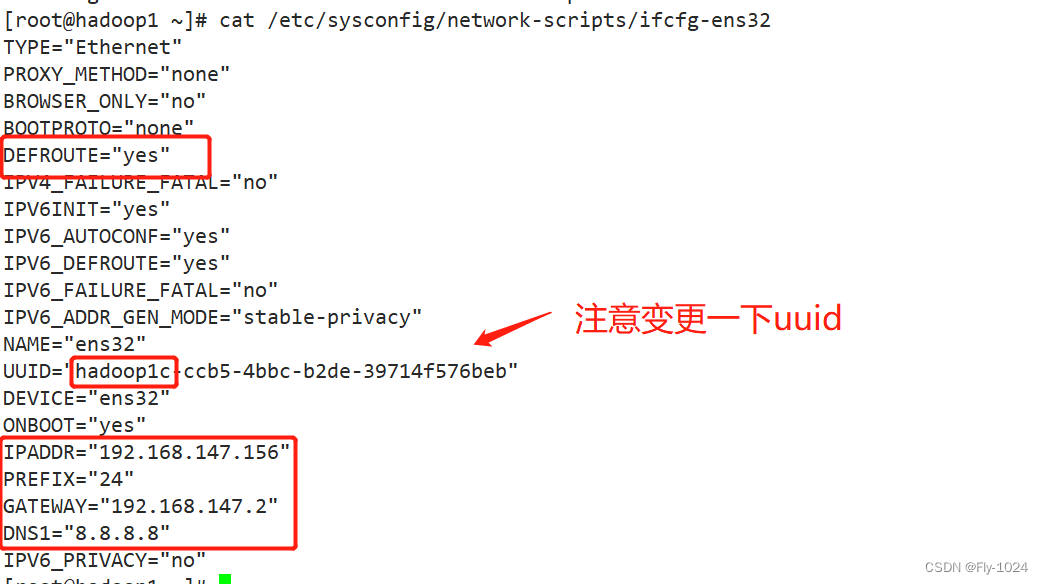
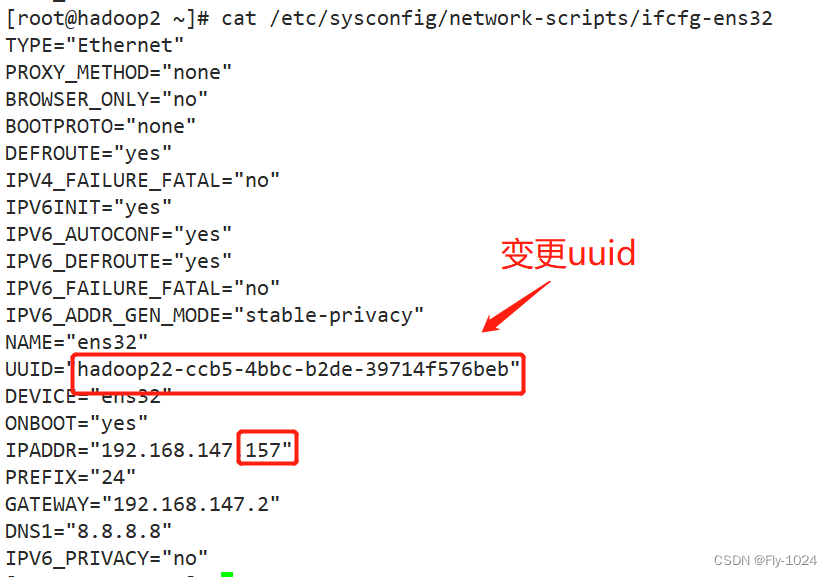
二、配置三台机器之间的ssh免密登录
- 在主机hadoop0,hadoop1,hadoop2上线分别执行以下命令,生成密钥,多次回车,使用默认配置:
ssh-keygen -t rsa
- 1
- 在hadoop0上/root/.ssh目录下创建文件authorized_keys
cd /root/.ssh
touch authorized_keys & chmod 600 authorized_keys
- 1
- 2
- 将hadoop0,hadoop1,hadoop2的公钥信息都放入hadoop0的/root/.ssh/authorized_keys里面
# 在hadoop0上执行
cat /root/.ssh/id_rsa.pub >> authorized_keys
# 在hadoop1和hadoop2上分别执行
ssh-copy-id -i /root/.ssh/id_rsa.pub hadoop0
- 1
- 2
- 3
- 4
- 在hadoop0上查看公钥信息,是否已经拥有三台机器的公钥
cat /root/.ssh/authorized_keys
- 1
- 将hadoop0的authorized_keys拷贝到hadoop1和hadoop2上
#在hadoop0上分别执行
scp -p /root/.ssh/authorized_keys hadoop1:/root/.ssh/
scp -p /root/.ssh/authorized_keys hadoop2:/root/.ssh/
- 1
- 2
- 3
- 三台机器已经可以免密互访
ssh hadoop0
ssh hadoop1
ssh hadoop2
- 1
- 2
- 3
三、安装Hadoop
0.前置准备
a. 下载上传解压
下载hadoop:https://hadoop.apache.org/release/3.3.3.html
上传安装包到hadoop0的/usr/local/hadoop目录下,解压
cd /usr/local/hadoop
tar -zxvf hadoop-3.3.3.tar.gz
- 1
- 2
注:根据自己喜好调整文件目录
b. 配置hadoop的环境变量,hadoop0、hadoop1、hadoop2均配置
# 执行 vim /etc/profile 添加以下内容(注意文件目录和自己的一致)
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# 执行 source /etc/profile 使环境变量立即生效
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注:不要漏了$HADOOP_HOME/sbin
c.在hadoop1上更改配置文件信息
# 修改hadoop-env.sh,添加JAVA_HOME
vim /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/hadoop-env.sh
- 1
- 2
#修改core-site.xml,添加配置信息
vim /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/core-site.xml
#在configuration标签中添加下面内容
<!--HDFS临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-3.3.3/tmp</value>
</property>
<!--HDFS的默认地址、端口 访问地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
#修改yarn-site.xml
vim /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/yarn-site.xml
#在configuration标签中添加下面内容
<!--集群master-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
<!--NodeManager上运行的附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--容器可能会覆盖的环境变量,而不是使用NodeManager的默认值-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value>
</property>
<!--关闭内存检测,在虚拟机环境中不做配置会报错-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
#修改mapred-site.xml
vim /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/mapred-site.xml
#在configuration标签中添加下面内容
<!--local表示本地运行,classic表示经典mapreduce框架,yarn表示新的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--如果map和reduce任务访问本地库(压缩等),则必须保留原始值,当此值为空时,设置执行环境的命令将取决于操作系统-->
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-3.3.3</value>
</property>
<!--可以设置AM【AppMaster】端的环境变量-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-3.3.3</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
#修改hdfs-site.xml
vim /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/hdfs-site.xml
#在configuration标签中添加下面内容
<!--hdfs web的地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop0:50070</value>
</property>
<!--副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--是否启用hdfs权限,当值为false时,代表关闭-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--块大小,默认128M-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
#修改works文件
vim /usr/local/hadoop/hadoop-3.3.3/etc/hadoop/workers
#添加以下内容(第一个是master)
hadoop0
hadoop1
hadoop2
- 1
- 2
- 3
- 4
- 5
- 6
d.将hadoop0上的配置文件发送给hadoop1和hadoop2
#在hadoop0上面执行
scp -r /usr/local/hadoop/hadoop-3.3.3 hadoop1://usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-3.3.3 hadoop2://usr/local/hadoop/
- 1
- 2
- 3
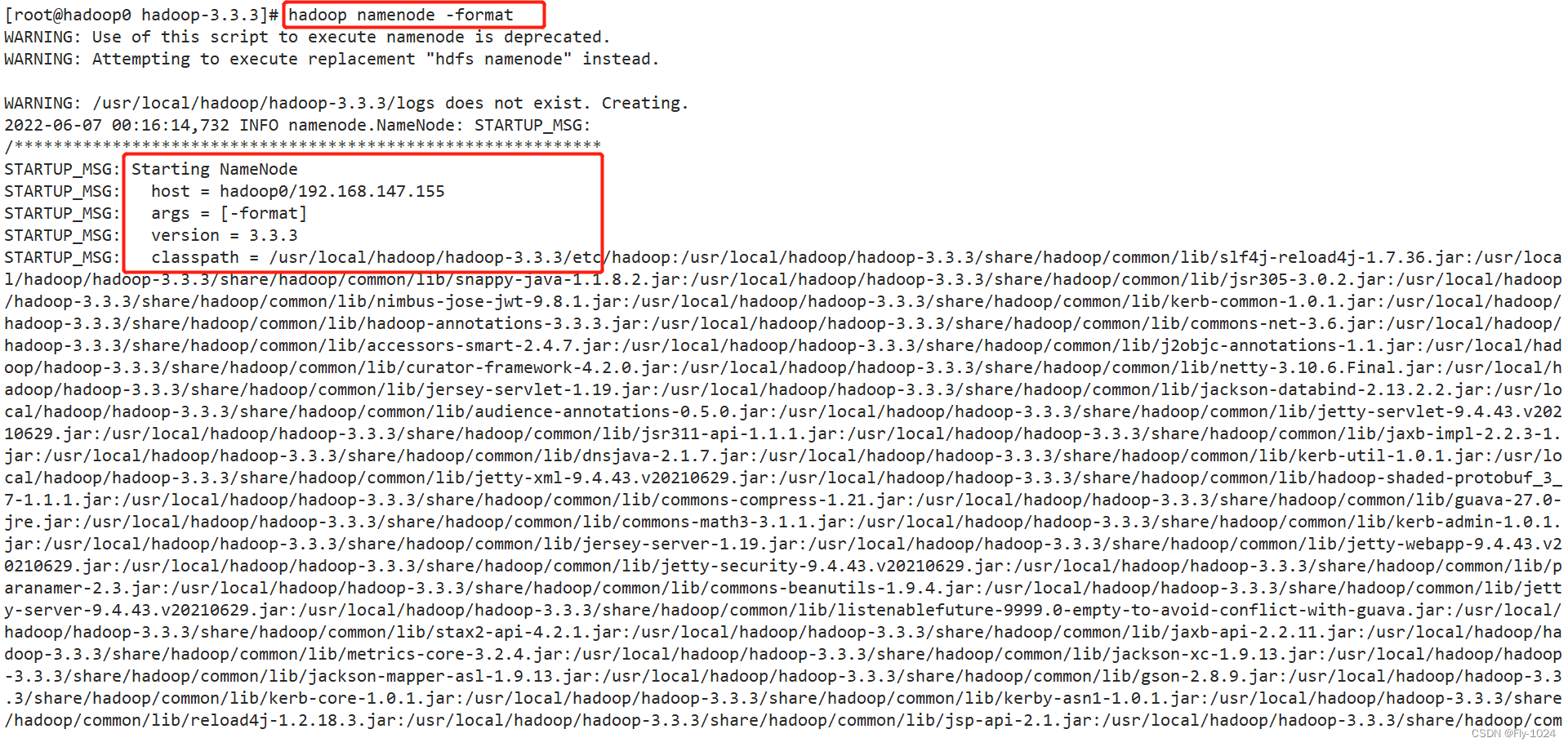
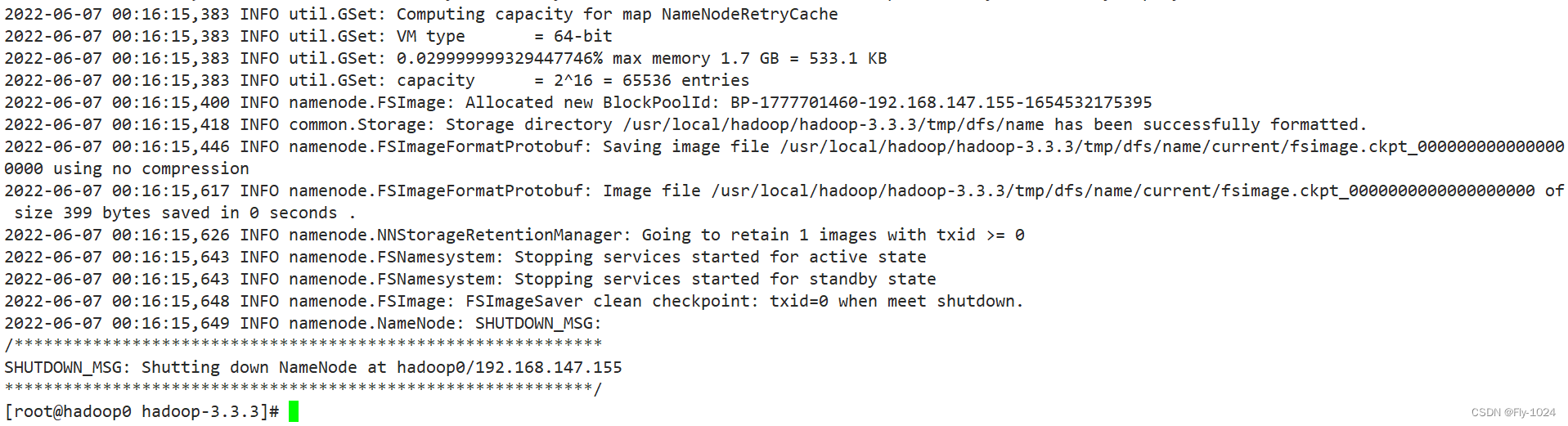
1.格式化
hadoop使用之前必须格式化,如果安装目录下已有data和logs目录,先删除
# 在hadoop0上面执行
hadoop namenode -format
- 1
- 2
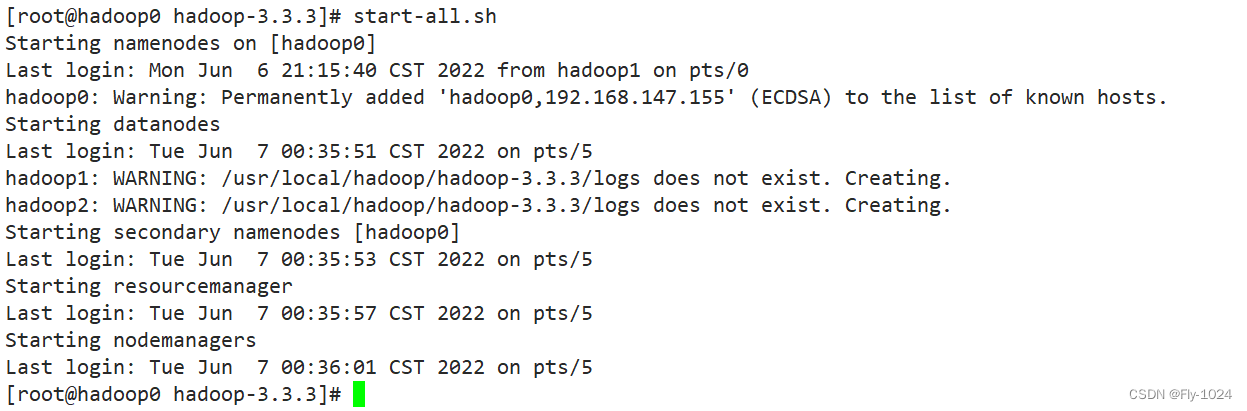
2.启动Hadoop
在主机hadoop0上面执行start-all.sh(位于sbin目录下)命令启动Hadoop的所有进程,停止所有进程可以使用stop-all.sh,执行结果如下:
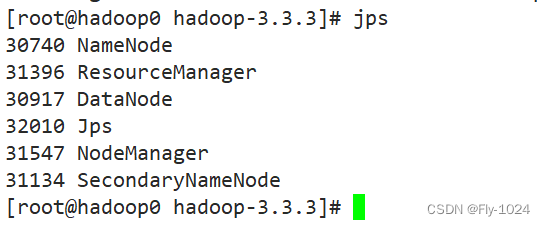
3.查看主从节点启动的相关进程情况
主节点hadoop0,启动了5个进程:
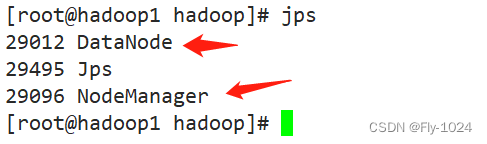
从节点hadoop1,hadoop2,都启动了NodeManager和DataNode两个进程

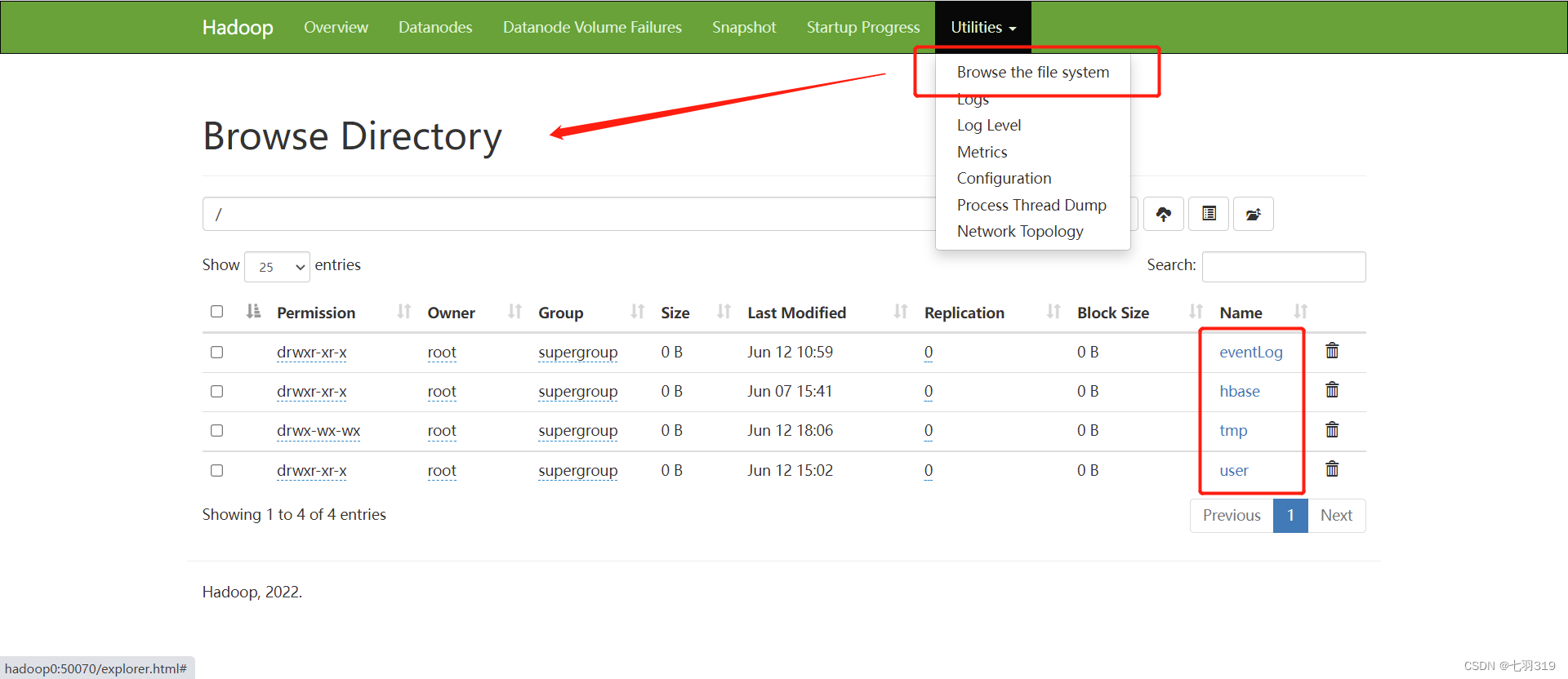
4.浏览HDFS文件
# 初始没有任何文件
hadoop fs ls /
- 1
- 2

5.浏览器访问hadoop
使用ip或域名(配置解析)浏览器中访问hadoop的web页面
http://192.168.147.155:50070/
或
http://hadoop0:50070/
- 1
- 2
- 3
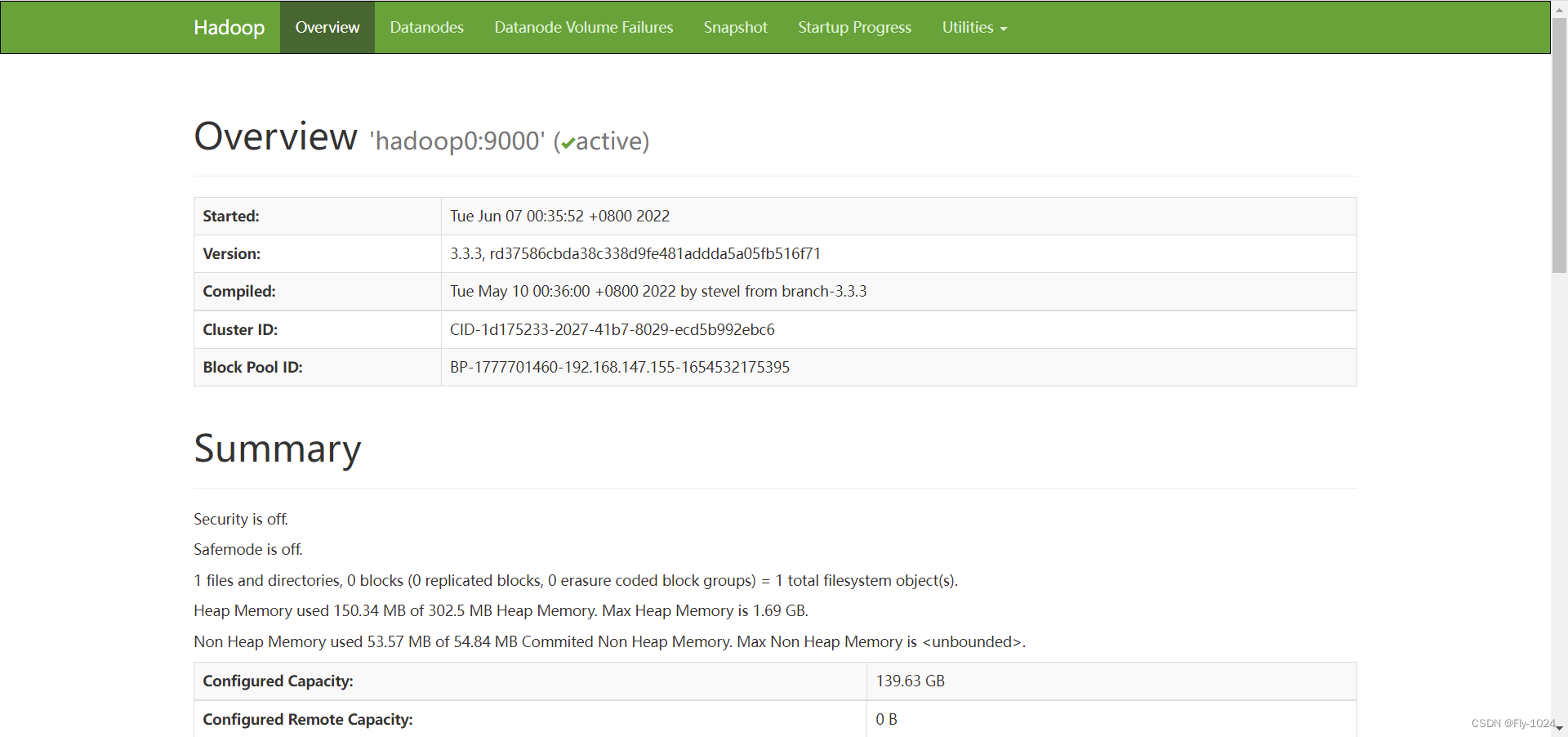
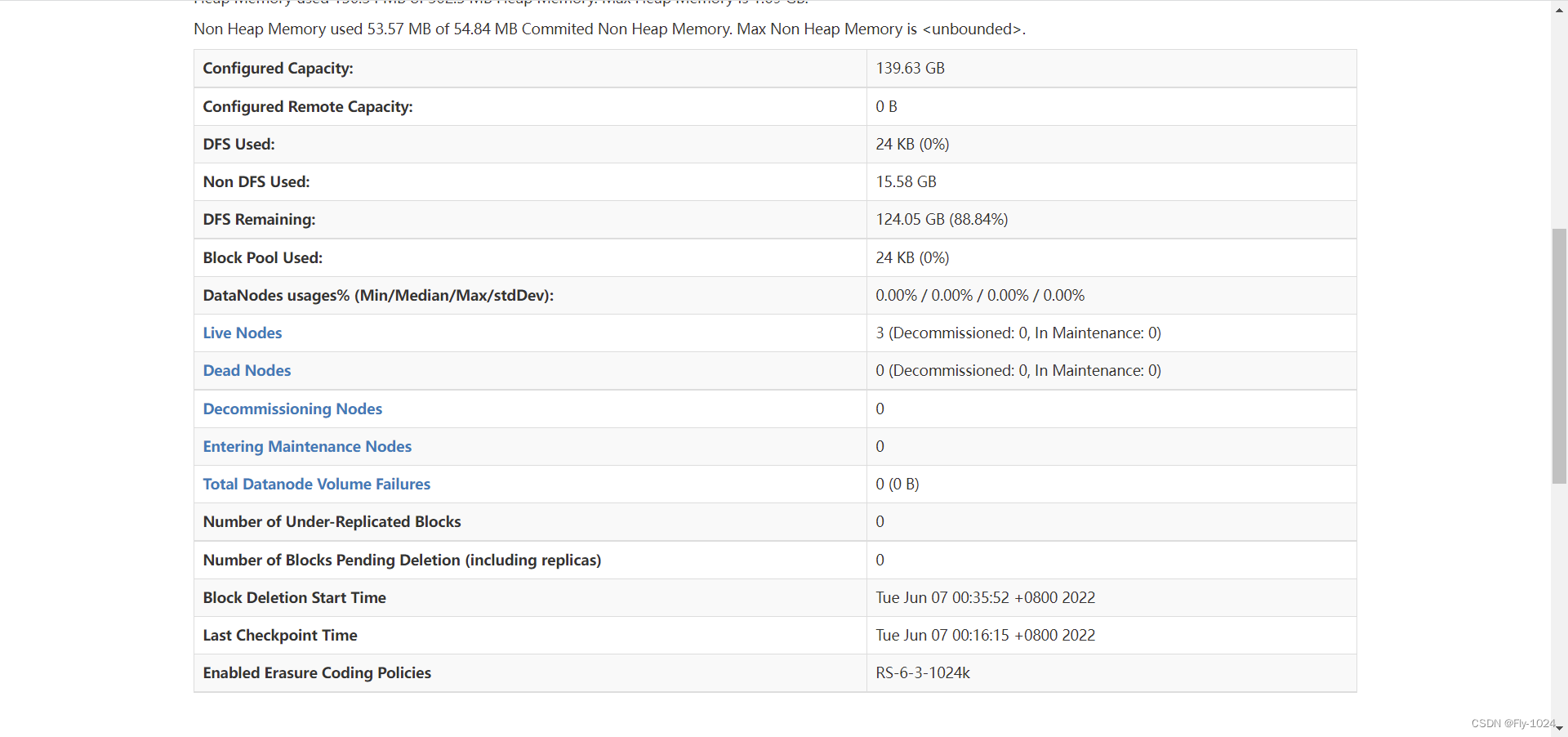
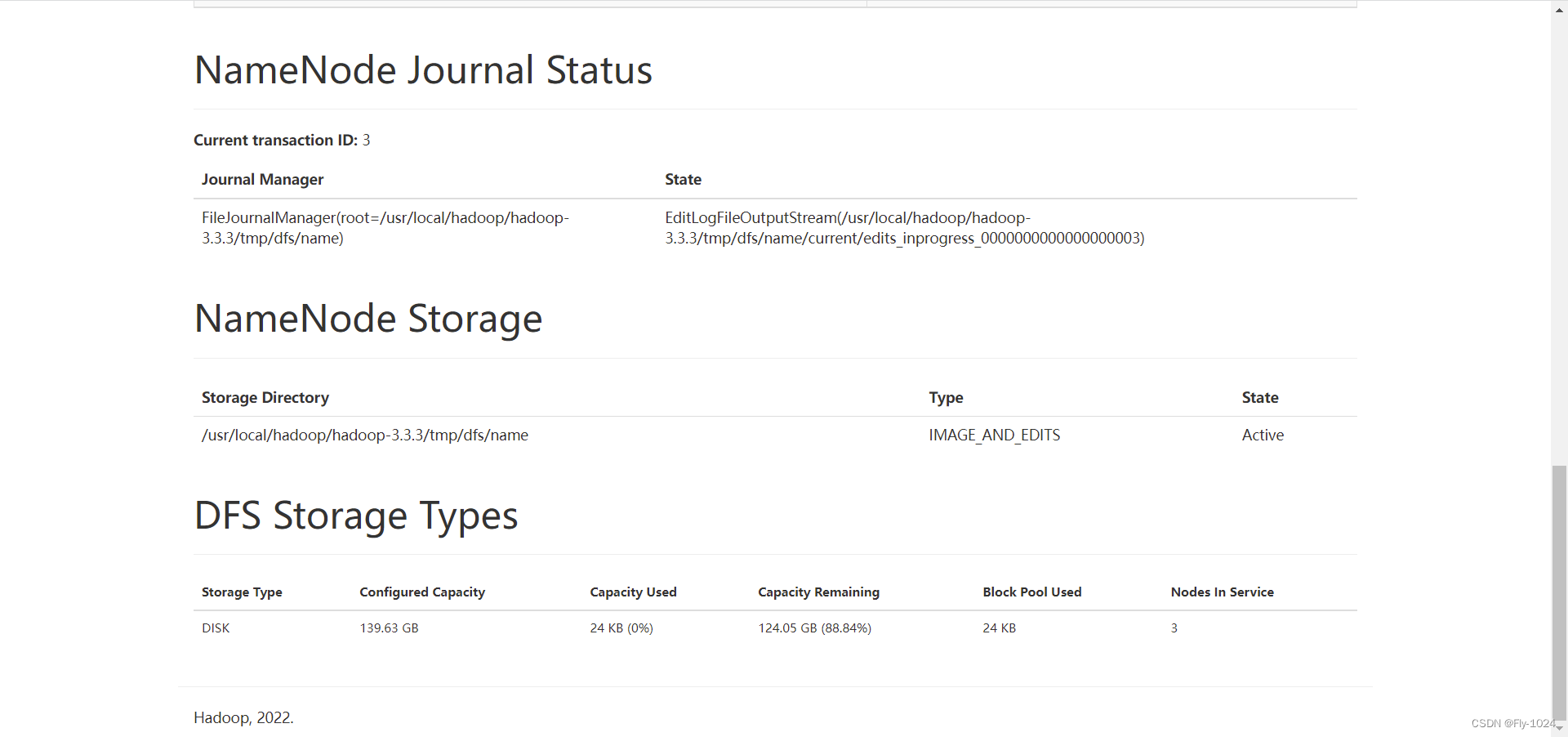
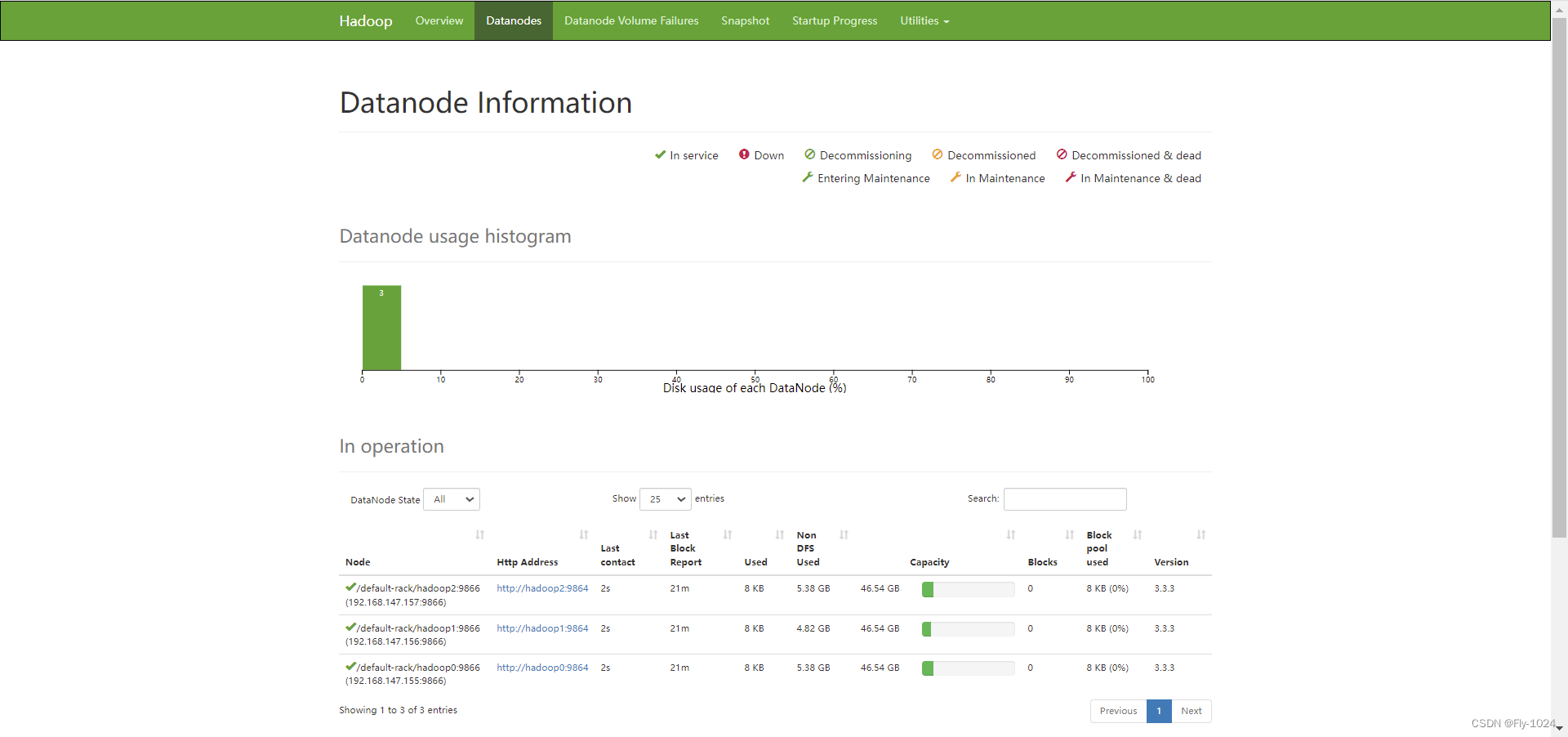
http://hadoop0:50070/explorer.html#/
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/632907
推荐阅读
相关标签

