
- 1VOC2007数据集下载、解压_vocdevkit数据集下载
- 2Numpy系统学习(五)数组元素运算_numpy数组取倒数运算的函数
- 3【AI大模型】从零开始运用LORA微调ChatGLM3-6B大模型并私有数据训练_chatglm3-6b 从mysql数据库获取数据
- 4mac vscode 怎么配置git密码_vscode git 密码
- 5方法汇总 | CSDN 提升原力等级及排名_csdn原力值怎么分级
- 6AI辅写疑似度检测软件:七款工具让你轻松应对_反ai写作检测工具
- 7AI的十大趋势如何?斯坦福《2024年人工智能指数报告》告诉你_斯坦福大学 李飞飞 《2024年人工智能指数报告》下载
- 8Spring Boot 中实现跨域的 5 种方式_springboot跨域配置
- 9混合A*算法(Hybrid A*)
- 10前端---git不会用?这一篇就够了!
hadoop问题小结_org.apache.hadoop.hdfs.blockmissingexception:
赞
踩
20220413
注意:windows上执行hdfs命令不成功
Cannot execute /usr/local/hadoop-3.2.2/libexec/yarn-config.sh
因为hadoop下的sbin目录没有加入到环境变量中
- 1
- 2
- 3
start-yarn.sh出错 ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
- 1
https://blog.csdn.net/qq_31945139/article/details/102766997
mapred --daemon start historyserver
mapred --daemon stop historyserver
停掉历史服务
hdfs --daemon start /stop datanode
单独启动datanode
yarn–daemon start /stop resource manager
集群崩溃
1.先删除所有节点上的logs文件夹
2.hdfs namenode -format
3.再重启
端口 8020 内部各节点之间的通信
9820 外部浏览器ui访问端口
20220406
从日志中可以看到错误是发生在/usr/lib/hadoop-3.1.0/etc/hadoop/mapred-site.xml文件,找到该文件,发现有两个configuration,但一般都只有一个,因此对其进行合并,如下。
https://blog.csdn.net/lucien7l/article/details/80781908
https://blog.csdn.net/qq_40285736/article/details/106690465
python读取hdfs,端口为web端口9870
hadoop3启动后没有namenode
https://blog.csdn.net/m0_67402026/article/details/123739570
https://blog.csdn.net/hmyqwe/article/details/117299345
hadoop常用端口
20220322
https://blog.csdn.net/lt5227/article/details/119459827
hadoop控制台设置密码 访问验证
20220314
进入hive
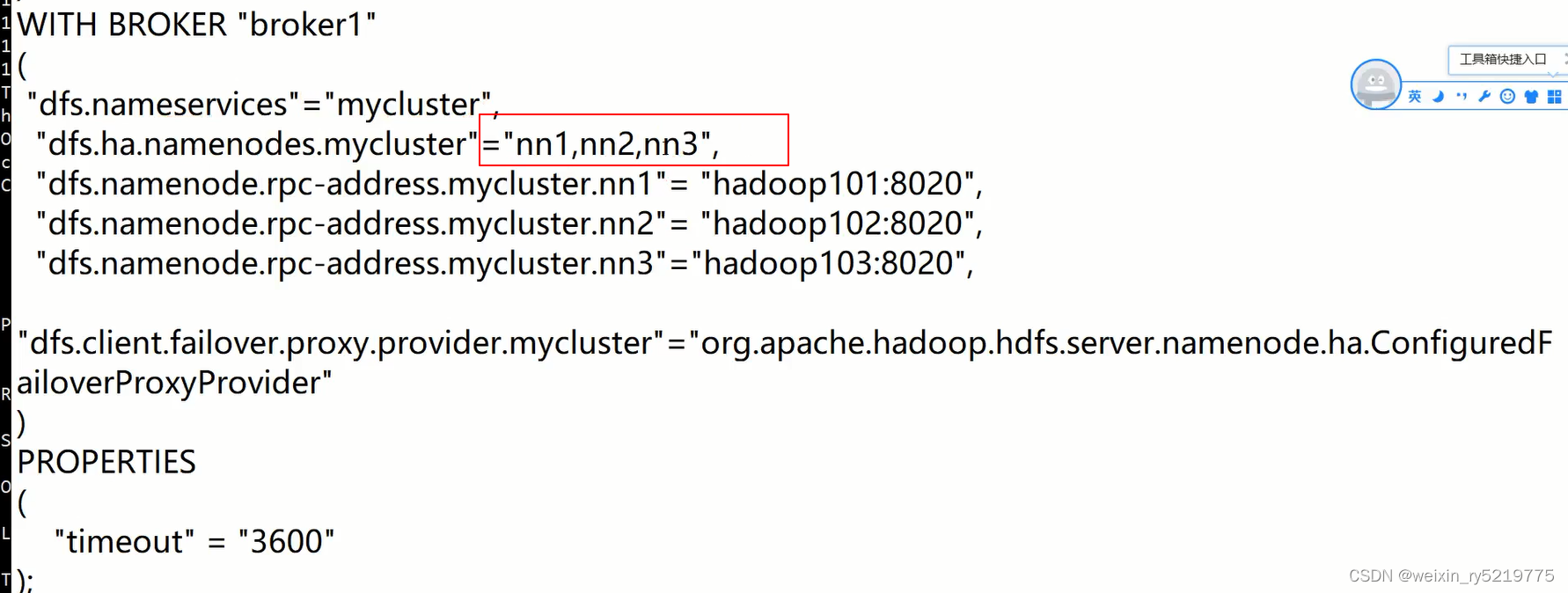 高可用三天都可以设置为namenode
高可用三天都可以设置为namenode
provider是HA的类
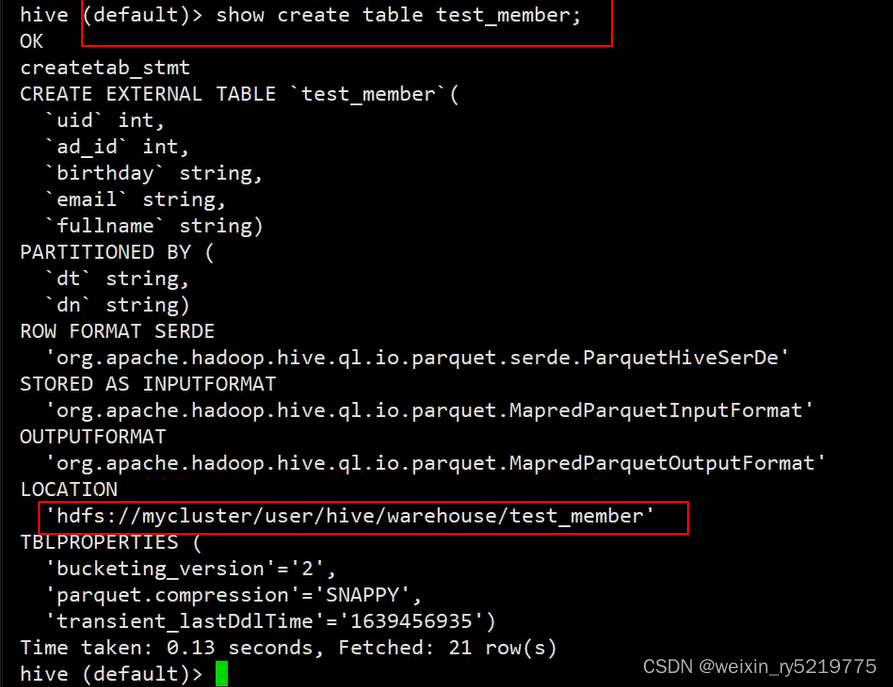
查看表存储的地址
20220306
No route to host
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /data/tb_order_user_sec_type_group.csv._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s) are excluded in this operation.
这两个错误都是因为datanode上的防火墙没关,所有节点上的防火墙都要关或者指定端口要打开
- 1
- 2
- 3
- 4
- 5
- 6
20220305
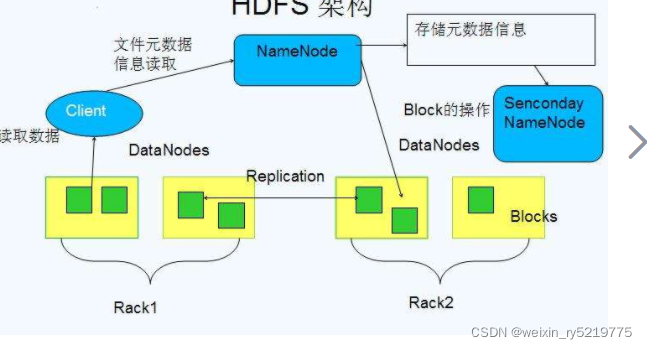
hdfs组件进程构成:管理数据 namenode(目录),secondary name node,datanode(实际文件)
yarn组件进程构成:管理资源调度 resource manager,node manager
hadoop2.x
20220304
http://192.168.1.122:50070/explorer.html#/data
2.7的ui端口
- 1
- 2
Could not obtain block: BP-10915069-192.168.1.122-1640768723000:blk_1073741844_1020 file=/data/tb_order_user_sec_type_group.csv
文件损坏,重新上传?
- 1
- 2
错误Name node is in safe mode的解决方法
https://blog.csdn.net/hu_belif/article/details/83312778
- 1
- 2
20220214
Exception in createBlockOutputStream java.net.noRouteToHostException: No route to host
https://blog.csdn.net/xtm_rongbing/article/details/22486363
关闭所有节点的防火墙
org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block:
https://blog.csdn.net/xiaozhaoshigedasb/article/details/88999595
20220207
由于Hive是针对数据仓库应用设计的,而数据仓库的仓库是读多写少,因此,Hive中不支持数据的改写和添加,所有数据都是加载的时候确定好的。而数据库中的数据通常要经常进行修改的,因此可以使用insert into 关键字添加数据,使用update …set修改数据,且仅支持覆盖重写整个表;
使用关键字clustered by 指定分区依据的列名及桶数
hive> hive.enforce.bucketiong=true;
hive> create table btest(id int,name string) clustered by(id) into 3 buckets row format delimited fields terminated by '\t';
- 1
- 2
20211231
下载文件到本地
11:get
使用方法:hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
示例:
hadoop fs -get /user/hadoop/file localfile
hadoop fs -get hdfs://host:port/user/hadoop/file localfile
返回值:
成功返回0,失败返回-1。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
What does "moveToLocal: Option '-moveToLocal' is not implemented yet." means?
hadoop2.7中这个命令还不可用
- 1
- 2
- 3
20211230
https://www.cnblogs.com/pengpp/p/9833349.html
python调用执行shell命令最简单
https://www.cnblogs.com/yang520ming/p/12886660.html
http://blog.sina.com.cn/s/blog_46dcac190102uxqr.html
filexistchk = "hadoop dfs -test -e " + hdfs_path + ";echo $?"
filexistchk_output = subprocess.Popen(filexistchk, shell=True, stdout=subprocess.PIPE).communicate()
if '1' not in str(filexistchk_output[0]): # 0是存在
return 1 # 存在
else:
return 0
##################
hadoop fs -test -e /path/exist
if [ $? -eq 0 ] ;then
echo 'exist'
else
echo 'Error! path is not exist'
fi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
判断hdfs文件是否存在 前面两个连接好像不起作用
https://blog.csdn.net/ahilll/article/details/83377387
python删除hdfs文件
hdfs://k8s04:9001/output/41_客户类型_关联规则.csv ;’
是在hdfs-site.xml里面配置
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>k8s04:9001</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
hdfs对应的物理路径在这里
spark的输入和输出都基于hadoop的hdfs上面hdfs不别 "."的当前目录 直接从根目录开始
/data
https://www.cnblogs.com/yifeiyu/p/11044290.html
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
hadoop命令
https://blog.csdn.net/beishanyingluo/article/details/102556752
https://www.cnblogs.com/biehongli/p/7463180.html
HDFS常用命令(总结) 重点
1.查看hdfs下根目录下的文件
hdfs dfs -ls /
- 1
- 2
6.hdfs文件移动到本地:
hdfs dfs -moveToLocal /test/test123/hellow.txt /opt/hadoop/servers/
- 1
- 2
8.将本地文件放到hdfs某个目录:
hdfs dfs -put /opt/hadoop/servers/test/ /tmp/
- 1
- 2
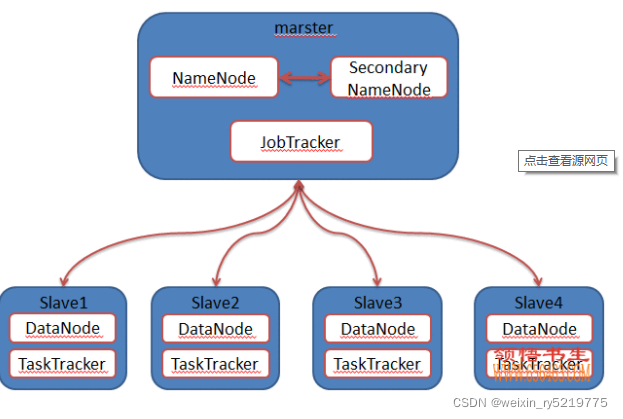
https://blog.csdn.net/stars_tian/article/details/78744500
https://www.yisu.com/zixun/61687.html
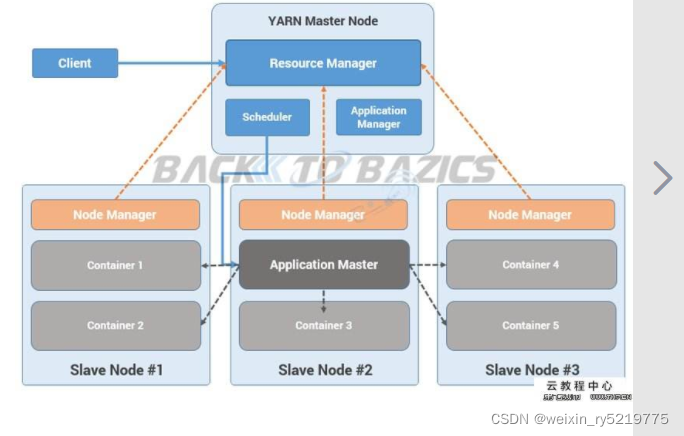
Hadoop五个进程的作用和联系
https://jingyan.baidu.com/article/86fae34614a1c53c49121a3a.html
执行 ./start-all.sh 可以启动hadoop了
在使用完毕后执行./stop-all.sh即可关闭Hadoop。
20211229
path does not exist hdfs://k8s04:9001/usr/root/xxx.csv
现在hdfs上新建 /data文件夹
hdfs dfs -mkdir /data
然后上传本地文件到hdfs
hdfs dfs -put /home/guanlian_algo_confirm2/tb_order_user_sec_type_group.csv /data
hadoop控制台
http://192.168.1.122:50070/explorer.html#/data
2.7版本
http://192.168.1.122:8088/cluster/scheduler

