
- 1php问答系统模板,tipask问答系统模板资料对照
- 2熬了一晚上,我从零实现了Transformer模型,把代码讲给你听
- 3解决stable diffusion webui1.6 wd1.4 tagger加载失败的问题_wd1.4标签器错误
- 4【WPF专题 】如何自定义控件_wpf自定义控件
- 5(二十三)Java工具类ToStringBuilder方法详解_tostringbuilder java
- 6Python爬取某二手房官网某地区二手房的数据【附加源码】_安家居二手房python爬虫代码
- 7蓝易云 - Kubernetes的DaemonSet详解
- 8Python全栈开发前端与后端的完美融合_前端与python结合
- 9win10修改conda环境和缓存默认路径
- 10AI绘画Stable Diffusion【ControlNet】:使用InstantID插件实现人物角色一致性_idcontrolnet
机器翻译的流程(原理)是怎么样的?_基于规则的机器翻译工作原理
赞
踩
目前最重要的两种机器翻译方式:规则法和统计法
1. 规则法(rule based machine translation, RBMT),依据语言规则对文本进行分析,再借助计算机程序进行翻译。多数商用机器翻译系统采用规则法。
规则法机器翻译系统的运作通过三个连续的阶段实现:分析,转换,生成,根据三个阶段的复杂性分为三级。
- 直接翻译:简单的词到词的翻译。
- 转换翻译:翻译过程要参考并兼顾到原文的词法、句法和语义信息。因为信息来源范围过于宽泛,语法规则过多且相互之间存在矛盾和冲突,转换翻译较为复杂且易出错。【别说转换了,光是根据各种语法规则,对源语言进行分析都会崩溃好吗!
- 国际语翻译:迄今为止,还只是设想。大概是想凭借通用的完全不依赖语言的形式,实现对语言信息的解码。【国际语本身就是人工语言啊,还怎么做到不依赖语言形式。这个想法最早出现在13世纪orz
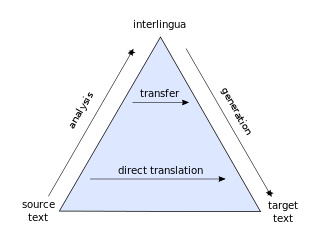 Bernard Vauquois' pyramid
Bernard Vauquois' pyramid
2. 统计法 (statistical machine translation, SMT),通过对大量的平行语料进行统计分析,构建统计翻译模型(词汇、比对或是语言模式),进而使用此模型进行翻译,一般会选取统计中出现概率最高的词条作为翻译,概率算法依据贝叶斯定理。假设要把一个英语句子A翻译成汉语,所有汉语句子B,都是A的可能或是非可能的潜在翻译。Pr(A)是类似A表达出现的概率,Pr(B|A)是A翻译成B出现的概率。找到两个参数的最大值,就能缩小句子及其对应翻译检索的范围,从而找出最合适的翻译。
SMT根据文本分析程度级别的不同分为两种:基于词的SMT和基于短语的SMT,后一个是目前普遍使用的,Google用的就是这种。翻译文本被自动分为固定长度的词语序列,再对各词语序列在语料库里进行统计分析,以查找到出现对应概率最高的翻译。【所以,不要嫌弃谷歌翻译啦,如果不是依托于它自己强大的搜索引擎,能获取相对数量的语料库,翻译的质量可能更糟,可以对比必应和百度。非在线的开源机器翻译也有做得很棒的,多也是使用的统计法模式。
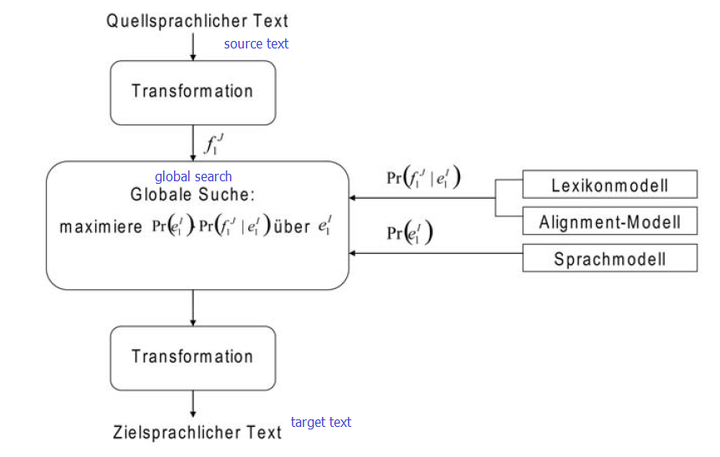
其他方式还有如范例法(example based machine translation, EBMT),类似统计法原理,不同的点在于比对对象是相对小型的语料库,从中找到对应的翻译片段的类似范例,再用片段组成相应的翻译;上下文法(context based machine translation, CBMT);知识法(knowledge based machine translation, KBMT)和混合法,但是不及前面两种使用率高。
刚好这两天在看Daniel Stein写的MT概述"Maschinelle Übersetzung – ein Überblick",有提到机器翻译的不同类型和原理,以上。链接:知乎专栏
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
原文:Adam Geitgey
翻译:巡洋舰科技——赵95
你是不是看烦了各种各样对于深度学习的报导,却不知其所云?我们要来改变这个问题。
有趣的机器学习 前六章已更新!点此查看第一章:最简明入门指南、第二章:用机器学习【制造超级马里奥】的关卡、第三章:图像识别【鸟or飞机】第四章:用深度进行【人脸识别】第五章:使用深度学习进行【语言翻译】和 序列的魔力第六章:如何用深度学习进行【语音识别】
我们都知道并且喜欢使用Google翻译,这个网站可以瞬时翻译100种不同的人类语言,就好像有魔法一样。他甚至存在于我们的手机和智能手表上面:(知乎无法上传太大的GIF,看图请戳原文)
Google翻译背后的科技被称为机器翻译。它改变了世界,在本来根本不可能的情况下让(不同语言的)人们完成了沟通。
但我们都知道,在过去的15年里,高中学生已经使用Google翻译...额 ...协助他们完成他们的西班牙语作业。这已经不是新闻了…?
<img src="https://pic3.zhimg.com/50/v2-a9fcbd775a70567a8d49ea73e42f4358_hd.jpg" data-rawwidth="853" data-rawheight="192" class="origin_image zh-lightbox-thumb" width="853" data-original="https://pic3.zhimg.com/v2-a9fcbd775a70567a8d49ea73e42f4358_r.jpg">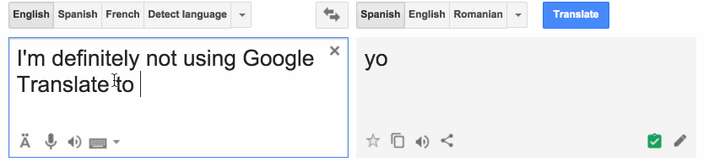
事实证明,在过去两年,深度学习已经完全改写了我们的机器翻译方法。那些对语言翻译一无所知的深度学习研究人员正在利用一个个相对简单的机器学习解决方案,来打败世界上最好的专家建造的语言翻译系统。
这一突破背后的技术被称为序列到序列学习sequence to sequence learning。这是一项非常强大的技术,被用于解决许多种类的问题。在我们看到它如何被用于翻译之后,我们还将学习这个算法是怎样用来编写AI聊天机器人和描述图片的。
我们开始吧!
让计算机翻译
那么我们该如何编写代码,才能让计算机翻译人类的语言呢?
最简单的方法,就是把句子中的每个单词,都替换成翻译后的目标语言单词。这里有一个简单的例子,把西班牙语逐字翻译成英语:
<img src="https://pic2.zhimg.com/50/v2-db380a8bf032afa9533d358389de99d6_hd.jpg" data-rawwidth="1000" data-rawheight="180" class="origin_image zh-lightbox-thumb" width="1000" data-original="https://pic2.zhimg.com/v2-db380a8bf032afa9533d358389de99d6_r.jpg">
我们只是用匹配的英语单词替换每个西班牙单词。
这很容易实现,因为你所需要是一本字典来查找每个单词的翻译。但结果并不好,因为它忽略了语法和上下文的联系。
因此,下一件你可能要做的事,就是开始添加特定语言规则以改进结果。例如,你可能将两个常用词翻译为词组。你可能互换名词和形容词的顺序,因为他们在西班牙语中以相反的顺序出现:
<img src="https://pic2.zhimg.com/50/v2-bed5ad249e62bea5ac3958c725dd0160_hd.jpg" data-rawwidth="1000" data-rawheight="250" class="origin_image zh-lightbox-thumb" width="1000" data-original="https://pic2.zhimg.com/v2-bed5ad249e62bea5ac3958c725dd0160_r.jpg">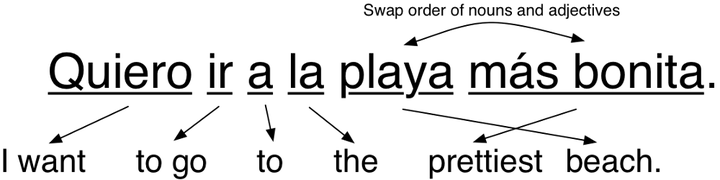
这真的有效!如果我们就继续添加更多的规则,直到我们可以应对每一部分语法,我们的程序应该就能够翻译任何句子了,对吧?
这就是最早的机器翻译系统的工作原理。语言学家提出了许多复杂的规则,并逐一编程实现。一些世界上最聪明的语言学家在冷战期间辛勤努力了多年,才创建出了一些更容易理解俄罗斯人交流的翻译系统。
不幸的是,这种套路只对简单问题适用,比如说像天气预报这样结构简单的文档。它对于真实世界的文字来说并不可靠。
问题是,人类语言并不总是遵循固定的规则。人类语言充满了各种特殊情况,区域差异,或者干脆就不按套路出牌(#‵′)凸。我们说英语的方式更多地受到几百年前入侵的人的影响,而不是由坐下来定义语法规则的人。
利用统计数据使计算机更好地翻译
在基于规则的系统失效之后,一些新的翻译方法被开发出来了,他们基于概率和统计的模型而不是语法规则。
建造一个基于统计的翻译系统需要大量的训练数据,其中完全相同的文本被翻译成至少两种语言。这种双重翻译的文本称为平行语料库parallel corpora。18世纪的科学家以同样的方式在罗塞塔石碑上面从希腊语中找出埃及象形文字。(译者注:罗塞塔石碑,高1.14米,宽0.73米,制作于公元前196年,刻有古埃及国王托勒密五世登基的诏书。石碑上用希腊文字、古埃及文字和当时的通俗体文字刻了同样的内容,这使得近代的考古学家得以有机会对照各语言版本的内容后,解读出已经失传千余年的埃及象形文之意义与结构,而成为今日研究古埃及历史的重要里程碑)以同样的方式,计算机可以使用平行语料库猜测如何将文本从一种语言转换为另一种语言。
幸运的是,有很多双重翻译的文本已经存在在世界的各个角落。例如,欧洲议会将其诉讼程序翻译成21种语言。因此,研究人员经常使用这些数据来帮助建造翻译系统。
<img src="https://pic3.zhimg.com/50/v2-8405085e2a71fe599a8a0365b8a61596_hd.jpg" data-rawwidth="1000" data-rawheight="167" class="origin_image zh-lightbox-thumb" width="1000" data-original="https://pic3.zhimg.com/v2-8405085e2a71fe599a8a0365b8a61596_r.jpg">
训练数据通常令人兴奋!但这只是无数条政府文件而已...
用概率的思维思考
统计翻译系统的根本不同,在于它们试图生成不止一个精确的翻译。相反,他们生成成千上万种可能的翻译,然后他们按照可能最正确的给这些翻译排名。他们通过与训练数据的相似性来估计有多“正确”。以下是它的工作原理:
第1步:将原始句子分成块
首先,我们将我们的句子分成简单的块,每一块都可以轻松翻译:
<img src="https://pic2.zhimg.com/50/v2-ec2cc836a5ae27ee35ed01a912036d31_hd.jpg" data-rawwidth="1000" data-rawheight="87" class="origin_image zh-lightbox-thumb" width="1000" data-original="https://pic2.zhimg.com/v2-ec2cc836a5ae27ee35ed01a912036d31_r.jpg">
第2步:找到每一块的所有可能的翻译
接下来,我们将翻译每块文字,我们将通过寻找我们数据库中所有人类翻译过的相同词块来完成我们的翻译。
要着重注意的是,我们不只是在一本简简单单的翻译字典中查找这些词块。相反,我们看到是真实的人在真实的句子中如何翻译这些相同的词。这有助于我们捕获到在不同语境中所有不同的表达方式:
<img src="https://pic4.zhimg.com/50/v2-4a56bab19fc10b4fd4f52cc2cf9351b5_hd.jpg" data-rawwidth="1000" data-rawheight="471" class="origin_image zh-lightbox-thumb" width="1000" data-original="https://pic4.zhimg.com/v2-4a56bab19fc10b4fd4f52cc2cf9351b5_r.jpg">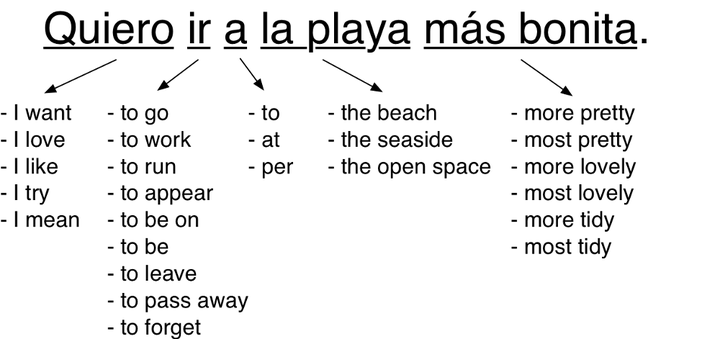
即使最常见的短语也有很多种可能的翻译
这些可能的翻译中的有一些会比其他翻译更频繁地使用。根据我们训练数据中每个翻译出现的频率,我们可以给它设定一个分数。
例如,有人说“Quiero”更多的时候是指“我想要”而不是“我尝试”。所以,我们可以使用我们训练数据中 “Quiero”被翻译成“我想要”的频率,给“我想要”这个翻译更多的权重。
第3步:生成所有可能的句子,找到最有可能的那句
接下来,我们将使用这些词块的每种可能翻译来组合生成一堆可能的句子。
从第二步中列出的翻译过的词块中,我们可以通过不同组合方式生成将近2,500个不同的句子。下面是一些例子:
I love | to leave | at | the seaside | more tidy.
I mean | to be on | to | the open space | most lovely.
I like | to be |on | per the seaside | more lovely.
I mean | to go | to | the open space | most tidy.
但在真实世界中,因为有不同的语序和词块分解方法,所以实际上有更多可能的词块组合:
I try | to run | at | the prettiest | open space.
I want | to run | per | the more tidy | open space.
I mean | to forget | at | the tidiest | beach.
I try | to go | per | the more tidy | seaside.
现在需要扫描所有这些生成的句子,找到那个听起来“最像人话”的句子。
为此,我们将每个生成的句子与来自英语书籍和新闻故事的数百万个真实句子进行比较。我们拥有的英语文本越多越好。
我们采用这种可能的翻译:
I try | to leave | per | the most lovely | open space.
很可能没有人用英语写过这样的句子,所以它不会与我们的数据库任何句子非常相似。我们给这个可能的翻译设定一个低概率的得分。
但看看下面这个可能的翻译:
I want | to go | to | the prettiest | beach.
这个句子和我们的训练集中的句子很类似,所以它将获得一个高概率的得分。
在尝试过所有可能的句子之后,我们会选择那个,既是最有可能的词块翻译,又与真实英语句子最相似,的句子。
我们最后的翻译将是“I want | to go | to | the prettiest | beach.
我想去最漂亮的海滩。”不错!
有里程碑意义的统计机器翻译
当有足够多的训练数据的时候,统计机器翻译系统的性能要优于基于语言规则的系统。 Franz Josef Och基于这些想法并做出了改进,并在21世纪初使用它们构建了Google翻译。机器翻译终于可以被全世界使用。
早期的时候,基于概率翻译的“愚蠢”方法居然比语言学家设计规则系统做的更好,这让每个人都感到惊讶。这导致了80年代的时候,研究人员会(有点刻薄的)说:
“每当我炒了一个语言学家鱿鱼的时候,我的翻译准确度就会上升。” Frederick Jelinek
统计机器翻译的局限性
虽然统计机器翻译系统效果还不错,但是他们难于构建和维护。每一对需要翻译的新语言,都需要专业人士对一个全新的多步骤“翻译流水线”进行调试和修整。
因为构建这些不同的流水线需要做太多工作,所以我们必须进行权衡。如果你要用Google翻译把格鲁吉亚语翻译成泰卢固语(印度东部德拉维拉语言),那么作为一个中间步骤,它必须先翻译成英语。因为并没有太多格鲁吉亚到泰卢固语的翻译需求,所以在这一对语言上投入太多并没有太大意义。相比于英语翻译到法语,它可能会使用一个更低级的“翻译流水线”。
如果我们能让计算机为我们做所有令人讨厌的开发工作,这不更好么?
让电脑翻译的更好——无需昂贵的专家们
机器翻译的核心是一个黑盒系统,它通过查看训练数据,自己就可以学习如何翻译。使用统计机器翻译,人们仍然需要建立和调整多步骤的统计模型。
2014年,KyungHyun Cho的团队取得了突破。他们发现了一种应用深度学习来构建这种黑盒系统的方法。他们的深度学习模型采用平行语料库,并使用它来学习如何在无任何人为干预的情况下在这两种语言之间进行翻译。
两个宏伟的方法使这成为可能 - 循 环神经网络和编码。通过巧妙地结合这两个想法,我们可以建立一个能够自学的翻译系统。
循环神经网络
我们已经在第2章讨论过了循环神经网络,让我们快速回顾一下。
一个常规(非循环)神经网络是泛型机器学习算法,接收一序列数字并计算结果(基于先前的训练)。神经网络可以用作一个黑盒子,来解决很多问题。例如,我们可以基于房子的属性,使用神经网络来计算房屋的近似价格:
<img src="https://pic3.zhimg.com/50/v2-6ea7212dd6e34f5ed60eec35acb7c756_hd.jpg" data-rawwidth="860" data-rawheight="389" class="origin_image zh-lightbox-thumb" width="860" data-original="https://pic3.zhimg.com/v2-6ea7212dd6e34f5ed60eec35acb7c756_r.jpg">
但是像大多数机器学习算法一样,神经网络是无状态(Stateless)的。你输入一序列数字,神经网络计算并输出结果。如果再次输入相同的数字,它总是计算出相同的结果。它没有进行过的计算的记忆。换句话说,2 + 2总是等于4。
一个循环神经网络(Recurrent Neural Network或简称RNN)是一个稍微改进过的神经网络的版本,区别是RNN先前的状态是可以被当做输入,再次带入到下一次计算中去。这意味着之前的计算结果会更改未来计算的结果!
<img src="https://pic4.zhimg.com/50/v2-d164b6165ed48bef689a837f6a70aca0_hd.jpg" data-rawwidth="860" data-rawheight="556" class="origin_image zh-lightbox-thumb" width="860" data-original="https://pic4.zhimg.com/v2-d164b6165ed48bef689a837f6a70aca0_r.jpg">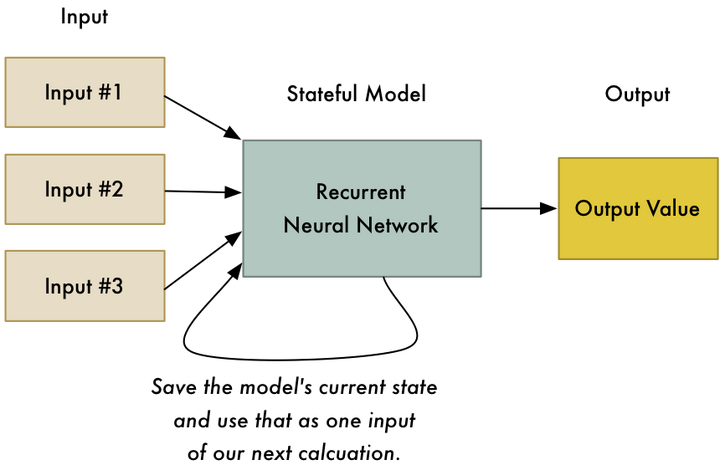
人类痛恨他:一个黑科技就让机器变得更聪明!
我们为什么要这样做?无论我们上次计算结果是什么,2 + 2不应该总是等于4么?
这个技巧允许神经网络学习数据序列中的规律。例如,基于句子的前几个词,你可以使用它来预测句子中下一个最有可能的单词是什么:
<img src="https://pic2.zhimg.com/50/v2-4c999bbcdf7e7ce9a691ce76438064de_hd.jpg" data-rawwidth="887" data-rawheight="530" class="origin_image zh-lightbox-thumb" width="887" data-original="https://pic2.zhimg.com/v2-4c999bbcdf7e7ce9a691ce76438064de_r.jpg">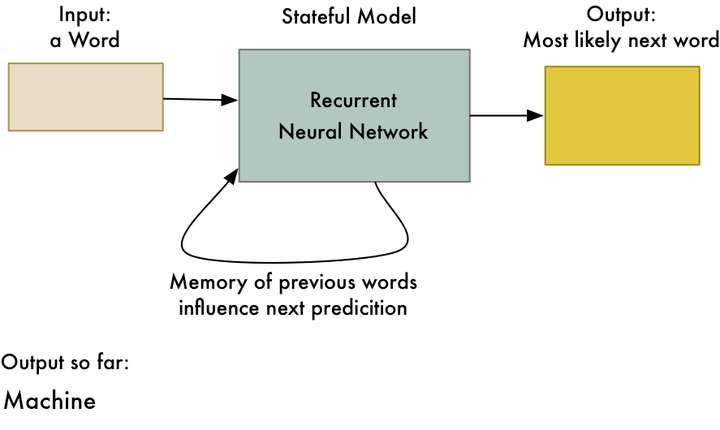
实现智能手机输入法的“自动更正”的方法之一…
当你想要学习数据中的规律时,RNN将会非常有用。因为人类语言其实只是一个大而复杂的“规律”,自然语言处理的各个领域越来越多地使用RNN。
如果你想了解更多关于RNN,你可以阅读第2章,我们使用了RNN来生成一本海明威写作风格的假书,然后使用同一个RNN生成了超级马里奥兄弟的游戏关卡。
编码
我们需要回顾的另一个想法是编码Encoding。在第4章中作为脸部识别的一部分,我们谈到了编码。为了解释编码,让我们稍作调整,了解一下如何用电脑区分两个人。
当你试图用电脑区分两张脸时,你从每张脸收集不同的测量值,并与其他脸部比较这些测量值。例如,我们可以测量耳朵的大小或眼间的间距,比较两个图片的测量值以确定他们是否是同一个人。
你可能已经从观看热门影视剧CSI当中对这个想法耳熟能详了(知乎无法上传太大的GIF,看图请戳原文)。
把面部特征转换为一系列测量值的想法就是编码的例子之一。我们获取到原始数据(面部图片),并将其转换为代表这张脸的一系列测量值(编码)。
但是像我们在第4章中看到的,我们不必提出一个具体的面部特征列表来测量我们自己。相反,我们可以使用神经网络,让它自动从面部生成测量值。找出哪些测量值能够区分两个相似的人,计算机在这方面比我们做的更好:
<img src="https://pic1.zhimg.com/50/v2-6e2b5cfcbd33b1105a4d8d40191c162d_hd.jpg" data-rawwidth="1000" data-rawheight="499" class="origin_image zh-lightbox-thumb" width="1000" data-original="https://pic1.zhimg.com/v2-6e2b5cfcbd33b1105a4d8d40191c162d_r.jpg">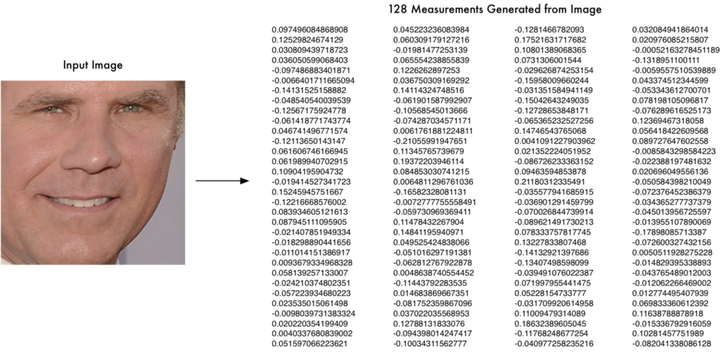
这些是由神经网络产生的面部特征测量值,训练后的该神经网络可以保证不同的数字代表了不同人的面部。
这是我们的编码。它让我们用简单的东西(128个数字)代表非常复杂的东西(一张脸的图片)。现在比较两张脸更加容易了,因为我们只需要比较这128个数字而不是比较整张脸的图像。
你猜怎么着?我们可以用句子做同样的事情!我们可以把任何一个句子表达成一系列独特的编码:
<img src="https://pic3.zhimg.com/50/v2-4fa1d6823b59d61bc84d290f4cf8adeb_hd.jpg" data-rawwidth="1000" data-rawheight="479" class="origin_image zh-lightbox-thumb" width="1000" data-original="https://pic3.zhimg.com/v2-4fa1d6823b59d61bc84d290f4cf8adeb_r.jpg">
这一序列数字代表的是英语句子“有趣的机器学习!”。不同的句子将由不同的数字集表示。
为了生成这个编码,我们将句子输入到RNN中,一次一个词。最后一个词处理之后的最终结果,就将是表示整个句子的数值:
<img src="https://pic3.zhimg.com/50/v2-520f649f58b1d522f1c38ff49153c590_hd.jpg" data-rawwidth="877" data-rawheight="395" class="origin_image zh-lightbox-thumb" width="877" data-original="https://pic3.zhimg.com/v2-520f649f58b1d522f1c38ff49153c590_r.jpg">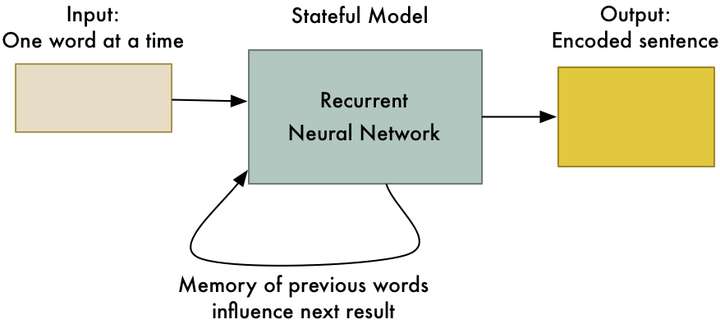
因为RNN具有记忆功能,能够记住处理过得每个词,所以它计算的最终编码表示句子中的所有词。
棒极了,所以现在我们有一种方法来把一个整个句子表示成一组独特的数字!我们不知道编码中的每个数字是什么意思,但这并不重要。只要每一句话都能由一组独特的数字标识出来,那么我们就不需要准确地知道这些数字是如何生成的。
让我们开始翻译吧!
好的,所以我们知道怎样使用RNN去个一句话编码并生成一组独特的数字。它有什么用呢?事情从这儿开始变得酷炫了!
如果我们使用两个RNNs并将它们首尾相连呢?第一个RNN可以给句子生成编码。然后,第二RNN遵循相反的逻辑,解码得到原始句子:
<img src="https://pic3.zhimg.com/50/v2-473f0ea39bfa46879f0975c77272b8c8_hd.jpg" data-rawwidth="1250" data-rawheight="336" class="origin_image zh-lightbox-thumb" width="1250" data-original="https://pic3.zhimg.com/v2-473f0ea39bfa46879f0975c77272b8c8_r.jpg">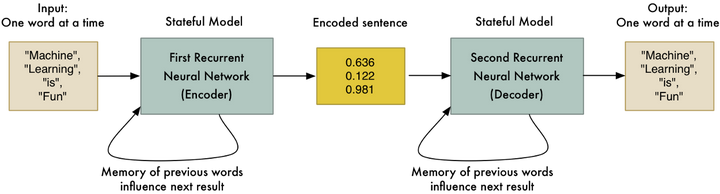
当然,编码然后再解码并得到原始语句并没有太大用处。但是如果(这里是问题的关键),我们训练第二个RNN,使它解码成西班牙语而不是英语,这会怎样?我们可以使用平行语料库训练数据来训练它:
<img src="https://pic4.zhimg.com/50/v2-04ff81324066f8cc916e3b9773808cc9_hd.jpg" data-rawwidth="1250" data-rawheight="334" class="origin_image zh-lightbox-thumb" width="1250" data-original="https://pic4.zhimg.com/v2-04ff81324066f8cc916e3b9773808cc9_r.jpg">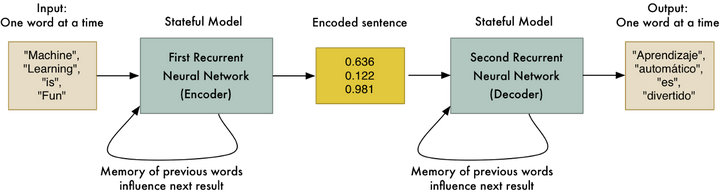
就像这样,我们有一个通用的方法,将一序列英语单词转换成同样的西班牙语单词序列!
这是一个强有力的想法:
l 这种方法主要受限于你拥有的训练数据量和你可以投入的计算机生产力。机器学习研究人员仅仅在在两年前发明了这个方法,但它已经表现的和统计机器翻译系统一样好了,而后者花了20年时间才开发完善。
l 这不依赖于任何关于人类语言规则的了解。算法自己计算出这些规则。这意味着你不需要专业人士来调整“翻译流水线”的各个步骤,计算机为你把这个做好了。
l 这种方法适用于几乎任何种类的序列到序列sequence-to-sequence问题!而且事实证明,许多有趣的问题都实际上是 序列到序列的问题。继续阅读了解其他你可以做的酷炫的事!
注意,我们忽略了一些处理真实数据会碰到的问题。例如,如何处理不同长度的输入和输出?这还需要一些额外的工作(请参见bucketing和padding)。非常用词翻译也是一个问题。
构建你自己的序列到序列翻译系统
如果你想建立自己的语言翻译系统,这儿有一个包括可以在英语和法语之间翻译的TensorFlow的demo。然而,这并不是给胆小鬼或预算有限的人准备的。这仍然是一项新技术,并且资源有限。即使你有一台带有高级显卡的高级电脑,可能也需要连续一个月的时间来训练你自己的语言翻译系统。
此外,序列到序列语言翻译技术正在及快速地改进,以至于难以跟上。许多最近的改进(如添加注意机制attention mechanism或上下文跟踪tracking context)显着改善了翻译结果,但这些发展太过前沿,以至于他们甚至还没有维基百科页面。如果你想做认真的去做任何序列到序列学习,随着技术的发展,你需要持续保持更新,。
序列到序列模型的无穷力量
那么,我们还能用序列到序列模型做什么呢?
大约一年前,Google的研究人员表示,你可以使用序列到序列模型来建造AI机器人。这个想法是如此简单,并且令人震惊的是,它真的有效。
首先,他们获取了一些Google员工和Google技术支持小组之间的聊天记录。然后他们训练了序列到序列模型,其中输入的句子就是雇员的问题,而技术支持团队的回复是该句子的“翻译”。
<img src="https://pic2.zhimg.com/50/v2-b0e96c4e8b2853799ecc52ee39689f1a_hd.jpg" data-rawwidth="1250" data-rawheight="341" class="origin_image zh-lightbox-thumb" width="1250" data-original="https://pic2.zhimg.com/v2-b0e96c4e8b2853799ecc52ee39689f1a_r.jpg">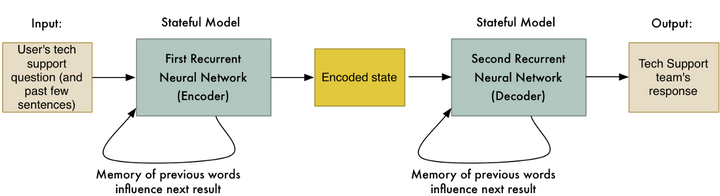
当用户与机器人进行交互时,他们将使用该系统“翻译”每个用户的消息以获得机器人的响应。
他们最终得到的是一个半智能机器人,(有时)可以回答真正的技术支持问题。下面是一部分用户和机器人之间的对话示例:
人:连接被拒绝或类似的东西
机器:我可以知道你连接的网络连接的版本吗?
人:我不确定我知不知道
机器:是网络连接提示任何用户证书?
人类:是的
机器:你现在在家还是在工作?办公室?
人:我在家
机器:试试这个。 goto <URL redacted>页面,然后输入您的姓名和密码
人类:完成
机器:尝试使用<NAME redacted>登录,然后检查其是否正常工作
人类:是的,现在它在工作!
机器:棒极了。还有什么我可以帮助你的?
他们还试图建立一个基于数百万部电影字幕的聊天机器人。他们的想法是,使用电影角色之间的对话作为一种训练机器人像人一样说话的方式。输入句子是一名角色的一句话,“翻译”是另一名角色在对话里回应他的内容:
&lt;img src="https://pic2.zhimg.com/50/v2-dffddd0667601ce5600454dfd82b5007_hd.jpg" data-rawwidth="1250" data-rawheight="340" class="origin_image zh-lightbox-thumb" width="1250" data-original="https://pic2.zhimg.com/v2-dffddd0667601ce5600454dfd82b5007_r.jpg"&gt;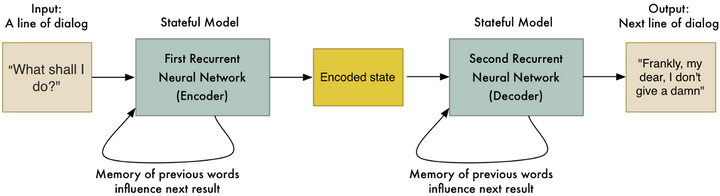
他们得到了很有意思的结果。机器人不仅仅像一个人,更是显示出了一点点智能化:
人类:我的名字是david。我的名字是什么?
机器:david。
人:我的名字是约翰。我的名字是什么?
机器:约翰。
人类:你是领导还是追随者?
机器:我是领导者。
人类:你是追随者还是领导者?
机器:我是领导者。
这只是可能性的开始。我们将不局限于将一个句子转换成另一个句子,同样,我们制作一个图像到序列的模型,它可以将图像转换为文本!
Google的另一个团队通过将第一个RNN替换为卷积神经网络(如我们在第3章中所了解的那样)。这允许输入是图片而不是句子,其余的工作基本相同:
&lt;img src="https://pic2.zhimg.com/50/v2-9d899c93bdc3d566e6441d2e2a2f938e_hd.jpg" data-rawwidth="1250" data-rawheight="341" class="origin_image zh-lightbox-thumb" width="1250" data-original="https://pic2.zhimg.com/v2-9d899c93bdc3d566e6441d2e2a2f938e_r.jpg"&gt;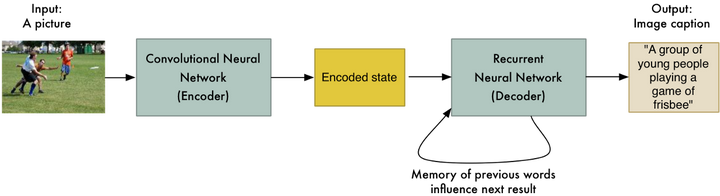
就像这样,(只要我们有很多很多的训练数据)我们就可以把图片变成单词!
Andrej Karpathy把这个想法进行了拓展,以构建一个通过分别处理图像的多个区域,来详细描述图像的系统:
&lt;img src="https://pic1.zhimg.com/50/v2-380c811bf4f9ffc0ebd1fa03427de50d_hd.jpg" data-rawwidth="1000" data-rawheight="763" class="origin_image zh-lightbox-thumb" width="1000" data-original="https://pic1.zhimg.com/v2-380c811bf4f9ffc0ebd1fa03427de50d_r.jpg"&gt;
Andrej Karpathy论文中的图片
这个想法使得我们可以构建一个,能够按照奇怪的要求找到特定图片的图片搜索引擎:
&lt;img src="https://pic2.zhimg.com/50/v2-80cf134e8142811f9ba5f0f1561012a1_hd.jpg" data-rawwidth="444" data-rawheight="356" class="origin_image zh-lightbox-thumb" width="444" data-original="https://pic2.zhimg.com/v2-80cf134e8142811f9ba5f0f1561012a1_r.jpg"&gt;
例子来自image sentence ranking visualize
甚至有研究人员正在研究相反的问题,仅仅基于文本描述产生一个完整的图片!
从这些例子,你可以开始想象的各种可能性。 到目前为止,序列到序列应用在从语音识别到计算机视觉各个领域。 我猜,明年会有更多的应用。
如果您想更深入地了解序列到序列模型和翻译,以下是一些推荐的资源:
- Richard Socher’s CS224D Lecture— Fancy Recurrent Neural Networks for Machine Translation (video)
- Thang Luong’s CS224D Lecture — Neural Machine Transation (PDF)
- TensorFlow’s description of Seq2Seq modeling
- The Deep Learning Book’s chapter on Sequence to Sequence Learning(PDF)&lt;img src="https://pic4.zhimg.com/50/v2-c8693405235197b0a454b2c41cb432d6_hd.jpg" data-rawwidth="1120" data-rawheight="808" class="origin_image zh-lightbox-thumb" width="1120" data-original="https://pic4.zhimg.com/v2-c8693405235197b0a454b2c41cb432d6_r.jpg"&gt;


