
- 1《深入浅出LLM基础篇》(一):大模型概念与发展_大模型发展时间线
- 2Hbase在集群中启动时碰到的问题
- 3React--useState_react usestate
- 4教程:利用LLaMA_Factory微调llama3:8b大模型_llama3模型微调保存
- 5【C语言课设】经典植物大战僵尸丨完整开发教程+笔记+源码_植物大战僵尸csdn
- 6Applied soft computing期刊投稿时间线_applied soft computing 需要上传代码吗
- 72024年前端最新2 年前端面试心路历程(字节跳动、YY、虎牙、BIGO),前端基础开发
- 8华为认证 | 华为HCIE认证体系有哪些?考哪个比较好?_华为网络认证体系
- 9微信扫码登录_第三方微信扫码登录
- 1010月华为OD面经整理分享,感谢三位上岸考友分享经验
语言大模型知识点简介_prefix decoder和casual decoder
赞
踩
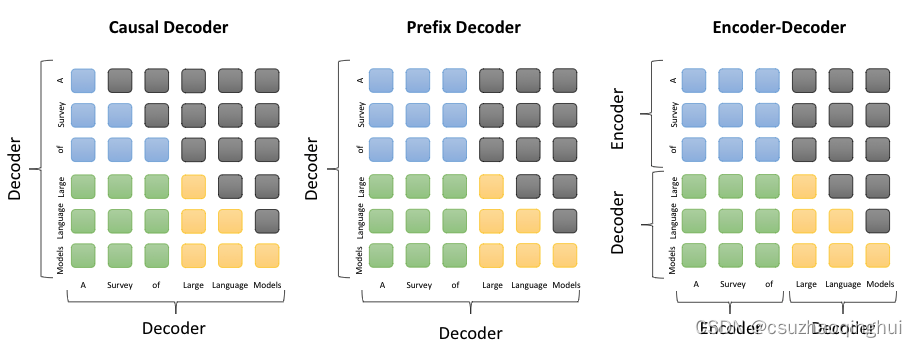
1. prefix Decoder 和 causal Decoder 和 Encoder-Decoder 区别是什么?
-
因果解码器(causal decoder,当前主流):它是一种解码器结构,在生成新的输出时,只会考虑到之前的输出,而不会考虑到未来的输出。这种结构在处理时间序列数据或者语音信号等任务中常见。
-
前缀解码器(prefix decoder):它是一种解码器结构,在生成新的输出时,会考虑到所有之前生成的输出。这种结构在自然语言处理任务中常见,例如机器翻译、文本生成等。
-
编码器-解码器(encoder-decoder):它是一种常见的神经网络结构,它包括一个编码器(Encoder)和一个解码器(Decoder)。编码器负责将输入数据转化为一个连续的向量,解码器则负责将这个向量转化为最终的输出。这种结构在许多任务中都有应用,例如机器翻译、语音识别等。
note:不同的语言模型通过attention mask设计,mask取全1就对应双向注意力,mask取下三角矩阵就对应单向注意力,我们可以只使用transformer encoder的情况下,自定义attention mask来兼容不同模型架构(如auto agressive单向注意力、auto encoding 双向注意力、encoder-decoder 解码器用单向注意力 且用交叉注意力连接两者)。如下图蓝色:the attention between prefix tokens 绿色:the attention between prefix and target tokens 黄色:the attention betweetn target tokens and masked attention
2. 大模型LLM的训练目标
-
大模型LLM(Language Model)的训练目标是学习语言的统计规律,以便能够生成或者理解人类语言。具体来说,LLM通常通过最大化训练数据的似然性来进行训练,也就是尽可能地让模型生成的语言与人类语言相似。
3. 为何现在的大模型大部分是Decoder only结构?
-
计算效率:Decoder only结构比Encoder-Decoder结构更加简单,计算效率更高。因为Decoder only结构只需要一次前向传播,而Encoder-Decoder结构则需要两次前向传播。
-
训练效果:Decoder only结构在许多任务上的表现与Encoder-Decoder结构相当,甚至更好。例如在语言模型任务上,Decoder only结构通常能够达到更好的效果。
-
数据利用:Decoder only结构可以更好地利用无标签数据进行训练。因为它可以直接使用大量的文本数据进行无监督学习,而不需要标签数据。
4. 模型涌现能力的原因
-
涌现能力是指模型在训练过程中自然产生的能力,例如理解语法、词义等。这主要是因为模型在训练过程中,通过大量的数据学习到了语言的统计规律,从而能够理解和生成符合这些规律的语言。
5. 什么是 LLMs 复读机问题?
-
LLMs复读机问题是指大型语言模型在生成文本时出现的一种现象,即模型倾向于无限地复制输入的文本或者以过度频繁的方式重复相同的句子或短语。这种现象使得模型的输出缺乏多样性和创造性,给用户带来了不好的体验。
6. 为什么会出现 LLMs 复读机问题?
-
复读机问题可能出现的原因包括数据偏差、训练目标的限制和缺乏多样性的训练数据。数据偏差指的是训练数据中存在大量的重复文本或者某些特定的句子或短语出现频率较高,模型在生成文本时可能会倾向于复制这些常见的模式。训练目标的限制是指大型语言模型的训练通常是基于自监督学习的方法,通过预测下一个词或掩盖词来学习语言模型。这样的训练目标可能使得模型更倾向于生成与输入相似的文本,导致复读机问题的出现。缺乏多样性的训练数据指的是训练数据中缺乏多样性的语言表达和语境,模型可能无法学习到足够的多样性和创造性,导致复读机问题的出现。
7. 如何缓解 LLMs 复读机问题?
-
为了解决复读机问题,可以采取以下策略:多样性训练数据、引入噪声、温度参数调整和后处理和过滤。多样性训练数据指的是在训练阶段,尽量使用多样性的语料库来训练模型,避免数据偏差和重复文本的问题。引入噪声可以在生成文本时引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成文本的多样性。温度参数调整是通过调整温度参数的值,可以控制生成文本的独创性和多样性,从而减少复读机问题的出现。后处理和过滤是对生成的文本进行后处理和过滤,去除重复的句子或短语,以提高生成文本的质量和多样性。
8. LLaMA 输入句子长度理论上可以无限长吗?
-
理论上,LLaMA 输入句子长度可以无限长,但未训练过的长度效果通常不好,因此接受2k的长度限制。
9. 什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型?
-
选择使用Bert模型还是LLaMA、ChatGLM类大模型,主要取决于任务需求和资源限制。一般来说,如果任务需要深度理解和生成复杂的文本,且有足够的计算资源,可以选择使用LLaMA、ChatGLM类大模型。如果任务主要是文本分类或实体识别等,且计算资源有限,可以选择使用Bert模型。
10. 各个专业领域是否需要各自的大模型来服务?
-
专业领域的大模型:在某些情况下,专业领域可能需要各自的大模型。这是因为每个领域都有其特定的术语和知识结构,通用的大模型可能无法完全理解和处理这些领域特定的信息。例如,医学、法律、工程等领域都有其独特的术语和知识结构,如果使用通用的大模型,可能无法提供准确和深入的信息。因此,为这些领域开发专门的大模型可能是必要的。
-
通用大模型的优势:然而,通用的大模型也有其优势。首先,它们可以处理各种类型的查询,而不仅仅是特定领域的查询。其次,由于它们接受了大量和多样的训练数据,它们可能在处理未知或罕见查询时表现得更好。最后,通用的大模型可能更容易维护和更新,因为它们不需要针对每个领域进行特定的训练和优化。
11. 如何让大模型处理更长的文本?
-
增加模型的容量:一种方法是增加模型的容量,例如增加模型的层数或宽度。这可以使模型能够处理更长的文本序列。然而,这也会增加模型的计算需求和训练时间。
-
使用注意力机制:另一种方法是使用注意力机制,这可以使模型在处理长文本时更加高效。注意力机制允许模型在处理每个词时,都能考虑到其上下文中的其他词,这使得模型能够更好地理解长文本。
-
使用滑动窗口或分块处理:还可以使用滑动窗口或分块处理的方法来处理长文本。这种方法将长文本分成多个较短的段落,然后分别处理。这种方法的优点是可以处理非常长的文本,缺点是可能会丢失一些上下文信息。
-
使用长文本处理的专门技术:最后,也可以使用一些专门针对长文本处理的技术,如Transformer-XL、Compressive Transformer等。这些模型使用了一些特殊的技术,如缓存机制、自我回归等,以处理长文本。
12. 大模型(LLMs)微调显存需求
-
全参数微调的显存需求取决于多个因素,包括模型的大小(参数数量),批次大小,序列长度,以及是否使用了混合精度训练等。对于GPT-3这样的大模型,如果想要在单个GPU上进行全参数微调,可能需要数十GB甚至上百GB的显存。这通常超过了常规GPU的显存容量,因此可能需要使用特殊的硬件,或者使用模型并行技术将模型分布在多个GPU上进行训练。
13. SFT后LLM表现下降的原因
-
SFT(Supervised Fine-Tuning)是一种常见的微调技术,它通过在特定任务的标注数据上进行训练来改进模型的性能。然而,SFT可能会导致模型的泛化能力下降,这是因为模型可能过度适应于微调数据,而忽视了预训练阶段学到的知识。这种现象被称为灾难性遗忘(catastrophic forgetting)。
-
为了解决这个问题,可以使用一些策略,如:
-
使用更小的学习率进行微调,以减少模型对预训练知识的遗忘。
-
使用正则化技术,如权重衰减或者早停,以防止模型过度适应微调数据。
-
使用Elastic Weight Consolidation(EWC)等技术,这些技术试图在微调过程中保留模型在预训练阶段学到的重要知识。
-
14. 缓解模型遗忘通用能力的方法
-
在进行领域模型的预训练时,通用能力往往会有所下降,这是因为模型在学习领域知识的同时,可能会忘记在原始预训练阶段学到的通用知识。为了缓解这个问题,可以采取以下策略:
-
使用更小的学习率进行预训练,以减少模型对通用知识的遗忘。
-
在预训练数据中混入一些通用数据,以帮助模型保持通用能力。
-
使用正则化技术,如权重衰减或者早停,以防止模型过度适应领域数据。
-
15. 提高模型在预训练过程中学习知识的方法
-
如果想要让模型在预训练过程中学习到更多的知识,可以尝试以下方法:
-
增加预训练数据的多样性和数量,让模型接触到更多的知识和情况。
-
使用更复杂的模型,如增加模型的深度或宽度,以提高模型的学习能力。
-
使用更好的预训练策略,如使用不同的预训练任务,或者使用更先进的预训练方法。
-
16. SFT操作的基座模型选择
-
进行SFT(Supervised Fine-Tuning)操作的时候,基座模型的选择取决于具体的任务需求。如果任务需要处理对话类型的数据,那么选择Chat模型可能会更好,因为Chat模型在预训练阶段就已经学习了处理对话数据的能力。如果任务更加关注通用的语言理解和生成能力,那么选择Base模型可能会更合适。总的来说,应该根据任务的具体需求和模型的特性来选择最合适的基座模型。
17. 大模型LLM进行SFT操作学习内容
-
当大模型LLM(Large Language Model)进行SFT(Supervised Fine-Tuning)操作时,它主要在学习如何更好地完成特定的任务。这个过程中,模型会根据标注的任务数据进行训练,调整模型的参数以优化任务的性能。例如,如果是文本分类任务,模型会学习如何根据输入的文本来预测正确的类别。
18. 预训练和SFT操作的区别
-
预训练和SFT操作是模型训练过程中的两个重要阶段,它们的主要区别在于训练数据和目标:
-
PreTrain阶段,模型通常使用大量无标签的文本数据进行训练,目标是学习语言的一般规律和知识,例如词义、语法结构等。
-
SFT阶段,模型使用标注的任务数据进行训练,目标是学习如何完成特定的任务,例如文本分类、情感分析等。
-
19. 样本量规模增大导致的OOM错误
-
当样本量规模增大时,可能会出现OOM(Out of Memory)错误,这是因为模型需要更多的内存来存储和处理数据。为了解决这个问题,可以尝试以下方法:
-
减小批量大小:这可以减少每次训练需要处理的数据量,从而减少内存使用。
-
使用梯度累积:这种方法可以在不减小批量大小的情况下,减少内存使用。
-
使用模型并行:这种方法可以将模型的不同部分放在不同的设备上进行训练,从而减少每个设备需要的内存。
-
20. 大模型LLM进行SFT时的样本优化方法
-
对于大模型LLM进行SFT时,可以通过以下方法对样本进行优化:
-
数据增强:通过对原始数据进行变换,生成新的训练样本,可以增加数据的多样性,提高模型的泛化能力。
-
硬负采样:对于分类任务,可以选择那些模型预测错误的样本进行重复训练,以提高模型的性能。
-
样本权重调整:根据样本的难易程度或者重要性,调整它们在训练中的权重,可以帮助模型更好地学习。
-

