
- 1PostgREST的安装部署(Windows和Linux环境)_postgrest 配置文件
- 2【正点原子Linux连载】 第四十二章 多点电容触摸屏实验摘自【正点原子】ATK-DLRK3568嵌入式Linux驱动开发指南
- 3DevOps与IT运维的未来趋势:自动化和人工智能
- 4SpringBoot3 集成Springdoc 实现Swagger3功能_springdoc-openapi-starter-webmvc-ui 2.5.0
- 5VsCode使用教程
- 6uniapp修改导航栏的文字和图标并触发事件_uniapp修改导航栏右侧文字
- 7大模型训练的关键技术之基础概念_模型训练基础概念
- 8CentOS6.5 安装VNC并开机自启_tigervnc如何默认启动display:2
- 9Property 'sqlSessionFactory' or 'sqlSessionTemplate' are required问题解决
- 10实现高效生成式预训练Transformer模型:基于多模态数据融合和多任务学习的方法_transformer数据融合
python深度学习入门-从零构建CNN和RNN
赞
踩
第1章 基本概念
本章说明如何将数据函数表示为一系列连接在一起构成计算图的运算,并演示如何利用这种表示方法和微积分的链式法则,来计算函数的输出相对于其输入的导数
1.1. 导数
d f d x ( a ) = lim Δ → 0 f ( a + Δ ) − f ( a − Δ ) 2 ∗ Δ \frac{df}{dx}(a) = \lim_{\Delta \to 0} \frac{{f \left( {a + \Delta } \right) - f\left( a - \Delta \right)}}{2 * \Delta } dxdf(a)=Δ→0lim2∗Δf(a+Δ)−f(a−Δ)
1.2. 链式法则
f
2
(
f
1
(
x
)
)
=
y
f_2(f_1(x)) = y
f2(f1(x))=y
f
1
(
x
)
=
u
f_1(x) = u
f1(x)=u
d
f
2
d
x
(
x
)
=
d
f
2
d
u
(
f
1
(
x
)
)
∗
d
f
1
d
x
(
x
)
\frac{df_2}{dx}(x) = \frac{df_2}{du}(f_1(x)) * \frac{df_1}{dx}(x)
dxdf2(x)=dudf2(f1(x))∗dxdf1(x)
1.3. 多输入函数的导数
f
(
x
,
y
)
=
s
f(x, y) = s
f(x,y)=s
a
=
a
(
x
,
y
)
=
x
+
y
a = a(x, y) = x + y
a=a(x,y)=x+y
s
=
σ
(
a
)
s = \sigma(a)
s=σ(a)
∂
f
∂
x
=
∂
σ
∂
u
(
a
(
x
,
y
)
)
∗
∂
a
∂
x
(
(
x
,
y
)
)
=
∂
σ
∂
u
(
x
+
y
)
∗
∂
a
∂
x
(
(
x
,
y
)
)
\frac{\partial f}{\partial x} = \frac{\partial \sigma}{\partial u}(a(x, y)) * \frac{\partial a}{\partial x}((x, y)) \ = \frac{\partial \sigma}{\partial u}(x + y) * \frac{\partial a}{\partial x}((x, y))
∂x∂f=∂u∂σ(a(x,y))∗∂x∂a((x,y)) =∂u∂σ(x+y)∗∂x∂a((x,y))
1.4. 多输入向量函数的导数
矩阵的导数实际上就是”矩阵中每个元素的导数“
X
=
[
x
11
x
12
x
13
]
X =
W
=
[
w
11
w
21
w
31
]
W =
v
=
X
∗
W
v = X * W
v=X∗W
d v d X = W T \frac{dv}{dX} = W^T dXdv=WT
1.5. 向量函数及其导数: 再进一步
向量函数及逐元素应用的函数嵌套的函数,进行求导运算
1.6. 包含两个二维矩阵数据的计算图
前面最多提到了向量,此处讨论的二维矩阵的导数
如果矩阵乘法作为一种”组合运算“包含在嵌套函数中时,求导的公式形式不变
d
v
d
X
=
W
T
\frac{dv}{dX} = W^T
dXdv=WT
假设矩阵 X 是 m 行 n 列,矩阵 W 是 n 行 p 列,F = XW。那么,F 对 X 的导数是一个四阶张量,其形状为 (m, n, m, p)。
但是,在许多实际应用中,我们通常对矩阵 F 的 Frobenius 范数(或者说,矩阵 F 的所有元素的平方和的平方根)的导数更感兴趣。记 L = ||F||_F^2 = trace(F^T F) = trace((XW)^T XW) = trace(W^T X^T XW)。对于这个 L,我们有:dL/dX = d(trace(W^T X^T XW))/dX = d(trace(W^T X^T XW) + trace(W^T W X^T dX))/dX = 2XWW^T所以,如果你对矩阵 F 的 Frobenius 范数的导数感兴趣,那么导数就是 2XWW^T。
第2章 基本原理
直接使用第一章中创建的构成要素来构建和训练模型,从而解决实际问题。具体来说,就是使用它们来构建线性回归模型和神经网络模型,并基于真是的数据集预测房间。通过比较得知,神经网络比起线性回归具有更好的性能。
2.1. 监督学习概述
监督学习是机器学习的子集,专门用于发现已测量的数据属性之间的关系
无监督学习(unsupervised learning) 是另一种机器学习,可以认为它是在已测量的事物可尚未测量的事物之间寻找关系
特征工程是将主观层面的(非正式的)观测结果的属性映射到特征的过程
监督学习概述:
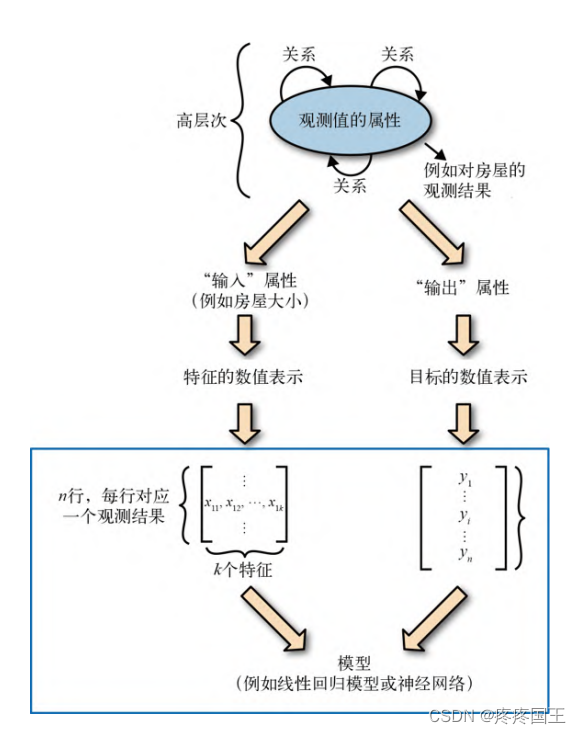
2.2. 监督学习模型
用一个矩阵X表式数据,该矩阵有n行,每行代表一个具有k的特征的观测值。每一行的观测值将是以xi = [xi1, xi2, xi3]表示的向量, 这些观测值将相互堆叠在一起形成一个批次。例如,一下是一个大小为3的批次:
x
b
a
t
c
h
=
[
x
11
x
12
x
13
.
.
.
x
1
k
x
21
x
22
x
23
.
.
.
x
2
k
x
31
x
32
x
33
.
.
.
x
3
k
]
x_{batch} =
每一批观测值都会有相应的一批目标,其中的每个元素都有对应观测值的目标数字。可以将他们表示为一维向量:
[
y
1
y
2
y
3
]
[y_{1} y_{2} y_{3}]
[y1y2y3]
2.3. 线性回归
y i = β 0 + β 1 ∗ x 1 + . . . + β k ∗ x k + ϵ y_{i} = \beta_{0} + \beta_{1} * x_{1} +...+ \beta_{k} * x_{k} + \epsilon yi=β0+β1∗x1+...+βk∗xk+ϵ
2.3.1. 线性回归: 示意图
从加法和乘法的层面理解线性回归运算:
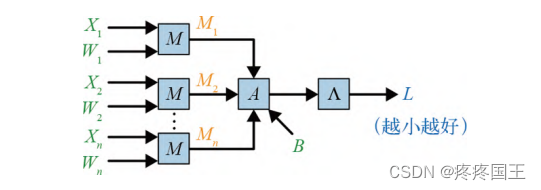
“训练”一个模型意味着什么呢?概括地讲,模型接受数据,并以某种方式将其与参数(parameter)进行组合,以生成预测结果 。例如,前面展示的线性回归模型接受数据X和参数W ,并使用矩阵乘法产生预测 P_batch:
P
b
a
t
c
h
=
[
P
1
P
2
P
3
]
P_{batch} =
惩罚函数可以评估所做预测是否准确,以及其误差的程度,例如这里使用均方误差(mean squared error, MSE):
M
S
E
(
p
b
a
t
c
h
,
y
b
a
t
c
h
)
=
(
y
1
−
p
1
)
2
+
(
y
2
−
p
2
)
2
+
(
y
3
−
p
3
)
2
3
MSE_{(p_{batch}, y_{batch})} = \frac{(y_{1} - p_{1})^2 + (y_{2} - p_{2})^2 + (y_{3} - p_{3})^2 }{3}
MSE(pbatch,ybatch)=3(y1−p1)2+(y2−p2)2+(y3−p3)2
将以上损失函数记为L(Loss)
2.3.2. 加入截距项
2.4. 训练模型
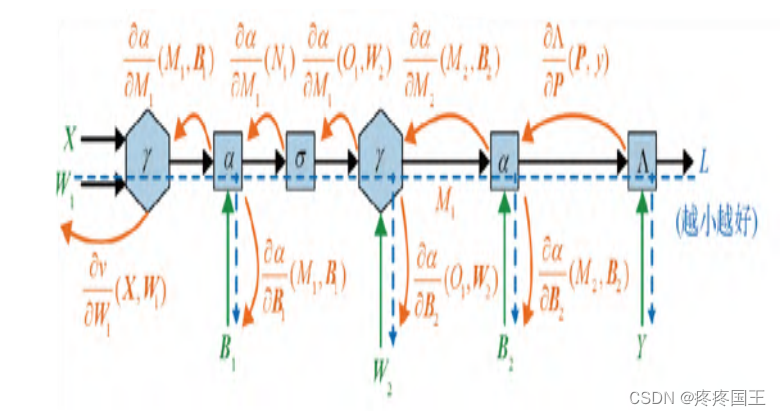
2.4.1. 计算梯度: 示意图
后向传递线性回归计算图:
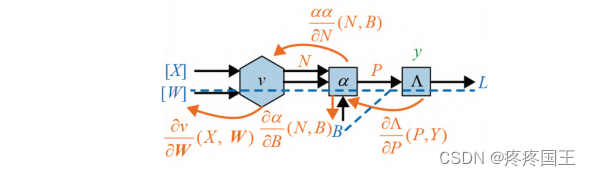
我们只需向后退,计算每个组成函数的导数,算出函数在前向传递中输入处的导数,最后将这些导数相乘。
2.4.2. 计算梯度: 数学和一些代码
2.4.3. 使用梯度训练模型
训练既是重复以下步骤:
- 选择一批数据
- 执行前向传递
- 使用在前向传递中计算所得的信息执行后向传递
- 使用在后向传递中计算的梯度来更新权重
2.5. 评估模型: 训练集和测试集
解决方案就是将样本分为训练集(training set)和测试集(testing set)。使用训练集训练模型(迭代更新权重),然后在测试集上评估模型 的性能。
这里的逻辑在于,如果模型能够成功地从训练集泛化到样本的其余部分 (整个数据集),那么相同的“模型结构”将很可能从样本(整个数据 集)泛化到总体,这也是最终目标。
2.6. 从零开始构建神经网络
以下将把线性回归模型扩充到非线性模,核心思想就是,首先执行一系列线性回归,然后将结果输入到一个非线性函数,最终执行最后一个线性回归并做出预测。
2.6.1. 步骤一: 一系列线性回归
什么是一系列线性回归? 也就是将W的维度由 [num_features, 1] 扩展到 [num_features, num_outputs]。 这样,对于每个观测值,都有原始特征的num_outputs个加权和。
可以将这些加权和视为”已学习到的特征“, 即原始特征的组合。
2.6.2. 步骤二:一个非线性函数
接下来把每个加权和输入到一个非线性函数中。我们要尝试的第一个函数是sigmod函数。
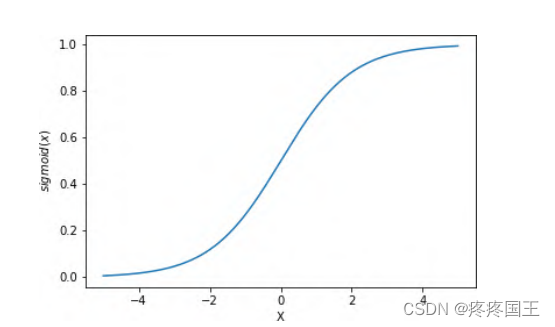
sigmod函数具有以下特点:
- 单调
- 非线性
- 导数可以用其自身表示,方便了计算
2.6.3. 步骤三: 另一个线性回归
最后将得到num_features个元素,其中每个元素都是原始特征的组合,当把他们输入到sigmod函数后,取值都在0和1之间。同时,将这些元素输入到 一个常规的线性回归模型中,使用它们的方式与之前使用原始特征的方式 相同。
2.6.4. 示意图
较为常见的神经网络表示法:
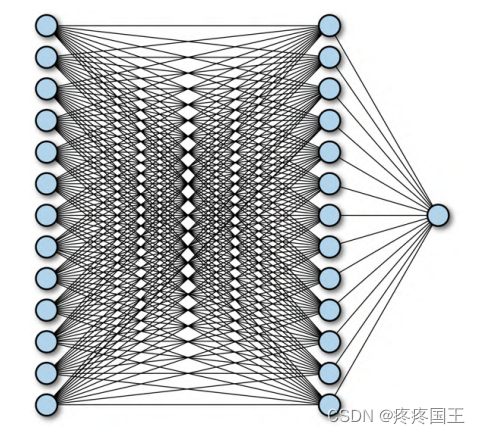
第一列13个圆圈表示13个原始特征。
第二列13个圆圈表示已学习到的13个特征。(第二列有13个原因是W的维度为[num_features, num_outputs], num_outputs取值为num_features, 也就是13)
最后一个圆代表最终预测结果。(由于每一个圆都用于最终结果预测,所以13个圆都要链接到最后一个圆圈)
2.6.5. 神经网络: 后向传递
在神经网络中,后向传递的原理与在简单的线性回归模型中的原理相同, 只不过步骤相对多一点。
主要涉及两个步骤:
- 计算每个运算的导数,并在其输入处进行求值。
- 将结果相乘。
2.7. 神经网络比简单的线性回归效果更好的原因
- 可以学习输入和输出之间的非线性关系(引入了sigmod函数)
- 除了单个特征,神经网络可以学习原始特征和目标之间的组合关系。(这是因为神经网络使用矩阵乘法来创建多个“已学习到的特征”, 每个特征都是所有原始特征的组合,本质上相当于在这些“已学习到的特 征”上应用另一个线性回归。)
第3章 从零开始深度学习
基于基本原理,构建深度学习模型更高层次的组件,即layer类、optimizer类等
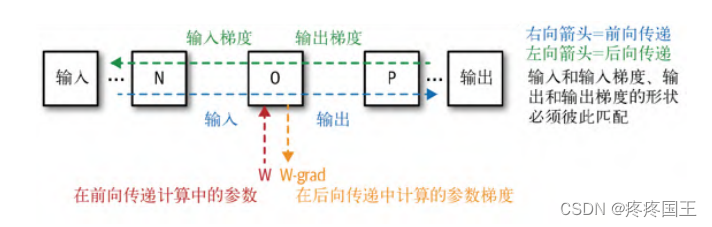
3.1. operaion(运算)
可以分为两类,一类是进行矩阵运算,例如矩阵乘法,另一类是进行将某个操作作用于所有矩阵元素,例如sigmod
限制:
1. 输出梯度的形状必须与输出的形状相匹配
2. 后向传递期间向后发送的输入梯度,其形状必须与输入的形状相匹配
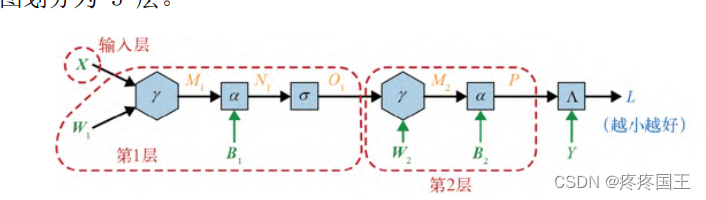
3.2. layer(层)
就operation类而言,层是一系列线性运算外加后边跟着的一个非线性运算。
- 输入自己构成一层,称为输入层
- 输出自己构成一层,称为输出层
- 中间层,称为隐藏层
3.3. 需要实现的operation及layer
需要实现的operation: 权重乘法, 偏差项加法,sigmod
class WeightMultipy(ParamOperation):
'''
神经网络的权重乘法运算
'''
class BiasAdd(ParamOperation):
'''
增加偏差项
'''
class Sigmod(ParamOperation):
'''
sigmod激活函数
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
需要实现的layer: 全连接层或者称为稠密层
class Dense(layer):
'''
全连接层
'''
- 1
- 2
- 3
- 4
3.4. NeuralNetwork类和其它类
NeuralNetWorkt需要具备的功能:
- 获取输入X, 将其连续向前传递给每个Layer类
- 将prediction与y进行比较,计算损失梯度
- 将损失梯度一次向后传递,并将其存储到相应的Operation类中
3.4.1. Loss类
class Loss(object):
'''
神经网络的损失
'''
class MeanSquaredError(Loss):
'''
均方误差
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.5. 构建深度学习模型
class NerralNeetwork(object):
'''
神经网络对应的类
'''
- 1
- 2
- 3
- 4
3.6. 优化器和训练器
3.6.1. 优化器
class Optimizer(object):
'''
神经网络优化基类
'''
class SGD(Optiomizer):
'''
随机梯度下降优化器
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.7. 训练器
需要具备的功能:
- 训练模型
- 将NeuralNetwork和Optimizer结合起来,进行参数矩阵的更新
class Trainer(object):
'''
训练神经网络
'''
- 1
- 2
- 3
- 4
3.8. 整合
deep_neural_network = NeuralNetwork( layers=[Dense(neurons=13, activation=Sigmoid()), Dense(neurons=13, activation=Sigmoid()), Dense(neurons=1, activation=LinearAct())], loss=MeanSquaredError(), learning_rate=0.01 ) optimizer = SGD(lr=0.01) trainer = Trainer(deep_neural_network, optimizer) trainer.fit(X_train, y_train, X_test, y_test, epochs = 50, eval_every = 10, seed=20190501)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
第4章 扩展(优化方法)
优化神经网络的一些关键技术
4.1. softmax交叉熵损失函数
引入的原因是, 对于输入到神经网络的所有观测值,不仅每个值都应该位于0到1之间,而且概率向量之和应为1
- softmax
s o f t m a x ( [ x 1 x 2 x 3 ] ) = [ e x 1 e x 1 + e x 2 + e x 3 e x 2 e x 1 + e x 2 + e x 3 e x 3 e x 1 + e x 2 + e x 3 ] softmax() =⎡⎣⎢x1x2x3⎤⎦⎥ softmax( x1x2x3 )= ex1+ex2+ex3ex1ex1+ex2+ex3ex2ex1+ex2+ex3ex3 ⎡⎣⎢⎢⎢ex1ex1+ex2+ex3ex2ex1+ex2+ex3ex3ex1+ex2+ex3⎤⎦⎥⎥⎥ - 交叉熵损失
C E ( p i , y i ) = − y i × l o g ( p i ) − ( 1 − y i ) × l o g ( 1 − p i i ) CE(p_{i},y_{i}) = -y_{i} \times log(p_{i}) - (1 - y_{i}) \times log(1 - p_{i_{i}}) CE(pi,yi)=−yi×log(pi)−(1−yi)×log(1−pii)
4.2. 动量
每个时间步长的参数更新将是过去时间步长参数更新的加权平均值,其中权重呈指数衰减
u p d a t e = ∇ t + μ × ∇ t − 1 + μ 2 × ∇ t − 2 + . . . update=\nabla_{t}+\mu \times \nabla_{t-1} + {\mu}^2 \times \nabla_{t-2} + ... update=∇t+μ×∇t−1+μ2×∇t−2+...
4.3. 学习率衰减
随着训练的进行,越来越需要降低学习率。
4.4. 权重初始化
4.5. dropout
简单地在一层中随机选择一定比例的神经元p,并在每次前向传递训练中将他们设置为0。他可以改变神经网络的容量,并降低发生过拟合的可能性
第5章 CNN
卷积神经网络,专门用于理解图像的神经网络
第6章 RNN
先介绍了前几章所构架的神经网络并不能处理的网络情形,从而引出了自动微分架构。循环神经网络,专门用于理解数据点按顺序出现的数据,例如时间序列数据或自然语言数据。还介绍了RNN的两种变体GRU和LSTM的工作原理。
第7章 PyTorch
如何使用高性能的开源神经网络PyTorch


