
- 1RocketMq集群安装&整合Springboot_rocketmq springboot多个namesrv 怎么订阅
- 2Python:关于创建字典的4种方式_python创建字典
- 32024-5-15
- 4金融与大模型:引领行业未来的创新融合
- 5AMEYA360代理品牌:ROHM开发出世界超小CMOS运算放大器,适用于智能手机和小型物联网设备等应用
- 6HDFS Disk Balancer_hdfs diskbalancer
- 7Centos7配置Hadoop出现Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password)的解决
- 8RocketMQ 第一章 核心功能 4 消息发送样例 4.5 批量消息_rocketmq批量发送 指定队列
- 9linux下使用libusb获取系统usb设备具体信息_libusb 对应
- 10java hutool工具类处理json的常用方法_hutool json字符串转map
使用Transfomer对时间序列进行预测(基于PyTorch代码)_transform预测值
赞
踩
代码来源
https://github.com/nok-halfspace/Transformer-Time-Series-Forecasting
文章信息:https://medium.com/mlearning-ai/transformer-implementation-for-time-series-forecasting-a9db2db5c820
数据结构
该项目中的数据结构如下图所示:有不同的sensor_id, 然后这些sensor在不同的时间段有不同的humidity.
数据导入和初步处理
首先是对数据进行初步处理,以下为DataLoader的代码:
- class SensorDataset(Dataset):
- """Face Landmarks dataset."""
-
- def __init__(self, csv_name, root_dir, training_length, forecast_window):
- """
- Args:
- csv_file (string): Path to the csv file.
- root_dir (string): Directory
- """
-
- # load raw data file
- csv_file = os.path.join(root_dir, csv_name)
- self.df = pd.read_csv(csv_file)
- self.root_dir = root_dir
- self.transform = MinMaxScaler() #对数据进行归一化处理
- self.T = training_length
- self.S = forecast_window
-
- def __len__(self):
- # return number of sensors
- return len(self.df.groupby(by=["reindexed_id"]))
-
- # Will pull an index between 0 and __len__.
- def __getitem__(self, idx):
-
- # Sensors are indexed from 1
- idx = idx+1
-
- # np.random.seed(0)
-
- start = np.random.randint(0, len(self.df[self.df["reindexed_id"]==idx]) - self.T - self.S)
- sensor_number = str(self.df[self.df["reindexed_id"]==idx][["sensor_id"]][start:start+1].values.item())
- index_in = torch.tensor([i for i in range(start, start+self.T)])
- index_tar = torch.tensor([i for i in range(start + self.T, start + self.T + self.S)])
- _input = torch.tensor(self.df[self.df["reindexed_id"]==idx][["humidity", "sin_hour", "cos_hour", "sin_day", "cos_day", "sin_month", "cos_month"]][start : start + self.T].values)
- target = torch.tensor(self.df[self.df["reindexed_id"]==idx][["humidity", "sin_hour", "cos_hour", "sin_day", "cos_day", "sin_month", "cos_month"]][start + self.T : start + self.T + self.S].values)
-
- # scalar is fit only to the input, to avoid the scaled values "leaking" information about the target range.
- # scalar is fit only for humidity, as the timestamps are already scaled
- # scalar input/output of shape: [n_samples, n_features].
- scaler = self.transform
-
- scaler.fit(_input[:,0].unsqueeze(-1))
- _input[:,0] = torch.tensor(scaler.transform(_input[:,0].unsqueeze(-1)).squeeze(-1))
- target[:,0] = torch.tensor(scaler.transform(target[:,0].unsqueeze(-1)).squeeze(-1))
-
- # save the scalar to be used later when inverse translating the data for plotting.
- dump(scaler, 'scalar_item.joblib')
-
- return index_in, index_tar, _input, target, sensor_number

其中比较重要的一个点是:在这里对初始的数据进行了MinMaxScaler()的处理,也就是进行数据归一化,这在深度学习中是很常见的一个操作。
时间信息Embedding
与LSTM模型不同,因为在transfoermer的模型中,所有的信息是一股脑丢进去的,所以是不带有时间的信息的。 所以对于时间序列,需要对时间信息进行额外处理。 在如下的代码中对原本的数据集增加了一些信息, 包括sin_hour, cos_hour, sin_day, cos_day有点类似于positional embedding的机制。 所要表达的信息如下图所示:

- import pandas as pd
- import time
- import numpy as np
- import datetime
- from icecream import ic
-
- # encoding the timestamp data cyclically. See Medium Article.
- def process_data(source):
-
- df = pd.read_csv(source)
-
- timestamps = [ts.split('+')[0] for ts in df['timestamp']]
- timestamps_hour = np.array([float(datetime.datetime.strptime(t, '%Y-%m-%d %H:%M:%S').hour) for t in timestamps])
- timestamps_day = np.array([float(datetime.datetime.strptime(t, '%Y-%m-%d %H:%M:%S').day) for t in timestamps])
- timestamps_month = np.array([float(datetime.datetime.strptime(t, '%Y-%m-%d %H:%M:%S').month) for t in timestamps])
-
- hours_in_day = 24
- days_in_month = 30
- month_in_year = 12
-
- df['sin_hour'] = np.sin(2*np.pi*timestamps_hour/hours_in_day)
- df['cos_hour'] = np.cos(2*np.pi*timestamps_hour/hours_in_day)
- df['sin_day'] = np.sin(2*np.pi*timestamps_day/days_in_month)
- df['cos_day'] = np.cos(2*np.pi*timestamps_day/days_in_month)
- df['sin_month'] = np.sin(2*np.pi*timestamps_month/month_in_year)
- df['cos_month'] = np.cos(2*np.pi*timestamps_month/month_in_year)
-
- return df
-
- train_dataset = process_data('Data/train_raw.csv')
- test_dataset = process_data('Data/test_raw.csv')
-
- train_dataset.to_csv(r'Data/train_dataset.csv', index=False)
- test_dataset.to_csv(r'Data/test_dataset.csv', index=False)
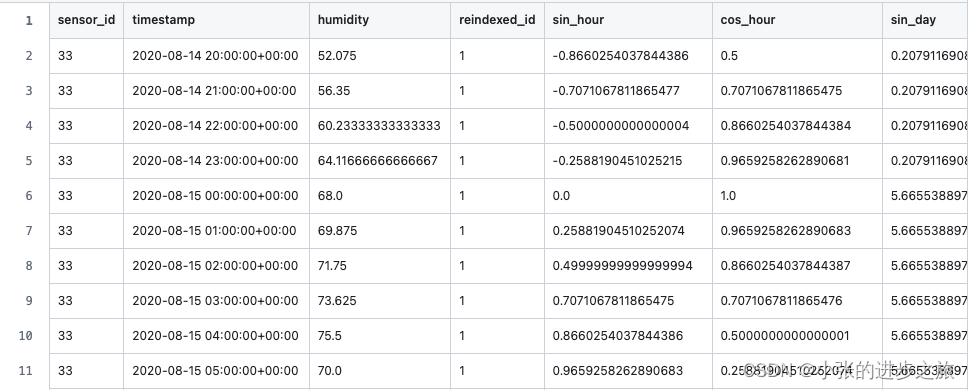
然后通过这个代码段,得到有更多变量的新的数据:
其中需要注意的是因为是在后续的main.py中对数据进行归一化,所以在这个数据集中看不出原本的humidity数据被归一化的处理过程。
带入到Transfomer模型进行计算
在对数据进行了数据的处理以后,接下来就是将数据带入到模型中进行计算
定义transfomer模型
这是在这个项目中很重要的代码段,所以在这里需要重点分析一下。 在代码的一开始作者就提出这个是基于文章《Attention is all you need》来进行计算的。
Transfomer是由encoder,decoder还有feed forward组成的。
模型构建:在这个项目中,用所有已知的历史数据对未来一个时期的数据进行预测。假设X1到X5分别是过去第1到第5期的历史数据,预测X2的时候,只使用X1的数据来进行预测;预测X3的时候则使用X1和X2的数据; 预测X4的时候使用X1,X2, X3的数据,以此类推。
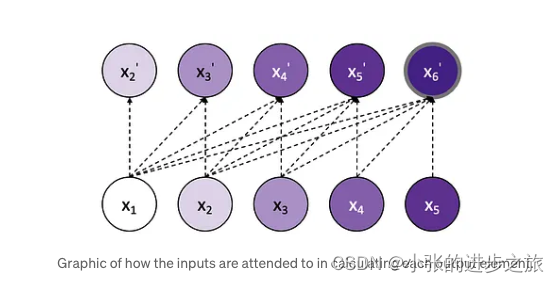
Masked self-attention: 因为transfomer中使用了自注意力机制, 但是在预测的过程中,是不可以看到预测的那个时间段之前的数据的,所以在这里使用了masked的机制,简单来说就是将未来的数据设为注意力为很小的一个数字,这样模型就看不到后面的数值了。
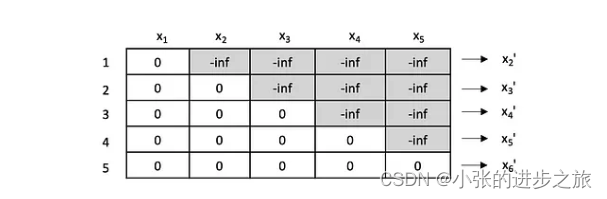
因为在Pytorch中其实已经有了现成的代码段,所以在这里只需要定义参数就可以使用。 听起来很简单,但是在使用的过程中也常常会遇到很多麻烦。
- feature_size:使用的特征个数,在该项目中是指时间的6个特征 ('sin_hour', 'cos_hour', 'sin_day', 'cos_day', 'sin_month', 'cos_month')+1个初始数据
- num_layers: encoder的层数,这个可以根据模型来具体调整
- dropout: 这个可以根据模型来具体调整
- nhead:多层注意力机制的头数,一定要注意的就是特征数必须能被头数整除,否则模型会报错 (该点很好理解,因为本来这个头数就是相当于分开映射的个数,不能整除就不好分)。
- import torch.nn as nn
- import torch, math
- from icecream import ic
- import time
- """
- The architecture is based on the paper “Attention Is All You Need”.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017.
- """
-
- class Transformer(nn.Module):
- # d_model : number of features
- def __init__(self,feature_size=7,num_layers=3,dropout=0):
- super(Transformer, self).__init__()
-
- self.encoder_layer = nn.TransformerEncoderLayer(d_model=feature_size, nhead=7, dropout=dropout)
- self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
- self.decoder = nn.Linear(feature_size,1) #feature_size是input的个数,1为output个数
- self.init_weights()
-
- #init_weight主要是用于设置decoder的参数
- def init_weights(self):
- initrange = 0.1
- self.decoder.bias.data.zero_()
- self.decoder.weight.data.uniform_(-initrange, initrange)
-
- def _generate_square_subsequent_mask(self, sz):
- mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
- mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
- return mask
-
- def forward(self, src, device):
-
- mask = self._generate_square_subsequent_mask(len(src)).to(device)
- output = self.transformer_encoder(src,mask)
- output = self.decoder(output)
- return output
执行模型
在该模型中,batch_size设为了1,也就是说在该模型中,每个sensor是相互独立的,在计算的时候是分别使用transfomer模型来进行计算。 并不考虑每个sensor之间的关系。
- import argparse
- # from train_teacher_forcing import *
- from train_with_sampling import *
- from DataLoader import *
- from torch.utils.data import DataLoader
- import torch.nn as nn
- import torch
- from helpers import *
- from inference import *
-
- def main(
- epoch: int = 1000,
- k: int = 60,
- batch_size: int = 1,
- frequency: int = 100,
- training_length = 48,
- forecast_window = 24,
- train_csv = "train_dataset.csv",
- test_csv = "test_dataset.csv",
- path_to_save_model = "save_model/",
- path_to_save_loss = "save_loss/",
- path_to_save_predictions = "save_predictions/",
- device = "cpu"
- ):
-
- clean_directory()
-
- train_dataset = SensorDataset(csv_name = train_csv, root_dir = "Data/", training_length = training_length, forecast_window = forecast_window)
- train_dataloader = DataLoader(train_dataset, batch_size=1, shuffle=True)
- test_dataset = SensorDataset(csv_name = test_csv, root_dir = "Data/", training_length = training_length, forecast_window = forecast_window)
- test_dataloader = DataLoader(test_dataset, batch_size=1, shuffle=True)
-
- best_model = transformer(train_dataloader, epoch, k, frequency, path_to_save_model, path_to_save_loss, path_to_save_predictions, device)
- inference(path_to_save_predictions, forecast_window, test_dataloader, device, path_to_save_model, best_model)
-
- if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--epoch", type=int, default=1000)
- parser.add_argument("--k", type=int, default=60)
- parser.add_argument("--batch_size", type=int, default=1)
- parser.add_argument("--frequency", type=int, default=100)
- parser.add_argument("--path_to_save_model",type=str,default="save_model/")
- parser.add_argument("--path_to_save_loss",type=str,default="save_loss/")
- parser.add_argument("--path_to_save_predictions",type=str,default="save_predictions/")
- parser.add_argument("--device", type=str, default="cpu")
- args = parser.parse_args()
-
- main(
- epoch=args.epoch,
- k = args.k,
- batch_size=args.batch_size,
- frequency=args.frequency,
- path_to_save_model=args.path_to_save_model,
- path_to_save_loss=args.path_to_save_loss,
- path_to_save_predictions=args.path_to_save_predictions,
- device=args.device,
- )

