
- 1银河麒麟高级服务器操作系统V10SP2(X86)audit服务组件升级、进程彻底关闭介绍_audit-3.0-5.se.08.ky10
- 2python opencv中文显示cv2 imshow()窗口中文标题乱码解决办法 python win32gui按装_cv2.imshow中文乱码
- 3【2023年APMCM亚太杯C题】完整代码+结果分析+论文框架_ahp分析汽车后市场影响因素
- 4Unity程序开发框架——单例模式基类模块_: singletonbehaviourbase
- 5使用div利用布局实现表格的效果_div 表格样式
- 6【ETOJ P1025】最长公共子序列 题解(动态规划+最长公共子序列)
- 7Android复习系列③之《Android筑基》_android开发scheme跳转支持唤醒到前台
- 8毕业设计 基于51单片机的智能门禁系统的设计_门禁报警电路怎么连接单片机
- 9【头歌-Python】列表自学引导_平台会对你编写的代码进行测试,平台生成一个包含1万个元素的列表(里面的元素每次
- 10Git reset 和 revert的区别_git reset和revert区别
【论文阅读】基于自适应小生境和 k 均值操作的数据聚类差分进化算法_小生境差分进化算法
赞
踩
原文题目
A Differential Evolution Algorithm With Adaptive Niching and K-Means Operation for Data Clustering
摘要
该论文解决的问题:数据聚类
使用的算法:差分进化算法
创新点:
- Adaptive Niching(自适应小生境)
目的:防止进化搜索的过早收敛(防止陷入局部最优) - Adaptive K-Means Operation(自适应 K-Means 操作) 局部搜索
目的:提高搜索效率(前人是固定 K-Means 的操作次数,这里改成自适应的了)
结果:优于相关算法
I. 引言
背景知识
聚类是数据挖掘中一个重要而又困难的任务。聚类的目的就是将数据集中的对象划分为不同的簇,使得相似的对象被划分到相同的簇而不相似的对象被划分到不同的簇。
聚类算法大致可以分为两类:
- 分层聚类算法
分层方法建立了一个树状的聚类层次结构,使每个聚类嵌套在层次结构的上一级的聚类中。 - 分区聚类算法
分区方法则是通过优化特定的标准,将数据集直接划分为不同的组。
根据数据对象是只被分配给一个簇还是具有一定成员关系的每个簇,分区方法可以进一步分类为硬聚类和模糊聚类。
Niching(小生境)
这个概念困扰了我好久,通过看论文和博客稍微理解了一点。
小生境(Niche):来自于生物学的一个概念,是指特定环境下的一种生存环境,生物在其进化过程中,一般总是与自己相同的物种生活在一起,共同繁衍后代。例如,热带鱼不能在较冷的地带生存,而北极熊也不能在热带生存。把这种思想提炼出来,运用到优化上来的关键操作是:当两个个体的相似度小于预先指定的某个值(称之为小生境距离)时,由于存在竞争关系,所以惩罚其中适应值较小的个体。
在多峰函数求解的遗传算法中,通常把解空间中峰周围的子空间比作生物生长的小生境, 把峰周围的个体比作在该小生境中繁衍的物种。所谓适应值共享, 就是将该小生境中所有个体的适应值按照物种的规模以一定的方式降低。显然, 如果某个小生境中有较多的个体, 那么该小生境中所有个体的适应值将以较大幅度降低。
A niche can be defined generally as a subset of resources in the environment. A species, on the other hand, can be defined as a type or class of individuals that takes advantage of a particular niche. Thus, niches are divisions of an environment, while species are divisions of the population.
小生境一般可以定义为环境中资源的子集。另一方面,一个物种可以定义为利用特定小生境的一种或一类个体。因此,小生境是环境的划分,而物种是种群的划分。
在生物学中,物种被定义为具有类似生物特征的个体群体,它们之间能够杂交,但不能与不同群体的个体杂交。由于每个小生境的资源数量有限,必须由占据该生态位的物种成员共享,随着时间的推移,环境中自然出现了不同的小生境和物种。自然生态系统不是无动于衷地进化单一的个体群体,而是进化出不同的物种(或子种群)来占据不同的小生境。
适应度共享
一个经典的小生境方法是适应度共享,可能是最广泛使用的小生境方法。共享概念最初是由Holland提出的,后来被采纳为一种机制,根据种群中个体的相似性将种群划分为几个子种群。适应度共享的灵感来自于在自然中观察到的共享概念,在自然中,一个个体只有有限的资源,且必须与环境中处于同一小生境的其他个体共享。适应度共享试图通过降低一个个体的适应度来维持一个多样化的群体,这种方法基于其他邻近个体的存在。在选择过程中,同一环境中的许多个体会降低彼此的适应度,从而使占据同一小生境的个体数量减少。
参考文献
X. Li, M. G. Epitropakis, K. Deb, and A. Engelbrecht, “Seeking multiple
solutions: An updated survey on niching methods and their applications,”
IEEE Trans. Evol. Comput., vol. 21, no. 4, pp. 518–538, Aug. 2017.
提出 Niching Method 的动机
一般来说,对于某些搜索空间很少有局部最优解的聚类问题,基于EA和基于EA的混合方法都能识别出最优解,而非平凡聚类问题通常涉及大量甚至大量的局部最优解。在这种情况下,这些方法很容易陷入局部最优。这主要是由于传统的EAs和混合EAs在进化过程中难以保持解的多样性。
小生境方法可以使进化算法并行地搜索解空间中的多个峰值。同时,它们可以用来保持种群的多样性,防止 EAs 陷入前景较差的局部最优。
多峰值的例子如下图所示
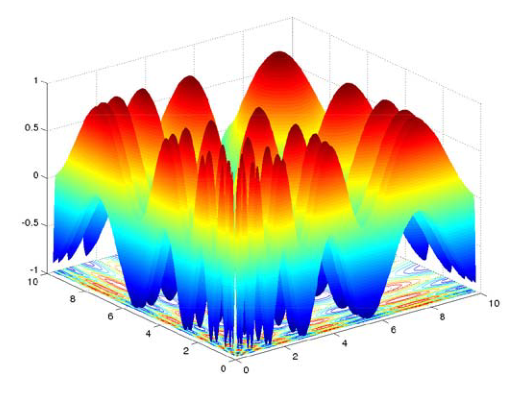
上图引用自 X. Li, M. G. Epitropakis, K. Deb, and A. Engelbrecht “Seeking multiple solutions: An updated survey on niching methods and their applications,” IEEE Trans. Evol. Comput., vol. 21, no. 4, pp. 518–538, Aug. 2017.
Niching Method 需要 Adaptive 的动机
小生境方法一般带有参数,这些参数的设定是基于特定问题的,随着进化过程的演变,问题可能发生变化,如果参数固定不变,可能会限制算法的性能。因此需要动态调节这些参数。
本文贡献
本文提出了一种自适应小生境方案(ANS)和自适应k均值操作(AKO),并通过优化ICV将它们整合到用于分区数据聚类的差分进化(DE)算法中。
主要贡献点如下:
- ANS:可动态调整种群中每个小生境大小,便于对空间进行适当的搜索,防止进化搜索的过早收敛。
- AKO:可动态确定进化过程中应用k-means算法的迭代次数,并将其应用于种群的小生境层次,以提高搜索效率。
II. 差分进化算法回顾




总结:
差分进化算法与遗传算法大体相同,包括交叉、变异和选择三个主要步骤,其中差分进化算法在变异操作方面使用差分策略,这也是差分进化算法名称的由来。常见的差分策略是随机选取种群中两个不同的个体,将其向量差缩放后与待变异个体进行向量合成。
III.相关工作
进化算法广泛应用于聚类算法
通过优化ICV准则进行分区聚类是NP难的。基于群体的搜索启发式算法,被认为是解决NP难问题的有效方法。因此许多基于进化算法的聚类方法被提出。
进化算法与 K-means 结合的动机
基于进化算法的方法可以提供比传统聚类方法更好的解决方案,但是计算成本可能会很高。为了提高搜索效率,已经开发了用于聚类的混合方法,将进化算法与基于k-means的局部搜索操作相结合。
结合k-means操作对进化过程中的解进行微调已被证明是一种可行的方法。
K-means 需要 Adaptive 的动机
前人的k-means操作通常采用固定次数的迭代。然而由于EA的进化是一个动态的过程,k-means运算的适当迭代次数取决于进化的阶段和后代的特征。固定的迭代次数可能会限制算法的性能。因此应该动态调节k-means的操作次数。
IV.所提算法
算法主体过程如下

A.表示、初始化和适应度函数
编码表示
对于具有d维数据和k个聚类的聚类问题,使用具有d × k的实数向量来编码单个解。第一个d实数表示第一个簇的中心,依此类推。
一个2维数据3个聚类的编码例子如下图所示
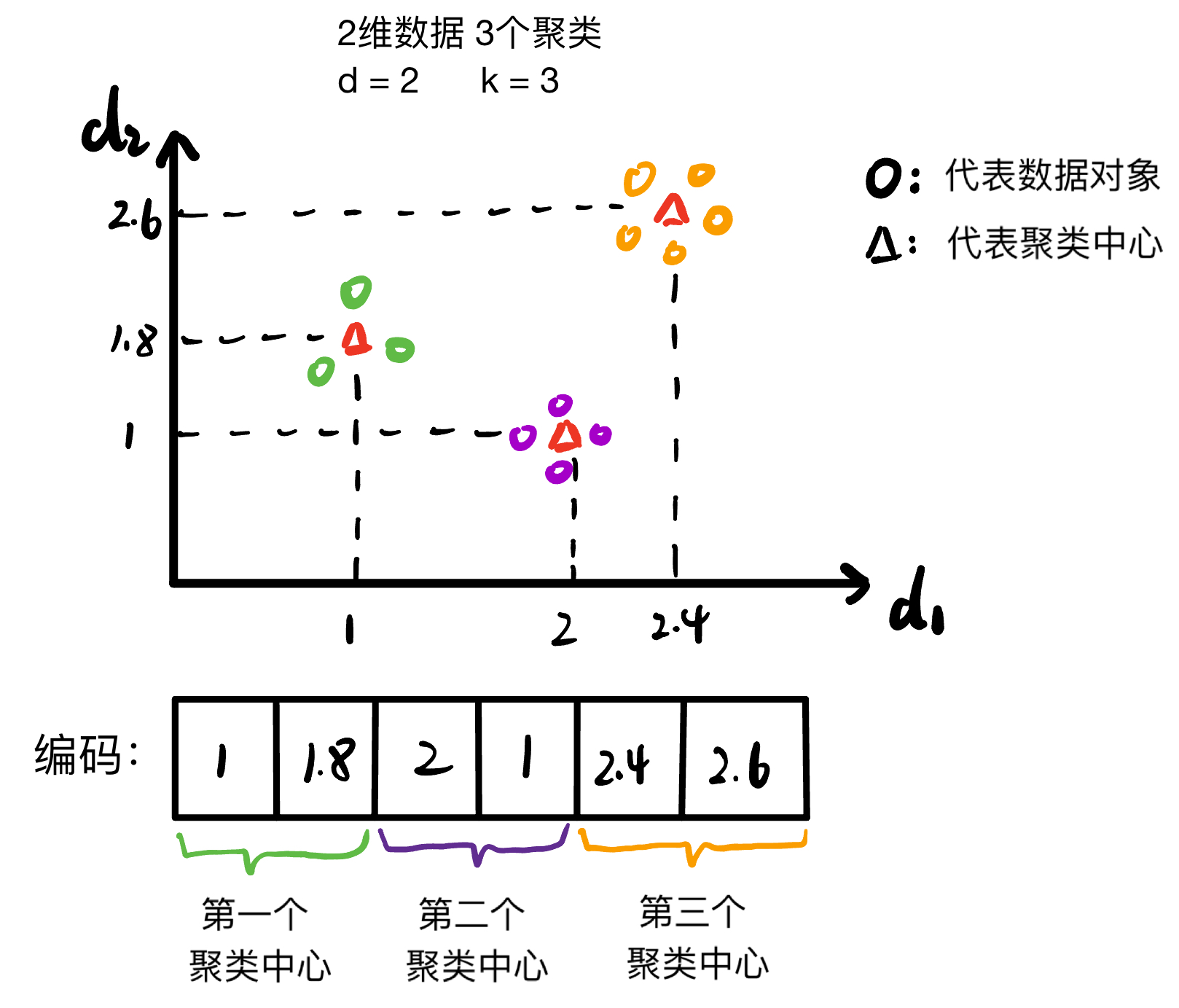
注意,采用上述表示,两个个体对应的聚类中心可能不会出现在同一位置,从而导致无效的突变和交叉。
之前对“两个个体对应的聚类中心可能不会出现在同一位置”这句话不太理解,现在明白了,还是用上图举例。
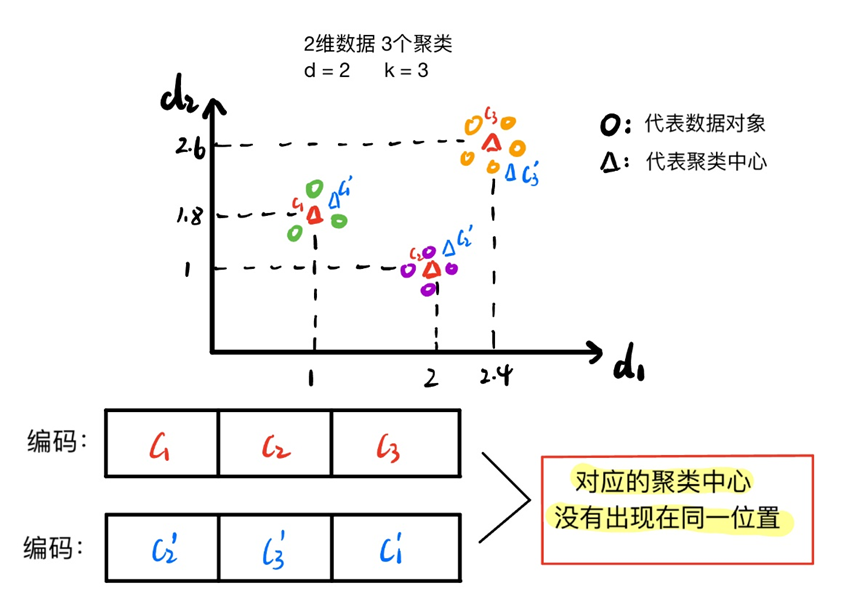
表示相同聚类中心的坐标可能不在同一列,因此需要调整。
为了解决这个问题,使用了聚类匹配方案[60]来重新排列解决方案中编码的聚类中心。
解决方法:
选择种群中最好的个体作为模板,其余个体的聚类中心根据模板重新排列,使最近的聚类中心出现在同一位置。如下图所示
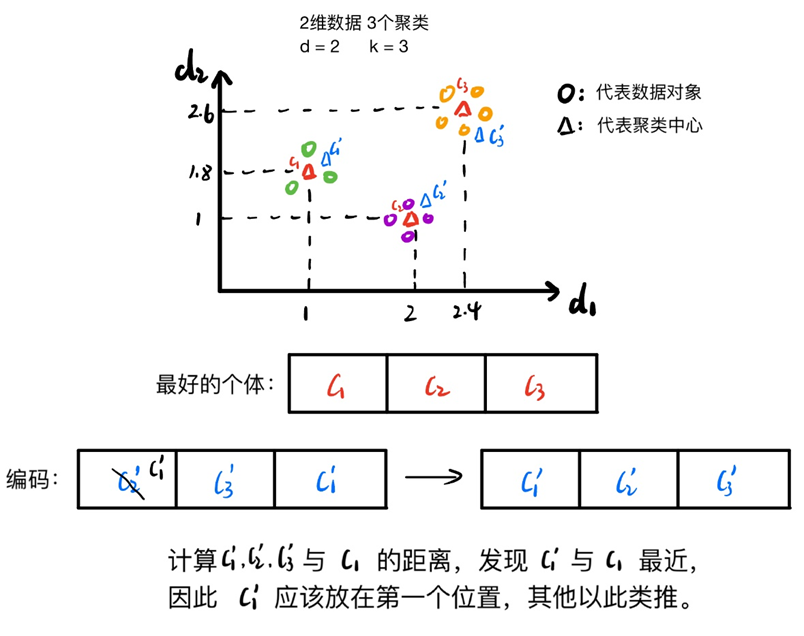
初始化
这些值在数据的属性范围内随机生成。
适应度函数
ICV 准则
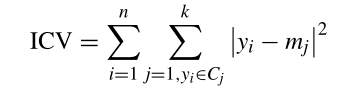
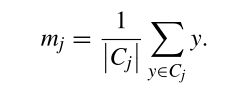
m 是聚类中心。
上述公式表达的意思就是所有数据与它聚类中心的距离的平方和。ICV越小表示聚类中心越好。
由于要优化最大值,因此适应度函数定义如下
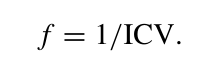
为了解决空簇的问题,加入惩罚因子,对含有较多空簇的解施加较大的惩罚,使其适应度降低,减少选择它们的概率。适应度函数重新定义如下
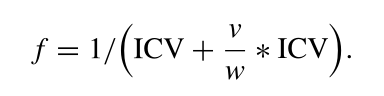
w和v分别表示总的簇数和空簇数。
B.自适应小生境方案
所提出的ANS建立在一个在[28]中提出的称为SCN小生境策略上。
首先通过柯西分布产生每个小生境的初始大小,起始均值和方差都为0.5。
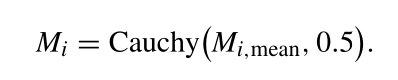
之后每一代小生境大小的更新策略如下
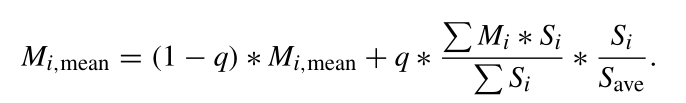
Si用来衡量小生境的表现,表现越好的小生境后续能够分配到更大的尺寸。Si定义为生成的后代成功取代其对应的亲本进入第i个小生境的比率。
C.自适应 K-means 操作
对于小生境,在每次进化生成后代后,考虑进行 K-means 操作,进行多少次 K-means 操作取决于该小生境的平均适应度。平均适应度大的小生境获得更多次数的 K-means 操作,来自平均适应度较低小生境的个体的后代几乎没有机会获得局部改进的机会。
计算k-means运算迭代次数的公式如下
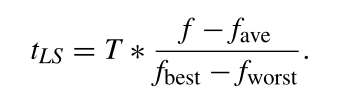
f
f
f为所选亲本个体的适应度,
T
T
T是一个缩放常数。
AKO算法流程如下

在执行AKO之后,得到的后代如果具有更好的适应度,将取代小生境中最相似的解(用欧氏距离测量)。
VI.结论
在这项工作中,本文提出了一种基于ANS和AKO的DE算法,通过优化ICV来实现数据聚类。实验结果证实了ANS能够帮助适当地搜索解空间,避免前景较差的最优解,而AKO能够提高进化效率。因此,结合这两种机制,所提出的算法能够高效地提供高质量的聚类解,优于可供比较的相关方法。

