
- 1我们是如何测试人工智能的(四)补充:模型全生命周期流程与测试图_智能软件测试模型
- 2Keil的软件仿真和硬件仿真
- 3关于有效解决Ubuntu中出现的若干问题(ROS2系统)_设置ubuntu系统的防火墙设置不会阻止ros2节点间的通信
- 4Go官方限流器time/rate分析_go time.rate
- 5【EI会议征稿通知】第四届云计算与大数据国际学术会议(ICCBD 2024)_2024年第四届iccbd云计算和大数据委员会国际会议2024
- 6微信小程序实现远程控制门锁_微信开发者小程序门禁系统代码怎么写
- 7最强分布式工具Redisson:分布式锁_redisson分布式锁
- 8数据结构 - 二叉树代码实现_创建二叉树的代码数据结构
- 9论文笔记——Generative Adversarial Nets生成对抗网络
- 10基于Android Studio生鲜商城(果蔬商城)_android studio 蔬菜商城项目
YOLOV9保姆级教程
赞
踩
YOLOv9保姆级教程(个人踩坑无数)----Windows11环境下训练自己的数据集
一、总述
这一篇则详细讲解如何配置YOLOv9,在本地电脑或者服务器都可,然后利用自己的数据集进行训练、推理、检测等。
二、YOLOv9代码下载
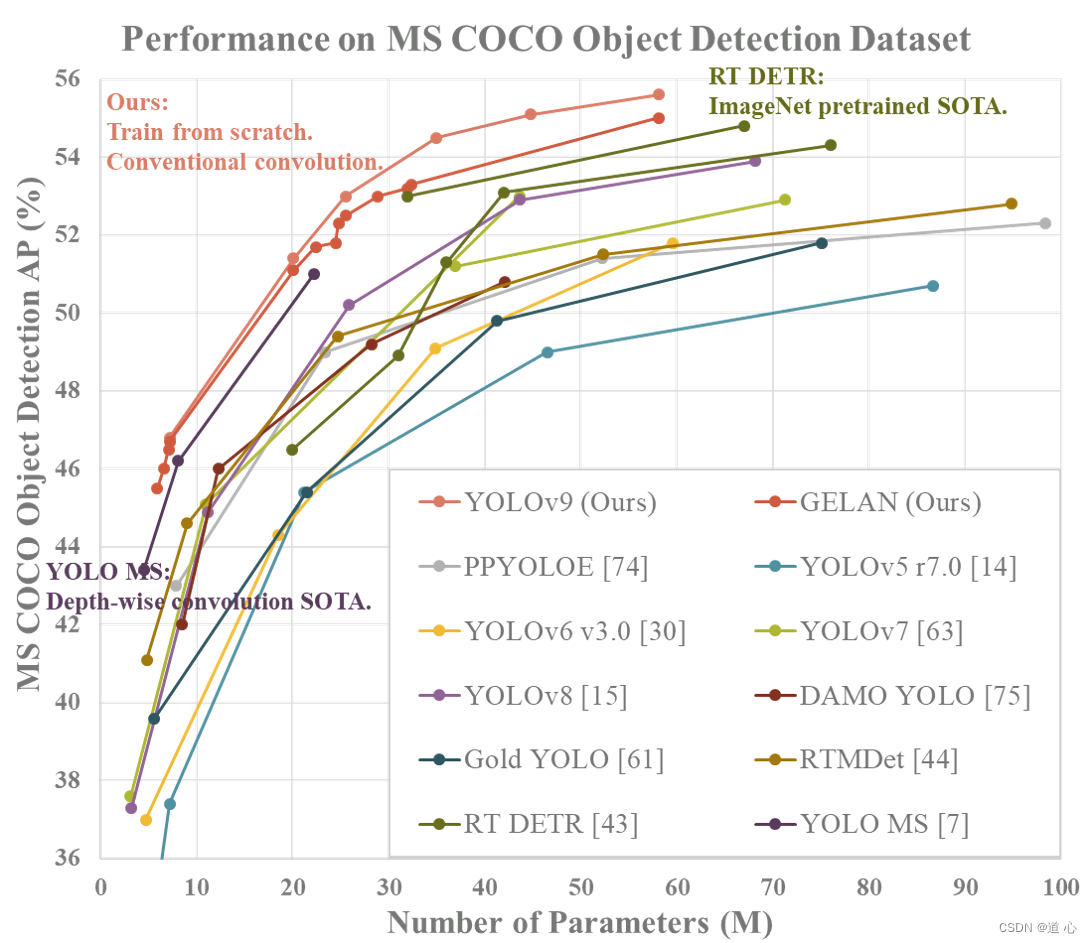
YOLOv9是原YOLOv7团队打造,提出了可编程梯度信息(PGI)的概念来应对深度网络实现多个目标所需的各种变化。 PGI可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,还设计了一种新的轻量级网络架构——基于梯度路径规划的通用高效层聚合网络(GELAN)。 GELAN的架构证实了PGI在轻量级模型上取得了优异的结果。
论文地址:YOLOv9论文地址
GitHub地址:GitHub代码下载地址
代码下载: 此处直接点击【Download ZIP】下载即可
权重下载: 此处直接选择【YOLOv9-C】和【YOLOv9-E】下载即可
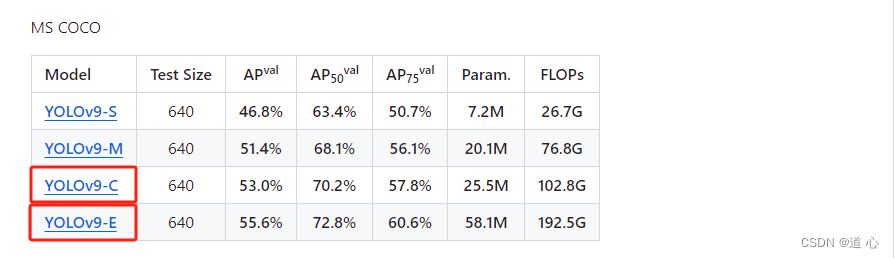
注意:目前【YOLOv9-S】和【YOLOv9-M】无法下载,应该是个BUG,相信很快就会得到解决。
在全部下载完成后,将权重文件放到yolov9文件夹内
三、环境配置
在windows系统下打开Anaconda的终端,创造虚拟环境。
① cd到yolov9所在文件夹
cd yolov9所在目录
- 1

② 创建虚拟环境
如下:输入 conda create -n yolov9(代表环境名称) python=3.8 (使用Python的版本),然后创建就可以了
conda create -n yolov9 python=3.8
- 1
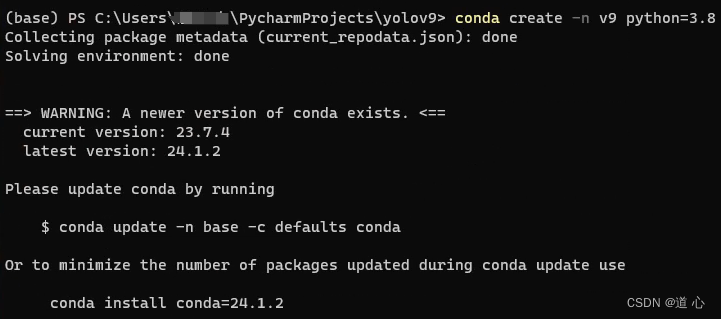
环境安装完成后,conda activate yolov9进入刚才创建的环境(这块我设置的为v9,只是一个名称,无伤大雅)
是否安装环境所需基础包,输入y安装即可,安装完成如下图:
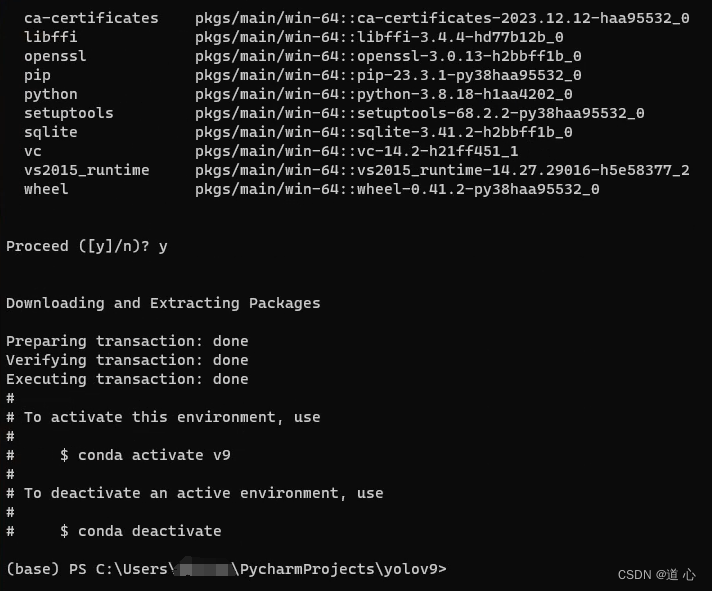
输入下面命令查看是否创建成功
conda env list
- 1

激活进入环境
conda activate yolov9
- 1

注:进入环境后,前面会从base变为yolov9
安装requirements.txt文件,后面加清华的镜像源效果更好。
//不加清华源
pip install -r requirements.txt
- 1
- 2
//加清华源
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
- 2
下载完毕
此时我们安装的只是基础的CPU状态,如果需要使用GPU训练,需要在pytorch中找到适合自己的cuda版本的torch口令然后下载
1、打开pytorch官网 :pytorch官网
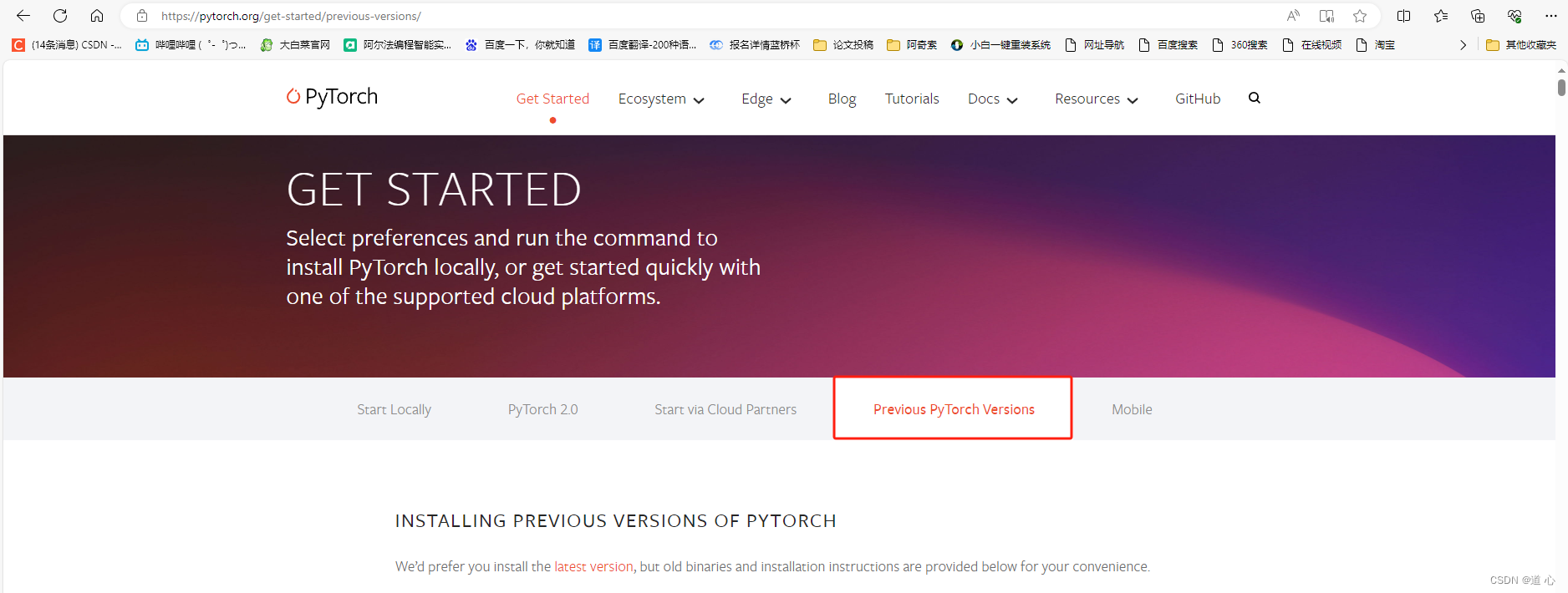
2、向下翻动找到适配于自己cuda版本的指令 :
例如说我的是CUDA 11.7版本,就选择对应的cuda指令
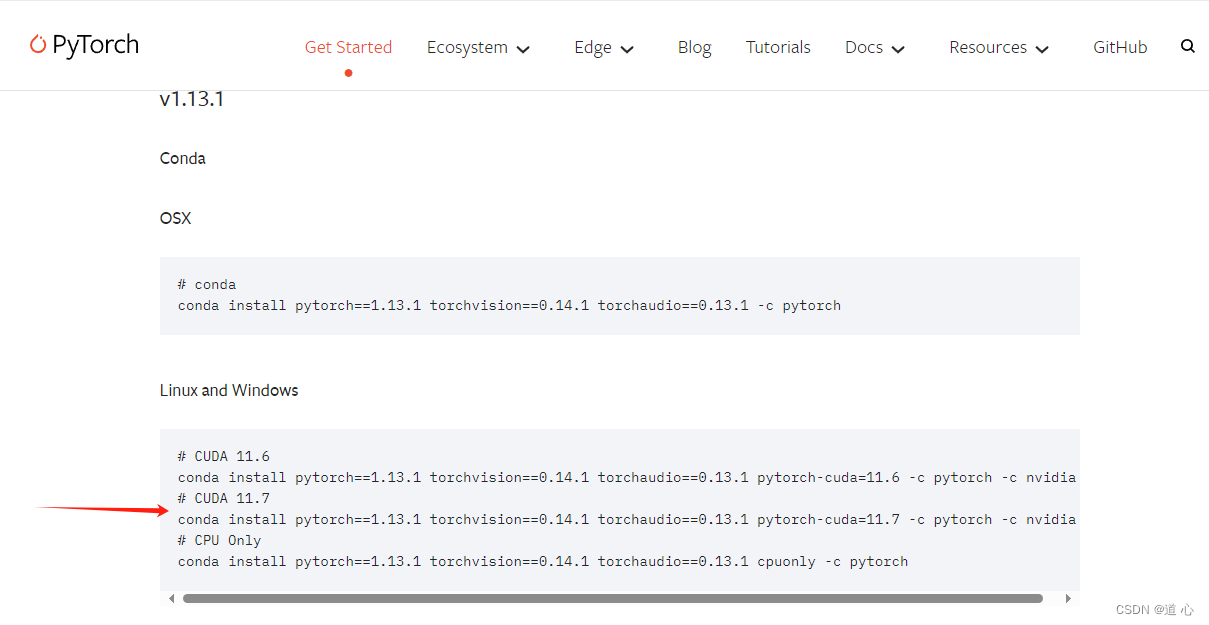
注:经过测试,当英伟达显卡超过1060系列的,基本上使用这条指令即可(如出现不兼容情况,欢迎留言)
# CUDA 11.7
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
- 1
- 2
等安装完毕后,gpu的训练环境就基本配置结束。
四、制作数据集
- 文件夹格式设置
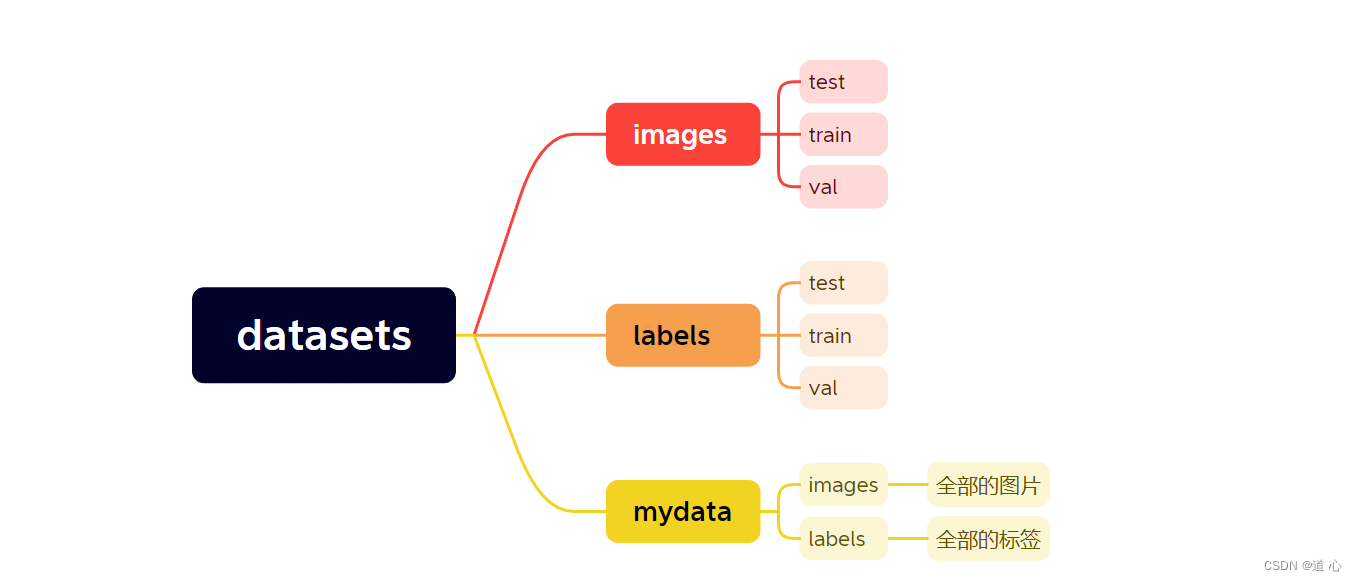
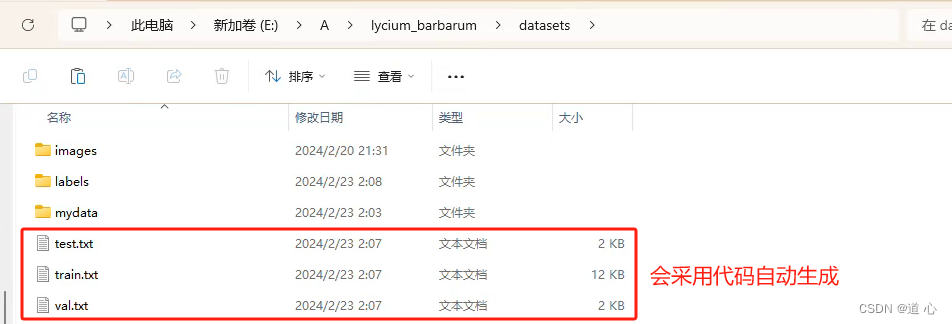
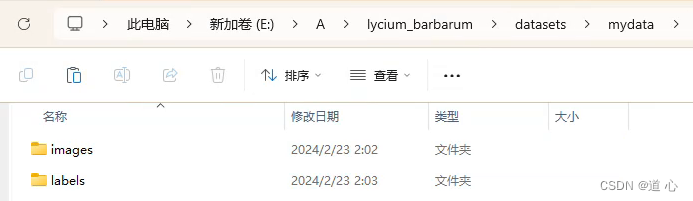
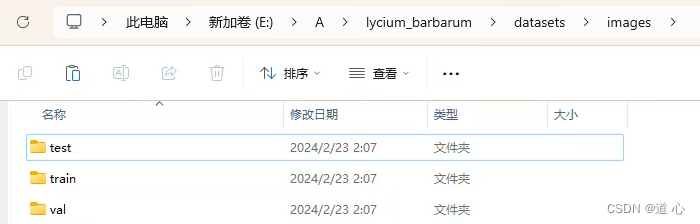
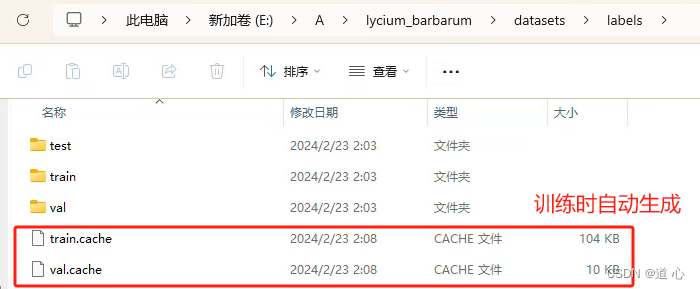
- 划分数据集
采用如下代码划分为训练数据集、验证数据集和测试数据集
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
# 原始路径
image_original_path = "E:/A/lycium_barbarum/datasets/mydata/images/"
label_original_path = "E:/A/lycium_barbarum/datasets/mydata/labels/"
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/images/train/")
train_label_path = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/labels/train/")
# 验证集路径
val_image_path = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/images/val/")
val_label_path = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/labels/val/")
# 测试集路径
test_image_path = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/images/test/")
test_label_path = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/labels/test/")
# 训练集目录
list_train = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/train.txt")
list_val = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/val.txt")
list_test = os.path.join(cur_path, "E:/A/lycium_barbarum/datasets/test.txt")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
def del_file(path):
for i in os.listdir(path):
file_data = path + "\\" + i
os.remove(file_data)
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
else:
del_file(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
else:
del_file(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
else:
del_file(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
else:
del_file(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
else:
del_file(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
else:
del_file(test_label_path)
def clearfile():
if os.path.exists(list_train):
os.remove(list_train)
if os.path.exists(list_val):
os.remove(list_val)
if os.path.exists(list_test):
os.remove(list_test)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + name + '.jpg'
srcLabel = label_original_path + name + ".txt"
if i in train:
dst_train_Image = train_image_path + name + '.jpg'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = val_image_path + name + '.jpg'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = test_image_path + name + '.jpg'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 制作data.yaml文件
新建yaml文件,其中yaml文件与YOLOV8类似
train: E:/A/lycium_barbarum/datasets/images/train # train images (relative to 'path') 128 images
val: E:/A/lycium_barbarum/datasets/images/val # val images (relative to 'path') 128 images
test: E:/A/lycium_barbarum/datasets/images/test # test images (optional)
nc: 2
# Classes
names: ['immaturate', 'mature']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
五、开始训练
使用PyCharm打开yolov9文件夹,并将环境转为刚建立的yolov9虚拟环境环境
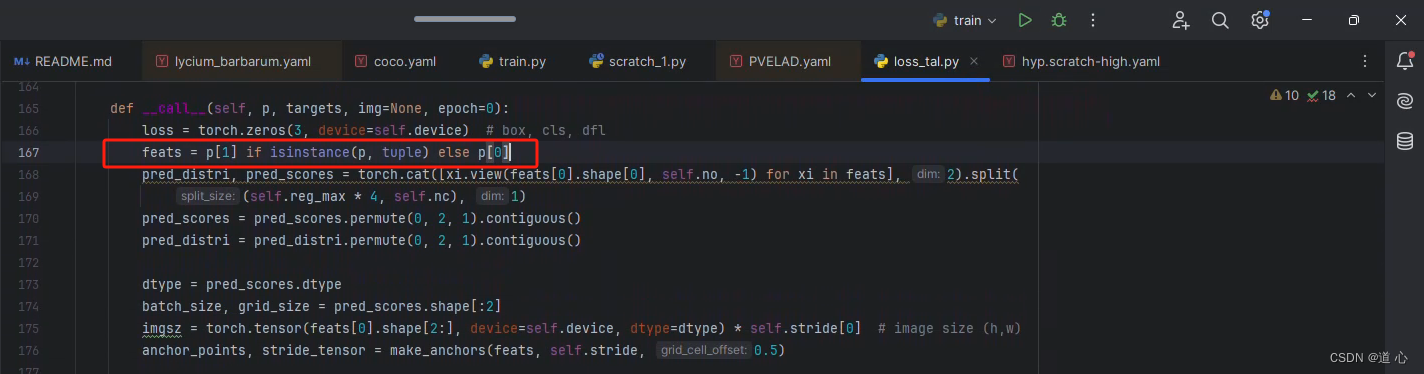
首先更改小错误,打开utils/loss_tal.py文件,到第167行,将p改为p[0]
其次打开trian.py文件,更改如下几个位置:
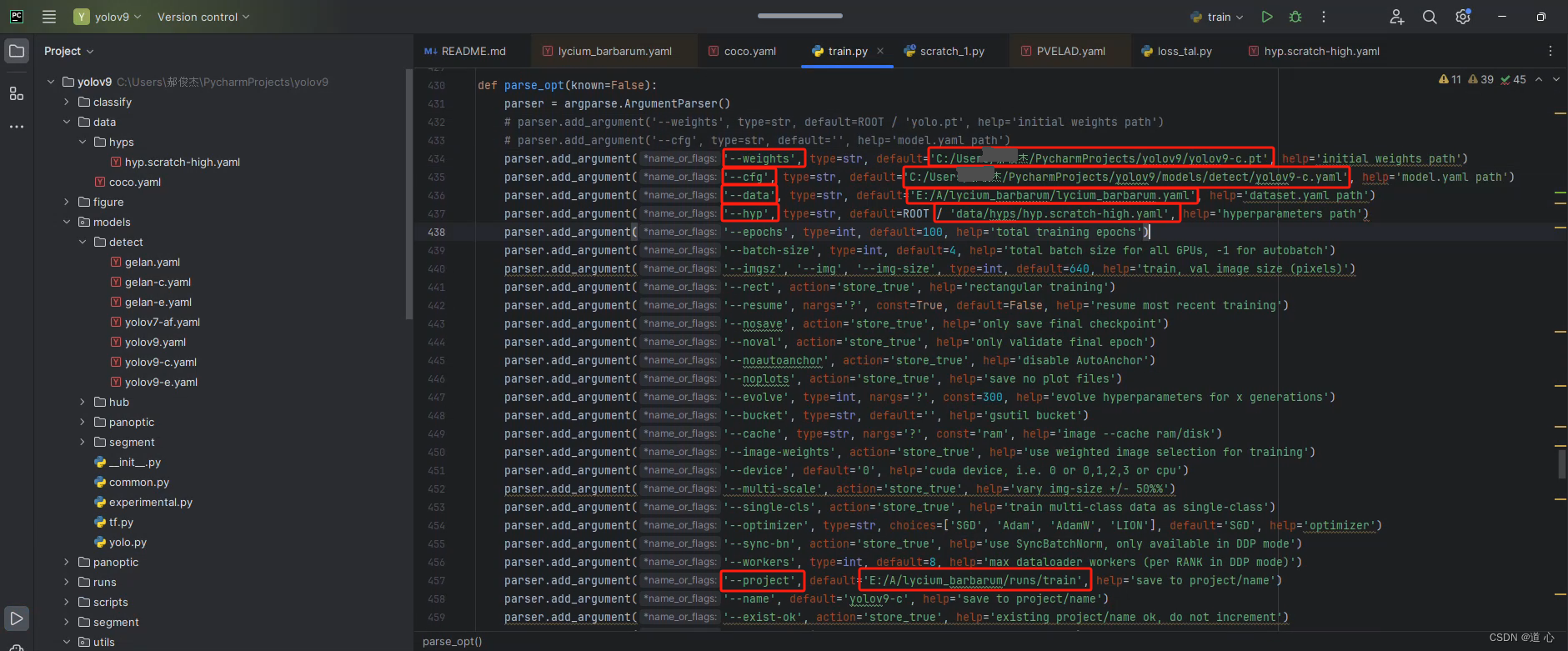
–weights : 此处更改为yolov9-c.pt的绝对路径
–cfg : 此处更改为yolov9-c.yaml的绝对路径
–data : 此处更改为data.yaml的绝对路径 ##上面4-3的data.yaml文件
–hyp : 此处更改为data/hyps/hyp.scratch-high.yaml
原本是data/hyps/hyp.scratch-low.yaml 但该文件内并未找到,,,猜测为YOLOv9作者调试过程中的小疏忽
–project : 此处更改为训练后文件保存的绝对路径
个人爱好,放源文件夹下太占地方,可不更改
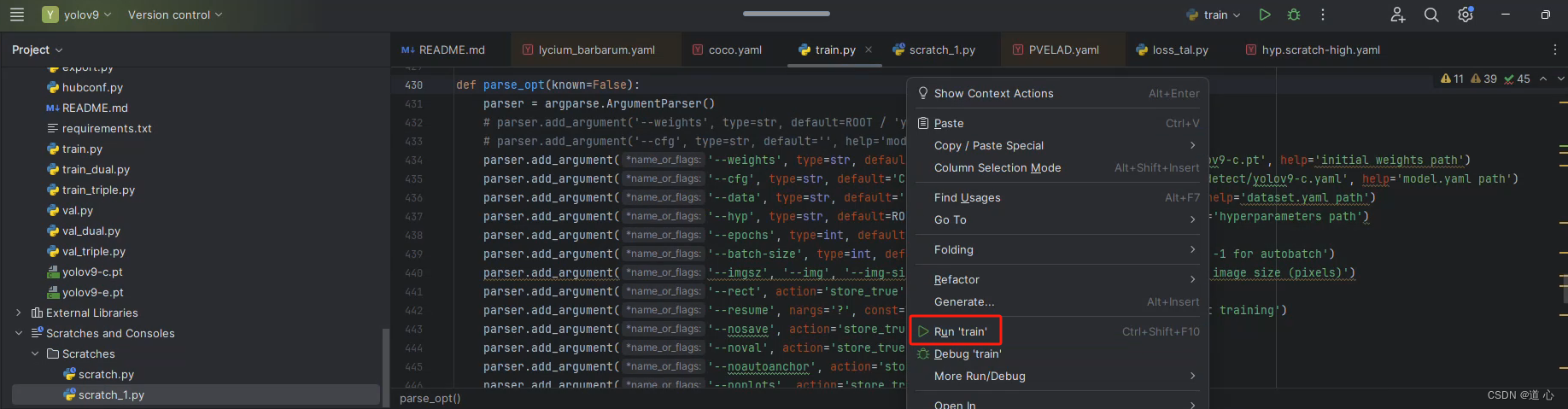
最后开启正式训练:
在trian.py文件下右键【run ‘train’】
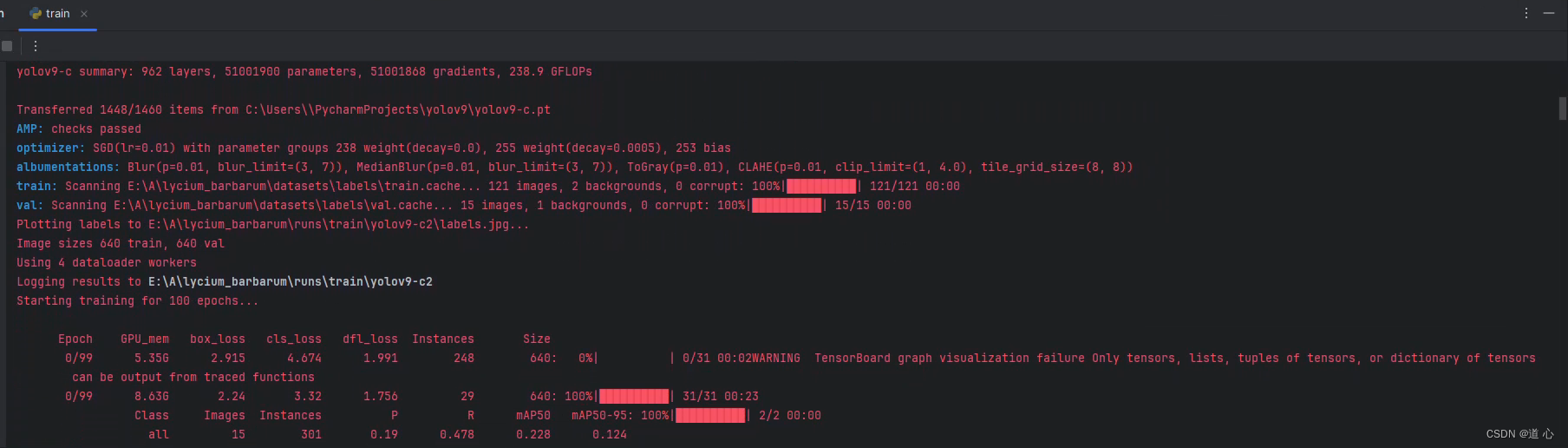
运行正常
六、报错解决
attributeerror: ‘FreeTypeFont‘ object has no attribute ‘getsize‘
这是因为安装了新版本的 Pillow (10),pip install tf-models-official删除了该getsize 功能,降级到 Pillow 9.0.1 解决了该问题
# 降低版本
pip install Pillow==9.0.1
- 1
- 2
如有问题,欢迎大家一起交流,不胜感激!!!

