
- 1Tensorflow入门——训练结果的保存与加载(Keras方式实现)
- 2字符串匹配算法(leetcode)_字符串匹配算法leetcode
- 3中标麒麟V7.0安装(龙芯、昆仑固件)_昆仑固件官网
- 4【编程入门题--二维数组的转置】
- 5【pytorch】nn.linear 中为什么是y=xA^T+b
- 6在git bash执行.sh文件_在gitbash上运行sh
- 7一个产品需求的研发流程是怎样的?
- 8Vi E212: can‘t open file for writing_vi e212: can't open file for writing
- 9Realsense2深度相机的基本操作命令(其实里面很多是ROS基本命令)_infra, infra1, infra2, color, depth,
- 10c/c++:数组指针与指针数组_c++指针数组和数组指针
YOLO系列最新综述从YOLOv1到YOLOv8【2023】_yolov8与物联网有关系吗
赞
踩

论文地址:http://arxiv.org/pdf/2304.00501.pdf
作者:Juan R. Terven 、Diana M. Cordova-Esparaza
以下内容均来自A COMPREHENSIVE REVIEW OF YOLO: FROM YOLOV1 AND BEYOND文章的译版,如翻译有误或不规范请查阅作者原论文。
摘要
YOLO已成为机器人、无人驾驶汽车和视频监控应用的核心实时目标检测系统。我们对YOLO的发展进行了全面的分析,检查了从最初的YOLO到YOLOv8、YOLO-NAS和YOLO with Transformers的每次迭代中的创新和贡献。我们首先描述标准指标和后处理;然后,我们讨论了网络架构的主要变化和每个模型的训练技巧。最后,我们总结了YOLO发展的重要经验教训,并对其未来发展进行了展望,强调了增强实时目标检测系统的潜在研究方向。
1 介绍
实时目标检测已成为众多应用中的关键组成部分,涵盖自动驾驶汽车、机器人、视频监控和增强现实等各个领域。在各种目标检测算法中,YOLO (You Only Look Once)框架以其出色的速度和准确性平衡而脱颖而出,能够快速可靠地识别图像中的目标。自成立以来,YOLO家族经历了多次迭代,每次迭代都建立在以前的版本之上,以解决局限性并提高性能(见图1)。本文旨在全面回顾YOLO框架的发展,从最初的YOLOv1到最新的YOLOv8,阐明每个版本的关键创新、差异和改进。

本文首先探讨了原始YOLO模型的基本概念和体系结构,为YOLO家族的后续发展奠定了基础。接下来,我们将深入研究从YOLOv2到YOLOv8的每个版本中引入的改进和增强。这些改进包括网络设计、损失函数修改、锚盒适应和输入分辨率缩放等各个方面。通过研究这些发展,我们的目标是全面了解YOLO框架的发展及其对目标检测的影响。
除了讨论每个YOLO版本的具体进步之外,本文还强调了在整个框架开发过程中出现的速度和准确性之间的权衡。这强调了在选择最合适的YOLO模型时考虑特定应用程序的上下文和需求的重要性。最后,我们展望了YOLO框架的未来方向,触及了进一步研究和开发的潜在途径,这将影响实时目标检测系统的持续进展。
2 YOLO在不同领域的应用
YOLO的实时目标检测能力在自动驾驶车辆系统中非常宝贵,可以快速识别和跟踪各种物体,如车辆、行人[1,2]、自行车和其他障碍物[3,4,5,6]。这些能力已经应用于许多领域,包括用于监控的视频序列中的动作识别[7][8]、运动分析[9]和人机交互[10]。
YOLO模型已在农业中用于农作物[11,12]、病虫害[13]的检测和分类,协助实现精准农业技术和农业流程自动化。它们也适用于生物识别、安全和面部识别系统中的面部检测任务[14,15]。
在医学领域,YOLO已被用于癌症检测[16,17]、皮肤分割[18]、药丸识别[19],提高了诊断的准确性,提高了治疗的效率。在遥感领域,它已被用于卫星和航空图像中的目标检测和分类,有助于土地利用制图、城市规划和环境监测[20,21,22,23]。
安防系统集成了YOLO模型,用于实时监控和分析视频馈送,从而可以快速发现可疑活动[24]、保持社交距离和检测口罩[25]。这些模型还被应用于表面检测,以检测缺陷和异常,加强制造和生产过程中的质量控制[26,27,28]。
在交通应用中,YOLO模型已被用于车牌检测[29]和交通标志识别[30]等任务,有助于智能交通系统和交通管理解决方案的发展。它们已被用于野生动物检测和监测,以识别濒危物种,用于生物多样性保护和生态系统管理[31]。最后,YOLO已广泛应用于机器人应用[32,33]和无人机目标检测[34,35]。
3 目标检测指标与非最大抑制(NMS)
平均精度(AP),传统上称为平均平均精度(mAP),是评估目标检测模型性能的常用度量。它测量所有类别的平均精度,提供一个单一的值来比较不同的模型。COCO数据集没有区分AP和mAP。在本文的其余部分,我们将把这个度量称为AP。
在YOLOv1和YOLOv2中,用于训练和基准测试的数据集是PASCAL VOC 2007和VOC 2012[36]。然而,从YOLOv3开始,使用的数据集是Microsoft COCO (Common Objects in Context)[37]。对于这些数据集,AP的计算方法不同。下面几节将讨论AP背后的基本原理,并解释如何计算AP。
3.1 AP
AP度量基于精度-召回率(precision-recall)度量,处理多个对象类别,并使用Intersection over Union(IoU)定义积极的预测。
精确度和召回率:精确度衡量模型积极预测的准确性,而召回率衡量模型正确识别的实际积极案例的比例。准确度和召回率之间往往存在权衡;例如,增加检测到的对象的数量(更高的召回率)可能导致更多的误报(更低的精度)。为了考虑这种权衡,AP指标结合了精确率-召回率曲线,该曲线绘制了不同置信度阈值下的精确率和召回率。该指标通过考虑准确度-召回曲线下的面积,提供了对精度和召回率的平衡评估。
处理多个目标类别:目标检测模型必须识别和定位图像中的多个目标类别。AP度量通过分别计算每个类别的平均精度(AP),然后在所有类别中取这些AP的平均值来解决这个问题(这就是为什么它也称为平均平均精度)。这种方法确保对每个类别单独评估模型的性能,为模型的整体性能提供更全面的评估。
IOU:目标检测的目的是通过预测边界框来准确定位图像中的目标。AP度量结合了Union (IoU)交叉度量来评估预测边界框的质量。IoU是预测边界框与地面真值边界框的交集面积与并集面积之比(见图2)。IoU衡量的是地面真值边界框与预测边界框的重叠程度。COCO基准考虑多个IoU阈值来评估模型在不同定位精度水平下的性能。
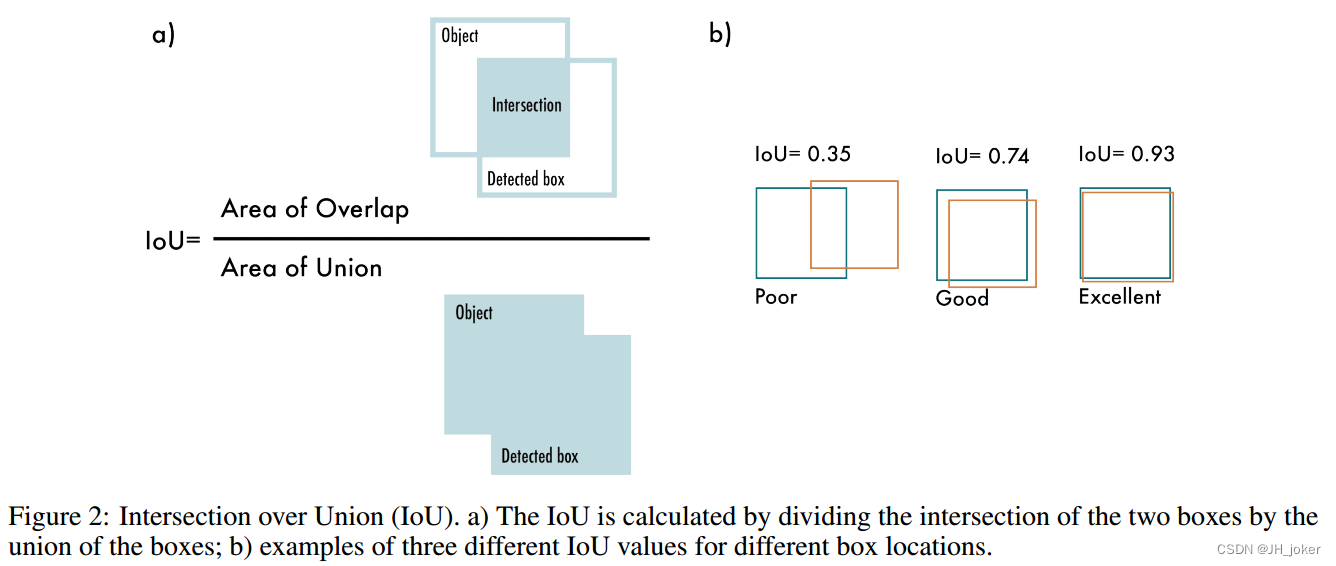
3.2 计算AP
AP在VOC和COCO数据集中的计算方式不同。在本节中,我们将描述如何在每个数据集上计算它。
VOC Dataset
该数据集包括20个对象类别。为了计算VOC中的AP,我们遵循以下步骤:
1. 对于每个类别,通过改变模型预测的置信阈值来计算精确召回曲线。
2. 使用内插的精度-召回率曲线的11点抽样计算每个类别的平均精度(AP)。
3.通过取所有20个类别中AP的平均值来计算最终的平均精度(AP)。
Microsoft COCO Dataset
该数据集包括80个对象类别,并使用更复杂的方法来计算AP。它使用101点插值而不是11点插值,即以0.01的增量计算101个召回阈值的精度,从0到1。此外,AP是通过对多个IoU值(而不仅仅是一个)进行平均来获得的,除了一个称为AP50的通用AP度量,它是单个IoU阈值0.5的AP。在COCO中计算AP的步骤如下:
1. 对于每个类别,通过改变模型预测的置信阈值来计算精确召回曲线。
2. 使用101个召回阈值计算每个类别的平均精度(AP)。
3.计算不同IoU阈值的AP,通常从0.5到0.95,步长为0.05。更高的IoU阈值需要更准确的预测才能被认为是真正的阳性。
4. 对于每个IoU阈值,取所有80个类别的ap的平均值。
5. 最后,通过平均每个IoU阈值计算的AP值来计算总体AP。
AP计算的差异使得很难直接比较两个数据集的目标检测模型的性能。当前的标准使用COCO AP,因为它对模型在不同IoU阈值下的表现进行了更细粒度的评估。
3.3 非最大抑制(NMS)
非最大抑制(NMS)是一种用于目标检测算法的后处理技术,目的是减少重叠边界框的数量,提高整体检测质量。目标检测算法通常会在同一目标周围生成多个具有不同置信度分数的边界框。NMS过滤掉冗余和不相关的边界框,只保留最准确的边界框。算法1描述了这个过程。图3显示了包含多个重叠边界框的对象检测模型的典型输出和NMS后的输出。


我们准备开始描述不同的YOLO模型。
4 YOLO: You Only Look Once
Joseph Redmon等人的YOLO发表于CVPR 2016[38]。它首次提出了一种实时的端到端目标检测方法。YOLO的意思是“你只看一次”,指的是它能够通过一次网络来完成检测任务,而不是以前的方法,要么使用滑动窗口,然后使用分类器,每个图像需要运行数百或数千次,或者更先进的方法,将任务分为两步,其中第一步检测具有对象或区域建议的可能区域,第二步对建议运行分类器。此外,YOLO使用了更直接的输出与Fast R-CNN[39]相反,Fast R-CNN[39]使用两个单独的输出,对概率进行分类,对方框坐标进行回归。
4.1 YOLOv1工作原理
YOLOv1统一了目标检测步骤,同时检测所有的边界框。为了实现这一点,YOLO将输入图像划分为S × S网格,并预测同一类的B个边界框,以及每个网格元素对C个不同类的置信度。每个边界框预测由五个值组成:P c, bx, by, bh, bw,其中P c是框的置信度得分,反映模型对框中包含对象的置信度以及框的准确性。bx和by坐标是相对于网格单元格的框的中心,bh和bw是相对于完整图像的框的高度和宽度。YOLO的输出是S×S×(B×5+C)张量,可选地跟随非最大抑制(NMS)来去除重复检测。
在最初的YOLO论文中,作者使用了包含20个类(C=20)的PASCAL VOC数据集[36];一个7×7的网格(S=7),每个网格元素最多2个类(B = 2),给出7×7×30的输出预测。
图4显示了一个简化的输出向量,考虑了一个3乘3的网格、3个类,每个网格一个类代表8个值。在这个简化的情况下,YOLO的输出将是3 × 3 × 8。
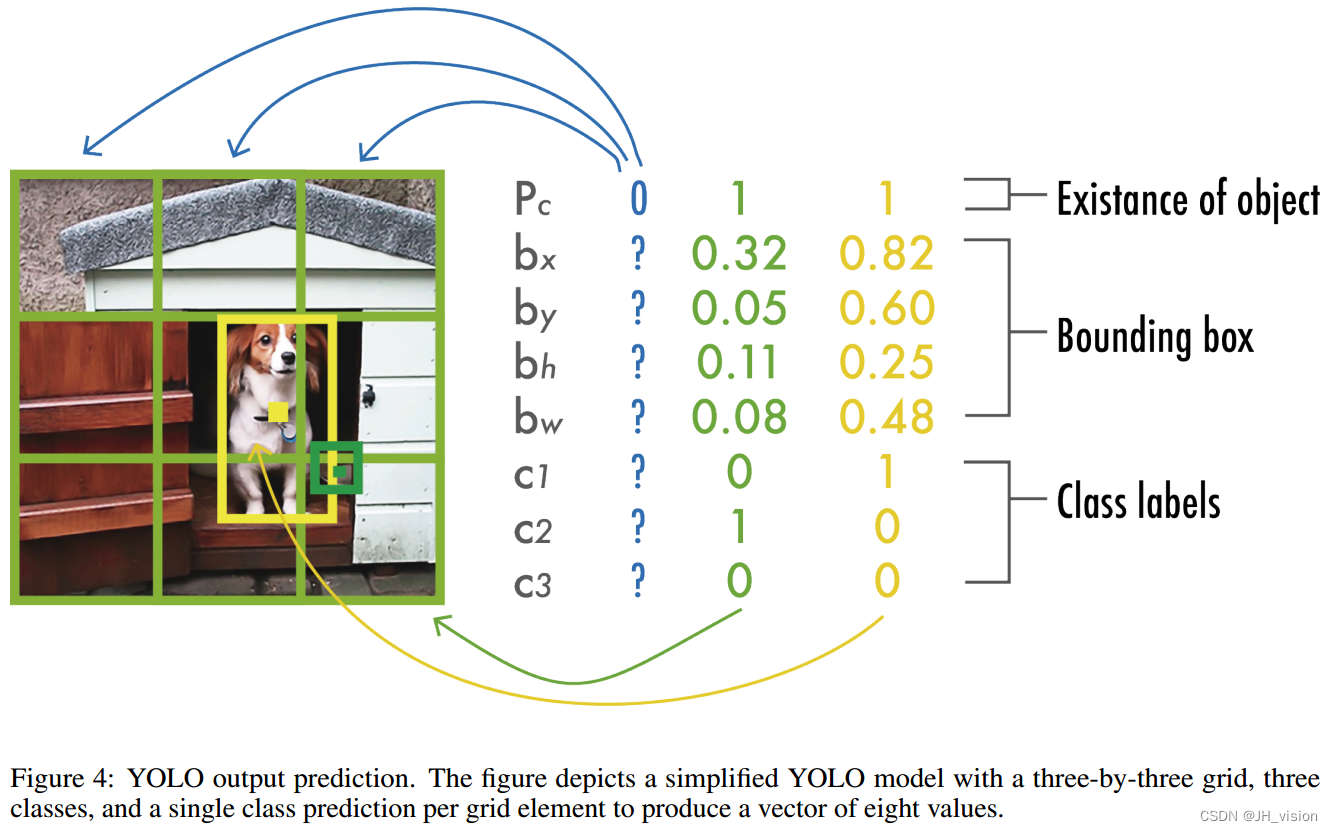
YOLOv1在PASCAL VOC2007数据集上的平均精度(AP)为63.4。
4.2 YOLOv1的架构
YOLOv1架构包括24个卷积层,然后是两个完全连接的层,用于预测边界框坐标和概率。除最后一层使用线性激活函数外,所有层都使用Leaky ReLU激活函数[40]。受GoogLeNet[41]和Network in Network[42]的启发,YOLO使用1 × 1卷积层来减少特征映射的数量,并保持相对较低的参数数量。作为激活层,表1描述了YOLOv1体系结构。作者还介绍了一个更轻的模型,称为Fast YOLO,由9个卷积层组成。
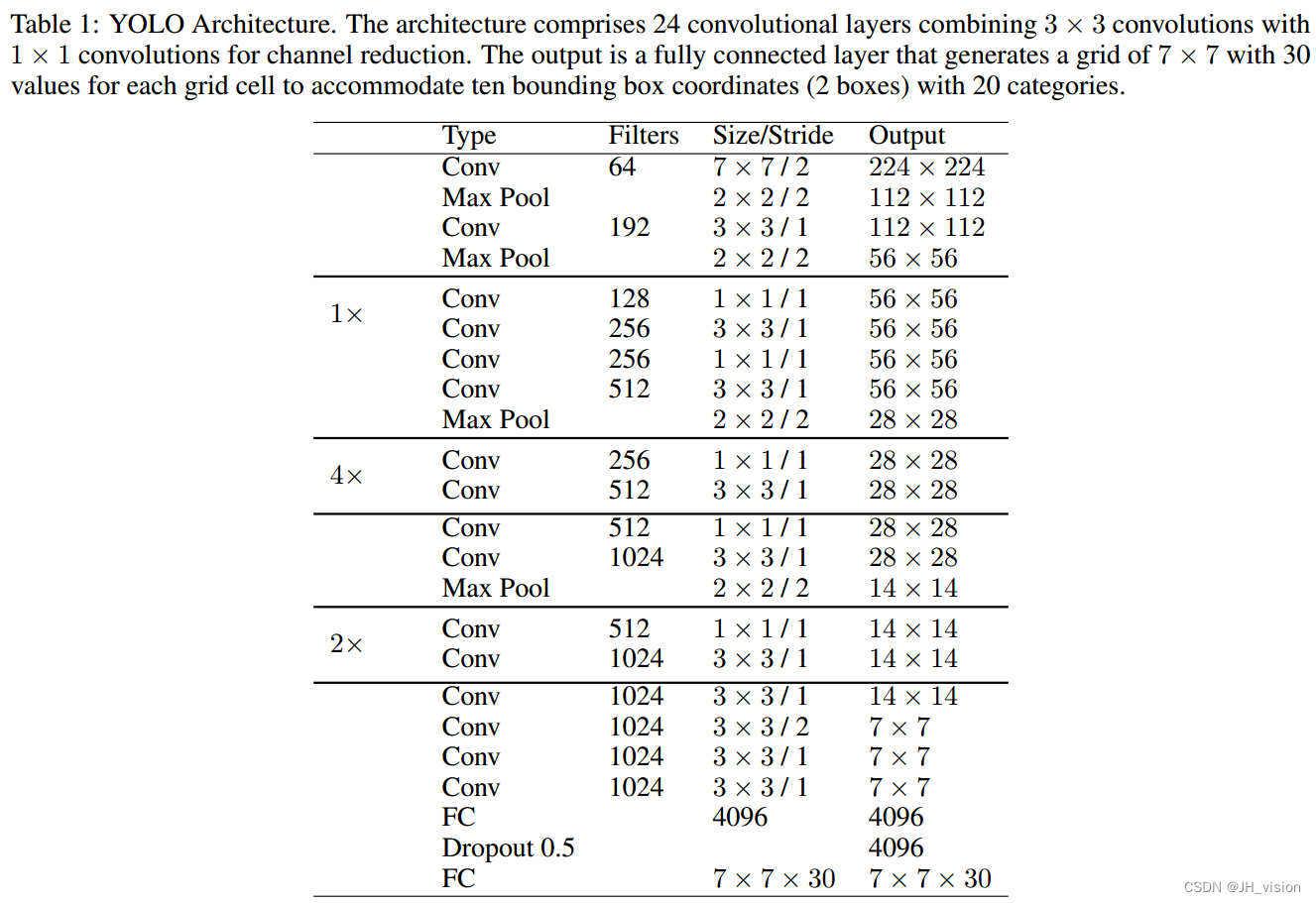
4.3 YOLOv1 训练
作者使用ImageNet数据集以224 × 224的分辨率预训练了YOLO的前20层[43]。然后,他们添加了随机初始化权重在最后四层,并使用PASCAL VOC 2007和VOC 2012数据集[36]以448 × 448的分辨率对模型进行了精细调整,以增加细节,从而更准确地检测目标。
在增强方面,作者使用了最多为输入图像大小 20% 的随机缩放和平移,以及在 HSV 色彩空间中使用上限系数为 1.5 的随机曝光和饱和度。HSV 色彩空间的上限系数为 1.5。
YOLOv1使用了一个由多个和平方误差组成的损失函数,如图5所示。在损失函数中,是给予边界框预测更多重要性的比例因子,
是降低不包含对象的框的重要性的比例因子。
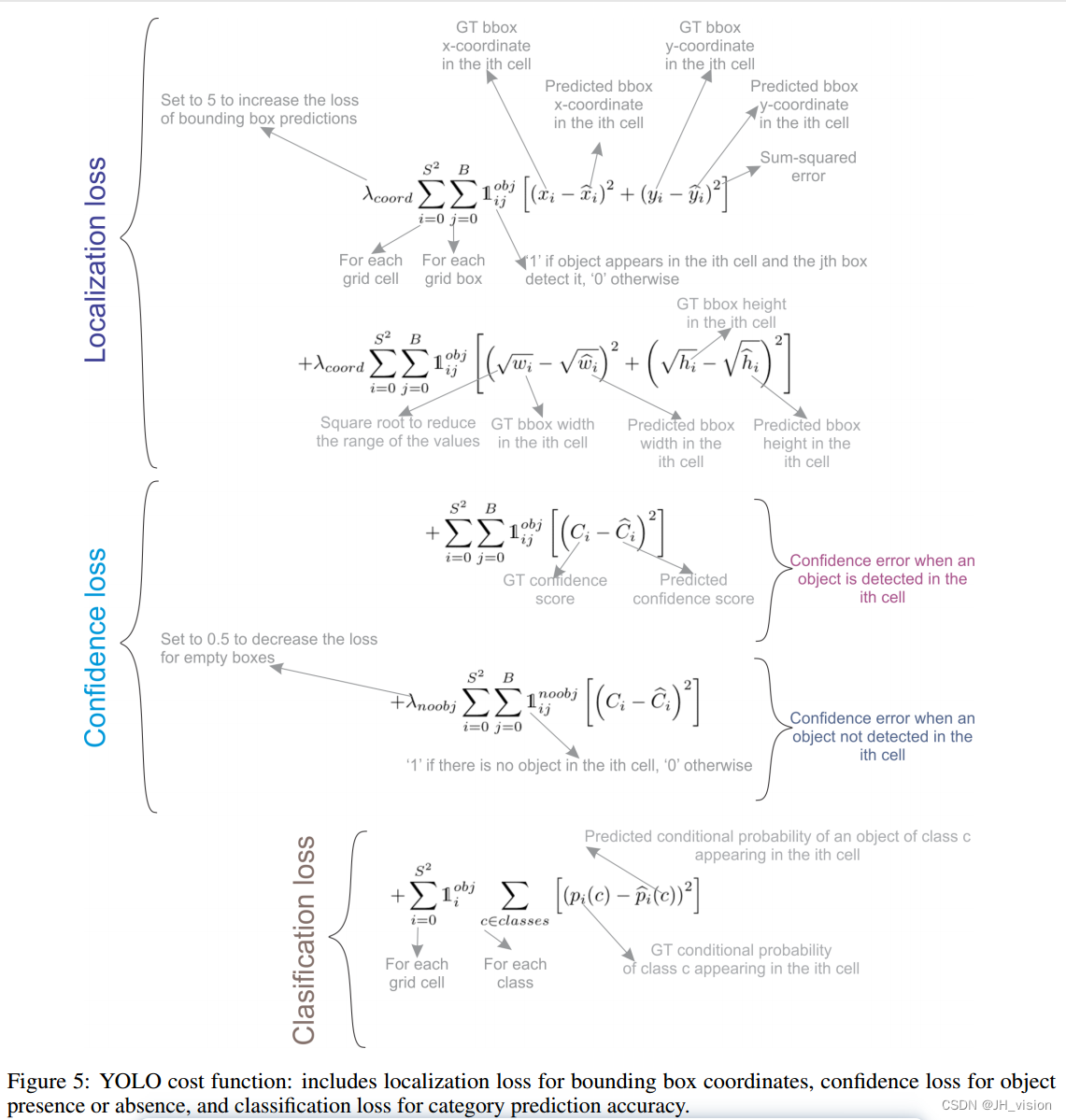
损失的前两项表示局部化损失;它计算预测的边界框位置(x, y)和大小(w, h)中的误差。注意,这些误差仅在包含对象的框中计算(表示)通过,只有在该网格单元中存在对象时才会受到惩罚。第三和第四个损失项表示信心损失;第三项测量在盒子中检测到对象时的置信误差(
),第四项测量在盒子中未检测到对象时的置信误差(
)。由于大多数盒子是空的,这个损失被
项加权。最后的损失分量是分类损失,它仅在对象出现在单元格(
)中时测量每个类别的类别条件概率的平方误差。
4.4 YOLOv1 的优势和局限性
YOLO的简单架构,以及其新颖的全图像单次回归,使其比现有的目标检测器更快,从而实现实时性能。
然而,尽管YOLO的执行速度比任何目标检测器都快,但与Fast R-CNN等最先进的方法相比,定位误差更大[39]。造成这种限制的主要原因有三个:
1. 它最多只能检测到网格单元中两个同类的物体,这限制了它预测附近物体的能力。
2. 它很难预测训练数据中没有出现的长宽比物体。
3. 由于采用了向下采样层从粗略的物体特征中学习。
5 YOLOv2: Better, Faster, and Stronger
YOLOv2由Joseph Redmon和Ali Farhadi在CVPR 2017上发表[44]。它对原来的YOLO进行了一些改进,使其更好,保持相同的速度,也更强大-能够检测9000个类别!改进如下:
1. 所有卷积层的批处理归一化提高了收敛性,并作为正则化器减少过拟合。
2. 高分辨率的分类器。与YOLOv1一样,他们使用ImageNet在224 × 224的分辨率下对模型进行预训练。然而,这一次,他们在ImageNet上调整了10个epoch的模型,分辨率为448 × 448,提高了网络在更高分辨率输入下的性能。
3.完全卷积。他们去掉了密集的层,使用了一个完全卷积的架构。
4. 使用锚框来预测边界框。它们使用一组先验框或锚框,锚框是具有预定义形状的框,用于匹配对象的原型形状,如图6所示。为每个网格单元定义多个锚框,系统预测每个锚框的坐标和类。网络输出的大小与每个网格单元的锚盒数量成正比。
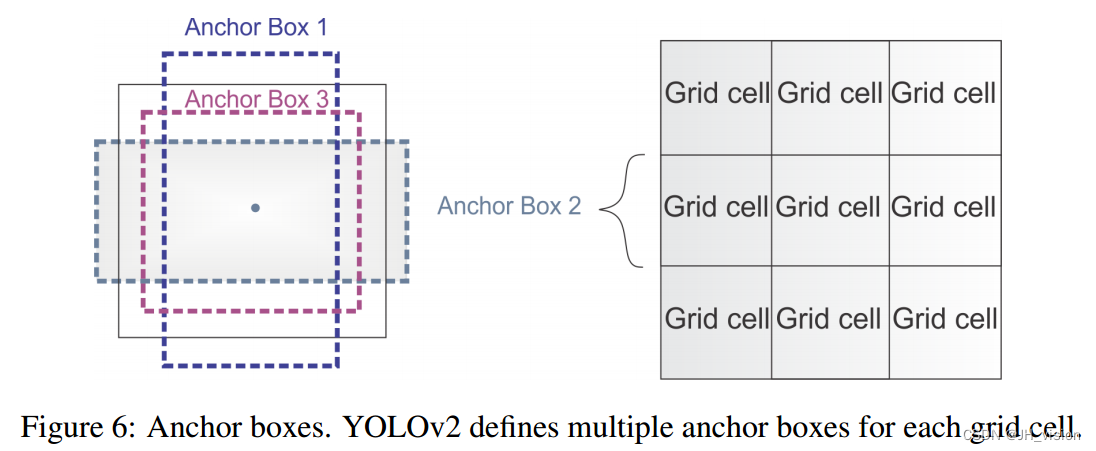
5. 维集群。选择好的先验框有助于网络学习预测更准确的边界框。作者在训练边界盒上运行k-means聚类来找到好的先验。他们选择了五个先前的盒子,在召回率和模型复杂性之间进行了很好的权衡。
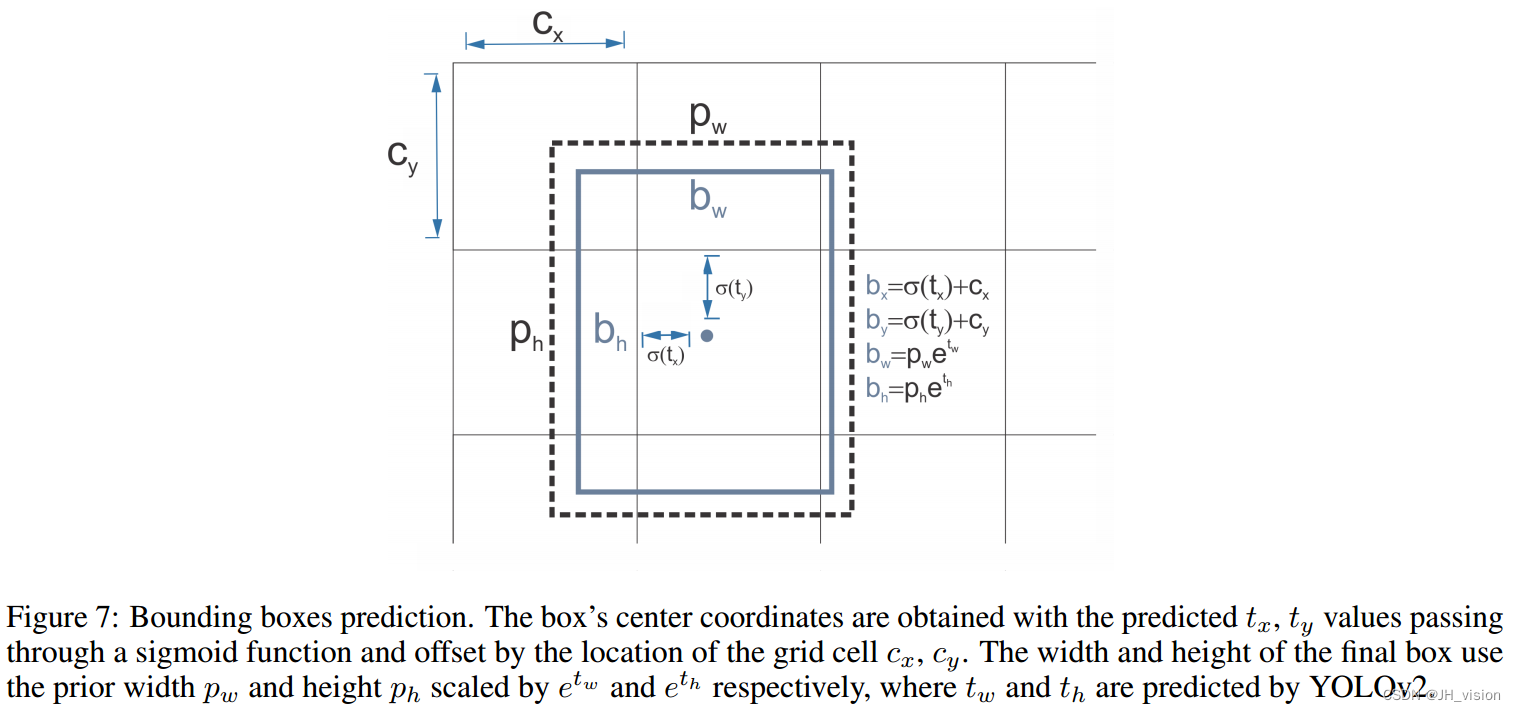
6. 直接位置预测。与其他预测偏移量的方法[45]不同,YOLOv2遵循相同的原理,预测相对于网格单元的位置坐标。网络为每个单元格预测5个边界框,每个边界框有5个值tx、ty、tw、th和to,其中to相当于YOLOv1中的P c,最终得到边界框坐标,如图7所示。
7. Finner-grained特性。与YOLOv1相比,YOLOv2去掉一个池化层,得到416 × 416输入图像的13 × 13输出特征图或网格。YOLOv2还使用了一个通层,该通层采用26 × 26 × 512的特征映射,并通过将相邻的特征堆叠到不同的通道中来重新组织它,而不是通过空间子采样丢失它们。这将生成13 × 13 × 2048个通道维度的特征图,并与低分辨率的13 × 13 × 1024个特征图进行连接,得到13 × 13 × 3072个特征图。有关架构细节,请参见表2。

8. 多尺度的训练。由于YOLOv2不使用完全连接的层,因此输入可以是不同的大小。为了使YOLOv2对不同的输入大小具有鲁棒性,作者随机训练模型,每10批次改变输入大小——从320 × 320到608 × 608。
通过所有这些改进,YOLOv2在PASCAL VOC2007数据集上的平均精度(AP)达到78.6%,而YOLOv1的平均精度为63.4%。
5.1 YOLOv2网络架构
YOLOv2使用的骨干架构称为Darknet-19,包含19个卷积层和5个maxpooling层。与YOLOv1的架构类似,它的灵感来自于Network in Network[42],在3 × 3之间使用1 × 1的卷积来减少参数的数量。此外,如上所述,他们使用批归一化来正则化和帮助收敛。
表2显示了带有目标检测头的整个Darknet-19主干。使用PASCAL VOC数据集时,YOLOv2预测5个边界框,每个边界框有5个值和20个类。
对象分类头将最后四个卷积层替换为一个包含1000个过滤器的单个卷积层,然后是一个全局平均池化层和一个Softmax。
5.2 YOLO9000是YOLOv2的升级版
作者在同一篇文章中介绍了一种训练联合分类和检测的方法。它使用COCO[37]中的检测标记数据学习边界框坐标和ImageNet中的分类数据,以增加可检测的类别数量。在训练过程中,他们将两个数据集结合起来,这样当使用检测训练图像时,它会反向传播检测网络,当使用分类训练图像时,它会反向传播体系结构的分类部分。结果是一个能够检测超过9000个类别的YOLO模型,因此名称为YOLO9000。
6 YOLOv3
YOLOv3[46]由Joseph Redmon和Ali Farhadi于2018年在ArXiv上发表。它包括重大变化和更大的架构,以与最先进的技术相媲美,同时保持实时性能。在下文中,我们描述了与YOLOv2相关的更改。
1. 边界框预测。与YOLOv2一样,该网络为每个边界框tx、ty、tw和th预测四个坐标;然而,这一次,YOLOv3使用逻辑回归预测每个边界框的对象得分。与地面真值重叠度最高的锚框得分为1,其余锚框得分为0。与Faster R-CNN[45]不同,YOLOv3只为每个ground truth对象分配一个锚框。同样,如果没有给对象分配锚盒,只会造成分类损失,不会造成定位损失和置信度损失。
2. 类的预测。他们没有使用softmax进行分类,而是使用二元交叉熵来训练独立的逻辑分类器,并将问题作为多标签分类。这个改变允许给同一个盒子分配多个标签,这可能发生在一些标签重叠的复杂数据集[47]上。例如,同一个对象可以是Person和Man。
3.新的支柱。YOLOv3具有更大的特征提取器,由53个带有残差连接的卷积层组成。第6.1节更详细地描述了该体系结构。
4. 空间金字塔池化(SPP)虽然在论文中没有提到,但作者还在主干中添加了一个修改的SPP块[48],该块连接多个最大池化输出而不进行子采样(stride = 1),每个块具有不同的内核大小k × k,其中k = 1,5,9,13允许更大的接受域。这个版本被称为YOLOv3-spp,是性能最好的版本,AP50提高了2.7%。
5. 多尺度预测。与特征金字塔网络[49]类似,YOLOv3在三个不同的尺度上预测三个盒子。第6.2节详细描述了多尺度预测机制。
6. 边界框先验。与YOLOv2一样,作者也使用k-means来确定锚框的边界框先验。不同之处在于,在YOLOv2中,他们为每个单元格总共使用了五个先验框,而在YOLOv3中,他们为三个不同的尺度使用了三个先验框。
6.1 YOLOv3 网络架构
YOLOv3中呈现的架构主干称为Darknet-53。它用跨行卷积替换了所有的最大池化层,并添加了剩余连接。总的来说,它包含53个卷积层。图8显示了体系结构的细节。
Darknet-53骨干网获得与ResNet-152相当的Top-1和Top-5精度,但几乎快了2倍。

6.2 YOLOv3多尺度预测
除了更大的架构外,YOLOv3的一个基本特征是多尺度预测,即在多个网格大小下进行预测。这有助于获得更精细的细节框,并显着提高了对小物体的预测,这是以前版本的YOLO的主要弱点之一。
图9所示的多尺度检测架构的工作原理如下:标记为y1的第一个输出相当于YOLOv2的输出,其中一个13 × 13的网格定义了输出。第二个输出y2是将Darknet-53的(Res × 4)之后的输出与(Res × 8)之后的输出拼接而成。feature map的大小不同,分别是13 × 13和26 × 26,所以在拼接之前需要进行上采样操作。最后,使用上采样操作,第三个输出y3将26 × 26特征映射与52 × 52特征映射连接起来。
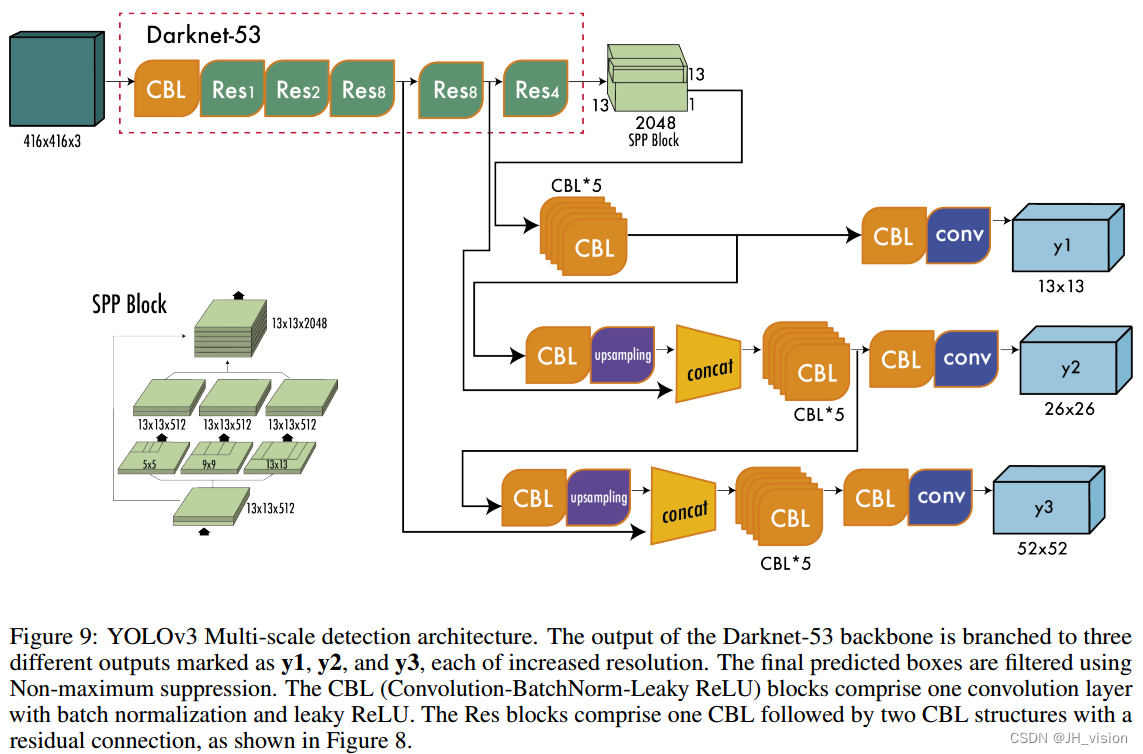
对于具有80个类别的COCO数据集,每个尺度提供一个形状为N ×N ×[3x(4+1+80)]的输出张量,其中N ×N为特征图(或网格单元)的大小,3表示每个单元的框数,4+1包括四个坐标和对象得分。
6.3 YOLOv3结论
当YOLOv3发布时,目标检测的基准已经从PASCAL VOC改为Microsoft COCO[37]。因此,从这里开始,所有的yolo都在MS COCO数据集中进行评估。在20 FPS下,YOLOv3-spp的平均精度AP为36.2%,AP50为60.6%,达到了当时最先进的水平,速度提高了2倍。
7 Backbone, Neck, and Head
此时,目标探测器的结构开始被描述为三个部分:脊柱、颈部和头部。图10显示了一个高级的脊柱、颈部和头部图。
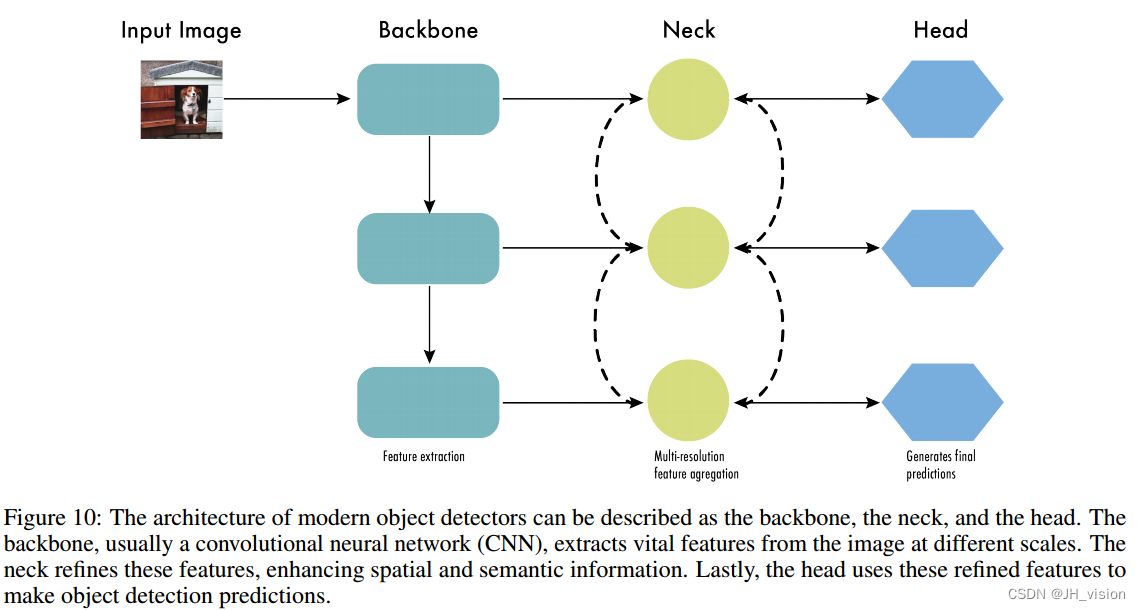
主干负责从输入图像中提取有用的特征。它通常是在大规模图像分类任务上训练的卷积神经网络(CNN),例如ImageNet。主干捕获不同尺度的分层特征,较低级的特征(如边缘和纹理)在较早的层中提取,较高级的特征(如对象部分和语义信息)在较深的层中提取。
颈部是连接脊柱和头部的中间部分。它对主干提取的特征进行聚合和细化,往往侧重于增强不同尺度的空间和语义信息。颈部可能包括额外的卷积层、特征金字塔网络(FPN)[49]或其他机制来改善特征的表示。
头部是物体检测器的最终组成部分;它负责根据脊柱和颈部提供的特征做出预测。它通常由一个或多个特定于任务的子网组成,这些子网执行分类、定位以及最近的实例分割和姿态估计。头部处理颈部提供的特征,为每个候选对象生成预测。最后,一个后处理步骤,如非最大抑制(NMS),过滤掉重叠的预测,只保留最可靠的检测。
在YOLO模型的其余部分中,我们将使用脊柱、颈部和头来描述架构。
8 YOLOv4
两年过去了,并没有新的YOLO版本。直到2020年4月,Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao在ArXiv发表了YOLOv4的论文[50]。起初,不同的作者提出了一个新的“官方”版本的YOLO,这让人感到奇怪;然而,yolo4保持了相同的YOLO理念——实时、开源、单阶段和网络框架——并且改进是如此令人满意,社区迅速接受了这个版本作为官方的yolo4。
YOLOv4试图找到最佳的平衡,尝试了许多被归类为Bag-of-freebies和bag-of-specials的变化。Bag-of-freebies是指只改变训练策略,增加训练成本,但不增加推理时间的方法,最常见的是数据增强。另一方面,bag-of-specials是稍微增加推理成本但显著提高准确率的方法。这些方法的例子包括扩大感受野[48,51,52],结合特征[53,49,54,55]和后处理[56,40,57,58]等。
我们将YOLOv4的主要变化总结为以下几点:
- 带有特色包(BoS)集成的增强架构。作者尝试了多种骨干网架构,如ResNeXt50[59]、EfficientNet-B3[60]和Darknet-53。性能最好的架构是对Darknet-53的修改,采用跨级部分连接(CSPNet)[61],以Mish激活函数[57]作为主干(见图11)。对于颈部,他们使用了来自YOLOv3- SPP的修改版本的空间金字塔池(SPP)[48]和与YOLOv3一样的多尺度预测,但使用了修改版本的路径聚合网络(PANet)[62]而不是FPN以及修改的空间注意模块(SAM)[63]。最后,对于探测头,他们使用YOLOv3中的锚。因此,将模型命名为CSPDarknet53-PANet-SPP。添加到Darknet-53中的跨级部分连接(CSP)有助于减少模型的计算量,同时保持相同的精度。在YOLOv3-spp中,SPP块在不影响推理速度的情况下增加了接受野。PANet的修改版本将这些特性连接起来,而不是像在PANet的原始文件中那样添加它们。
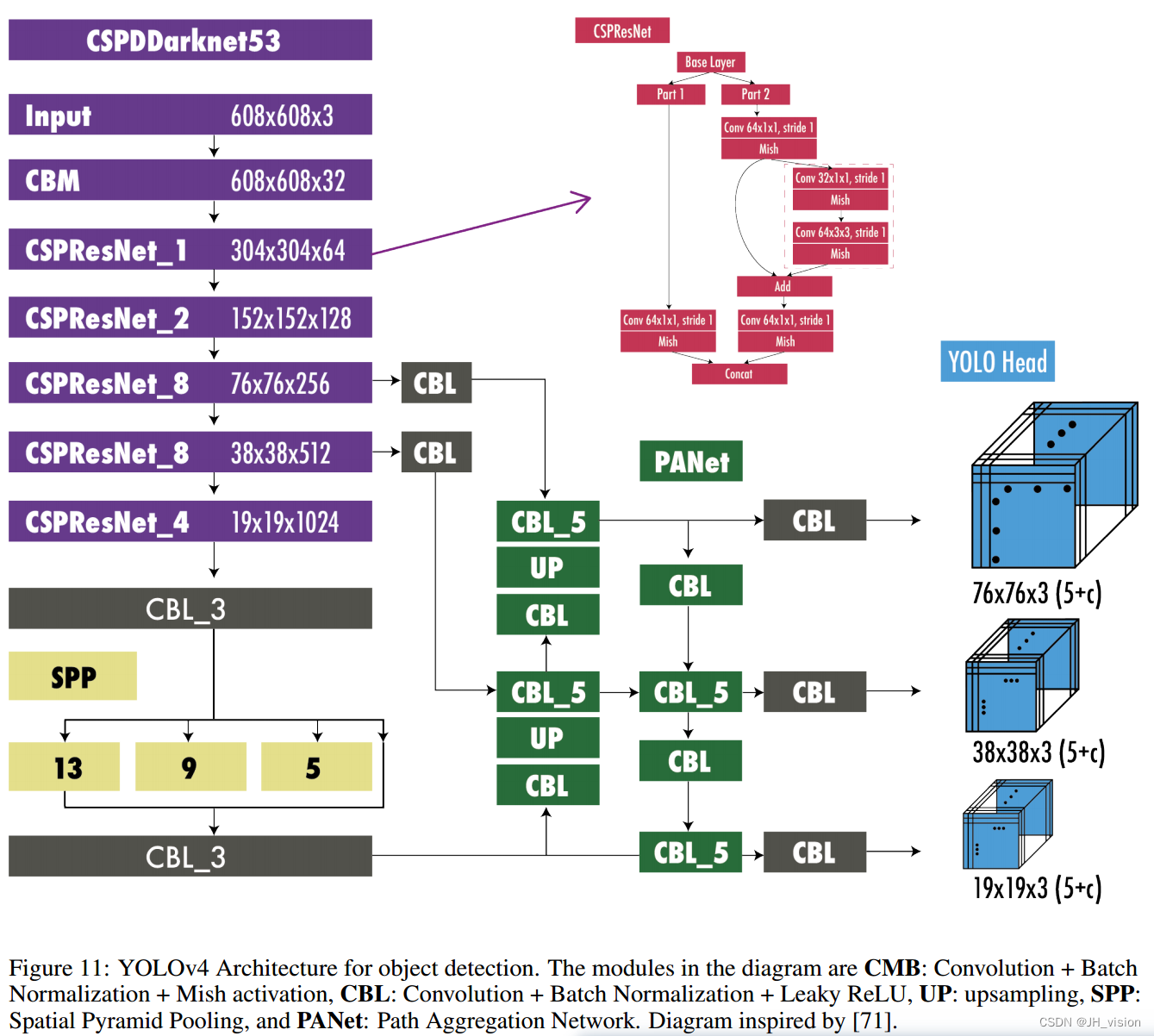
- 整合免费赠品袋(BoF)的高级培训方法。除了常规的增强,如随机亮度、对比度、缩放、裁剪、翻转和旋转,作者还实现了马赛克增强,将四张图像合并为一张图像,允许检测其通常上下文之外的对象,并减少了批量规范化对大型迷你批大小的需求。对于正则化,他们使用DropBlock[64]作为Dropout[65]的替代品,但用于卷积神经网络以及类标签平滑[66,67]。对于检测器,他们增加了CIoU损耗[68]和Cross mini-bath normalization (CmBN),以便从整个批次收集统计数据,而不是像常规批次归一化那样从单个小批次收集统计数据[69]。
- 自我对抗训练(SAT)。为了使模型对扰动更具鲁棒性,对输入图像执行对抗性攻击,以创建一个欺骗,即地面真实对象不在图像中,但保持原始标签以检测正确的对象。
- 遗传算法的超参数优化。为了找到用于训练的最优超参数,他们在前10%的周期中使用遗传算法,并使用余弦退火调度器[70]来改变训练期间的学习率。它开始缓慢地降低学习率,然后在训练过程中快速降低,最后略有降低。
表3列出了骨干网和检测器的bof和bof的最终选择。

在MS COCO数据集测试开发2017上进行评估,YOLOv4在NVIDIA V100上以超过50 FPS的速度实现了43.5%的AP和65.7%的AP50。
9 YOLOv5
YOLOv5[72]于2020年由Ultralytics的创始人兼首席执行官Glen Jocher在YOLOv4发布几个月后发布。它使用了YOLOv4部分中描述的许多改进,但在Pytorch而不是Darknet中开发。YOLOv5采用了一种名为AutoAnchor的Ultralytics算法。这个预训练工具检查和调整锚框,如果它们不适合数据集和训练设置,比如图像大小。它首先对数据集标签应用k-means函数来生成遗传进化(GE)算法的初始条件。然后,GE算法使用CIoU损失[68]和最佳可能召回(Best Possible Recall)作为适应度函数,默认在1000代以上进化这些锚。图12显示了YOLOv5的详细体系结构。

9.1 YOLOv5骨干网络
主干是一个改进的CSPDarknet53,从一个Stem开始,一个具有大窗口大小的跨行卷积层,以减少内存和计算成本;然后是卷积层,从输入图像提取相关特征。SPPF(空间金字塔池化快速)层和后续的卷积层处理不同尺度的特征,而上样层增加了特征图的分辨率。SPPF层的目的是通过将不同尺度的特征池化成固定大小的特征映射来加快网络的计算速度。每次卷积之后是批归一化(batch normalization, BN)和SiLU激活[73]。颈部使用SPPF和改良的CSP-PAN,而头部则类似于YOLOv3。
YOLOv5使用了几种增强功能,如马赛克、复制粘贴[74]、随机仿射、MixUp[75]、HSV增强、随机水平翻转以及来自albumentations包的其他增强功能[76]。它还提高了网格的灵敏度,使其对失控梯度更稳定。
YOLOv5提供了5个缩放版本:YOLOv5n(纳米)、YOLOv5s(小)、YOLOv5m(中)、YOLOv5l(大)和YOLOv5x(超大),其中卷积模块的宽度和深度不同,以适应特定的应用和硬件要求。例如,YOLOv5n和YOLOv5s是针对低资源设备的轻量级模型,而YOLOv5x则针对高性能进行了优化,尽管是以牺牲速度为代价。
撰写本文时发布的YOLOv5版本是v7.0,其中包括能够分类和实例分割的YOLOv5版本。
YOLOv5是开源的,由Ultralytics积极维护,有250多个贡献者,并且经常有新的改进。YOLOv5易于使用、训练和部署。Ultralytics提供iOS和Android的移动版本,以及许多标签、培训和部署的集成。
在MS COCO数据集test-dev 2017上进行评估,YOLOv5x在图像尺寸为640像素时实现了50.7%的AP。使用32个批处理大小,它可以在NVIDIA V100上实现200 FPS的速度。使用更大的输入大小(1536像素)和测试时间增量(TTA), YOLOv5实现了55.8%的AP。
10 Scaled-YOLOv4
在YOLOv4发布一年后,同一作者在CVPR 2021上提出了Scaled-YOLOv4[79]。与YOLOv4不同的是,Scaled YOLOv4是在Pytorch而不是Darknet中开发的。主要的新颖之处是引入了按比例放大和按比例缩小的技术。扩大规模意味着以较低的速度为代价来提高准确性;另一方面,按比例缩小需要生成一个以牺牲准确性为代价提高速度的模型。此外,按比例缩小的模型需要更少的计算能力,并且可以在嵌入式系统上运行。
这个按比例缩小的架构被称为YOLOv4-tiny;它是为低端gpu设计的,可以在Jetson TX2上运行46 FPS或在RTX2080Ti上运行440 FPS,在MS COCO上实现22%的AP。
按比例扩大的模型体系结构称为YOLOv4-large,其中包括三种不同的尺寸P5、P6和P7。该架构是为云GPU设计的,并实现了最先进的性能,超过了所有以前的模型[80,81,82],在MS COCO上具有56%的AP。
11 YOLOR
YOLOR[83]由YOLOv4的同一个研究小组于2021年5月在ArXiv上发表。它代表You Only Learn One Representation。在本文中,作者采用了一种不同的方法;他们开发了一种多任务学习方法,旨在通过学习一般表示和使用子网络创建任务特定表示来为各种任务(例如,分类,检测,姿态估计)创建单个模型。鉴于传统的联合学习方法通常会导致次优特征生成,YOLOR旨在通过对神经网络的隐式知识进行编码以应用于多个任务来克服这一问题,类似于人类如何利用过去的经验来解决新问题。结果表明,在神经网络中引入隐式知识对所有任务都有好处。
在MS COCO数据集测试开发2017上进行评估,在NVIDIA V100上30 FPS下,YOLOR的AP为55.4%,AP50为73.3%。
12 YOLOX
YOLOX[84]由旷视科技于2021年7月在ArXiv上发表。在Pytorch中开发并使用来自Ultralytics的YOLOV3作为起点,它有五个主要的变化:无锚点架构,多个阳性,解耦头部,高级标签分配和强增强。它在2021年取得了最先进的成绩,在速度和精度之间取得了最佳平衡,特斯拉V100的AP为50.1%,FPS为68.9%。下面,我们将介绍YOLOX相对于YOLOv3的五个主要变化:
- Anchor-free。自YOLOv2以来,所有后续的YOLO版本都是基于锚点的检测器。YOLOX的灵感来自于无锚点的最先进的目标探测器,如CornerNet[85]、CenterNet[86]和FCOS[87],它回归到无锚点的架构,简化了训练和解码过程。与YOLOv3基线相比,无锚点使AP增加了0.9个点。
- 多积极的方面。为了弥补锚点缺失造成的巨大不平衡,作者使用中心抽样[87],他们将中心3 × 3的区域指定为正区域。这种方法使AP提高了2.1分。
- 解耦。文献[88,89]表明,分类置信度和定位精度之间可能存在不一致。因此,YOLOX将两者分为两个头(如图13所示),一个用于分类任务,另一个用于回归任务,将AP提高了1.1点,加快了模型收敛速度。
- 高级标签分配。文献[90]表明,当多个物体的盒子重叠时,地面真值标签分配可能存在歧义,并将分配过程制定为最优传输(OT)问题。YOLOX受到这项工作的启发,提出了一个简化的版本,叫做simOTA。这个改动使AP增加了2.3点。
- 强大的扩增。YOLOX使用MixUP[75]和Mosaic增强。作者发现,使用这些增强后,ImageNet预训练不再有益。强大的增强使AP增加2.4点。

13 YOLOv6
YOLOv6[91]由美团视觉AI部门于2022年9月在ArXiv上发表。该网络设计由一个具有RepVGG或CSPStackRep块的高效主干网、一个PAN拓扑颈和一个具有混合信道策略的高效解耦头组成。此外,本文还介绍了使用训练后量化和通道蒸馏的增强量化技术,从而实现更快,更准确的检测器。总体而言,YOLOv6在精度和速度指标上优于以前最先进的型号,如YOLOv5, YOLOX和PP-YOLOE。
图14显示了YOLOv6的详细体系结构。
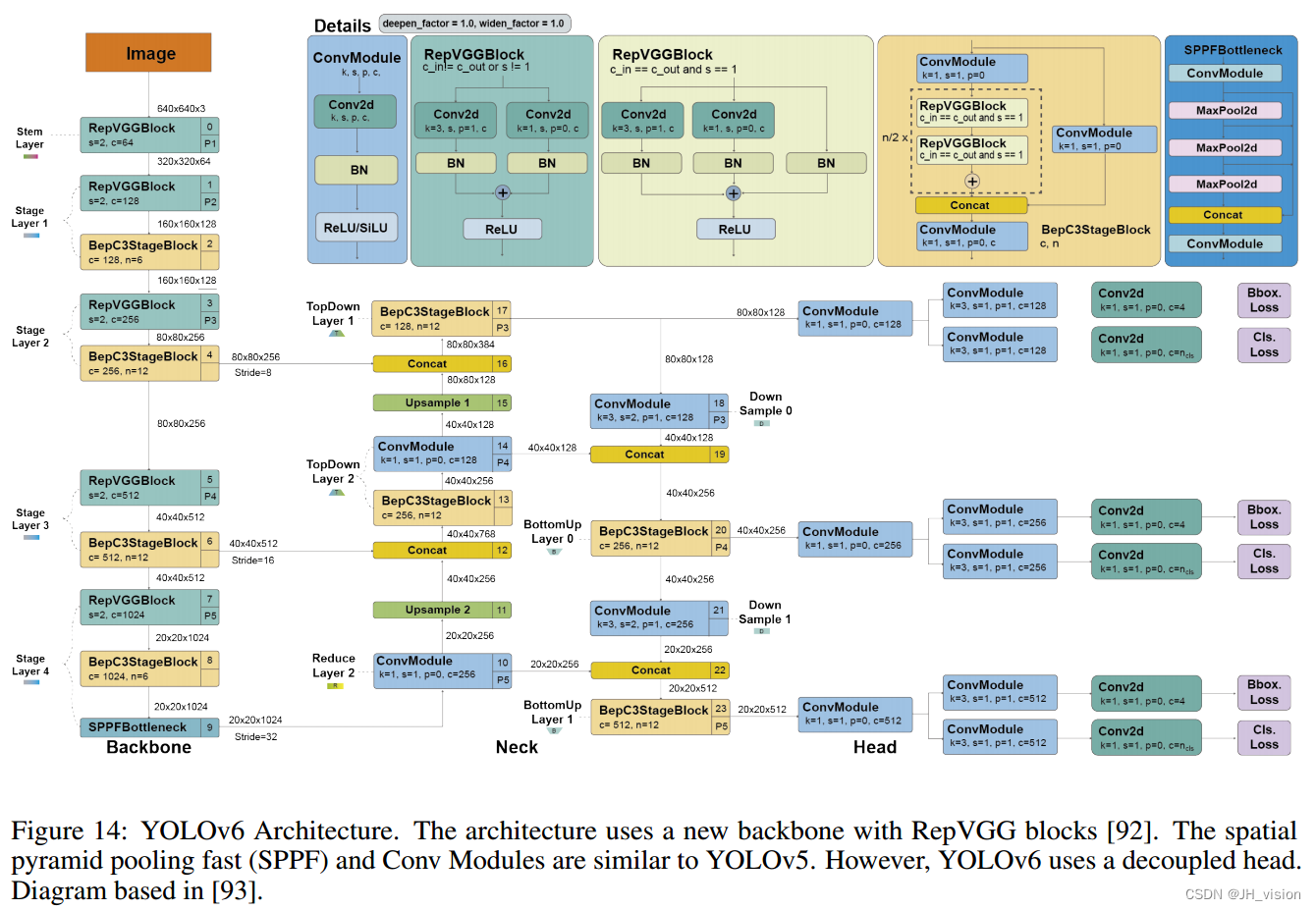
该模型的主要新颖之处总结如下:
- 一种基于RepVGG[92]的新型骨干网,称为EfficientRep,它比以前的YOLO骨干网使用更高的并行性。对于颈部,他们使用PAN[62]和RepBlocks[92]或CSPStackRep[61] block进行增强。继YOLOX之后,他们开发了一个高效的分离头。
- 使用tod[94]中引入的任务对齐学习方法进行标签分配。
- 新的分类和回归损失。他们使用了变焦损失分类[95]和SIoU [96]/GIoU[97]回归损失。
- 回归和分类任务的自蒸馏策略。
- 一种使用RepOptimizer[98]和通道式蒸馏[99]的检测量化方案,有助于实现更快的检测器。
作者提供了从YOLOv6-N到YOLOv6-L6的八个缩放模型。在MS COCO数据集test-dev 2017上进行评估,最大的模型在NVIDIA Tesla T4上以29 FPS左右的速度实现了57.2%的AP。
14 YOLOv7
YOLOv7[100]于2022年7月由YOLOv4和YOLOR的同一作者发表在ArXiv上。当时,它在速度和精度上超过了所有已知的物体探测器,在5 FPS到160 FPS的范围内。与YOLOv4一样,它只使用MS COCO数据集进行训练,没有预先训练主干。YOLOv7提出了几个架构变化和一系列免费赠品,在不影响推理速度的情况下提高了准确性,只影响了训练时间。
图15显示了YOLOv7的详细体系结构。
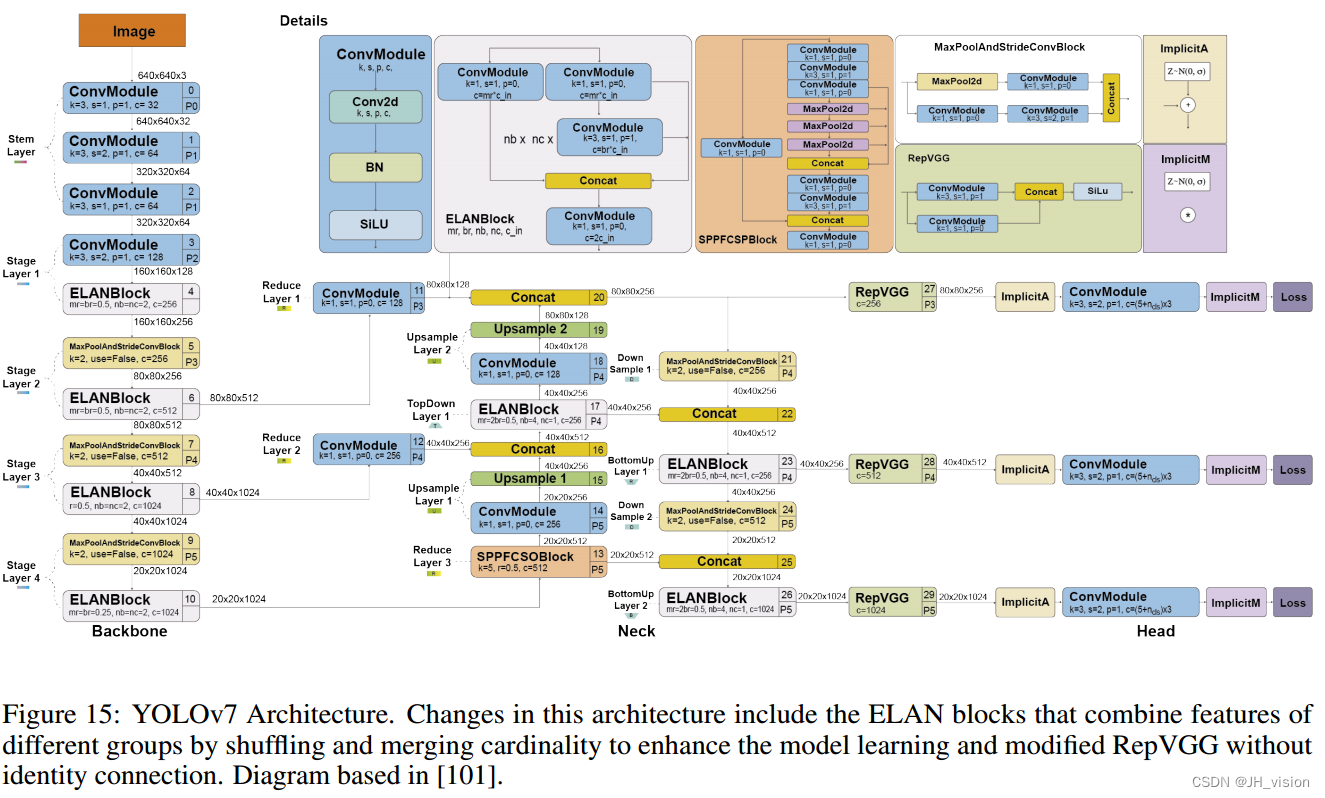
YOLOv7的架构变化如下:
- 扩展高效层聚合网络(E-ELAN)。ELAN[102]是一种策略,通过控制最短最长的梯度路径,允许深度模型更有效地学习和收敛。YOLOv7提出的E-ELAN适用于具有无限堆叠计算块的模型。E-ELAN通过洗牌和合并基数来结合不同群体的特征,在不破坏原有梯度路径的情况下增强网络的学习能力。
- 基于连接的模型的模型缩放。缩放通过调整模型的某些属性来生成不同大小的模型。YOLOv7的体系结构是基于串联的体系结构,其中标准缩放技术(如深度缩放)会导致过渡层的输入通道和输出通道之间的比率变化,从而导致模型的硬件使用减少。YOLOv7提出了一种新的基于串联的模型缩放策略,该策略将块的深度和宽度以相同的因子进行缩放,以保持模型的最优结构。
在YOLOv7中使用的免费包包括:
- 计划的重新参数化卷积。与YOLOv6一样,YOLOv7的架构也受到了重参数化卷积(RepConv)的启发[92]。然而,他们发现RepConv中的身份连接破坏ResNet[53]中的残留和DenseNet[103]中的连接。出于这个原因,他们删除了身份连接并将其称为RepConvN。
- 粗标签分配辅助头和细标签分配领导头。组长负责最终产出,副组长协助培训。
- 批量规范化的转换bn激活。这将批归一化的均值和方差集成到推理阶段卷积层的偏差和权重中。
- 在YOLOR中启发的隐性知识[83]。
- 指数移动平均作为最终的推理模型。
14.1 与YOLOv4和YOLOR的比较
在本节中,我们将重点介绍YOLOv7与由同一作者开发的以前的YOLO模型相比的增强。
与YOLOv4相比,YOLOv7的参数减少了75%,计算量减少了36%,同时平均精度(AP)提高了1.5%。
与YOLOv4-tiny相比,YOLOv7-tiny在保持相同AP的情况下,分别减少了39%和49%的参数和计算量。
最后,与YOLOR相比,YOLOv7分别减少了43%和15%的参数数量和计算量,同时AP略有增加0.4%。
在MS COCO数据集test-dev 2017上进行评估,YOLOv7-E6在NVIDIA V100上以50 FPS的速度,以1280像素的输入大小实现了55.9%的AP和73.5%的AP50。
15 DAMO-YOLO
DAMO-YOLO[104]由阿里巴巴集团于2022年11月在ArXiv上发表。DAMO-YOLO受到当前技术的启发,包括以下内容:
- 神经结构搜索(NAS)。他们使用阿里巴巴开发的MAE-NAS[105]方法自动找到高效的架构。
- 大脖子。受GiraffeDet[106]、CSPNet[61]和ELAN[102]的启发,作者设计了一种可以实时工作的颈部,称为Efficient-RepGFPN。
- 一个小脑袋。作者发现,大颈和小颈的性能更好,他们只留下一个线性层用于分类,一个用于回归。他们称这种方法为零头。
- aliignedota标签分配。动态标签分配方法,如OTA[90]和ood[94],由于其相对于静态方法的显著改进而受到欢迎。然而,分类和回归之间的不一致仍然是一个问题,部分原因是分类和回归损失之间的不平衡。为了解决这一问题,他们的AlignOTA方法将焦损失[81]引入到分类成本中,并使用预测和地面真值盒的IoU作为软标签,可以为每个目标选择对齐的样本,从全局角度解决问题。
- 知识蒸馏。他们提出的策略包括两个阶段:第一阶段是教师指导学生,第二阶段是学生自主微调。此外,他们在蒸馏方法中加入了两个增强功能:Align模块,它使学生的特征与教师的特征具有相同的分辨率,以及Channel-wise Dynamic Temperature,它使教师和学生的特征标准化,以减少实际值差异的影响。
作者生成了名为DAMO-YOLO-Tiny/Small/Medium的缩放模型,最佳模型在NVIDIA V100上以233 FPS的速度实现了50.0%的AP。
16 YOLOv8
YOLOv8[107]于2023年1月由开发YOLOv5的公司Ultralytics发布。YOLOv8提供了5个缩放版本:YOLOv8n (nano)、YOLOv8s (small)、YOLOv8m (medium)、YOLOv8l (large)和YOLOv8x(超大)。YOLOv8支持多种视觉任务,如对象检测,分割,姿态估计,跟踪和分类。
16.1 YOLOv8架构
图16显示了YOLOv8的详细体系结构。YOLOv8使用与YOLOv5类似的主干,只是在CSPLayer上做了一些更改,现在称为C2f模块。C2f模块(具有两个卷积的跨阶段部分瓶颈)将高级特征与上下文信息相结合,以提高检测精度。

YOLOv8使用具有解耦头部的无锚模型来独立处理对象、分类和回归任务。这种设计允许每个分支专注于自己的任务,并提高模型的整体准确性。在YOLOv8的输出层中,他们使用sigmoid函数作为对象得分的激活函数,表示边界框中包含对象的概率。它使用softmax函数表示类概率,表示对象属于每个可能类的概率。
YOLOv8使用CIoU[68]和DFL[108]损失函数表示边界盒损失,使用二元交叉熵表示分类损失。这些损失提高了目标检测性能,特别是在处理较小的目标时。
YOLOv8还提供了一个语义分割模型,称为YOLOv8- seg模型。主干是CSPDarknet53特征提取器,其次是C2f模块,而不是传统的YOLO颈部架构。C2f模块后面是两个分割头,它们学习预测输入图像的语义分割掩码。
该模型具有与YOLOv8相似的检测头,由5个检测模块和1个预测层组成。YOLOv8-Seg模型在保持高速度和效率的同时,在各种目标检测和语义分割基准上取得了最先进的结果。
YOLOv8可以从命令行界面(CLI)运行,也可以作为PIP包安装。此外,它还具有用于标记、培训和部署的多个集成。
在MS COCO数据集测试开发2017上进行评估,YOLOv8x在图像尺寸为640像素时实现了53.9%的AP(相比之下,在相同输入尺寸下,YOLOv5的AP为50.7%),在NVIDIA A100和TensorRT上的速度为280 FPS。
17 PP-YOLO、PP-YOLOv2和PP-YOLOE
PP-YOLO模型已经与我们描述的YOLO模型并行发展。但是,我们决定将它们分组在一个部分中,因为它们从YOLOv3开始,并且在以前的PP-YOLO版本的基础上逐渐改进。尽管如此,这些模型对YOLO的演变产生了影响。PP-YOLO[82]与YOLOv4和YOLOv5类似,是基于YOLOv3的。该研究于2020年7月由百度公司的研究人员发表在ArXiv上。作者使用了PaddlePaddle[110]深度学习平台,因此其名称为PP。遵循我们从YOLOv4开始看到的趋势,PP-YOLO增加了十个现有的技巧来提高探测器的准确性,保持速度不变。根据作者的说法,本文并不是要介绍一种新的目标检测器,而是要展示如何一步一步地构建一个更好的检测器。PP-YOLO使用的大多数技巧与yolo4中使用的技巧不同,重叠的技巧使用不同的实现。PP-YOLO与YOLOv3的变化:
- ResNet50-vd骨干网在最后阶段用一个增强了可变形卷积的架构取代DarkNet-53骨干网[111],并使用一个蒸馏的预训练模型,该模型在ImageNet上具有更高的分类精度。这个架构被称为ResNet5-vd-dcn。
- 更大的批处理规模以提高训练的稳定性,它们从64个增加到192个,同时更新了训练计划和学习率。
- 维护训练参数的移动平均线,并使用它们代替最终训练值。
- DropBlock只应用于FPN。
- 在另一个分支中,将IoU损失与边界盒回归的l1损失一起添加。
- 添加了IoU预测分支来测量定位精度以及IoU感知损失。在推理过程中,YOLOv3将分类概率和客观评分相乘计算最终检测结果,PP-YOLO还将预测IoU相乘考虑定位精度。
- 采用类似于YOLOv4的网格敏感方法改进网格边界的边界框中心预测。
- 采用矩阵式NMS[112],可以并行运行,比传统NMS运行速度更快。
- CoordConv[113]用于FPN的1 × 1卷积,在检测头的第一个卷积层上。CoordConv允许网络学习平移不变性,提高检测定位。
-
空间金字塔池化仅在顶部特征图上使用,以增加主干的接受野。
17.1 PP-YOLO增强和预处理
PP-YOLO采用了以下增强和预处理:
- 混合训练[75],从β (α, β)分布中采样权值,其中α = 1.5, β = 1.5。
- 随机颜色失真。
- 随机的扩大。
- 随机裁剪和随机翻转的概率为0.5。
- RGB通道z-score归一化,均值为[0.485,0.456,0.406],标准差为[0.229,0.224,0.225]。
- 从[320,352,384,416,448,480,512,544,576,608]中均匀绘制多个图像大小。
在MS COCO数据集测试开发2017上进行评估,PP-YOLO在NVIDIA V100上以73 FPS的速度实现了45.9%的AP和65.2%的AP50。
17.2 PP-YOLOv2
PP-YOLOv2[114]于2021年4月在ArXiv上发表,并对PP-YOLO进行了四项改进,将NVIDIA V100上69 FPS的AP性能从45.9%提高到49.5%。PP-YOLOv2对PP-YOLO的修改如下:
- 骨干网从ResNet50修改为ResNet101。
- PAN (Path aggregation network),替代类似于YOLOv4的FPN。
- Mish激活函数。与YOLOv4和YOLOv5不同的是,它们仅在检测颈部应用了mish激活功能,使主干与ReLU保持不变。
- 较大的输入尺寸有助于提高小对象的性能。他们将最大的输入大小从608扩展到768,并将每个GPU的批处理大小从24张减少到12张。输入大小从[320,352,384,416,448,480,512,544,576,608,640,672,704,736,768]中均匀抽取。
- 修改后的IoU感知分支。他们修改了IoU感知损失计算的计算,使用软标签格式代替软权重格式。
17.3 PP-YOLOE
PP-YOLOE[115]于2022年3月在ArXiv上发表。它对PP-YOLOv2进行了改进,在NVIDIA V100上以78.1 FPS实现了51.4% AP的性能。图17显示了详细的架构图。PP-YOLOE对PP-YOLOv2的主要变化有:
- Anchor-free。PP-YOLOE遵循[87,86,85,84]作品推动的时代趋势,采用无锚结构。
- 新的脊柱和颈部。受TreeNet[116]的启发,作者使用结合残差和密集连接的RepResBlocks修改了脊柱和颈部的结构。
- 任务一致性学习(TAL)。YOLOX首先提出了任务错位问题,即分类置信度和定位精度在所有情况下都不一致。为了减少这个问题,PP-YOLOE实现了tod[94]中提出的TAL,其中包括动态标签分配和任务对齐损失。
- 高效任务对齐头(ET-head)。与YOLOX的分类和定位磁头分离不同,PP-YOLOE使用基于ood的单个磁头来提高速度和准确性。
- 变焦(VFL)和分布焦损失(DFL)。VFL[95]使用目标分数对阳性样本进行权重损失,对IoU高的样本给予更高的权重。这在训练期间优先考虑高质量的样本。同样,两者都使用IACS作为目标,允许对分类和定位质量进行联合学习,从而实现训练和推理的一致性。另一方面,DFL[108]将Focal Loss从离散标签扩展到连续标签,从而成功地优化了结合质量估计和类别预测的改进表示。这允许在实际数据中准确地描述灵活的分布,从而消除不一致的风险。
与之前的YOLO版本一样,作者通过改变脊柱和颈部的宽度和深度来生成多个缩放模型。这些型号分别为PP-YOLOE-s(小型)、PP-YOLOE-m(中型)、PP-YOLOE-l(大型)和PP-YOLOE-x(超大型)。
18 YOLO-NAS
YOLO-NAS[118]由Deci于2023年5月发布,Deci是一家开发生产级模型和工具以构建、优化和部署深度学习模型的公司。YOLO-NAS旨在检测小物体,提高定位精度,提高每计算性能比,适合实时边缘设备应用。此外,它的开源架构可用于研究。
YOLO-NAS的新颖之处包括:
- 量化感知模块[119],称为QSP和QCI,它们结合了8位量化的重新参数化,以最大限度地减少训练后量化期间的准确性损失。
- 自动化架构设计采用Deci专有的NAS技术AutoNAC。
- 混合量化方法,选择性地量化模型的某些部分,以平衡延迟和准确性,而不是标准量化,其中所有层都受到影响。
- 具有自动标记数据、自蒸馏和大型数据集的预训练方案。
AutoNAC系统在创建YOLO-NAS过程中发挥了重要作用,它是通用的,可以适应任何任务、数据的具体情况、进行推断的环境和性能目标的设置。它帮助用户确定最合适的结构,为他们的特定用途提供精度和推理速度的完美结合。该技术考虑了数据和硬件以及推理过程中涉及的其他元素,如编译器和量化。此外,为了与训练后量化(Post-Training Quantization, PTQ)兼容,在NAS过程中将RepVGG块纳入模型架构。他们通过改变QSP和QCI块的深度和位置生成了三种体系结构:YOLO-NASS、YOLO-NASM和YOLO-NASL (S、M、L分别代表小、中、大)。图18显示了YOLO-NASL的模型体系结构。

该模型在Objects365[120]上进行预训练,其中包含200万张图像和365个类别,然后使用COCO数据集生成伪标签。最后,使用COCO数据集的118k原始训练图像对模型进行训练。
在撰写本文时,已经发布了FP32, FP16和INT8精度的三种YOLO-NAS型号,在16位精度的MS COCO上实现了52.2%的AP。
19 带Transformers的YOLO
随着Transformer[121]的兴起,它接管了从语言和音频处理到视觉的大多数深度学习任务,因此将Transformer和YOLO结合在一起是很自然的。最早使用变形器进行目标检测的尝试之一是You Only Look at One Sequence或YOLOS[122],将预训练的视觉变形器(Vision transformer, ViT)[123]从图像分类转向目标检测,在MS COCO数据集上实现了42.0%的AP。对于ViT主要有两点变化:
- 将一个用于分类的[CLS]令牌替换为一百个用于检测的[DET]令牌;
- 将ViT中的图像分类损失替换为类似于Transformer端到端目标检测的二部匹配损失[124]。
许多作品将变压器与针对特定应用量身定制的yolo相关架构结合在一起。例如,Zhang等人[125]基于Vision Transformers对遮挡、摄动和域移的鲁棒性,提出了viti - yolo,这是一种混合架构,结合了主干的CSP-Darknet[50]和多头自注意(MHSA-Darknet),以及颈部的双向特征金字塔网络(BiFPN)[80]和多尺度检测头(如YOLOv3)。它们的具体用例是用于无人机图像中的目标检测。图19显示了viti - yolo的详细体系结构。
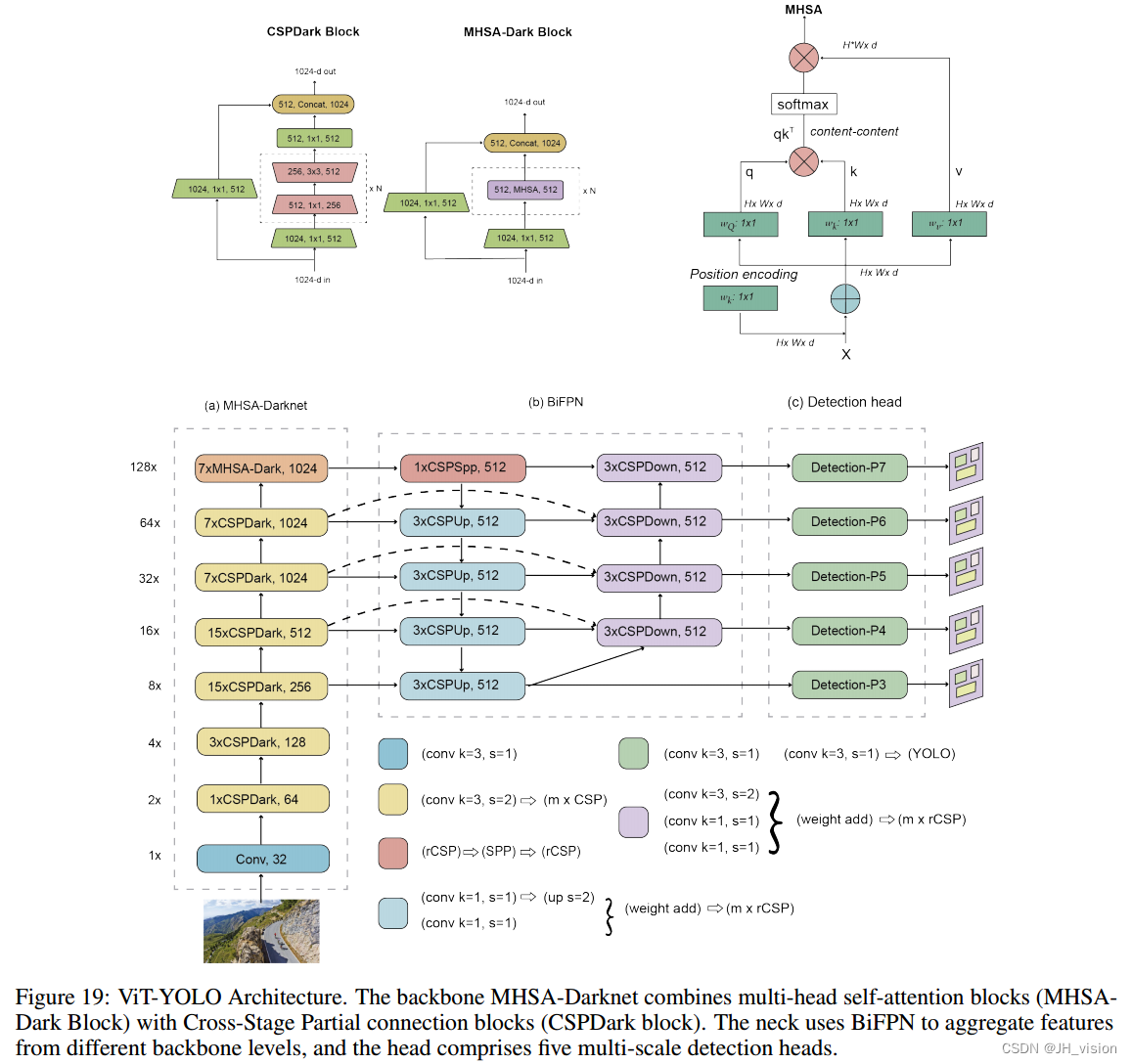
MSFT-YOLO[126]在骨干和检测头上增加了基于变压器的模块,用于检测钢表面的缺陷。NRT-YOLO [127] (Nested Residual Transformer)试图解决遥感图像中微小物体的问题。通过增加一个额外的预测头、特征融合层和一个剩余的变压器模块,NRT-YOLO在DOTA数据集中将YOLOv5l提高了5.4%[128]。
在遥感应用中,YOLO-SD[129]试图提高合成孔径雷达(SAR)图像对小型船舶的探测精度。他们开始使用YOLOX[84]结合多尺度卷积(MSC)来改善在不同尺度下的检测和特征变换模块来捕捉全局特征。作者表明,与HRSID数据集中的YOLOX相比,这些变化提高了YOLO-SD的准确性[130]。
另一个将YOLO与检测变压器(DETR)相结合的有趣尝试[124]是DEYO[131]的情况,包括两个阶段:基于yolov5的模型,然后是类似DETR的模型。第一阶段生成输入到第二阶段的高质量查询和锚。结果表明,与DETR相比,该方法具有更快的收敛时间和更好的性能,在COCO检测基准中达到了52.1%的AP。
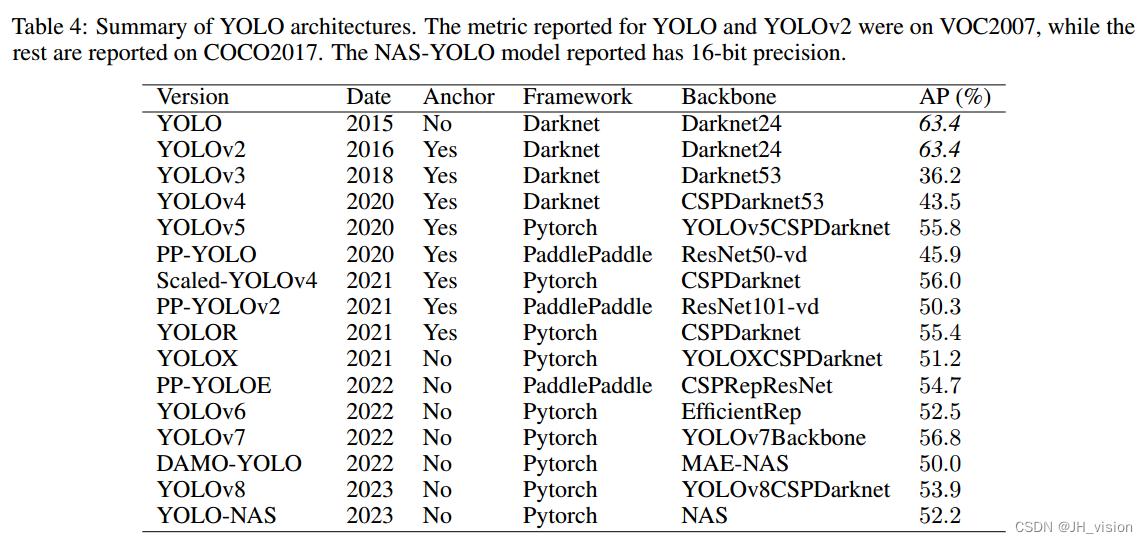
20 讨论
本文研究了16个YOLO版本,从最初的YOLO模型到最新的YOLO-NAS。表4提供了所讨论的YOLO版本的概述。从这张表中,我们可以识别出几个关键模式:
- 锚点:最初的YOLO模型相对简单,没有使用锚点,而最新的模型依赖于带锚点的两级探测器。YOLOv2加入了锚点,从而提高了边界框预测的准确性。这种趋势持续了5年,直到YOLOX推出了一种无锚的方法,取得了最先进的效果。从那时起,后续的YOLO版本已经放弃了锚的使用。
- 框架:最初,YOLO是使用暗网框架开发的,随后的版本也紧随其后。然而,当Ultralytics将YOLOv3移植到PyTorch时,剩余的YOLO版本是使用PyTorch开发的,从而导致增强的激增。另一种使用的深度学习语言是PaddlePaddle,这是一个最初由百度开发的开源框架。
- 骨干:随着时间的推移,YOLO模型的骨干架构发生了重大变化。从包含简单卷积和最大池化层的Darknet架构开始,后来的模型在YOLOv4中加入了跨阶段部分连接(CSP),在YOLOv6和YOLOv7中加入了重新参数化,在DAMO-YOLO和yoloo - nas中加入了神经结构搜索。
- 性能:虽然YOLO模型的性能随着时间的推移有所提高,但值得注意的是,它们通常优先考虑速度和准确性的平衡,而不是仅仅关注准确性。这种权衡对于YOLO框架是必不可少的,它允许跨各种应用程序进行实时对象检测。
20.1 速度和精度之间的权衡
YOLO系列目标检测模型一直专注于平衡速度和准确性,旨在提供实时性能而不牺牲检测结果的质量。随着YOLO框架在各种迭代中不断发展,这种权衡一直是一个反复出现的主题,每个版本都以不同的方式寻求优化这些相互竞争的目标。在最初的YOLO模型中,主要关注的是实现高速目标检测。该模型利用单个卷积神经网络(CNN)直接从输入图像中预测物体的位置和类别,从而实现实时处理。然而,这种对速度的强调导致了准确性的妥协,主要是在处理小对象或具有重叠边界框的对象时。
随后的YOLO版本引入了改进和增强,以解决这些限制,同时保持框架的实时功能。例如,YOLOv2 (YOLO9000)引入锚盒和穿透层来改善物体的定位,从而提高精度。此外,YOLOv3通过采用多尺度特征提取架构增强了模型的性能,从而可以在各种尺度上更好地检测目标。
随着YOLO框架的发展,速度和准确性之间的权衡变得更加微妙。像YOLOv4和YOLOv5这样的模型引入了创新,比如新的网络主干网、改进的数据增强技术和优化的训练策略。这些发展在不显著影响模型实时性能的情况下显著提高了精度。
从YOLOv5开始,所有官方YOLO型号都在速度和精度之间进行了微调,提供不同的模型尺度以适应特定的应用程序和硬件要求。例如,这些版本通常提供针对边缘设备优化的轻量级模型,以准确性换取降低的计算复杂性和更快的处理时间。
21 YOLO的未来
随着YOLO框架的不断发展,我们预计以下趋势和可能性将影响未来的发展:研究人员和开发人员将利用深度学习、数据增强和训练技术方面的最新方法,继续完善YOLO架构。这种持续的创新可能会提高模型的性能、健壮性和效率。
基准进化。目前用于评估目标检测模型的基准,COCO 2017,最终可能会被一个更先进、更具挑战性的基准所取代。这反映了前两个YOLO版本中使用的VOC 2007基准的转变,反映了随着模型变得更加复杂和准确,对更高要求的基准的需求。
YOLO模型及其应用的扩展。随着YOLO框架的发展,我们预计每年发布的YOLO模型数量将会增加,应用范围也会相应扩大。随着框架变得更加通用和强大,它可能会被应用于更多不同的领域,从家用电器设备到自动驾驶汽车。
扩展到新的领域。YOLO模型有潜力扩展到目标检测和分割之外,探索视频中的目标跟踪和3D关键点估计等领域。我们预计YOLO模型将过渡到多模态框架,结合视觉和语言、视频和声音处理。随着这些模型的发展,它们可以作为创新解决方案的基础,以适应更广泛的计算机视觉和多媒体任务。
对各种硬件的适应性。YOLO模型将进一步跨越硬件平台,从物联网设备到高性能计算集群。这种适应性将支持在各种上下文中部署YOLO模型,具体取决于应用程序的需求和约束。此外,通过定制模型以适应不同的硬件规格,YOLO可以为更多的用户和行业提供访问和有效的服务。
22 感谢
We thank the National Council for Science and Technology (CONACYT) for its support through the National Research System (SNI).

