- 1十四届蓝桥杯第三期模拟赛(C/C++ C组)_十四届蓝桥杯第三期模拟题
- 2MyBatis 源码解析:通过源码深入理解 SQL 的执行过程
- 3win10开机自启动python脚本_windows环境下配置python脚本的开机启动
- 4Vue前端 更具router.js 中的meta的roles实现路由卫士,实现权限判断。_router.js能做判断吗
- 5docker-compose health check unhealthy_docker-compose unhealthy
- 6导入导出excel表格EasyExcel操作_@excelproperty
- 7Python高级系列教程:Python的进程和线程_python怎么并行调用多个exe文件,且主线程打印内容
- 8Ubuntu 18.04安装D435i 相机驱动及Ros1 Wrapper_ubuntu18.04安装realsense d435i相机sdk及realsense-ros
- 9面试 CSS 框架八股文十问十答第三期
- 10NameError: name ‘time‘ is not defined_nameerror: name 'timer' is not defined. did you me
零基础yolov8实时检测_用yolov8训练完后,如何用视频进行测试?
赞
踩
零基础实现yolov8实时检测
1.前言
-
操作系统:window、Ubuntu下均可,本文中演示的是在win11系统下。
-
软件准备:anaconda,没装的请自行安装。
-
本项目调用官方开源yolov8模型实现本地摄像头及视频的检测,详细模型调用方法等请参考官方文档及官方GitHub项目。
2.创建一个新的文件夹,在该文件夹下打开terminal

3.使用conda创建一个名叫yolo的虚拟环境
conda create -n yolo python=3.8
- 1
4.激活虚拟环境
conda activate yolo
- 1

最前面会出现当前python环境名称
5.安装ultralytics包
pip install ultralytics
- 1
会顺带一起安装很多包,包括pytorch,opencv等。

下载的pytorch是cpu版本的,可以自行下载gpu版本的,检测速度应该会更快。

6.在命令行尝试调用官方提供的接口
官方文档相关内容:
YOLOv8 可以在命令行界面(CLI)中直接使用,只需输入 yolo 命令:
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
- 1
yolo 可用于各种任务和模式,并接受其他参数,例如 imgsz=640。查看 YOLOv8 CLI 文档以获取示例。
我使用位于C:\Users\10925\Pictures\1.jpg的图片直接在命令行进行演示

他首先会下载yolo模型的权重文件yolov8.pt,并保存在当前文件夹下。建议每次使用yolo时都在该文件夹下打开,不然每次都会重新下载一次权重文件。
显示处理完成的结果保存在runs\detect\predict,这个也是在当前文件夹下创建的

原图:

经过官方的yolo模型接口处理后的结果:

7.调用本地摄像头实时检测
处理方式:持续从本地摄像头捕获帧并使用yolo对每一帧进行处理
7.1.使用官方写好的方法处理原图像
方法1:只可视化实时检测结果,不保存任何内容
这种情况下如果同时设置save = True只会保存目前处理的最后一帧的检测图,如果想保存成视频的参考接下来的方法2.
(注:如果单纯输入的source是视频文件的话,设置save = True可以保存完整处理完毕视频)
import cv2 from ultralytics import YOLO # 加载 YOLOv8 模型 model = YOLO("yolov8n.pt") # 获取摄像头内容,参数 0 表示使用默认的摄像头 cap = cv2.VideoCapture(0) while cap.isOpened(): success, frame = cap.read() # 读取摄像头的一帧图像 if success: model.predict(source=frame, show=True) # 对当前帧进行目标检测并显示结果 # 通过按下 'q' 键退出循环 if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() # 释放摄像头资源 cv2.destroyAllWindows() # 关闭OpenCV窗口

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
运行结果:

方法2:可视化实时检测结果并保存检测结果视频
可以自行修改代码设置保存检测结果视频的尺寸、时间长度等。
import cv2 from ultralytics import YOLO # 载入 YOLOv8 模型 model = YOLO('yolov8n.pt') # 获取摄像头内容 cap = cv2.VideoCapture(0) # 获取原视频的宽度和高度 original_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) original_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 设置新的视频帧大小 new_width = 1280 new_height = 720 # 设置保存视频的文件名、编解码器和帧速率 output_path = "output_video.avi" # 替换为你的输出视频文件路径 fourcc = cv2.VideoWriter_fourcc(*'XVID') out = cv2.VideoWriter(output_path, fourcc, 20.0, (original_width, original_height)) # 循环遍历视频帧 while cap.isOpened(): # 从视频中读取一帧 success, frame = cap.read() if success: # 对帧运行 YOLOv8 推理 results = model(frame) # 在帧上可视化结果 annotated_frame = results[0].plot() # 显示带有标注的帧 cv2.imshow("YOLOv8 推理", annotated_frame) # 将帧写入输出视频 out.write(frame) # 如果按下 'q' 键,则中断循环 if cv2.waitKey(1) & 0xFF == ord("q"): break else: # 如果达到视频结尾,中断循环 break # 释放视频捕获对象并关闭显示窗口 cap.release() cv2.destroyAllWindows() out.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
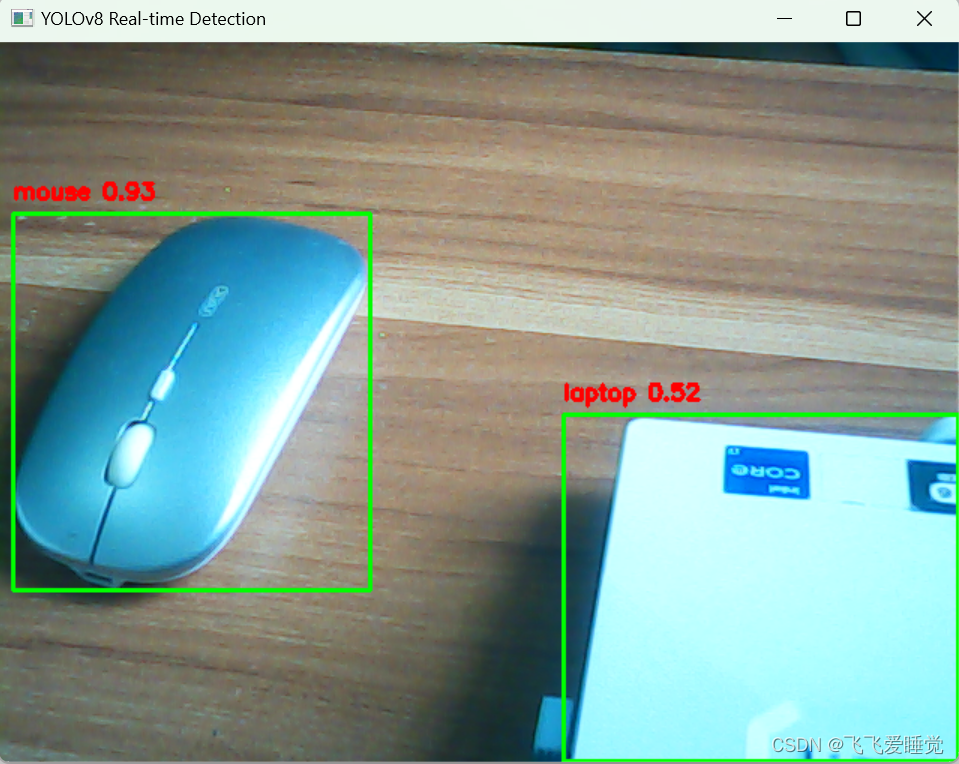
7.2.根据模型返回数据自己处理原图像
可以自己设置检测框以及检测标签的样式,相关模型返回数据及处理方式请参考官方文档
import cv2 from ultralytics import YOLO # 加载 YOLOv8 模型 model = YOLO("yolov8n.pt") # 获取摄像头内容 cap = cv2.VideoCapture(0) # 获取视频内容 # video_path = "1.mp4" # 替换为你的视频文件路径 # cap = cv2.VideoCapture(video_path) # 获取原视频的大小 # original_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # original_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 设置新的视频帧大小 # new_width = 1280 # new_height = 720 # 设置保存视频的文件名、编解码器和帧速率 # output_path = "output_video.avi" # 替换为你的输出视频文件路径 # fourcc = cv2.VideoWriter_fourcc(*'XVID') # out = cv2.VideoWriter(output_path, fourcc, 20.0, (original_width, original_height)) while True: ret, frame = cap.read() if not ret: break # 调整帧的大小 # frame = cv2.resize(frame, (new_width, new_height)) # 使用模型进行目标检测,并返回相应数据 results_list = model.predict(source=frame) # 获取每个结果对象并进行处理 for results in results_list: if results.boxes is not None: xyxy_boxes = results.boxes.xyxy conf_scores = results.boxes.conf cls_ids = results.boxes.cls for box, conf, cls_id in zip(xyxy_boxes, conf_scores, cls_ids): x1, y1, x2, y2 = map(int, box) cls_id = int(cls_id) label = model.names[cls_id] confidence = f"{conf:.2f}" # 颜色 rectangle_color = (0, 255, 0) label_color = (0, 0, 255) # 在图像上绘制矩形框和标签 cv2.rectangle(frame, (x1, y1), (x2, y2), rectangle_color, 2) cv2.putText(frame, f"{label} {confidence}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, label_color,2) # 显示图像 cv2.imshow('YOLOv8 Real-time Detection', frame) # 将帧写入输出视频 # out.write(frame) # 如果按下 'q' 键,则中断循环 if cv2.waitKey(1) & 0xFF == ord('q'): break # 释放视频文件和输出视频 cap.release() cv2.destroyAllWindows() # out.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
运行结果: