
- 1【HarmonyOS应用开发】Web组件的使用(十三)
- 2环形链表题解以及证明_环形链表证明
- 3ResNet学习笔记(一)_resnet的shortcut
- 4Docker 进阶篇_docke 进阶
- 5【面试题】20个常见的前端算法题,你全都会吗?_前端算法面试题
- 6git 合并多次提交记录(commit)_git rebase devel
- 7第十三届蓝桥杯省赛(2022年4月17日)C++中级组题解_第13届蓝桥杯大赛青少年组c++中级组省赛试题
- 8使用GMM和KDE进行数据建模的MATLAB实现_matlab gmm拟合一维数据
- 9开源软件:推动技术发展的强大引擎
- 10带有小数的数字反转(大水题)_小数翻转输出
图像分类篇章-4-transformer,Vision TransFormer,swinTrans_transformer、vision transformer、swin transformer的关系
赞
踩
transformer:
相比 可以并行化
RNN【时序网络】:记忆长度比较短。
transformer:记忆长度无限长
self-attention结构:
核心:Attention的公式《矩阵相乘的公式》——并行化
x通过embedding生成a
q代表query,后续会去和每一个k 进行匹配
k 代表key,后续会被每个q 匹配
v 代表从a 中提取得到的信息
后续q和k 匹配的过程可以理解成计算两者的相关性,相关性越大对应v 的权重也就越大
之后利用attention公式match QK 【d:k的dimension】,

首先使用embedding层:
embedding层是全连接层的一个特例。设输入向量为x,全连接层的权重参数矩阵为W,则该层的输出向量为y=Wx;只是在embedding层中,x为one-hot向量,例如:[0,1,0,0,0],则线性变换就退化成了一个查表操作。
self-attention理论:
点乘生成a11 a12 再利用softmax生成a^11 a^12 以及后面的变量。【各个V的权重】【多线程】
利用softmax获得与k最匹配的q


第二步:
前面的乘上V获得bi【多线程】[qk 相当于v的权重大小]

Multi Head self-attention结构:
结构展示:
multi:简单的是将q1转换为q11,q12【简单均分/线性映射】
之后对每个head使用和Self-Attention中相同的方法即可得到对应的结果:


进行划分 类似于分组 获得bij 在进行拼接【头相同、第一个数字相同的进行拼接】


最后进行融合 得到最终结果b1 b2 【类似于组卷积】

位置编码:
问题:输入交换 结果交换

确定输入和输出的位置。

Vision TransFormer
1.首先分成图像patches 再用embedding层转化为token +classtoken +位置token
2.需要预训练训练参数 否则效果不好
1.Embedding层:
图像利用卷积 14*14块 再展平 196*768
之后获得 class的token
再将两者相加
2.使用位置编码可以提高3%准确率【0-9】 且各类位置编码精度提高差不多 故使用1D位置编码
MLP层用于分类的层结构

位置编码余弦相似度:
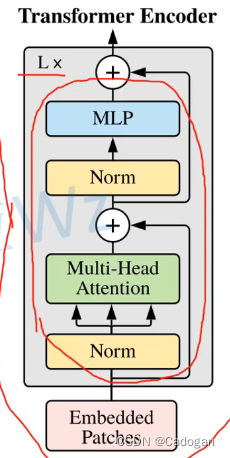
Transformer Encoder:
【类似于组卷积】
2.MLP Head层
MLP Head是全连接或者fc+tanh+linear

整体结构: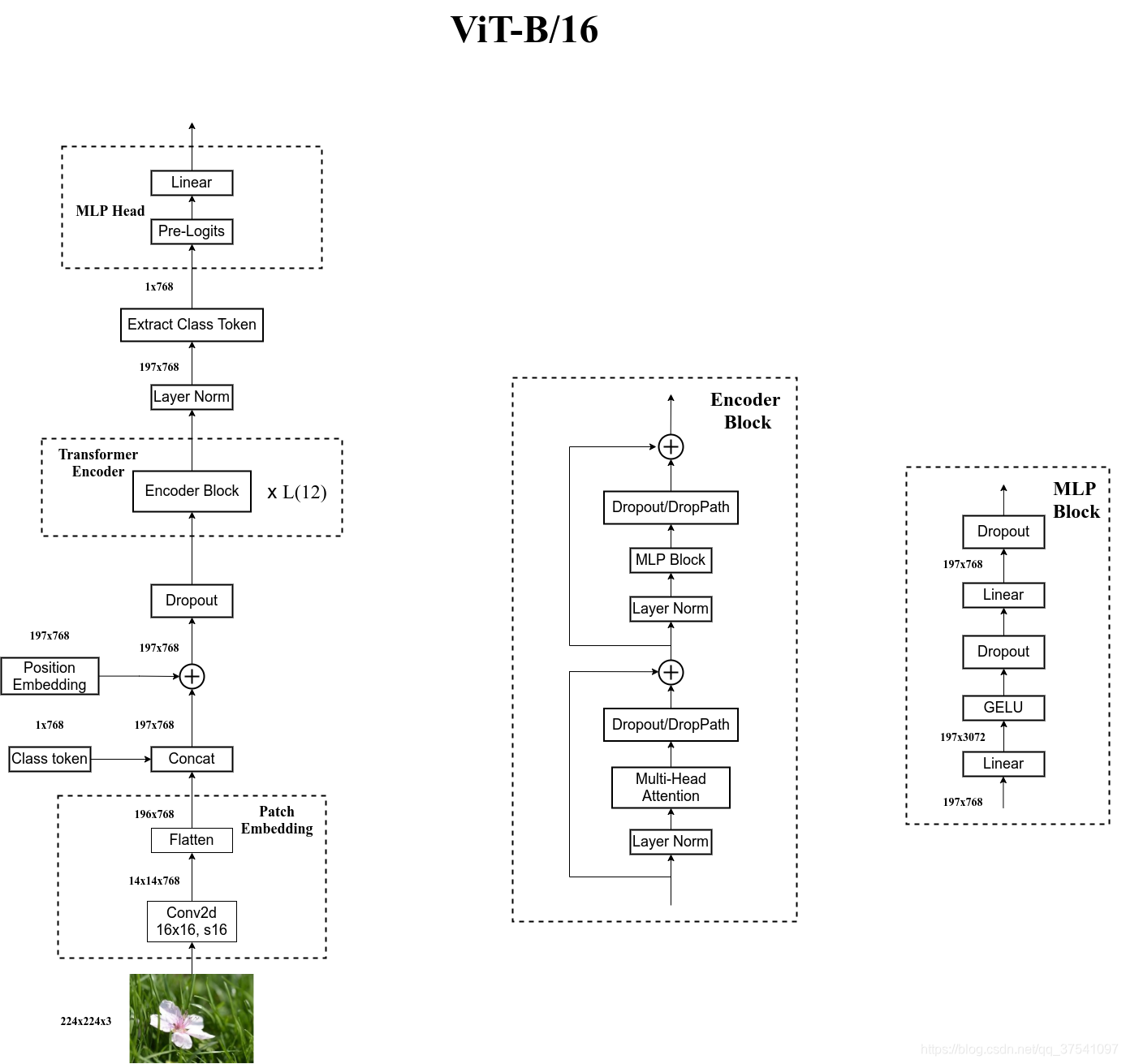

code:
1.embedding:
- self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
- self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
- # flatten: [B, C, H, W] -> [B, C, HW]
- # transpose: [B, C, HW] -> [B, HW, C]
- x = self.proj(x).flatten(2).transpose(1, 2)
- x = self.norm(x)
2.self-attention模块
3.MLP
4.encoder block
5.ViTrans
其他结构:

swinTrans:

1.与vitrans区别:
1.4 8 16三种下采样
2.使用窗口

主要结构:
类似resnet下采样。
每次下采样中channel翻倍
重复偶数次swintransblock 因为两个匹配使用。

patchpartion:
调整通道

patch Mearging:


