
热门标签
热门文章
- 1《剑指 Offer》专项突破版 - 面试题 11 : 0 和 1 个数相同的子数组(C++ 实现)- 前缀和 + 哈希表
- 2langchain系列:langchain入门(一分钟搞定对话机器人)_langchain while true
- 3【Unity小游戏】整整一个周末写一款《皇室战争 玩法》 的 即时战斗类 游戏Demo。两万多字游戏制作过程+解析_开发即时类游戏
- 4十个小项目带你学会python编程,很简单,识字就行_python小项目
- 5bat 启动 jar 及 Tomcat_jar包 bat脚本
- 6微分方程应用(MATLAB)
- 7tensorflow入门
- 8流式计算的理论与技术_流式计算的核心技术点
- 9线性规划和整数规划求解(lingo\matlab)_lingo代码
- 10挑战杯 python opencv 深度学习 指纹识别算法实现
当前位置: article > 正文
论文解读10——Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting_informer论文解读
作者:Monodyee | 2024-02-15 19:37:49
赞
踩
informer论文解读

1、文章贡献
这篇是2021年AAAI的best paper,主要提出了Informer模型来解决Transformer中无法用于长时间序列预测的问题,提高了长时间序列预测问题的能力。
Transformer存在的问题:
- self-attention的二次计算,即规范点积对,会导致每层的时间复杂度和内存使用量为O(L²)。
- J层encoder-decoder堆叠层导致总内存使用量为O(J*L²),限制了接收长时间序列输入的可扩展性。
- 解码器形式为steo-by-step,预测长序列输出的速度变慢。
Informer的改进:
- 使用ProbSparse self-attention机制取代原始的self-attention机制,实现了O(LlogL)的时间复杂度和内存使用量。
- 提出了self-attention distilling操作,优先支配J层堆叠层的注意力分数,将总空间复杂度降低为O((2-ε)LlogL),有助于接收长序列输入。
- 提出了生成式解码器,只需一个前向步骤即可获得长序列输出。
2、有效的self-attention机制
- 在2017年Transformer中的注意力机制采用缩放的点积对,其中Q、K、V分别代表query、key、value值
- 文中进一步讨论自注意力机制,让qi、ki、vi分别代表Q、K、V的第i行,第i个query的注意力被定义为概率形式的内核平滑器:
- 其中k(.)是计算两个向量相似度的核函数,这里选择的是非对称的指数函数,用条件概率p(kj | qi)对value进行加权求和。
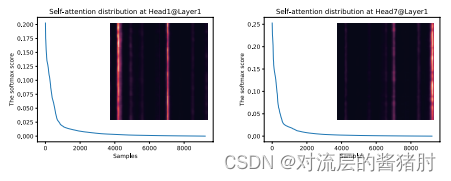
- self-attention的概率分布具有稀疏性,其注意力分数形成了一个长尾分布,即只有少数点积贡献了大部分注意力,将第i个query对所有key的注意力定义为p(kj | qi),主要的点积对促使query的注意力概率分布远离均匀分布,即序列中某个元素只会和少数几个元素具有较高的相关性。如果p(kj | qi)接近于均匀分布q(kj | qi),则与对应的query结合无实际意义。
- 于是文中用p(kj | qi)和q(kj | qi)分布之间的相似性来区分query的重要性程度,其中p(kj | qi)和q(kj | qi)分布之间的相似性用Kullback-Leibler散度来度量:
- 去掉常数后,第i个query的稀疏性度量定义为:
其中第一项是qi在所有key上的Log-Sum-Exp,第二项是它们的算术平均数。如果第i个query获得了较大的M(qi,K),那么它注意力的概率p更有区别性,更有可能包含长尾self-attention分布头部区域的主要点积对。- 解决M(qi,K)的计算复杂度O(Lk*Lq)以及第一项LSE导致的数值不稳定,于是对M(qi,K)做经验近似,第i个query稀疏性M(qi,K)的上下界为:
M(qi,K)的经验近似:

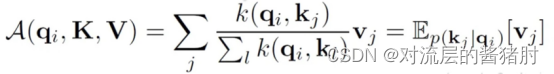
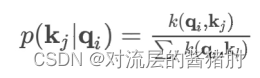
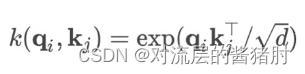
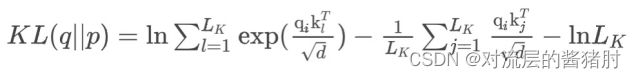

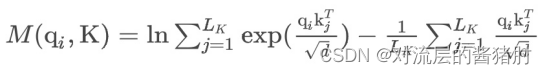
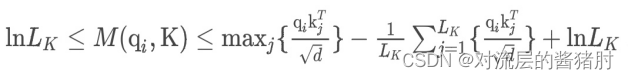
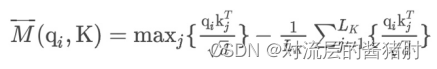

3、ProbSparse self-attention机制
- 在长尾分布下,只需随机采样U=Lq lnLk个点积对计算近似的M(qi,K),用零填充其他对。选择稀疏性得分最高的前u个query作为Q拔和key值做点积来获得ProbSparse Self-attention,使得总时间复杂度和空间复杂度为O(LlnL)。
其中Q拔是与q大小相同的稀疏矩阵,它只包含稀疏性度量M(qi,K)下的前u个query

- 算法流程如下:
先随机采样key值;
将每一个query关于采样的key做点积;
计算每一个query对应的点积的注意力和均匀分布的差异,即M拔;
选取前u个差异最大的query作为Q拔计算注意力概率,其余的值用均值填充。
其中u=c*lnLQ,c为采样因子,故点积相乘的复杂度从 L² 降到了LlnL

4、self-attention distilling
为了解决长输入内存的问题,提出了自注意力蒸馏的方法
- 利用自注意力蒸馏机制来提取具有主导特征的输入,减少输入的时间维度。
其中[xj]表示第j层第t个时刻的attention堆叠层,使用1维k=3的卷积过滤器和步长为2的最大池化层将X下采样到半切片中,使内存使用量减少到O((2-ε)LlogL)。
构建输入减半的副堆叠层,输出维度对应,将所有堆叠连接得到encoder的最终隐藏表示。
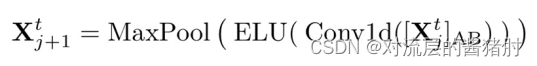
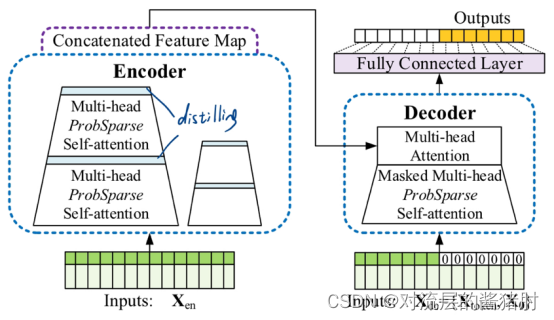
5、Generative style decoder
- 为提高解码时的预测速度,将原先step-by-step解码改进成了生成式解码,解码器的输入是部分真实值和待预测值的拼接,直接一步输出预测结果。
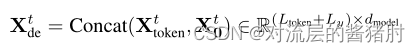
6、实验
- 数据集:
ETTh1、ETTh2: 2年的电力变压器温度数据,采样频率为每小时
ETTm1: 2年的电力变压器温度数据,采样频率为每15分钟
ECL:2年的用电负荷量,采样频率为每小时
Weather:4年的气候数据,采样频率为每小时
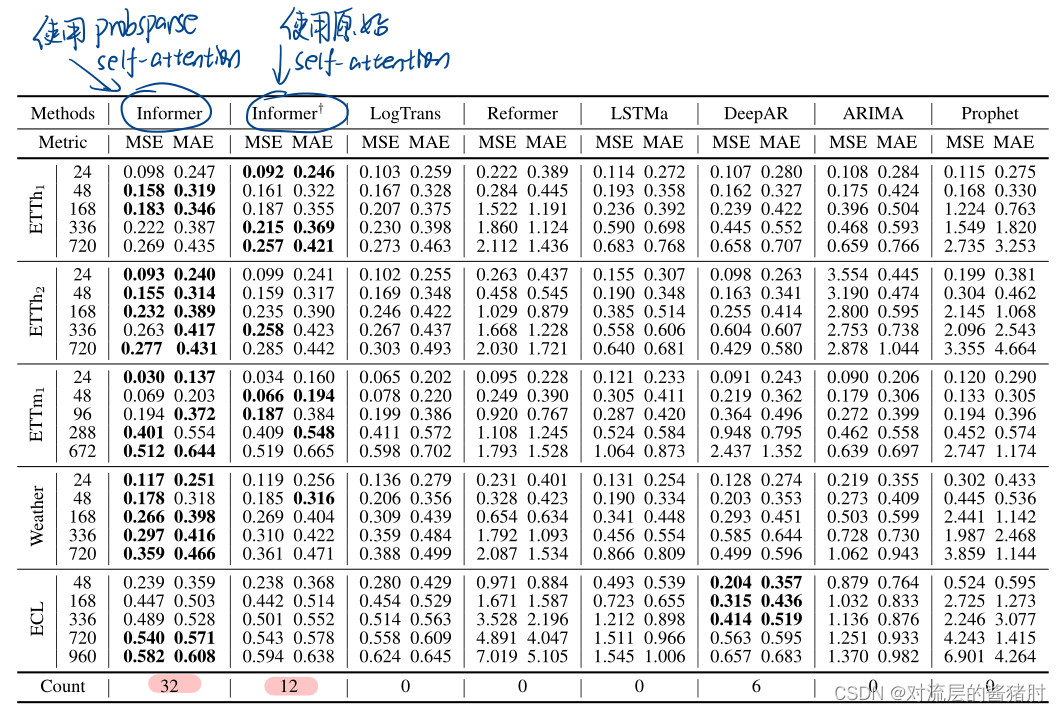
- 单变量
count计数的是MSE、MAE最小的次数,其中Informer次数最多,其次是使用原始Transformer的self-attention
- 多变量
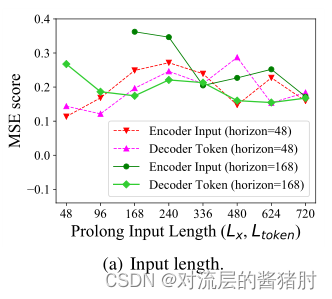
- 改变encoder-decoder输入长度
当预测短序列时,输入长度越长会降低模型性能;当预测序列变长,输入长度增加有助于降低MSE,提高模型性能。
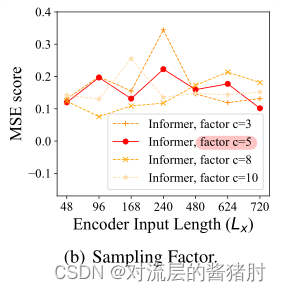
- 改变采样因子c
当c取5的时候MSE随序列长度增加最稳定
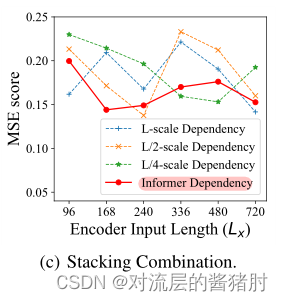
- 改变encoder中堆叠层的联接
L拼接L/4效果最佳

消融实验
- 消除ProbSparse self-attention
- 消除self-attention distilling
- 消除Generative style decoder
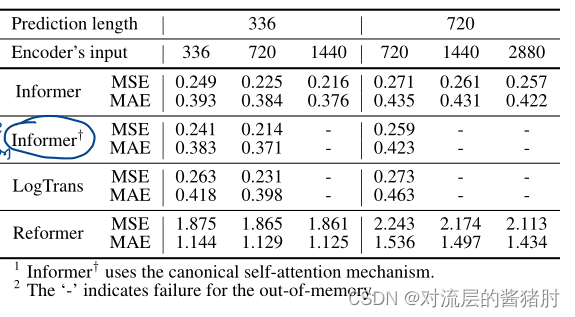
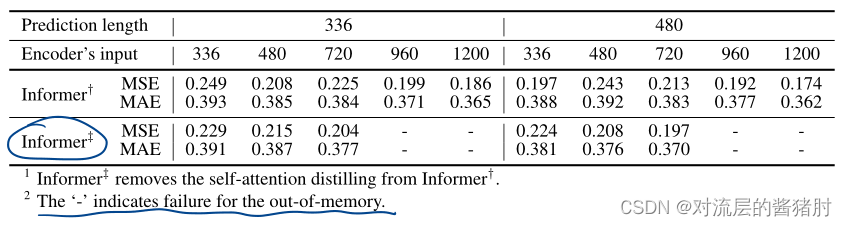
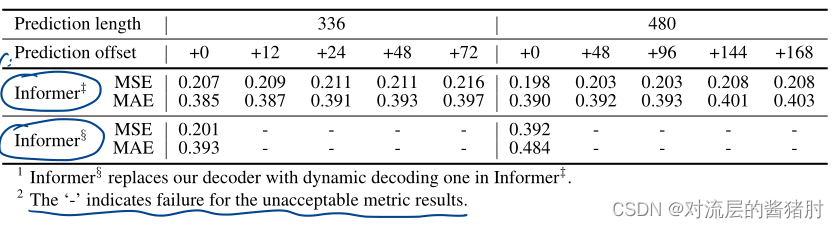
ProbSparse self-attention、self-attention distilling降低了总复杂度,Generative style decoder加快了预测速度,有助于长时序预测。
推荐阅读
相关标签

