
- 1unet网络python代码详解_Keras:Unet网络实现多类语义分割方式
- 2【Linux】Centos 8 服务器部署:阿里云域名注册、域名解析、个人网站 ICP 备案详细教程_网站域名和服务器
- 3烂泥:学习ubuntu远程桌面(一):配置远程桌面
- 4素数判断函数 c_在c++中if(mrun.currentfloor!=index)什么意思
- 5【Java】Spring Boot 配置 PageHelper分页插件_springboot分页插件pagehelper
- 6【v8初体验】利用yolov8训练COCO数据集或自定义数据集
- 7记一次用Sublime Text 4 配置LaTeX写作环境_latex sublime
- 8Git如何回退到某个提交_git还原到某个提交
- 9面试:大数据和深度学习之间的关系是什么?
- 10Sublime text3保存自动编译TypeScript_sublime3 typescript插件
InternImage
赞
踩
终于有对抗Transformer 的了~~
来自浦江实验室、清华等机构的研究人员提出了一种新的基于卷积的基础模型,称为 InternImage,与基于 Transformer 的网络不同,InternImage 以可变形卷积作为核心算子,使模型不仅具有检测和分割等下游任务所需的动态有效感受野,而且能够进行以输入信息和任务为条件的自适应空间聚合。InternImage-H 在 COCO 物体检测上达到 65.4 mAP,ADE20K 达到 62.9,刷新检测分割新纪录。用CNN做基础模型,可变形卷积InternImage实现检测分割新纪录!
近年来大规模视觉 Transformer 的蓬勃发展推动了计算机视觉领域的性能边界。视觉 Transformer 模型通过扩大模型参数量和训练数据从而击败了卷积神经网络。来自上海人工智能实验室、清华、南大、商汤和港中文的研究人员总结了卷积神经网络和视觉 Transformer 之间的差距。从算子层面看,传统的 CNNs 算子缺乏长距离依赖和自适应空间聚合能力;从结构层面看,传统 CNNs 结构缺乏先进组件。
针对上述技术问题,来自浦江实验室、清华等机构的研究人员创新地提出了一个基于卷积神经网络的大规模模型,称为 InternImage,它将稀疏动态卷积作为核心算子,通过输入相关的信息为条件实现自适应空间聚合。InternImage 通过减少传统 CNN 的严格归纳偏置实现了从海量数据中学习到更强大、更稳健的大规模参数模式。其有效性在包括图像分类、目标检测和语义分割等视觉任务上得到了验证。并在 ImageNet、COCO 和 ADE20K 在内的挑战性基准数据集中取得了具有竞争力的效果,在同参数量水平的情况下,超过了视觉 Transformer 结构,为图像大模型提供了新的方向。
-
论文链接:https://arxiv.org/abs/2211.05778
-
开源代码:https://github.com/OpenGVLab/InternImage
传统卷积神经网络的局限
扩大模型的规模是提高特征表示质量的重要策略,在计算机视觉领域,模型参数量的扩大不仅能够有效加强深度模型的表征学习能力,而且能够实现从海量数据中进行学习和知识获取。ViT 和 Swin Transformer 首次将深度模型扩大到 20 亿和 30 亿参数级别,其单模型在 ImageNet 数据集的分类准确率也都突破了 90%,远超传统 CNN 网络和小规模模型,突破了技术瓶颈。但是,传统的 CNN 模型由于缺乏长距离依赖和空间关系建模能力,无法实现同 Transformer 结构相似的模型规模扩展能力。研究者总结了传统卷积神经网络与视觉 Transformer 的不同之处:
(1)从算子层面来看,视觉 Transformer 的多头注意力机制具有长距离依赖和自适应空间聚合能力,受益于此,视觉 Transformer 可以从海量数据中学到比 CNN 网络更加强大和鲁棒的表征。
(2)从模型架构层面来看,除了多头注意力机制,视觉 Transformer 拥有 CNN 网络不具有的更加先进的模块,例如 Layer Normalization (LN), 前馈神经网络 FFN, GELU 等。
尽管最近的一些工作尝试使用大核卷积来获取长距离依赖,但是在模型尺度和精度方面都与最先进的视觉 Transformer 有着一定距离。
可变形卷积网络的进一步拓展
InternImage 通过重新设计算子和模型结构提升了卷积模型的可扩展性并且缓解了归纳偏置,包括(1)DCNv3 算子,基于 DCNv2 算子引入共享投射权重、多组机制和采样点调制。(2)基础模块,融合先进模块作为模型构建的基本模块单元(3)模块堆叠规则,扩展模型时规范化模型的宽度、深度、组数等超参数。
该工作致力于构建一个能够有效地扩展到大规模参数的 CNN 模型。首先,重新设计的可变形卷积算子 DCNv2 以适应长距离依赖和弱化归纳偏置;然后,将调整后的卷积算子与先进组件相结合,建立了基础单元模块;最后,探索并实现模块的堆叠和缩放规则,以建立一个具有大规模参数的基础模型,并且可以从海量数据中学习到强大的表征。
与最近关注large dense kernels的CNN不同,InternImage以可变形卷积为核心算子,使我们的模型不仅具有检测和分割等下游任务所需的大有效感受野,而且具有受输入和任务信息约束的自适应空间聚合。因此,所提出的InternImage减少了传统CNNs严格归纳偏差,并使其能够从像ViT这样的海量数据中学习具有大规模参数的更强、更稳健的模式。我们的模型的有效性在ImageNet、COCO和ADE20K等具有挑战性的基准测试中得到了验证。值得一提的是,InternImage-H在COCO测试开发上获得了创纪录的65.4mAP,在ADE20K上获得了62.9mIoU,优于目前领先的CNNs和ViTs。
为了弥合CNNs和ViTs之间的差距,首先从两个方面总结了它们的差异:(1)从操作员层面来看,ViTs的多头自注意(MHSA)具有长程依赖性和自适应空间聚合(见图(a)段)。得益于灵活的MHSA,ViT可以从海量数据中学习到比CNN更强大、更健壮的表示。(2) 从架构的角度来看,除了MHSA之外,ViTs还包含一系列未包含在标准CNN中的高级组件,如层归一化(LN)、前馈网络(FFN)、GELU等。

算子层面,该研究首先总结了卷积算子与其他主流算子的主要区别。当前主流的 Transformer 系列模型主要依靠多头自注意力机制实现大模型构建,其算子具有长距离依赖性,足以构建远距离特征间的连接关系,还具有空间的自适应聚合能力以实现构建像素级别的关系。但这种全局的注意力机制其计算和存储需求量巨大,很难实现高效训练和快速收敛。同样的,局部注意力机制缺乏远距离特征依赖。大核密集卷积由于没有空间聚合能力,而难以克服卷积天然的归纳偏置,不利于扩大模型。因此,InternImage 通过设计动态稀疏卷积算子,达到实现全局注意力效果的同时不过多浪费计算和存储资源,实现高效训练。
研究者基于 DCNv2 算子,重新设计调整并提出 DCNv3 算子,具体改进包括以下几个部分。
(1)共享投射权重。与常规卷积类似,DCNv2 中的不同采样点具有独立的投射权重,因此其参数大小与采样点总数呈线性关系。为了降低参数和内存复杂度,借鉴可分离卷积的思路,采用与位置无关的权重代替分组权重,在不同采样点之间共享投影权重,所有采样位置依赖性都得以保留。
(2)引入多组机制。多组设计最早是在分组卷积中引入的,并在 Transformer 的多头自注意力中广泛使用,它可以与自适应空间聚合配合,有效地提高特征的多样性。受此启发,研究者将空间聚合过程分成若干组,每个组都有独立的采样偏移量。自此,单个 DCNv3 层的不同组拥有不同的空间聚合模式,从而产生丰富的特征多样性。
(3)采样点调制标量归一化。为了缓解模型容量扩大时的不稳定问题,研究者将归一化模式设定为逐采样点的 Softmax 归一化,这不仅使大规模模型的训练过程更加稳定,而且还构建了所有采样点的连接关系。


构建 DCNv3 算子之后,接下来首先需要规范化模型的基础模块和其他层的整体细节,然后通过探索这些基础模块的堆叠策略,构建 InternImage。最后,根据所提出模型的扩展规则,构建不同参数量的模型。
基础模块。与传统 CNN 中广泛使用的瓶颈结构不同,该研究采用了更接近 ViTs 的基础模块,配备了更先进的组件,包括 GELU、层归一化(LN)和前馈网络(FFN),这些都被证明在各种视觉任务中更有效率。基础模块的细节如上图所示,其中核心算子是 DCNv3,通过将输入特征通过一个轻量级的可分离卷积来预测采样偏置和调制尺度。对于其他组件,遵循与普通 Transformer 相同的设计。

按照此规则,该研究构建了不同尺度的模型,即 InternImage-T、S、B、L、XL。具体参数为:

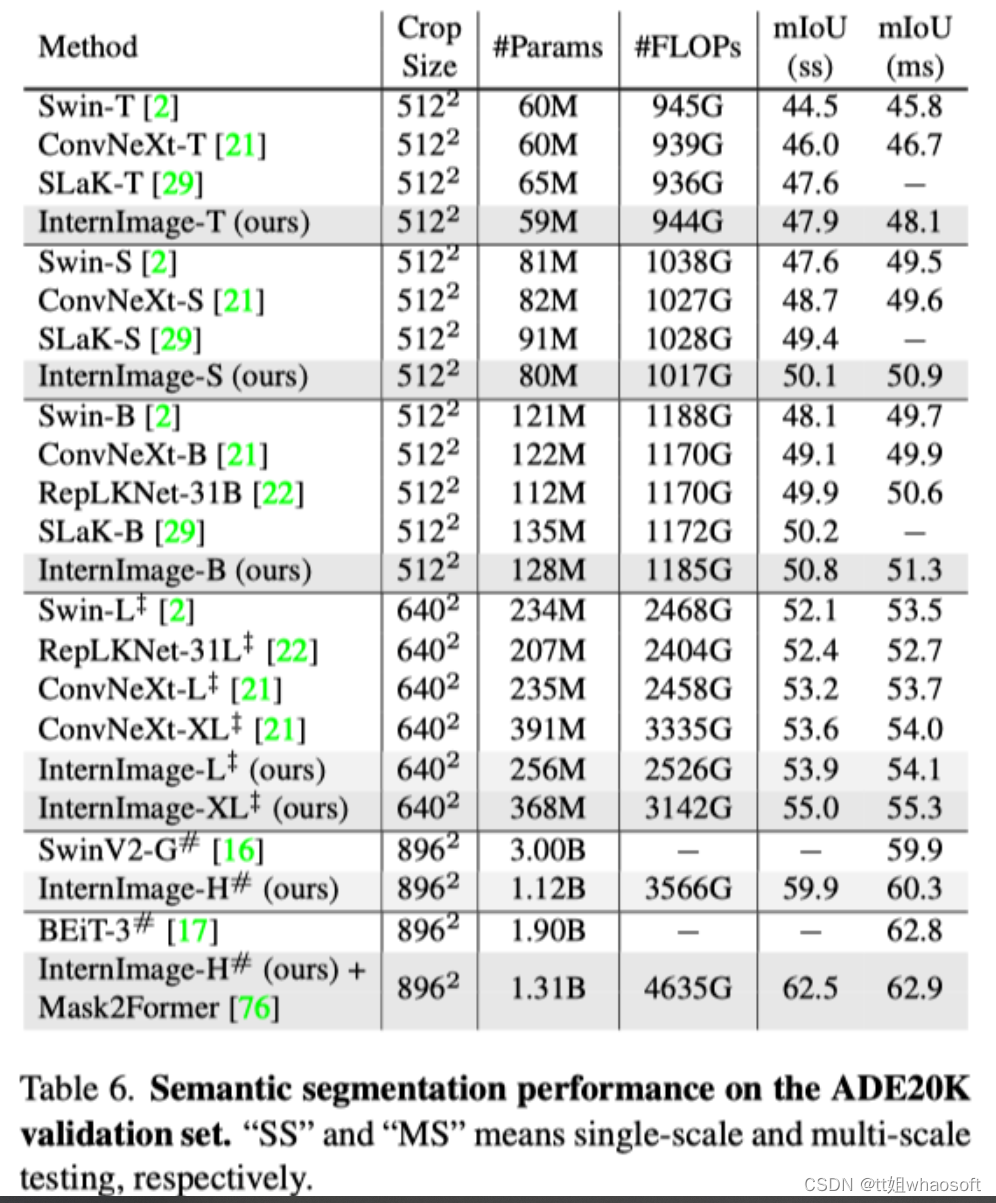
实验结果
图像分类实验:通过使用 427M 的公共数据集合:Laion-400M,YFCC15M,CC12M,InternImage-H 在 ImageNet-1K 的精度达到了 89.2%。

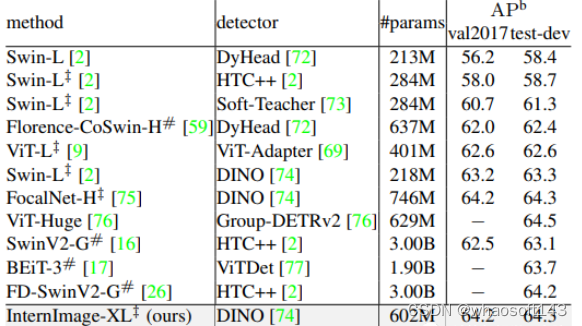
 目标检测:以最大规模的 InternImage-H 为骨干网络,并使用 DINO 作为基础检测框架,在 Objects365 数据集上预训练 DINO 检测器,然后在 COCO 上进行微调。该模型在目标检测任务中达到了 65.4% 的最优结果,突破了 COCO 目标检测的性能边界。
目标检测:以最大规模的 InternImage-H 为骨干网络,并使用 DINO 作为基础检测框架,在 Objects365 数据集上预训练 DINO 检测器,然后在 COCO 上进行微调。该模型在目标检测任务中达到了 65.4% 的最优结果,突破了 COCO 目标检测的性能边界。

语义分割:在语义分割上,InternImage-H 同样取得了很好的性能,结合 Mask2Former 在 ADE20K 上取得了当前最高的 62.9%。 whaosoft aiot http://143ai.com
为了进一步提高目标检测的性能,在ImageNet-22K或大规模联合数据集上预先训练的权重初始化主干,并通过复合技术将其参数翻倍。然后,在Objects365和COCO数据集上一个接一个地对其进行微调,分别针对26个epochs和12个epochs。如下表所示,新方法在COCO val2017和test-dev上获得了65.0 APb和65.4 APb的最佳结果。与以前最先进的模型相比,比FD-SwinV2-G[26]高出1.2分(65.4比64.2),参数减少了27%,并且没有复杂的蒸馏过程,这表明了新模型在检测任务上的有效性。
共享权重的模型参数和GPU内存使用v.s卷积神经元之间的非共享权重。左纵轴表示模型参数,右纵轴表示批量大小为32且输入图像分辨率为224×224时每个图像的GPU内存使用情况。 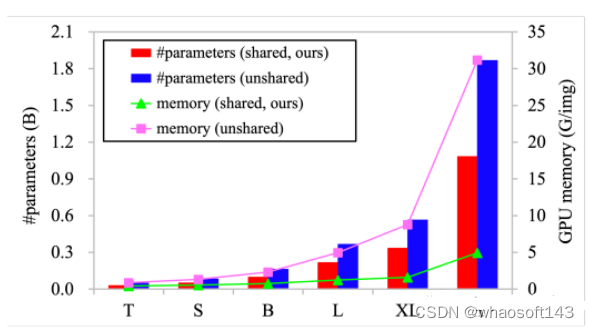
不同阶段不同组的采样位置可视化。蓝色的星表示查询点(在左边的羊),不同颜色的点表示不同组的采样位置。 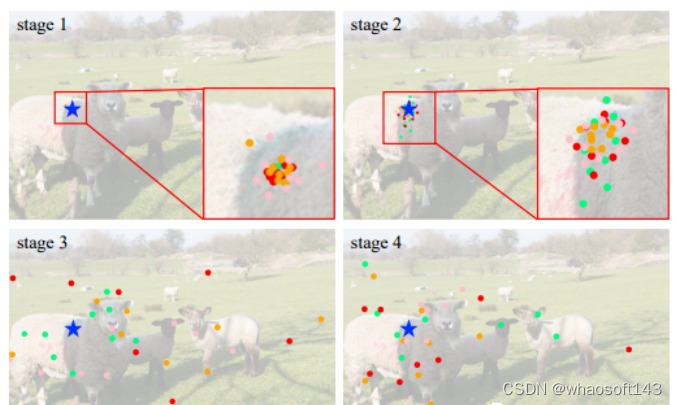

结论
该研究提出了 InternImage,这是一种新的基于 CNN 的大规模基础模型,可以为图像分类、对象检测和语义分割等多功能视觉任务提供强大的表示。研究者调整灵活的 DCNv2 算子以满足基础模型的需求,并以核心算子为核心开发了一系列的 block、stacking 和 scaling 规则。目标检测和语义分割基准的大量实验验证了 InternImage 可以获得与经过大量数据训练、且精心设计的大规模视觉 Transformer 相当或更好的性能,这表明 CNN 也是大规模视觉基础模型研究的一个相当大的选择。尽管如此,大规模的 CNN 仍处于早期发展阶段,研究人员希望 InternImage 可以作为一个很好的起点。

