
- 1windows常见系统进程_windos 警告 是哪个进程
- 2Java——时间戳和时间格式转换_java时间戳转换日期格式 yyyy-mm-dd
- 3C#正则表达式——中文/英文空格(全角/半角空格)处理
- 4git 从git log --graph命令输出结果中查看版本进化大致过程以分支合并原理
- 5浅谈arduino的bootloader
- 6CentOS使用docker本地部署StackEdit Markdown编辑器并实现公网访问
- 7关于电影的HTML网页设计-威海影视网站首页-电影主题HTM5网页设计作业成品_html电影首页实现的功能
- 8python之自动发送微信消息_python微信自动发消息
- 9给出32位有符号整数,将这个整数翻转_32位的有符号整数,进行反转 c语言
- 10前端基础之《NodeJS(2)—模块化》_(use `node --trace-warnings ...` to show where the
3D 人体姿态估计简述
赞
踩
0 前言
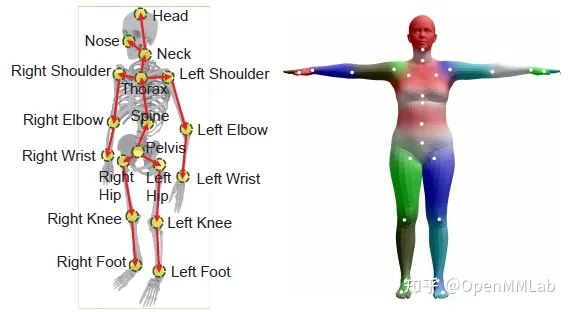
3D Human Pose Estimation(以下简称 3D HPE )的目标是在三维空间中估计人体关键点的位置。3D HPE 的应用非常广泛,包括人机交互、运动分析、康复训练等,它也可以为其他计算机视觉任务(例如行为识别)提供 skeleton 等方面的信息。关于人体的表示一般有两种方式:第一种以骨架的形式表示人体姿态,由一系列的人体关键点和关键点之间的连线构成;另一种是参数化的人体模型(如 SMPL [2]),以 mesh 形式表示人体姿态和体型。
近几年,随着深度学习在人体姿态估计领域的成功应用,2D HPE 的精度和泛化能力都得到了显著提升。然而,相较于 2D HPE,3D HPE 面临着更多的挑战。一方面,受数据采集难度的限制,目前大多数方法都是基于单目图像或视频的,而从 2D 图像到 3D 姿态的映射本就是一个多解问题。另一方面,深度学习算法依赖于大量的训练数据,但由于 3D 姿态标注的难度和成本都比较高,目前的主流数据集基本都是在实验室环境下采集的,这势必会影响到算法在户外数据上的泛化性能。另外,2D HPE 面临的一些难题(例如自遮挡)同样也是 3D HPE 亟待解决的问题。
本文将结合 MMPose 对 3D HPE 的主流算法和数据集做一些介绍。
1 主流算法
1.1 基于单目图像的方法
由于单目图像易于获取且不受场景限制,很多方法都以此为输入数据。但是,正如前面提到的,根据 2D 图像估计 3D 姿态是一个不适定问题,即可能存在多个不同的 3D 姿态,它们的 2D 投影是同一个 2D 姿态。并且,基于单目图像的方法也面临着自遮挡、物体遮挡、深度的不确定性等问题。由于缺少 3D 信息,目前的方法大多只能预测 root-relative pose,即以根关节(pelvis)为坐标原点的三维姿态。
基于单目图像的方法可以根据是否依赖 2D HPE 分成两类,下面将分别介绍这两类方法。
1.1.1 直接预测
这类方法不依赖 2D HPE,直接从图像回归得到 3D 关键点坐标。代表作 C2F-Vol [3] 借鉴了 2D HPE 中的 Hourglass 网络结构,并以 3D Heatmap 的形式表示 3D pose。为了降低三维数据带来的巨大存储消耗,采用了在 depth 维度上逐渐提升分辨率的方法。
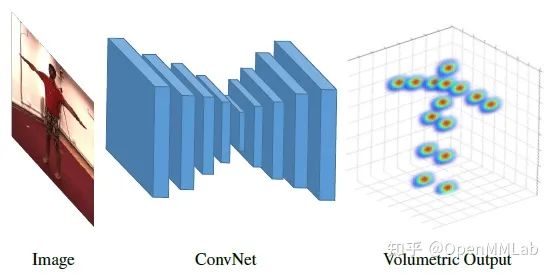
直接预测可以更好地利用原始图像中的信息。而其最大的缺陷在于,2D-3D 的映射是一个高度非线性问题,且 3D 空间的搜索范围更广,预测难度非常大。
1.1.2 2D-to-3D Lifting
得益于 2D HPE 的高精度和泛化能力,许多方法选择以 2D HPE 作为中间步骤,根据 2D pose(和原始图像特征)去估计 3D pose。SimpleBaseline3D [4] 是其中的一种经典方法。该方法以 2D 关键点坐标作为输入,通过残差连接的全连接层直接将 2D pose 映射到 3D 空间。尽管模型非常简单,该算法在当时达到了 SOTA 水平,并通过实验证明了目前大多数 3D HPE 算法的误差主要来源于图像信息的理解(2D HPE)而不是 2D-to-3D lifting 过程。

由于上述算法仅以 2D pose 作为输入,因此高度依赖 2D pose 的准确性,一旦 2D HPE 失败,将会严重影响后续的 2D-to-3D lifting。为了解决这一问题,也有一些算法同时学习 2D 和 3D 姿态 [5],这样一方面可以为 2D-to-3D lifting 引入来自于原始图像的信息,另一方面也为 2D/3D 数据集混合训练提供了可能,进一步提升算法的泛化能力。
以上介绍的都是单人姿态估计方法。对于多人场景下的 3D HPE,和 2D 的情况类似,也可以分成 top-down 和 bottom-up 这两类。其中,top-down 方法 [10] 需要先利用目标检测算法确定人体的 bounding box,然后对于每一个 bounding box 中的人体,计算其根关节的绝对坐标以及其他关节相对于根关节的坐标。而 bottom-up 方法 [11] 则首先预测所有关节的位置,再根据关节间的相对关系将属于同一个人的关节联系起来构成完整的人体。Bottom-up 方法的主要优点在于它的运行时间基本不会受到待检测人体数量的影响,因此在拥挤场景下 bottom-up 方法更有优势。再者,bottom-up 方法的关键点定位是在整体图像的基础上完成的,而 top-down 方法则是在 bounding box 区域内完成的,因此 bottom-up 方法更有利于把握全局信息,从而能更准确地定位人体在相机坐标系下的绝对位置。
1.2 基于多目图像的方法
为了解决遮挡问题,目前最有效的方法之一就是融合多视角信息。为了从多目图像中重建 3D pose,关键在于如何确定场景中同一个点在不同视角下的位置关系。一些方法引入多视角间的一致性约束,例如在 [6] 中,同时输入两个视角的图像,对于其中某一个视角的 2D pose 输入,根据两个视角间的转换关系,预测另一个视角的 3D pose 输出。也有一些方法借助于立体视觉中的 triangulation 方法,将所有视角下的 2D heatmap 聚合起来构成一个 3D volume,随后再通过三维卷积网络输出 3D heatmap。
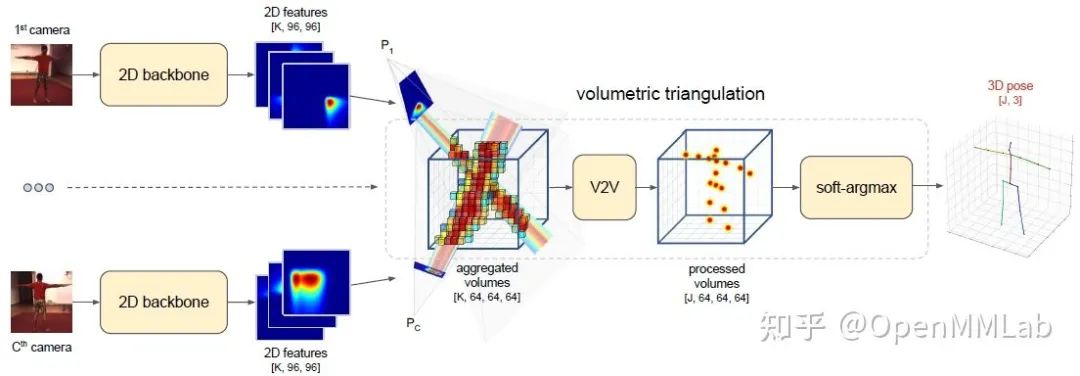
结合多目图像可以帮助解决遮挡问题,并且也能够在一定程度上解决深度不确定问题。但是这类方法对于数据采集的要求比较高,且模型结构相对复杂,在实际场景中的应用具有一定的局限性。
1.3 基于视频的方法
基于视频的方法就是在以上两类方法的基础上引入时间维度上的信息。相邻帧提供的上下文信息可以帮助我们更好地预测当前帧的姿态。对于遮挡情况,也可以根据前后几帧的姿态做一些合理推测。另外,由于在一段视频中同一个人的骨骼长度是不变的,因此这类方法通常会引入骨骼长度一致性的约束限制,有助于输出更加稳定的 3D pose。
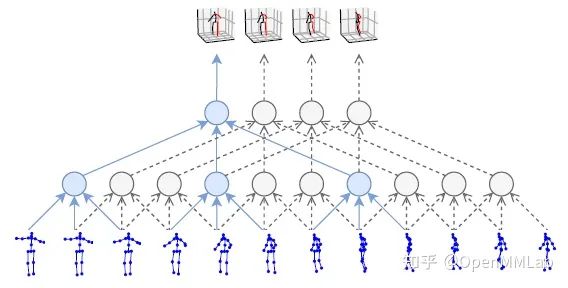
VideoPose3D [7] 以 2D pose 序列作为输入,利用 Temporal Convolutional Network (TCN) 处理序列信息并输出 3D pose。TCN 的本质是在时间域上的卷积,它相对于 RNN 的最大优势在于能够并行处理多个序列,且 TCN 的计算复杂度较低,模型参数量较少。在 VideoPose3D 中,作者进一步利用 dilated convolution 扩大 TCN 的感受野。具体的网络结构与 SimpleBaseline3D 类似,采用了残差连接的全卷积网络。除此以外,VideoPose3D 还包含了一种半监督的训练方法,主要思路是添加一个轨迹预测模型用于预测根关节的绝对坐标,将相机坐标系下绝对的 3D pose 投影回 2D 平面,从而引入重投影损失。半监督方法在 3D label 有限的情况下能够更好地提升精度。
1.4 其他方法
除了 RGB 图像以外,也有越来越多的传感器被应用于 3D HPE 任务中。常见的有深度相机、雷达、IMU(惯性测量单元)等。深度相机和雷达都提供了三维空间上的信息,这对于 3D HPE 来说非常重要,可以帮助缓解或消除深度不确定性问题。IMU 设备可以提供关节方向信息,它不依赖于视觉信号,因此可以帮助解决遮挡问题。
2 常用数据集
由于 3D 关键点标注难度较大,目前的数据集基本上都借助于 MoCap 和可穿戴 IMU设备来完成数据标注,也正因为此,大多数数据集都局限于室内场景。
MMPose 现已支持 Human3.6M 和 MPI-INF-3DHP 这两个常用的 3D HPE benchmark,我们也提供了数据预处理脚本,帮助用户快速得到训练所需的数据。
2.1 Human3.6M

Human3.6M 是目前 3D HPE 任务最为常用的数据集之一,包含了360万帧图像和对应的 2D/3D 人体姿态。该数据集在实验室环境下采集,通过4个高清相机同步记录4个视角下的场景,并通过 MoCap 系统获取精确的人体三维关键点坐标及关节角。如图所示,Human3.6M 包含了多样化的表演者、动作和视角。
Human3.6M 的评价指标主要有 Mean Per Joint Position Error (MPJPE) 和 P-MPJPE。其中,MPJPE 是所有关键点预测坐标与 ground truth 坐标之间的平均欧式距离,一般会事先将预测结果与 ground truth 的根关节对齐;P-MPJPE 则是将预测结果通过 Procrustes Analysis 与 ground truth 对齐,再计算 MPJPE。
2.2 MPI-INF-3DHP

上面提到,Human3.6M 尽管数据量大,但场景单一。为了解决这一问题,MPI-INF-3DHP 在数据集中加入了针对前景和背景的数据增强处理。具体来说,其训练集的采集是借助于多目相机在室内绿幕场景下完成的,对于原始的采集数据,先对人体、背景等进行分割,然后用不同的纹理替换背景和前景,从而达到数据增强的目的。测试集则涵盖了三种不同的场景,包括室内绿幕场景、普通室内场景和室外场景。因此,MPI-INF-3DHP 更有助于评估算法的泛化能力。

在评价标准方面,除了 MPJPE,该数据集也把 2D HPE 中广泛使用的 Percentage of Correct Keypoints (PCK) 和 Area Under the Curve (AUC) 扩展到了 3D HPE 中。其中 PCK 是误差小于一定阈值(150 mm)的关键点所占的百分比,AUC 则是 PCK 曲线下的面积。
2.3 CMU Panoptic

CMU Panoptic [13] 是一个大型的多目图像数据集,提供了31个不同视角的高清图像以及10个不同视角的 Kinect 数据,包含了65段视频(总时长5.5 h),3D skeleton 总数超过150万。该数据集还包含了多个多人场景,因此也成为了多人 3D HPE 的 benchmark 之一。
CMU Panoptic 的评价标准与 Human3.6M 类似,一般采用 MPJPE 和 P-MPJPE 来评估算法精度。
3 MMPose 中的 3D HPE 算法实现
MMPose 现已支持 SimpleBaseline3D 和 VideoPose3D 这两个经典的 3D HPE 算法,并在 Human3.6M 和 MPI-INF-3DHP 数据集上完成了训练和测试。我们也提供了基于图像和视频的 demo,感兴趣的话不妨先去尝试一下~
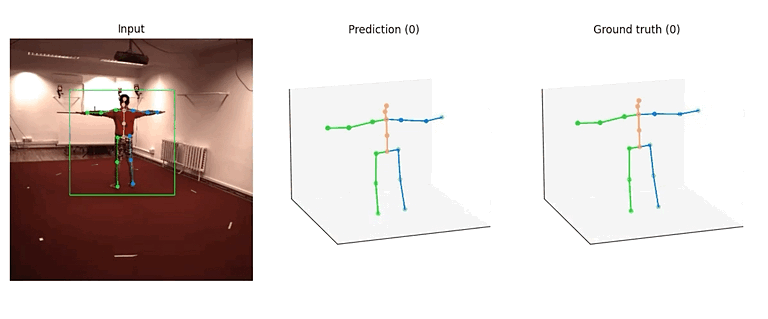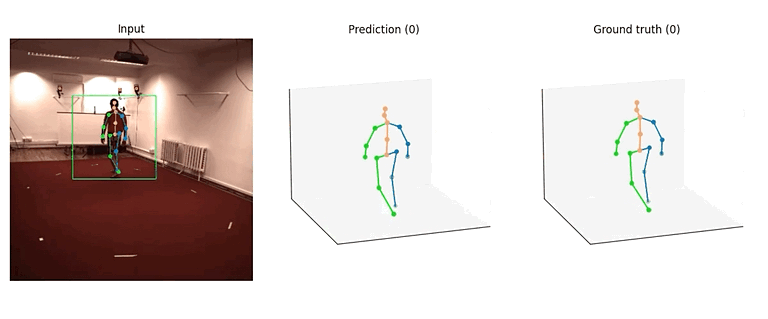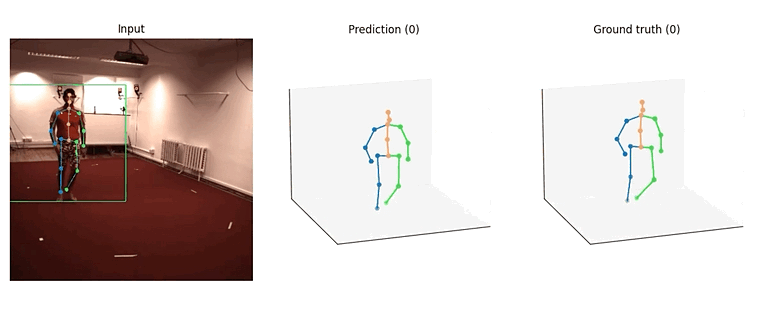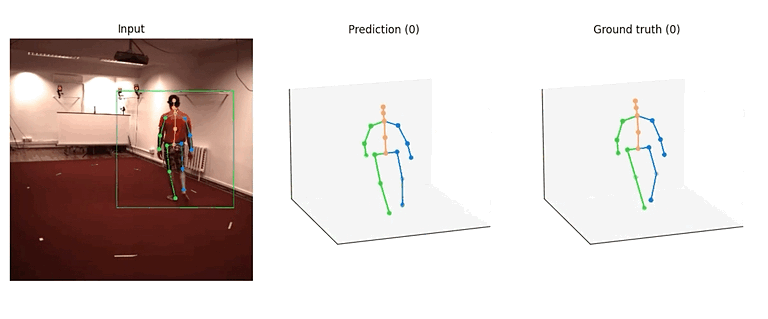
这两个算法的模型结构大体相似,其中 SimpleBaseline3D 可以看作是 VideoPose3D 在感受野为单帧时的特殊情况,因此我们都采用了 TCN 作为 backbone。下面将以 VideoPose3D 中的一个模型(videopose3d_h36m_243frames_fullconv_supervised_cpn_ft)为例,介绍算法的具体实现。
3.1 Model
3.1.1 Backbone
Backbone 为 TCN 模型(具体实现见 tcn.py),输入为17个关键点的 2D 坐标,block 总数为4,其中每一个 block 都由两个残差连接的卷积层构成。值得注意的是 use_stride_conv 参数。论文中提到,训练阶段的模型输出被限制为单帧,在这种情况下,可以用 strided convolution 替代 dilated convolution,以减少不必要的计算量,并且能够实现同等的效果。实际实验中发现,采用 strided convolution 可以将训练时间缩短一半以上。
- backbone=dict(
- type='TCN',
- in_channels=2 * 17,
- stem_channels=1024,
- num_blocks=4,
- kernel_sizes=(3, 3, 3, 3, 3),
- dropout=0.25,
- use_stride_conv=True)
3.1.2 Head
Head 仅由一层卷积构成,输出17个关键点的三维坐标,具体实现见 temporal_regression_head.py。Loss 为 MPJPE 误差。
- keypoint_head=dict(
- type='TemporalRegressionHead',
- in_channels=1024,
- num_joints=17,
- loss_keypoint=dict(type='MPJPELoss'))
3.2 Data
3.2.1 Data config
以下是与训练数据相关的一些配置,具体实现见 body3d_h36m_dataset.py。其中seq_len为每一段序列的长度,也是模型在时域上的感受野。temporal_padding采用了复制填充的方式。joint_2d_src支持三种不同的 2D pose 来源:
- data_root = 'data/h36m'
- train_data_cfg = dict(
- num_joints=17,
- seq_len=243,
- seq_frame_interval=1,
- causal=False,
- temporal_padding=True,
- joint_2d_src='detection',
- joint_2d_det_file=f'{data_root}/joint_2d_det_files/cpn_ft_h36m_dbb_train.npy',
- need_camera_param=True,
- camera_param_file=f'{data_root}/annotation_body3d/cameras.pkl')
● 'gt':annotation 文件中的 2D pose
● 'detection':2D HPE 算法的输出文件
● 'pipeline':2D HPE 算法的直接输出
3.2.2 Pipeline
数据预处理的 pipeline 主要由以下几个步骤组成(具体实现见 pose3d_transform.py):
1. GetRootCenteredPose:所有关键点的 3D 坐标减去 root 关节的 3D 坐标,即转换到以 root 关节为原点的坐标系下。注意 VideoPose3D 并没有对 3D pose 做归一化处理,而 SimpleBaseline3D 则添加了归一化处理。
2. ImageCoordinateNormalization:图像坐标归一化处理。根据原始图像的长和宽将 2D 坐标归一化到 [-1, 1] 区间。
3. RelativeJointRandomFlip:对输入的 2D pose 和对应的 3D pose 做随机的左右翻转。其中,2D pose 以零点作为翻转中心,而 3D pose 以 root 关节作为翻转中心。
4. PoseSequenceToTensor:将形如[T,K,C]的 pose 序列转化成[K*C, T]的形式,作为 TCN 的输入。
Collect:整合训练中需要用到的数据。
- train_pipeline = [
- dict(
- type='GetRootCenteredPose',
- item='target',
- visible_item='target_visible',
- root_index=0,
- root_name='root_position',
- remove_root=False),
- dict(type='ImageCoordinateNormalization', item='input_2d'),
- dict(
- type='RelativeJointRandomFlip',
- item=['input_2d', 'target'],
- flip_cfg=[
- dict(center_mode='static', center_x=0.),
- dict(center_mode='root', center_index=0)
- ],
- visible_item=['input_2d_visible', 'target_visible'],
- flip_prob=0.5),
- dict(type='PoseSequenceToTensor', item='input_2d'),
- dict(
- type='Collect',
- keys=[('input_2d', 'input'), 'target'],
- meta_name='metas',
- meta_keys=['target_image_path', 'flip_pairs', 'root_position'])]

3.3 训练配置
3.3.1 Optimizer
采用 Adam 作为优化器,与论文中不同的是,这里初始学习率设为1e-4。
- optimizer = dict(type='Adam', lr=1e-4)
- optimizer_config = dict(grad_clip=None)
3.3.2 Learning policy
学习率采用指数衰减的形式,每个 epoch 下降0.98,总共训练200个 epoch。值得注意的是,原作在构建训练集时包含了所有样本的 flipped 版本和原始版本,而我们采用了概率为0.5的随机 flip 方式,为了达到相似的效果,我们将 epoch 总数增加到原来的2倍以上。
- lr_config = dict(
- policy='exp',
- by_epoch=True,
- gamma=0.98)
- total_epochs = 200
4 总结
本文介绍了 3D HPE 的一些主流算法和常用数据集,并以 VideoPose3D 为例,介绍了 MMPose 中的具体算法实现。希望大家通过本文的阅读能够对 3D HPE 有一个初步的认识,也欢迎大家使用 MMPose 来支持相关的研究与应用~~欢迎前往MMPose,随手star:
https://github.com/open-mmlab/mmocr
5 参考文献
[1] Zheng, C., Wu, W., Yang, T., Zhu, S., Chen, C., Liu, R., ... & Shah, M. (2020). Deep learning-based human pose estimation: A survey. arXiv preprint arXiv:2012.13392.
[2] Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., & Black, M. J. (2015). SMPL: A skinned multi-person linear model. ACM transactions on graphics (TOG), 34(6), 1-16.
[3] Pavlakos, G., Zhou, X., Derpanis, K. G., & Daniilidis, K. (2017). Coarse-to-fine volumetric prediction for single-image 3D human pose. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7025-7034).
[4] Martinez, J., Hossain, R., Romero, J., & Little, J. J. (2017). A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2640-2649).
[5] Habibie, I., Xu, W., Mehta, D., Pons-Moll, G., & Theobalt, C. (2019). In the wild human pose estimation using explicit 2d features and intermediate 3d representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10905-10914).
[6] Chen, X., Lin, K. Y., Liu, W., Qian, C., & Lin, L. (2019). Weakly-supervised discovery of geometry-aware representation for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10895-10904).
[7] Pavllo, D., Feichtenhofer, C., Grangier, D., & Auli, M. (2019). 3d human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7753-7762).
[8] Ionescu, C., Papava, D., Olaru, V., & Sminchisescu, C. (2013). Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelligence, 36(7), 1325-1339.
[9] Mehta, D., Rhodin, H., Casas, D., Fua, P., Sotnychenko, O., Xu, W., & Theobalt, C. (2017, October). Monocular 3d human pose estimation in the wild using improved cnn supervision. In 2017 international conference on 3D vision (3DV) (pp. 506-516). IEEE.
[10] Moon, G., Chang, J. Y., & Lee, K. M. (2019). Camera distance-aware top-down approach for 3d multi-person pose estimation from a single rgb image. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 10133-10142).
[11] Fabbri, M., Lanzi, F., Calderara, S., Alletto, S., & Cucchiara, R. (2020). Compressed volumetric heatmaps for multi-person 3d pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7204-7213).
[12] Li, S., Ke, L., Pratama, K., Tai, Y. W., Tang, C. K., & Cheng, K. T. (2020). Cascaded deep monocular 3D human pose estimation with evolutionary training data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 6173-6183).
[13] Joo, H., Liu, H., Tan, L., Gui, L., Nabbe, B., Matthews, I., ... & Sheikh, Y. (2015). Panoptic studio: A massively multiview system for social motion capture. In Proceedings of the IEEE International Conference on Computer Vision (pp. 3334-3342).
注:本文转载自知乎文章,已由作者授权转载,未经允许,不得二次转载。
原文链接:https://zhuanlan.zhihu.com/p/400922771
编辑:商汤学术
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 
[详细] -->赞
踩

