
- 1【百度AI】百度AI文字识别概述_百度ai std
- 2app Store 审核被拒问题详解_app 版本已被拒绝,无法接受或批准其他提交的项目。你可以在下方编辑 app 版本。
- 3vscode终端切换路径_使用VSCode来开发Python
- 428张图解 | 互联网究竟是「如何连接,如何进行通信」的?_互联网工作原理图解
- 5PostgreSQL:十三. PostgreSQL的用户管理_postgresql 用户
- 6python中如何生成词云_python词云生成
- 7AI数字人结合OLED透明屏在哪些领域有优势
- 8微服务架构—优雅停机方案
- 9百度智能云曦灵数字人平台重磅升级!限时邀测~
- 10《AI爆款文案 巧用AI大模型让文案变现插上翅膀》_书籍:ai爆款文案巧用ai模型让文案变现插上翅膀目录
学习笔记-动手学深度学习-数据预处理_orch.tensor(inputs.values)
赞
踩
2.2.1读取数据集
举一个例子,我们首先创建一个人工数据集,并存储在CSV(逗号分隔值)文件 ../data/house_tiny.csv中。 以其他格式存储的数据也可以通过类似的方式进行处理。 下面我们将数据集按行写入CSV文件中。
- import os
-
- os.makedirs(os.path.join('..', 'data'), exist_ok=True)
- data_file = os.path.join('..', 'data', 'house_tiny.csv')
- with open(data_file, 'w') as f:
- f.write('NumRooms,Alley,Price\n') # 列名
- f.write('NA,Pave,127500\n') # 每行表示一个数据样本
- f.write('2,NA,106000\n')
- f.write('4,NA,178100\n')
- f.write('NA,NA,140000\n')
要从创建的CSV文件中加载原始数据集,我们导入pandas包并调用read_csv函数。该数据集有四行三列。其中每行描述了房间数量(“NumRooms”)、巷子类型(“Alley”)和房屋价格(“Price”)。
- # 如果没有安装pandas,只需取消对以下行的注释来安装pandas
- # !pip install pandas
- import pandas as pd
-
- data = pd.read_csv(data_file)
- print(data)
输出:

2.2.2 处理缺失值
“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我们将考虑插值法。
通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
- inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
- inputs = inputs.fillna(inputs.mean())
- print(inputs)
输出:

对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
- inputs = pd.get_dummies(inputs, dummy_na=True)
- print(inputs)
输出:

2.2.3 转换为张量模式
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。 当数据采用张量格式后,可以通过在 2.1节中引入的那些张量函数来进一步操作。
- import torch
-
- X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
- X, y
输出

2.3 线性代数
2.3.1 标量
标量由只有一个元素的张量表示。
- import torch
-
- x = torch.tensor(3.0)
- y = torch.tensor(2.0)
-
- x + y, x * y, x / y, x**y
![]()
2.3.2 向量
- x = torch.arange(4)
- x
![]()
可以使用下标来引用向量的任一元素。 例如,我们可以通过xi来引用第i个元素(列向量是向量的默认方向)。
x[3]![]()
可以通过调用Python的内置len()函数来访问张量的长度。
len(x)![]()
用张量表示一个向量(只有一个轴)时,我们也可以通过.shape属性访问向量的长度。 形状(shape)是一个元素组,列出了张量沿每个轴的长度(维数)。
x.shape![]()
2.2.3 矩阵
当调用函数来实例化张量时, 我们可以通过指定两个分量m和n来创建一个形状为m×n的矩阵。
- A = torch.arange(20).reshape(5, 4)
- A

现在我们在代码中访问矩阵的转置
A.T
作为方阵的一种特殊类型,对称矩阵(symmetric matrix)A等于其转置:![]() 。 这里我们定义一个对称矩阵B
。 这里我们定义一个对称矩阵B
- B = torch.tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
- B

B == B.T
2.3.4 张量
当我们开始处理图像时,张量将变得更加重要,图像以n维数组形式出现, 其中3个轴对应于高度、宽度,以及一个通道(channel)轴, 用于表示颜色通道(红色、绿色和蓝色)。
- X = torch.arange(24).reshape(2, 3, 4)
- X

2.3.5 张量算法的基本性质
给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。
- A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
- B = A.clone() # 通过分配新内存,将A的一个副本分配给B
- A, A + B

A * B
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
- a = 2
- X = torch.arange(24).reshape(2, 3, 4)
- a + X, (a * X).shape

2.3.6 降维
我们可以对任意张量进行的一个有用的操作是计算其元素的和。 在数学表示法中,我们使用∑符号表示求和。 为了表示长度为d的向量中元素的总和,可以记为![]() 。 在代码中,我们可以调用计算求和的函数:
。 在代码中,我们可以调用计算求和的函数:
- x = torch.arange(4, dtype=torch.float32)
- x, x.sum()
![]()
我们可以表示任意形状张量的元素和。 例如,矩阵A中元素的和可以记为![]()
A.shape, A.sum() ![]()
默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。 默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。 以矩阵为例,为了通过求和所有行的元素来降维(轴0),我们可以在调用函数时指定axis=0。 由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
- A_sum_axis0 = A.sum(axis=0)
- A_sum_axis0, A_sum_axis0.shape
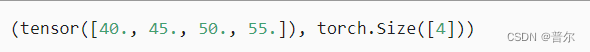
指定axis=1将通过汇总所有列的元素降维(轴1)。因此,输入轴1的维数在输出形状中消失
- A_sum_axis1 = A.sum(axis=1)
- A_sum_axis1, A_sum_axis1.shape

沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
A.sum(axis=[0, 1]) # SameasA.sum()![]()
一个与求和相关的量是平均值(mean或average)。我们通过将总和除以元素总数来计算平均值。在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean(), A.sum() / A.numel() 
同样,计算平均值的函数也可以沿指定轴降低张量的维度。
A.mean(axis=0), A.sum(axis=0) / A.shape[0] ![]()
但是,有时在调用函数来计算总和或均值时保持轴数不变会很有用。
- sum_A = A.sum(axis=1, keepdims=True)
- sum_A

例如,由于sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A。
A / sum_A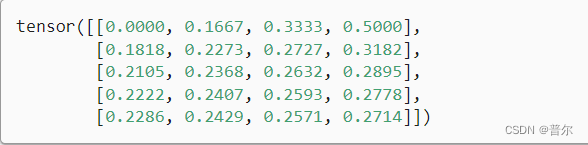
如果我们想沿某个轴计算A元素的累积总和, 比如axis=0(按行计算),我们可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
A.cumsum(axis=0)
2.3.7 点积
给定两个向量x,y∈Rd, 它们的点积(dot product)x⊤y (或〈x,y〉) 是相同位置的按元素乘积的和:![]()
- y = torch.ones(4, dtype = torch.float32)
- x, y, torch.dot(x, y)
![]()
我们可以通过执行按元素乘法,然后进行求和来表示两个向量的点积:
torch.sum(x * y)
2.3.8 向量积
在代码中使用张量表示矩阵-向量积,我们使用与点积相同的mv函数。 当我们为矩阵A和向量x调用torch.mv(A,x)时,会执行矩阵-向量积。 注意,A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。
A.shape, x.shape, torch.mv(A, x)![]()
2.3.9 矩阵-矩阵乘法
- B = torch.ones(4, 3)
- torch.mm(A, B)

2.3.10 范数
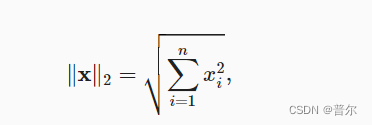
在L2范数中常常省略下标2,也就是说‖x‖等同于‖x‖2。 在代码中,我们可以按如下方式计算向量的L2范数。
- u = torch.tensor([3.0, -4.0])
- torch.norm(u)

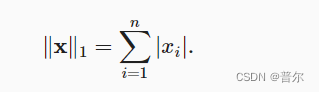
与L2范数相比,L1范数受异常值的影响较小。 为了计算L1范数,我们将绝对值函数和按元素求和组合起来。
torch.abs(u).sum()![]()

torch.norm(torch.ones((4, 9))) 

