
- 1python的pd.read_excel()函数_pd.readexcel
- 2深入解析链表:解锁数据结构核心奥秘
- 3Stable diffusion 3 (SD3) 现已推出!立即下载!_sd3 下载
- 4Snap7 在西门子PLC的使用_snap7 dbread c++
- 5大数据之Spark:Spark面试(初级)
- 6抖音矩阵系统搭建,AI剪辑短视频,一键管理矩阵账号
- 7深入研究simulink建模与仿真之小数转换为整数的舍入模式(圆整模式、取整模式)_integer rounding mode
- 8Logistic回归与牛顿法(附Matlab实现)
- 92020秋招Java面试题——Java框架题答案_内部提供了对各种优秀框架(如:struts、hibernate、mybatis、quartz等)的直
- 10山东大学软件学院计算机视觉考试回忆_山东大学计算机视觉复习
Kafka(4)kafka概述、系统框架和术语解释(broker、Topic、Partition、Leader、Consumer等说明)_kafka broker topic partition
赞
踩
一:kafka概述
官网:https://kafka.apache.org/
Kaka是由Apache软件基金会开发的一个开源流处理平台,由scala和Java编写。
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
可以有如下数据:

1.1 设计目标(已经实现)
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
支持离线数据处理和实时数据处理。
支持在线水平扩展
1.2 优点
解耦:
消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
冗余:数据重复的问题
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的""插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,
只要另外增加处理过程即可。不需要改变代码、不需要调节参数。非常简单
灵活性&峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。
使用消息队列能够使关键组件顶住突发的访问压力,而不会因突发的超负荷的请求而完全崩溃。
可恢复性
系统的一部分组件失效时,不会影响到整个系统。
消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的序来处理。
Kafka保证一个Partition内的消息的有序性。
缓冲
任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。
消息队列通过一个缓冲层来帮助任务最高效率的执行—-—写入队列的处理会尽可能的快速。该缓冲有助于控制和伏化数据流经过系统的速度。
异步通信
很多时候,用户不想也不需要立即处理消息。
消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
二:Kafka系统架构

在一个Topic又三个或多个Partition组成
相当于一个数据做了三个切点
每一个Partition数据都是从0开始,顺序存放的。进入数据是从左往右加入的,数据是放入节点里面,Kafka叫这个节点为Broker。
Leader和Follower不在同一个地方
2.1 拓扑结构

上图例说明:
- 一组的消费者不会消费同一个数据
- topic都有两个follower,所以该有两个备份,应该三个副本
- 上面的映射关系都会存储在zookeeper上面

三:术语解释
由Partition组成Topic,Topic放在Broker里面
Broker
Kafka集群中包含的一个或多个服务器,服务器节点称为Broker。
消息中间件出来节点,一个Kafka节点就是一个broker,一个或多个Broker可以组成一个Kafka集群
Topic
Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
kafka数据有可能放的是支付数据、通知消息等。不同的信息需要创建不同的topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
类似与一个主题(就像是数据库中一张表(表名),数据库中将不同的信息放在不同的表中),或者是ES中的index
物理上不同Topic的消息分开存储
如数据库中,表与表的数据不是放到一起的
逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处
在操作时,我们不需要去关心这些细节
Topic是用于区分消息是被谁消费,对消息做了归类
创建查看Topic
需要进入安装目录里面进行执行
./kafka-topics.sh --create --zookeeper 192.168.156.131:2181 --replication-factor 1 --partitions 1 --topic test
# 查看topic节点
./kafka-topics.sh --list --zookeeper localhost:2181
- 1
- 2
- 3
- 4
Partition
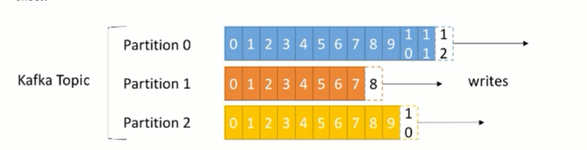
topic中的数据分割为一个或多个partition。
每个topic至少有一个partition,当生产者产生数据的时候,根据分配策略,选择分区,然后将消息追加到指定的分区的末尾(队列:先进先出)
每条消息都会有一个自增的编号
- 标识顺序
- 用于标识消息的偏移量
每个partition中的数据使用多个segment文件存储。
partition中的数据是有序的,不同partitionj间的数据丢失了数据的顺序。
如果topic有多个partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下,需要将partition数目设为1。
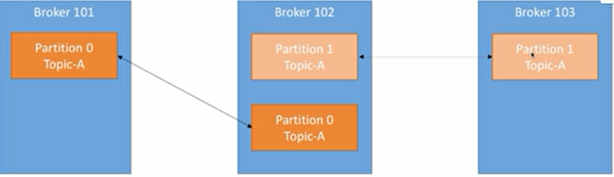
Partition也是分为主和从的:Leader、Follow
Leader(主副本)(partition主)
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
流程:
-
producer 先从 zookeeper的 " /brokers/…/state”节点找到该 partition的 leader
-
producer将消息发送给该leader
-
leader将消息写入本地 1og
-
fo11owers 从 leader pu11 消息,写入本地 1og 后 1eader发送ACK
-
leader收到所有ISR 中的 replica的 ACK后,增加HW (high watermark,最后 commit的 offset)并向 producer发送ACK
Follow(从副本)
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。
如果Leader失效,则从Follower中选举出一个新的Leader。
当Follower挂掉、卡住或者同步太慢,leader会把这个follower从" in sync replicas”(ISR)列表中删除,重新创建一个Follower。
follow同步leader里面的数据
replication(partition从)副本的备份
数据会存放到topic的partation中,但是有可能分区会损坏
所以我们需要对分区的数据进行备份(备份多少取决于你对数据的重视程度,越多越安全)
我们将分区的分为Leader(1)和Follower(N)
Leader负责写入和读取数据Follower只负责备份- 这样做的目的是:
保证了数据的一致性
备份数设置为N,表示主+备=N(参考HDFS)
Kafka分配 Replica (主从)的算法如下
- 将所有broker(假设共n个broker)和待分配的partition排序
- 将第i个partition分配到第(i mod n)个 broker 上
- 将第i 个partition的第j个replica分配到第( (i + j) mod n )个broker 上
Producer
消息生产者,向Broker发送消息的客户端
-
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。
-
broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。
-
生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
Consumer
消息消费者,从Broker读取消息的客户端
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
kafka提供了两套consumer APl:
1. The high-leve1 consumer API
2. The simpleconsumer API
区别:
high-level consumer API提供了一个从kafka消费数据的高层抽象,而SimpleConsumer API则需要开发人员更多地关注细节。
- 1
- 2
- 3
- 4

Consumer Group(消费者组)
每个Consumer属于一个特定的Consumer Group
可为每个Consumer指定group name,若不指定group name则属于默认的group
将多个消费者集中到一起去处理某一个Topic的数据,可以更快的提高数据的消费能力
一组只能读取一个数据一次
整个消费者组共享一组偏移量(防止数据被重复读取),因为一个Topic有多个分区

offset偏移量
用途:可以唯一的标识—条消息
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用kafka的消息
我们某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制
消息最终还是会被删除的,默认生命周期为1周(7*24小时)
zookeeper
kafka通过 zookeeper来存储集群的meta信息。
作用:
- 看管集群,存储一些信息
- 帮助消费者存储消费到的位置信息
0.9版本之前offset存储在ZK,0.9版本之后存储在本地(Kafka中的每一个Topic中)

