
- 1pkl文件读取
- 2latex IEEE trans 期刊缩写参考文献自动生成_latex参考文献期刊缩写
- 3【Spark系列1】DAG中Stage和Task的划分全流程_spark中怎样划分一个task
- 4docker容器技术篇:centos7搭建docker swarm集群_centos安装swarm 安装
- 5盘点13种即插即用的涨点模块,含注意力机制、卷积变体、Transformer变体_即插即用模块
- 6javaweb开发实战经典pdf,移动架构师成长路线_java web 调试 技巧 pdf
- 7【数据结构】树与二叉树(十七):二叉树的基础操作:删除指定结点及其左右子树(算法DST)_删除相关子树算法
- 8CES 2024之变:中国激情回归, AI碾压全展 | 钛媒体深度
- 9科技云报道:AI大模型疯长,存储扛住了吗?
- 10SpringBoot彩蛋(banner 图案)_搞怪的java启动类banner字符图
机器学习算法的分类与回归,有监督与无监督,决策树、随机森林、支持向量机_随机森林回归和分类的区别
赞
踩
分类与回归:
分类问题输出的是物体所属的类别,回归问题输出的是物体的值。
不管是分类,还是回归,其本质是一样的,都是对输入做出预测,并且都是监督学习。说白了,就是根据特征,分析输入的内容,判断它的类别,或者预测其值。
1.分类应用
分类问题应用非常广泛。通常是建立在回归之上,分类的最后一层通常要使用softmax函数进行判断其所属类别。分类并没有逼近的概念,最终正确结果只有一个,错误的就是错误的,不会有相近的概念。
例如判断一幅图片上的动物是一只猫还是一只狗,判断明天天气的阴晴,判断零件的合格与不合格等等。
2.回归应用
回归问题通常是用来预测一个值。另外,回归分析用在神经网络上,其最上层是不需要加上softmax函数的,而是直接对前一层累加即可。一个比较常见的回归算法是线性回归算法(LR)
如预测房价、股票的成交额、未来的天气情况等等。
有监督与无监督:
有监督学习算法,最常见的就是分类算法
常见的分类算法包括: 随机森林、决策树、朴素贝叶斯、支持向量机 (SVM)、KNN、xgBoost。
无监督学习算法,典型的就是聚类算法
聚类算法就是将数据自动聚类成几个类别,相似度大的聚在一起,主要用来做数据的划分常见的聚类算法就是 K-Means、最大期望算法 (EM)、主成分分析PCA。
决策树(Decision Tree)
原理:
决策树是一种树形结构,有根节点、内部节点和叶子节点。其中内部节点是根据信息增益(越大)或者基尼指数(越小)来选择的,最终产生叶子节点,也就是预测结果。
-
树结构: 决策树是一种层级结构,从根节点开始,逐步分裂为多个子节点,最终形成叶子节点。每个节点表示一个特征测试,每个分裂表示一个决策。
-
特征选择: 在构建决策树时,算法会选择最佳的特征来分裂数据。最佳特征是根据不同的标准(例如信息增益、基尼不纯度、均方误差等)来选择的,以尽量减小子节点中目标变量的不确定性。信息增益就是:得知特征A的信息而使得样本集合不确定性(熵)减少的程度,衡量了在已知某特征的情况下,样本集合的不确定性减少了多少。
-
分裂决策: 一旦选择了最佳特征,算法将数据集分成多个子集,每个子集对应于特征的不同取值。这个过程将递归地应用于每个子集,直到满足停止条件,如树的深度达到预定值或子集中的数据都属于相同类别。
-
叶子节点: 叶子节点是不再分裂的节点,它们包含最终的决策或输出。对于分类问题,叶子节点通常表示一个类别;对于回归问题,叶子节点表示一个数值。
-
剪枝: 决策树可能会变得过于复杂,容易过拟合训练数据。为了避免过拟合,可以对树进行剪枝,即去掉一些分支,以简化模型。
-
预测: 一旦构建了决策树,你可以使用它来进行预测。给定一个新的数据点,根据其特征从根节点开始沿着树进行遍历,直到达到叶子节点,然后返回叶子节点的预测值(分类或回归)。
-
优点:
- 易于理解和可视化,类似于人类决策过程。
- 运算速度快,不需要昂贵的计算代价。
- 不需要复杂的数据预处理。
- 可以同时处理连续变量和离散变量。其他的工具常常只能分析一种变量
-
缺点:
- 容易出现过拟合现象,特别是在深度较大的树中。
- 容易受到样本类别不平衡的影响。
- 稳定性较低,对数据集进行很小的改变就可能导致训练出完全不同的树。可以通过使用集成算法(随机森林、XGBoost)来解决这个问题。
应用场景:
-
医疗诊断: 决策树可以用于医疗领域,帮助医生诊断疾病或病症。例如,根据患者的症状和检查结果,决策树可以帮助确定可能的疾病或治疗方案。
-
金融风险评估: 银行和金融机构可以使用决策树来评估贷款申请的风险。根据借款人的信用历史、收入和其他因素,决策树可以预测贷款违约的概率。
-
自然语言处理: 决策树可以用于文本分类,例如垃圾邮件检测。根据文本中的关键词和特征,决策树可以判断一封电子邮件是否是垃圾邮件。
-
产品推荐: 在电子商务平台上,决策树可以根据用户的购买历史和兴趣,为用户推荐产品
随机森林(Random Forest)
原理:
随机森林是一种集成学习(Bagging)算法,它将一个输入样本输入到每棵决策树中进行分类,然后将若干个弱分类器的结果进行投票选择,从而组成一个强分类器。
-
随机选择样本: 从训练数据中随机选择一部分样本(有放回抽样),这些样本用于构建每棵决策树。这个过程被称为"自助采样"(Bootstrapped Sampling)。可以得知,每棵树的训练集都是不同的,但包含重复的训练样本。
-
随机选择特征: 在构建每棵决策树的过程中,随机选择一部分特征来进行分裂。这样,每棵决策树使用的特征都是不同的,增加了多样性。
-
多数投票原则: 随机森林中的每棵决策树都对数据进行预测。对于分类问题,每棵树的预测结果被视为一个投票,最终的预测结果是得到最多投票的类别。对于回归问题,每棵树的预测结果被平均,得到最终的预测值。
-
随机森林分类效果(错误率)与两个因素有关:
- 森林中任意两棵树的相关性:相关性越大,错误率越大;(弱分类器应该good且different)
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。(弱分类器应该good且different)
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m,这也是随机森林的一个重要参数。
-
优点:
- 模型随机性强,不容易过拟合;抗噪性强,对异常点不敏感。
-
处理高维数据更快,因为每棵树只使用随机选择的特征,减少了维度的影响。
-
树状结构,模型可解释性高,可以看到每个特征的重要性。因为你可以查看每棵树的投票或平均值。
-
缺点:
-
模型往往过于general,不具备正确处理过于困难的样本的能力。
-
支持向量机(Support Vector Machine,SVM)
原理:
支持向量机核心思想是找到分类间隔最大的超平面,该超平面将不同类别的数据样本分开。(在保证决策面方向不变且不会出现错分严格不能的情况下移动决策面,会在原来的决策面的两侧找到两个极限位置,如虚线所示。)并且使得离超平面最近的数据点(虚线穿过的样本点)到超平面的距离最大化。这些最接近超平面的数据点被称为支持向量。
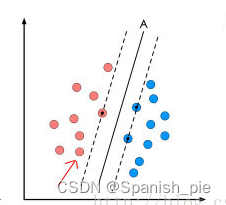
优点:
- SVM 在高维空间中表现出色,适用于处理高维数据。因为最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数。
- 核函数: SVM 可以使用核函数来处理非线性问题,将数据映射到更高维度的空间,从而使线性超平面分隔非线性数据。
缺点:
-
在大规模数据集上,SVM 的训练时间和内存消耗可能很大,因此不太适合大规模数据。
-
二分类限制: 原始的 SVM 算法是二分类器,虽然可以通过一些技巧扩展到多类别问题,但它不是天然的多类别分类器。
K-近邻(K-Nearest Neighbor, K-NN)
原理:
找到与给定样本点距离最近的k个样本。
-
距离度量: 首先,计算测试数据点与训练数据集中每个样本点之间的距离。常用的距离度量包括欧几里得距离、曼哈顿距离、闵可夫斯基距离等。
-
选择 K: 确定要考虑的最近邻的数量 K。K值的选择会对KNN算法的结果产生重大影响。
k值的减小就意味着整体模型变得复杂,分类器容易受到由于训练数据中的噪声而产生的过分拟合的影响。k值的的增大就意味着整体的模型变得简单。如果k太大,最近邻分类器可能会将测试样例分类错误,因为k个最近邻中可能包含了距离较远的,并非同类的数据点。在应用中,k值一般选取一个较小的数值,通常采用交叉验证来选取最优的k值。 -
投票或平均: 对于分类问题,根据 K 个最近邻的标签进行多数投票,以确定测试数据点的类别。对于回归问题,取 K 个最近邻的标签的平均值来估计测试数据点的值。
优点:
-
简单: KNN 是一种非常简单的算法,易于理解和实现。
-
无需训练: KNN 是一种懒惰学习(lazy learning)算法,不需要显式的训练过程。
缺点:
-
计算开销大: KNN 需要计算与每个训练样本的距离,因此在大型数据集上计算开销较大。
-
对异常值敏感: 异常值可能会对 KNN 的分类结果产生较大影响。
K-均值(k-means)
原理:
- 初始化聚类中心:随机选取k个样本作为初始的聚类中心。
- 给聚类中心分配样本:计算每个样本与各个聚类中心之间的距离,把每个样本分配给距离它最近的聚类中心。
- 移动聚类中心:新的聚类中心移动到这个聚类所有样本的平均值处。
- 停止移动:重复第2,3步,直到聚类中心不再移动为止.
优点:
-
简单而有效: K-Means 是一种简单但强大的聚类算法,容易实现和理解。
-
可伸缩性: 适用于大规模数据集,可以通过并行化实现高效的计算。
-
速度快: K-Means 在大多数情况下运行速度较快,因为它只涉及计算距离。
-
易解释性: 聚类结果直观,容易解释,每个簇都有一个中心点。
缺点:
-
对初始质心敏感: 初始质心的选择可以影响最终结果。不同的初始化可能导致不同的聚类结果。
-
需要事先指定簇的数量 K: 在实际问题中,通常不清楚应选择多少个簇。
-
对异常值敏感: 异常值可能会显著影响质心的计算和聚类结果。
-
局部最优解: K-Means 可能陷入局部最优解,因此多次运行算法并选择最佳结果通常是必要的。
-
不适合类别不平衡的数据。

