- 1山东大学软件学院网络攻击与防范2022-2023林丰波100词详解_林丰波系统安全
- 2小厂面试实录_小厂二面
- 3一键部署开源PaaS服务Dokploy,代替Vercel, Netlify 以及 Heroku
- 4AcrelCloud-6800智慧消防管理云平台在某中学的应用
- 5(文末送18本ChatGPT扫盲书)从一路高歌到遭多国“封杀”,ChatGPT未来将是什么样子?_chatgpt 书籍
- 6postgresql 配置文件 与 修改配置如何启用_pg数据库不需要重启的配置
- 7ShardingSphere 5.x 系列【11】水平分表_shardingsphere5.4水平分表
- 8c++------类和对象(下)包含了this指针、构造函数、析构函数、拷贝构造等
- 9了解等保测评的中间件安全Tomcat,如何检查配置是否符合安全要求?_通用中间件 等bao安全评估
- 10深度学习绘制热力图heatmap、使模型具有可解释性_深度学习热力图
遗传算法简单实例_遗传算法二进制编码实例
赞
踩
遗传算法的手工模拟计算示例
为更好地理解遗传算法的运算过程,下面用手工计算来简单地模拟遗传算法的各
个主要执行步骤。
例:求下述二元函数的最大值:

(1) 个体编码
遗传算法的运算对象是表示个体的符号串,所以必须把变量 x1, x2 编码为一种
符号串。本题中,用无符号二进制整数来表示。
因 x1, x2 为 0 ~ 7之间的整数,所以分别用3位无符号二进制整数来表示,将它
们连接在一起所组成的6位无符号二进制数就形成了个体的基因型,表示一个可
行解。
例如,基因型 X=101110 所对应的表现型是:x=[ 5,6 ]。
个体的表现型x和基因型X之间可通过编码和解码程序相互转换。
(2) 初始群体的产生
遗传算法是对群体进行的进化操作,需要给其淮备一些表示起始搜索点的初始
群体数据。
本例中,群体规模的大小取为4,即群体由4个个体组成,每个个体可通过随机
方法产生。
如:011101,101011,011100,111001
(3) 适应度汁算
遗传算法中以个体适应度的大小来评定各个个体的优劣程度,从而决定其遗传
机会的大小。
本例中,目标函数总取非负值,并且是以求函数最大值为优化目标,故可直接
利用目标函数值作为个体的适应度。
(4) 选择运算
选择运算(或称为复制运算)把当前群体中适应度较高的个体按某种规则或模型遗传到下一代群体中。一般要求适应度较高的个体将有更多的机会遗传到下一代
群体中。
本例中,我们采用与适应度成正比的概率来确定各个个体复制到下一代群体中
的数量。其具体操作过程是:
• 先计算出群体中所有个体的适应度的总和 fi ( i=1.2,…,M );
• 其次计算出每个个体的相对适应度的大小 fi / fi ,它即为每个个体被遗传
到下一代群体中的概率,
• 每个概率值组成一个区域,全部概率值之和为1;
• 最后再产生一个0到1之间的随机数,依据该随机数出现在上述哪一个概率区
域内来确定各个个体被选中的次数。

(5) 交叉运算
交叉运算是遗传算法中产生新个体的主要操作过程,它以某一概率相互交换某
两个个体之间的部分染色体。
本例采用单点交叉的方法,其具体操作过程是:
• 先对群体进行随机配对;
• 其次随机设置交叉点位置;
• 最后再相互交换配对染色体之间的部分基因。

(6) 变异运算
变异运算是对个体的某一个或某一些基因座上的基因值按某一较小的概率进
行改变,它也是产生新个体的一种操作方法。
本例中,我们采用基本位变异的方法来进行变异运算,其具体操作过程是:
• 首先确定出各个个体的基因变异位置,下表所示为随机产生的变异点位置,
其中的数字表示变异点设置在该基因座处;
• 然后依照某一概率将变异点的原有基因值取反。

对群体P(t)进行一轮选择、交叉、变异运算之后可得到新一代的群体p(t+1)。

从上表中可以看出,群体经过一代进化之后,其适应度的最大值、平均值都得
到了明显的改进。事实上,这里已经找到了最佳个体“111111”。
[注意]
需要说明的是,表中有些栏的数据是随机产生的。这里为了更好地说明问题,
我们特意选择了一些较好的数值以便能够得到较好的结果,而在实际运算过程中
有可能需要一定的循环次数才能达到这个最优结果。
==================================================================================
基本遗传算法的框图:

所以,遗传算法基本步骤是:
1) 初始化 t←0进化代数计数器;T是最大进化代数;随机生成M个个体作为初始群体 P(t);
2) 个体评价 计算P(t)中各个个体的适应度值;
3) 选择运算 将选择算子作用于群体;
4) 交叉运算 将交叉算子作用于群体;
5) 变异运算 将变异算子作用于群体,并通过以上运算得到下一代群体P(t + 1);
6) 终止条件判断 t≦T:t← t+1 转到步骤2;
t>T:终止 输出解。
好的,看下遗传算法的伪代码实现:
▲Procedures GA: 伪代码
begin
initialize P(0);
t = 0; //t是进化的代数,一代、二代、三代...
while(t <= T) do
for i = 1 to M do //M是初始种群的个体数
Evaluate fitness of P(t); //计算P(t)中各个个体的适应度
end for
for i = 1 to M do
Select operation to P(t); //将选择算子作用于群体
end for
for i = 1 to M/2 do
Crossover operation to P(t); //将交叉算子作用于群体
end for
for i = 1 to M do
Mutation operation to P(t); //将变异算子作用于群体
end for
for i = 1 to M do
P(t+1) = P(t); //得到下一代群体P(t + 1)
end for
t = t + 1; //终止条件判断 t≦T:t← t+1 转到步骤2
end while
end
二、深入遗传算法
1、智能优化算法概述
智能优化算法又称现代启发式算法,是一种具有全局优化性能、通用性强且适合于并行处理的算法。
这种算法一般具有严密的理论依据,而不是单纯凭借专家经验,理论上可以在一定的时间内找到最优解或近似最优解。
遗传算法属于智能优化算法之一。
常用的智能优化算法有:
遗传算法 、模拟退火算法、禁忌搜索算法、粒子群算法、蚁群算法。
(本经典算法研究系列,日后将陆续阐述模拟退火算法、粒子群算法、蚁群算法。)
2、遗传算法概述
遗传算法是由美国的J. Holland教授于1975年在他的专著《自然界和人工系统的适应性》中首先提出的。
借鉴生物界自然选择和自然遗传机制的随机化搜索算法。
模拟自然选择和自然遗传过程中发生的繁殖、交叉和基因突变现象。
在每次迭代中都保留一组候选解,并按某种指标从解群中选取较优的个体,利用遗传算子(选择、交叉和变异)对这些个
体进行组合,产生新一代的候选解群,重复此过程,直到满足某种收敛指标为止。
基本遗传算法(Simple Genetic Algorithms,GA)又称简单遗传算法或标准遗传算法),是由Goldberg总结出的一种最基本的遗传算法,其遗传进化操作过程简单,容易理解,是其它一些遗传算法的雏形和基础。
3、基本遗传算法的组成
(1)编码(产生初始种群)
(2)适应度函数
(3)遗传算子(选择、交叉、变异)
(4)运行参数
接下来,咱们分门别类,分别阐述着基本遗传算法的五个组成部分:
1、编码
遗传算法(GA)通过某种编码机制把对象抽象为由特定符号按一定顺序排成的串。
正如研究生物遗传是从染色体着手,而染色体则是由基因排成的串。
基本遗传算法(SGA)使用二进制串进行编码。
初始种群:基本遗传算法(SGA)采用随机方法生成若干个个体的集合,该集合称为初始种群。
初始种群中个体的数量称为种群规模。
2、适应度函数
遗传算法对一个个体(解)的好坏用适应度函数值来评价,适应度函数值越大,解的质量越好。
适应度函数是遗传算法进化过程的驱动力,也是进行自然选择的唯一标准,
它的设计应结合求解问题本身的要求而定。
3.1、选择算子
遗传算法使用选择运算对个体进行优胜劣汰操作。
适应度高的个体被遗传到下一代群体中的概率大;适应度低的个体,被遗传到下一代群体中的概率小。
选择操作的任务就是从父代群体中选取一些个体,遗传到下一代群体。
基本遗传算法(SGA)中选择算子采用轮盘赌选择方法。
Ok,下面就来看下这个轮盘赌的例子,这个例子通俗易懂,对理解选择算子帮助很大。
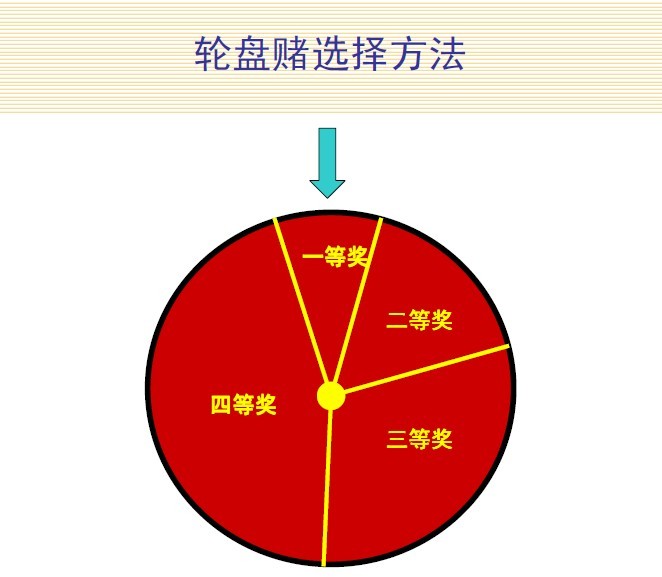
轮盘赌选择方法
轮盘赌选择又称比例选择算子,其基本思想是:
各个个体被选中的概率与其适应度函数值大小成正比。
设群体大小为N,个体xi 的适应度为 f(xi),则个体xi的选择概率为:

轮盘赌选择法可用如下过程模拟来实现:
(1)在[0, 1]内产生一个均匀分布的随机数r。
(2)若r≤q1,则染色体x1被选中。
(3)若qk-1<r≤qk(2≤k≤N), 则染色体xk被选中。
其中的qi称为染色体xi (i=1, 2, …, n)的积累概率, 其计算公式为:
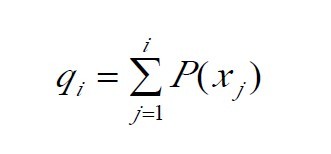
积累概率实例:

轮盘赌选择方法的实现步骤:
(1)计算群体中所有个体的适应度值;
(2)计算每个个体的选择概率;
(3)计算积累概率;
(4)采用模拟赌盘操作(即生成0到1之间的随机数与每个个体遗传到下一代群体的概率进行匹配)
来确定各个个体是否遗传到下一代群体中。
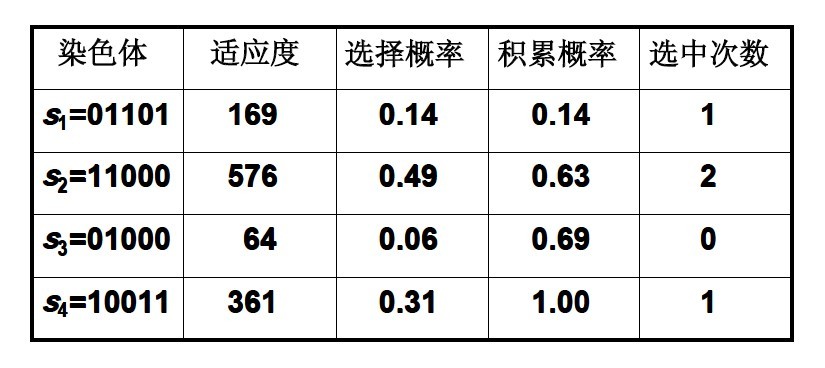
例如,有染色体
s1= 13 (01101)
s2= 24 (11000)
s3= 8 (01000)
s4= 19 (10011)
假定适应度为f(s)=s^2 ,则
f (s1) = f(13) = 13^2 = 169
f (s2) = f(24) = 24^2 = 576
f (s3) = f(8) = 8^2 = 64
f (s4) = f(19) = 19^2 = 361
染色体的选择概率为:

染色体的累计概率为:

根据上面的式子,可得到:

例如设从区间[0, 1]中产生4个随机数:
r1 = 0.450126, r2 = 0.110347
r3 = 0.572496, r4 = 0.98503
3.2、交叉算子
交叉运算,是指对两个相互配对的染色体依据交叉概率 Pc 按某种方式相互交换其部分基因,
从而形成两个新的个体。
交叉运算是遗传算法区别于其他进化算法的重要特征,它在遗传算法中起关键作用,
是产生新个体的主要方法。
基本遗传算法(SGA)中交叉算子采用单点交叉算子。
单点交叉运算

3.3、变异算子
变异运算,是指改变个体编码串中的某些基因值,从而形成新的个体。
变异运算是产生新个体的辅助方法,决定遗传算法的局部搜索能力,保持种群多样性。
交叉运算和变异运算的相互配合,共同完成对搜索空间的全局搜索和局部搜索。
基本遗传算法(SGA)中变异算子采用基本位变异算子。
基本位变异算子是指对个体编码串随机指定的某一位或某几位基因作变异运算。
对于二进制编码符号串所表示的个体,若需要进行变异操作的某一基因座上的原有基因值为0,
则将其变为1;反之,若原有基因值为1,则将其变为0 。
基本位变异算子的执行过程:

4、运行参数
(1)M :种群规模
(2)T : 遗传运算的终止进化代数
(3)Pc :交叉概率
(4)Pm :变异概率
三、浅出遗传算法
遗传算法的本质
遗传算法本质上是对染色体模式所进行的一系列运算,即通过选择算子将当前种群中的优良模式遗传
到下一代种群中,利用交叉算子进行模式重组,利用变异算子进行模式突变。
通过这些遗传操作,模式逐步向较好的方向进化,最终得到问题的最优解。
遗传算法的主要有以下八方面的应用:
(1)组合优化 (2)函数优化 (3)自动控制 (4)生产调度
(5)图像处理 (6)机器学习 (7)人工生命 (8)数据挖掘
四、遗传算法的应用
遗传算法的应用举例、透析本质(这个例子简明、但很重要)
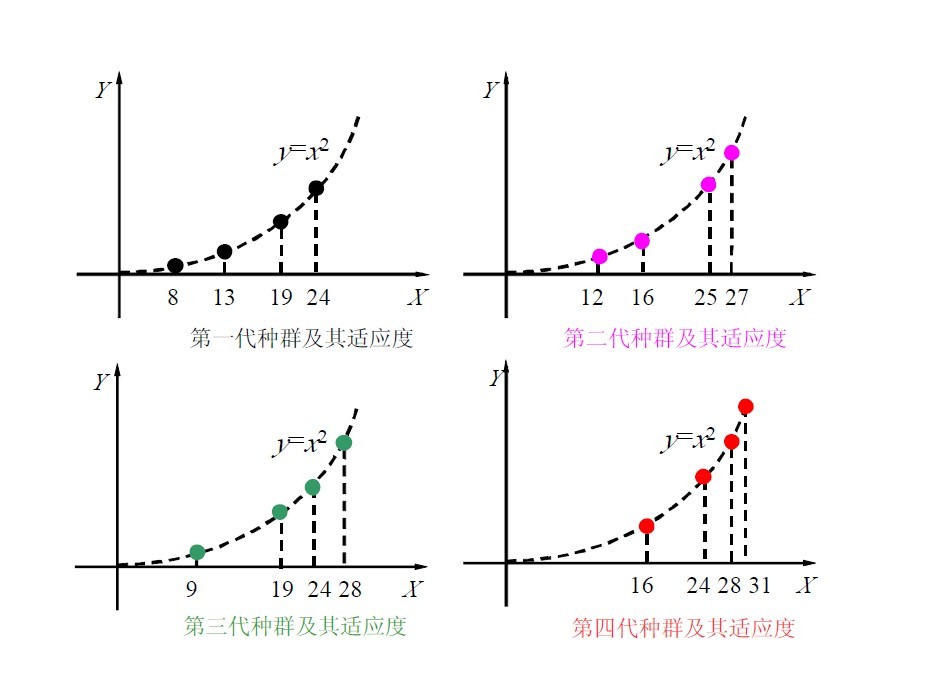
已知x为整数,利用遗传算法求解区间[0, 31]上的二次函数y=x2的最大值。

[分析]
原问题可转化为在区间[0, 31]中搜索能使 y 取最大值的点 a 的问题。
个体:[0, 31] 中的任意点x
适应度:函数值f(x)=x2
解空间:区间[0, 31]
这样, 只要能给出个体x的适当染色体编码, 该问题就可以用遗传算法来解决。
[解]
(1) 设定种群规模,编码染色体,产生初始种群。
将种群规模设定为4;用5位二进制数编码染色体;取下列个体组成初始种群S1
s1= 13 (01101), s2= 24 (11000)
s3= 8 (01000), s4= 19 (10011)
(2) 定义适应度函数, 取适应度函数
f (x)=x^2
(3) 计算各代种群中的各个体的适应度, 并对其染色体进行遗传操作,
直到适应度最高的个体,即31(11111)出现为止。
首先计算种群S1中各个体:
s1= 13(01101), s2= 24(11000)
s3= 8(01000), s4= 19(10011)
的适应度f (si), 容易求得:
f (s1) = f(13) = 13^2 = 169
f (s2) = f(24) = 24^2 = 576
f (s3) = f(8) = 8^2 = 64
f (s4) = f(19) = 19^2 = 361
再计算种群S1中各个体的选择概率:
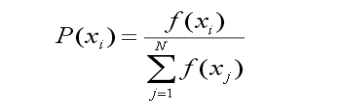
由此可求得
P(s1) = P(13) = 0.14
P(s2) = P(24) = 0.49
P(s3) = P(8) = 0.06
P(s4) = P(19) = 0.31
再计算种群S1中各个体的积累概率:
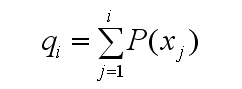
选择-复制
设从区间[0, 1]中产生4个随机数如下:
r1 = 0.450126, r2 = 0.110347
r3 = 0.572496, r4 = 0.98503
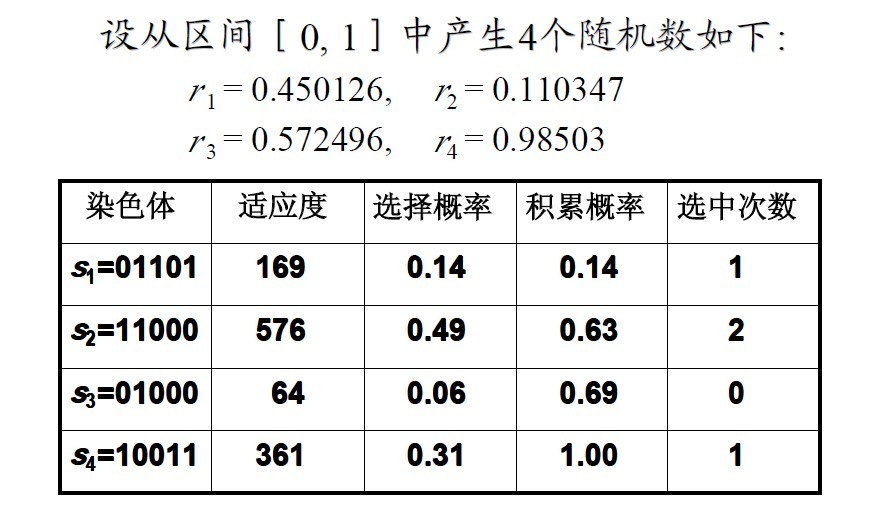
于是,经复制得群体:
s1’ =11000(24), s2’ =01101(13)
s3’ =11000(24)(24被选中俩次), s4’ =10011(19)
交叉
设交叉率pc=100%,即S1中的全体染色体都参加交叉运算。
设s1’与s2’配对,s3’与s4’配对。
s1’ =11000(24), s2’ =01101(13)
s3’ =11000(24), s4’ =10011(19)
分别交换后两位基因,得新染色体:
s1’’=11001(25), s2’’=01100(12)
s3’’=11011(27), s4’’=10000(16)
变异
设变异率pm=0.001。
这样,群体S1中共有
5×4×0.001=0.02
位基因可以变异。
0.02位显然不足1位,所以本轮遗传操作不做变异。
于是,得到第二代种群S2:
s1=11001(25), s2=01100(12)
s3=11011(27), s4=10000(16)
第二代种群S2中各染色体的情况:
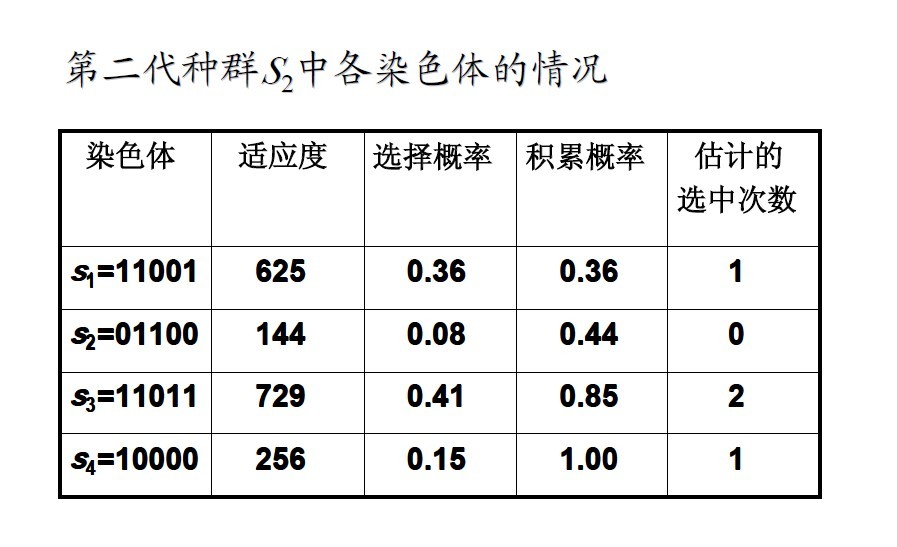
假设这一轮选择-复制操作中,种群S2中的4个染色体都被选中,则得到群体:
s1’=11001(25), s2’= 01100(12)
s3’=11011(27), s4’= 10000(16)
做交叉运算,让s1’与s2’,s3’与s4’ 分别交换后三位基因,得
s1’’=11100(28), s2’’ = 01001(9)
s3’’ =11000(24), s4’’ = 10011(19)
这一轮仍然不会发生变异。
于是,得第三代种群S3:
s1=11100(28), s2=01001(9)
s3=11000(24), s4=10011(19)
第三代种群S3中各染色体的情况:

设这一轮的选择-复制结果为:
s1’=11100(28), s2’=11100(28)
s3’=11000(24), s4’=10011(19)
做交叉运算,让s1’与s4’,s2’与s3’ 分别交换后两位基因,得
s1’’=11111(31), s2’’=11100(28)
s3’’=11000(24), s4’’=10000(16)
这一轮仍然不会发生变异。
于是,得第四代种群S4:
s1=11111(31)(出现最优解), s2=11100(28)
s3=11000(24), s4=10000(16)
显然,在这一代种群中已经出现了适应度最高的染色体s1=11111。
于是,遗传操作终止,将染色体(11111)作为最终结果输出。
然后,将染色体“11111”解码为表现型,即得所求的最优解:31。
将31代入函数y=x2中,即得原问题的解,即函数y=x2的最大值为961。
所以,综合以上各代群的情况,如下: