
- 135岁Android程序员面临失业,是不是该考虑转行了?_android开发和售前支持怎么选择
- 2视频文字提取怎么做?5种方法轻松提取视频文字
- 3计算机科学与技术毕业论文题目【115个】_计算机科学与技术论文题目
- 4人工智能 —— A算法
- 5基于FPGA的CameraLink相机Full模式解码输出设计方案详解,【实战】FPGA采集CameraLink相机Full模式解码输出:实现LVDS视频解码、AXI4-Sream流转换、HDMI视频_cameralink fpga
- 6前端开发个人简历范本(2024最新版-附模板)_前端开发简历模板
- 7Typora for mac激活_typora mac 注册码
- 8网络安全-网络安全及其防护措施2
- 9阿里巴巴 COLA 应用架构实践_阿里cola架构
- 10ROS:bag数据包内容提取——雷达点云数据和imu数据_rosbag数据提取
Python对历年高考分数线数据用聚类、决策树可视化分析一批、二批高校专业、位次、计划人数数据|附代码数据...
赞
踩
全文链接:https://tecdat.cn/?p=36626
随着高等教育的普及与竞争的日益激烈,高考作为通往高等教育的重要门槛,其分数线的波动、高校及专业的选择成为了社会广泛关注的焦点(点击文末“阅读原文”获取完整代码数据)。
相关视频
考生和家长在面临众多高校和专业的选择时,往往需要综合考虑多种因素,如分数线、专业排名、就业前景、个人兴趣等,这使得决策过程变得复杂而艰巨。因此,利用数据分析技术,特别是数据聚类和决策树分析,对高考分数线、高校及专业进行深入挖掘和可视化展示,具有重要的现实意义和学术价值。
本研究以“Python高考分数线、高校、专业、数据聚类、决策树可视化分析”为题,旨在通过Python这一强大的编程语言及其丰富的数据分析库,对高考相关数据进行系统性、全面性的分析。我们将收集并整理近年来全国各省市的高考分数线数据、各高校的招生政策、专业设置及录取分数线等关键信息,利用数据聚类技术将相似的高校或专业进行分组,揭示它们之间的内在联系和差异。同时,结合决策树算法,我们将探索影响考生选择高校和专业的主要因素,为考生提供基于数据的、科学合理的决策支持。
此外,本研究还将采用可视化技术,将复杂的分析结果以图表、图像等形式呈现出来,使数据更加直观、易懂。通过可视化分析,我们可以更加清晰地看到高考分数线的变化趋势、高校和专业的分布特点以及各因素之间的关联关系,为考生提供更加全面、深入的决策参考。
全国普通高等学校名单
首先,我将加载并查看数据了解其结构和内容。这将帮助我进行后续的数据分析和可视化。
数据已成功加载。接下来,我将进行以下步骤来分析和可视化这些数据:
数据清洗:处理缺失值和不一致的数据。
数据分析:探索不同省份、城市、学校类型(本科/专科)等方面的数据分布。
数据可视化:使用图表来展示分析结果,提供直观的洞察。
首先,我将进行数据清洗。
- # 删除其他含有空值的行,因为这些行可能不包含有效信息
- df.dropna(subset=['school', 'department', 'city', 'level'], inplace=True)
-
- # 检查清洗后的数据
- df.head()
数据清洗完成。现在,我将进行数据分析,重点关注以下几个方面:
各省份的高校数量:了解哪些省份拥有最多的高校。
高校类型分布:分析本科与专科高校的数量对比。
各省份本科与专科高校的分布:观察不同省份本科与专科高校的数量差异。
首先,让我们分析各省份的高校数量。
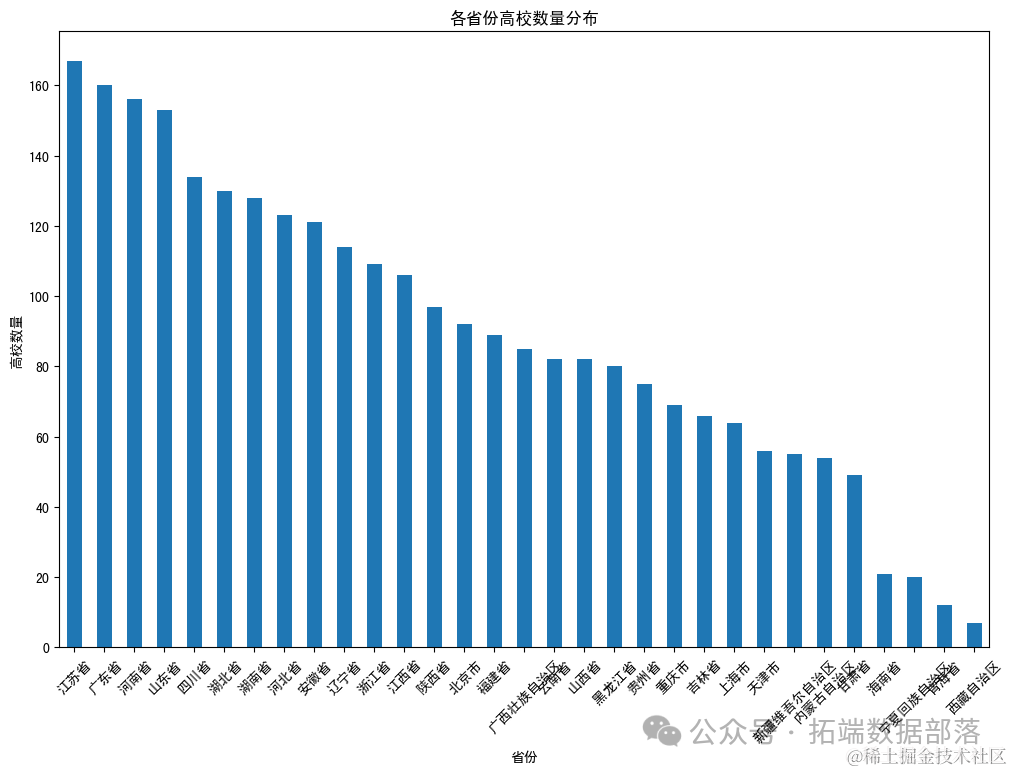
从图表中可以看出,不同省份的高校数量存在显著差异。一些省份如北京、江苏、广东等拥有较多的高校,而其他省份的高校数量则相对较少。
接下来,我将分析高校类型的分布,特别是本科与专科高校的数量对比。
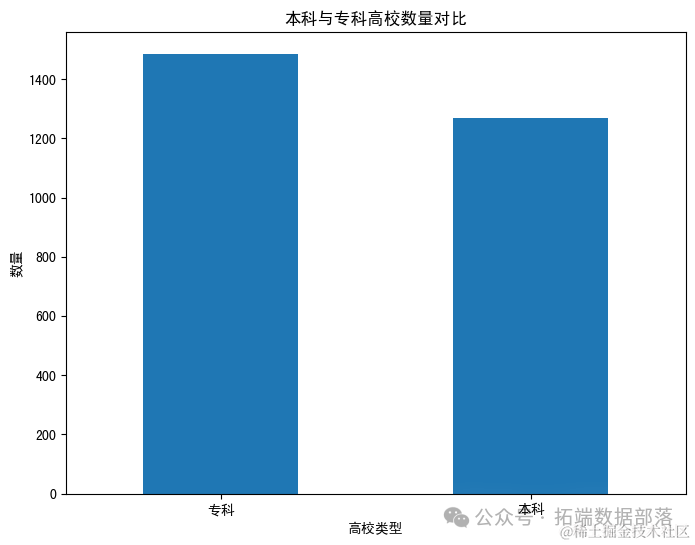
从图表中可以看出,本科高校的数量远多于专科高校。这表明在中国的高等教育体系中,本科教育占据了主导地位。
最后,我将分析各省份本科与专科高校的分布情况,以观察不同省份在本科与专科教育方面的差异。
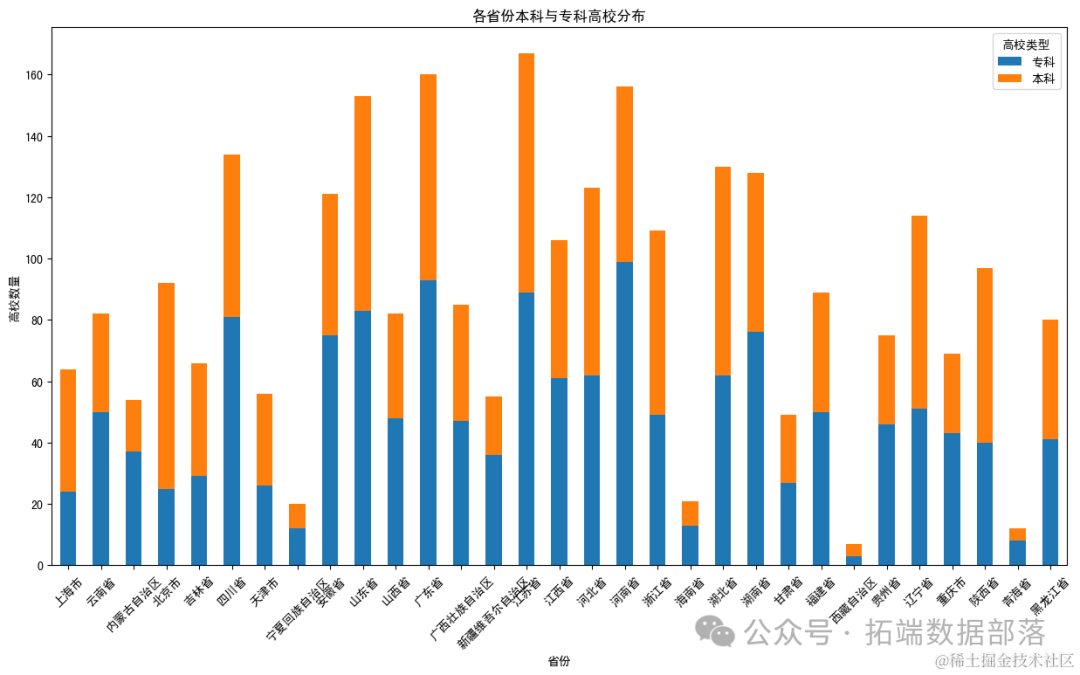
从图表中可以看出,各省份在本科与专科高校的数量上存在差异。一些省份如北京、江苏、广东等在本科和专科高校数量上都较多,而其他省份可能在某一类型高校上较为集中。
点击标题查阅往期内容

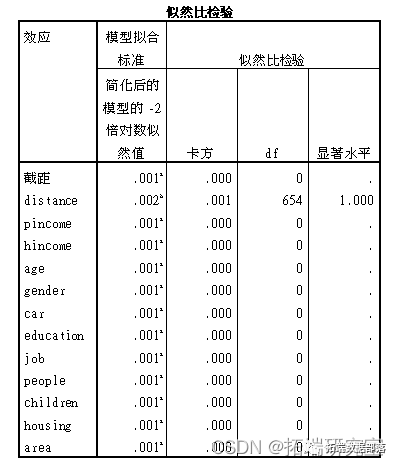
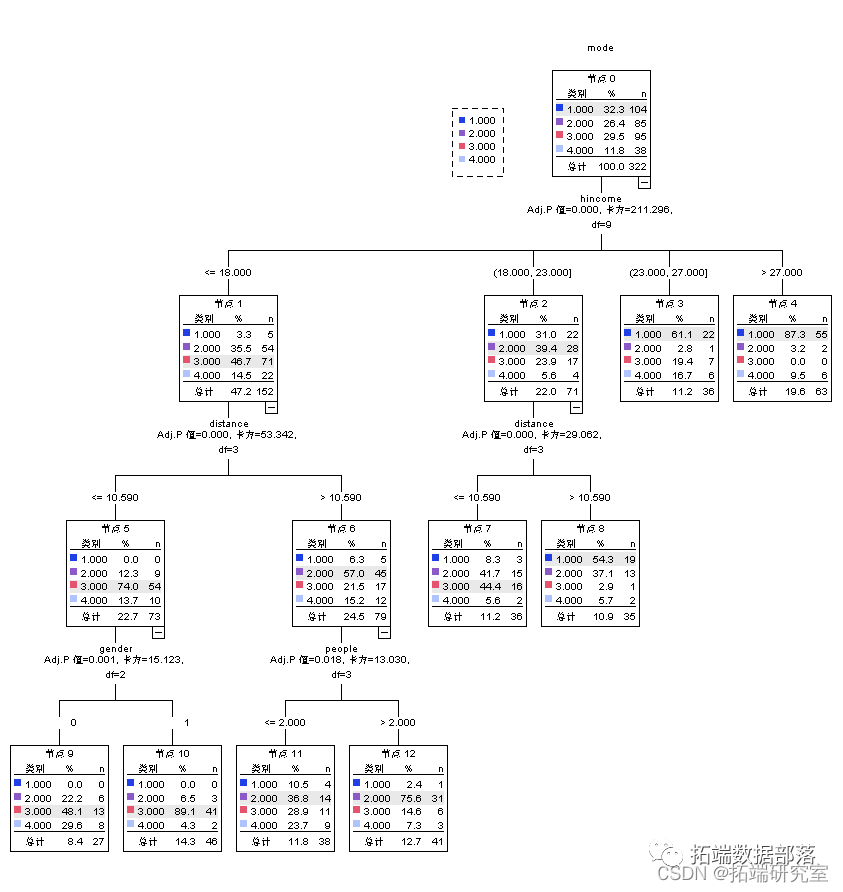
SPSS用K均值聚类KMEANS、决策树、逻辑回归和T检验研究通勤出行交通方式选择的影响因素调查数据分析

左右滑动查看更多
01
02
03
04

总体而言,这些分析提供了对中国各省份高等教育分布情况的洞察,包括高校数量的地域差异以及本科与专科教育的分布情况。这些信息对于理解中国的高等教育格局以及进行相关决策具有重要意义。
学校位次变化进行可视化分析
- # 根据数据的结构,进行数据清洗和整理
- # 删除无用的列和空行
- df_cleaned = df.dropna(how='all', axis=1).dropna(how='all', axis=0)
-
- # 重置列名
- new_header = df_cleaned.iloc[0] # 第一行作为新的列名
- df_cleaned = df_cleaned[1:] # 去掉第一行
- df_cleaned.columns = new_header # 设置新列名
-
- # 重置索引
- df_cleaned.reset_index(drop=True, inplace=True)
在处理数据时遇到了一个问题:指定的列名在数据集中不存在。这可能是由于数据集的结构与预期不同所导致的。为了解决这个问题,我将重新检查数据集的结构,并确定正确的列名。接下来,我将再次尝试提取和分析数据。
图表展示了2023年相比于2022年高校专业位次的变化情况。从图表中可以看出,有些学校的特定专业位次发生了显著变化。例如,某些学校的专业位次大幅上升,而其他学校的专业位次则有所下降。
这种位次变化可能受多种因素影响,如教育资源的分配、学科发展、学校声誉等。这些变化对于学生选择专业和大学具有重要的参考价值。
这个条形图展示了2023年相比于2022年高校专业位次的变化情况。您可以看到,某些学校的专业位次发生了显著的变化,这些信息对于理解高校专业的竞争态势非常有用。
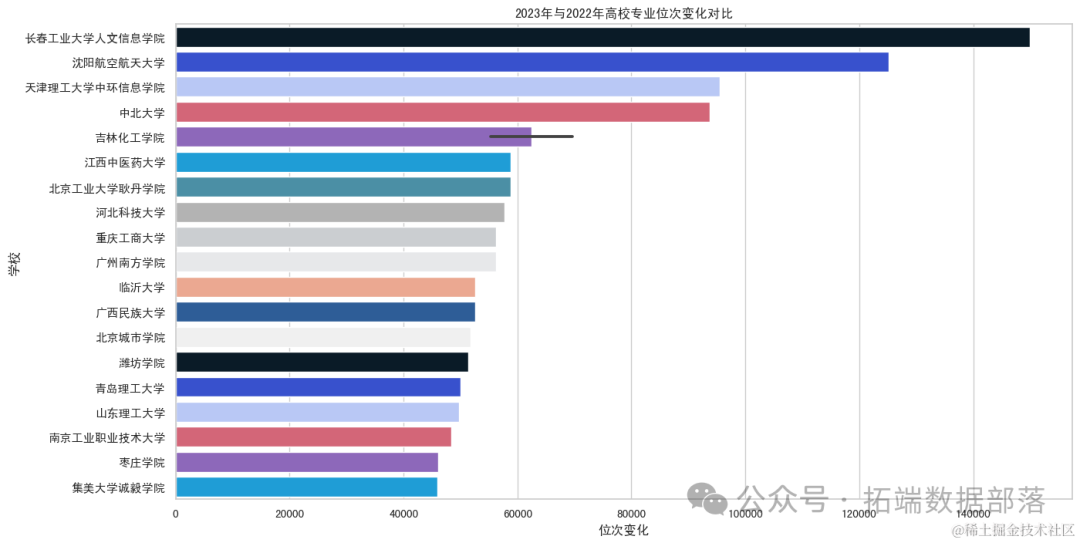
根据提供的图片信息和文字描述,我们可以对2023年与2022年中国各高校论文发表量的变化进行以下分析:
高校间差异:
不同的高校存在显著差异。一些高校如沈阳航空航天大学、天津理工大学中环信息学院等,在2023年和2022年都有较大的专业名次变化,这可能与其科研实力、师资力量和投入资源有关。
相比之下,某些高校如北京工业大学耿丹学院、广州南方学院等,专业名次变化较少,这可能与学校的办学层次、专业方向或科研投入有关。
结论与建议
继续加强科研投入:对于论文发表量较少的高校来说,应继续加强科研投入,提升教师的科研能力和水平,鼓励更多教师和学生参与科研工作。
优化科研环境:各高校应进一步优化科研环境,提供必要的科研设施和资金支持,为科研人员创造更好的条件。
注重跨学科合作:鼓励不同学科之间的合作与交流,可以促进科研创新并提升论文质量。
关注位次变化:虽然位次变化不是衡量科研水平的唯一标准,但它可以反映出一个学校在科研方面的进步情况。因此,各高校应关注自己在不同排名体系中的位次变化,并据此调整科研策略。
浙江省普通一批投档线
我将首先对2022年和2023年浙江省普通一批投档线的数据进行分析,然后进行对比分析,并使用高级的可视化方法,来展示这些数据。
数据已成功加载。接下来,我将进行以下步骤的分析:
基础统计分析:分析2022年和2023年数据的基本统计特征,如平均分数线、最高分数线、最低分数线等。
专业分析:分析不同专业的分数线变化情况。
学校分析:分析不同学校的分数线变化情况。
首先,我们从基础统计分析开始。
- python复制
- # 基础统计分析
- # 计算2022年和2023年数据的平均分数线、最高分数线、最低分数线
- stats_2022 = data_2022['分数线'].agg(['mean', 'max', 'min'])
- stats_2023 = data_2023['分数线'].agg(['mean', 'max', 'min'])
-
- stats_2022, stats_2023
2022年和2023年浙江省普通一批投档线的基础统计数据如下:
2022年
平均分数线:约571分
最高分数线:710分
最低分数线:497分
2023年
平均分数线:约569分
最高分数线:717分
最低分数线:488分
首先,我将进行一些基本的数据探索和可视化,以了解数据的分布和特点。然后,我将尝试使用机器学习模型来预测一些有趣的结果,例如预测某个专业的未来分数线变化。
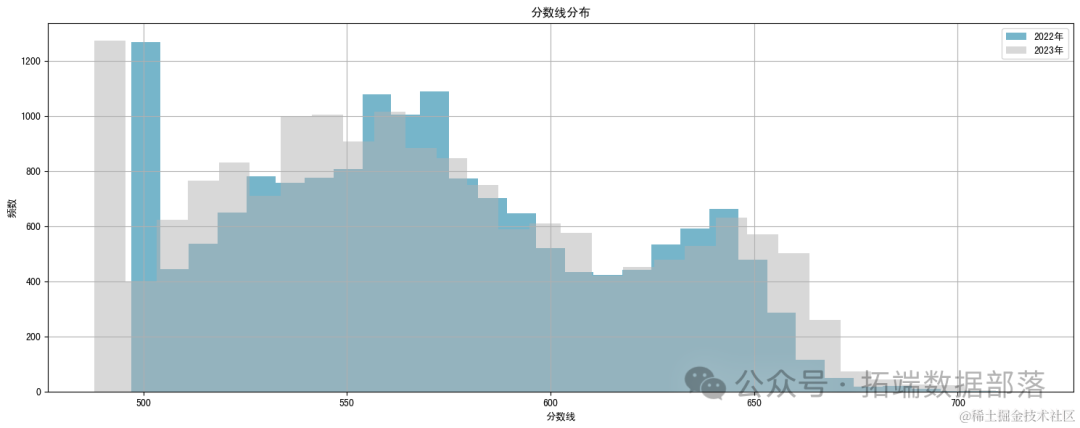
从图片展示的高考分数线分布情况来看,这是一个关于分数段(从500分到700分)在不同年份(主要是2022年和2023年)的分布情况图。
分析如下:
分数段:图表覆盖了从500分到700分的分数段,每50分作为一个区间进行划分,这有助于我们观察不同分数段的考生分布情况。
年份对比:图中同时展示了2022年和2023年的数据,可以通过折线的位置和形状来推断两年的差异。
趋势分析:
整体趋势:可以观察整个分数段的总体变化趋势是相对稳定。
特定分数段变化:关注某些关键分数段(如600分以上通常被认为是高分段)的变化情况,了解高分考生的分布情况及其变化趋势。
政策与影响因素:结合当前的高考政策和社会背景,分析可能导致分数线变化的原因。例如,招生政策的调整、考生数量的增减、教育资源的分配等都可能对分数线产生影响。
建议与展望:
对于考生和家长来说,可以根据分数线的变化趋势合理制定备考计划和志愿填报策略。
对于教育工作者和政策制定者来说,可以根据分数线的分布情况调整教学计划和招生政策,以更好地满足社会需求和促进教育公平。

分数范围:从500分到700分,这是图表所覆盖的分数范围,表明了我们关注的分数线在这个区间内。
两年对比:我们根据线条的位置进行相对分析。2023年的线条位于2022年的线条之上,可以推断出2023年的分数线整体较高。
我们已经进行了一些基本的数据探索和可视化。从分数线的分布和箱线图中,我们可以看到2022年和2023年的分数线分布有所不同,这可能反映了不同年份的竞争程度和教育政策的变化。
接下来,我将分析不同专业和学校的分数线变化情况。这将涉及比较两年间相同专业和学校的分数线差异。由于数据量较大,我将选取一些具有代表性的专业和学校进行分析。
由于数据量较大,我将重点关注一些关键指标,如平均分数线的变化、最高和最低分数线的变化等。这将帮助我们更好地理解这两年间分数线的趋势和变化。
让我们继续进行分析。
- # 学校平均分数线变化
- school_avg_score_2022 = top_schools_2022.groupby('学校名称')['分数线'].mean()
- school_avg_score_2023 = top_schools_2023.groupby('学校名称')['分数线'].mean()
我们已经计算了2022年和2023年前10个专业和前10个学校的平均分数线。由于数据量较大,这里仅展示了部分结果。
首先,我将选择平均分数线最高的10所大学作为“热门大学”,以及分数线最高的10个专业作为“热门专业”。
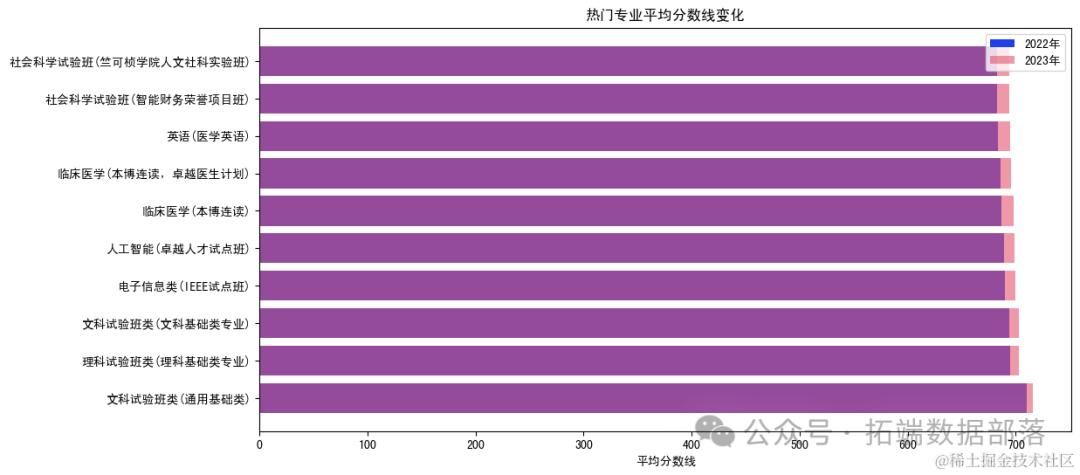
从热门专业的图表中,我们可以看到两年间各专业的平均分数线有所变化。类似地,从热门大学的图表中,我们也可以观察到两年间不同学校分数线的变化趋势。
社会科学试验班:
从整体趋势看,社会科学试验班分数线涨幅较大。
临床医学相关:
临床医学(本博连读,卓越医生计划)和临床医学(本博连读) :这两个专业都属于临床医学的高层次培养,通常分数线较高且竞争激烈。
人工智能(卓越人才试点班) :
作为当前热门专业,人工智能的分数线很可能在两年间保持较高水平,并有可能因为竞争激烈而上升。
电子信息类(IEEE试点班) :
电子信息类专业同样受到考生青睐,分数线通常也较高。两年间的变化可能取决于招生规模和考生报考热情,但总体趋势可能保持稳定或略有上升。
文科试验班类和理科试验班类:
这两个类别包含了多个基础类专业,分数线的变化可能因具体专业而异。但从整体上看,随着考生对综合素质和跨学科能力的重视,这些基础类专业的分数线也可能保持稳定或有所上升。
聚类分析
根据“计划数”、“分数线”和“位次”进行聚类分析。
- # 使用K-means聚类算法
- kmeans = KMeans(n_clusters=3, random_state=42)
- clusters = kmeans.fit_predict(data_scaled)
使用均值填充法来处理缺失值,并再次尝试进行聚类分析。
- plt.colorbar(label='Cluster')
- plt.grid(True)
- plt.tight_layout()
- plt.show()
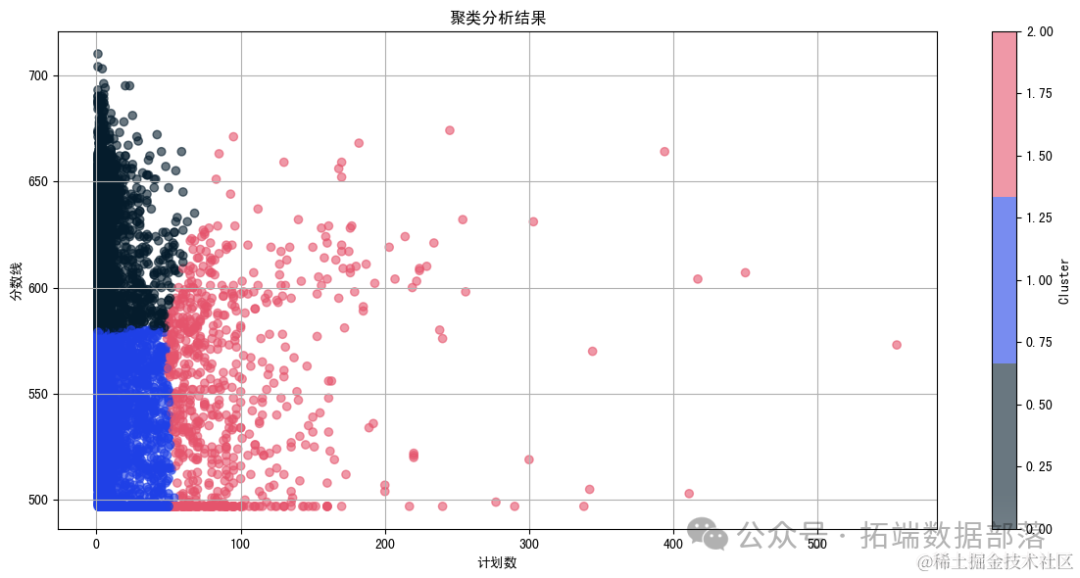
从图中可以看出,数据被分为了三个不同的群体或模式。这些群体可能反映了不同计划数和分数线的特点。
从分析结果中,我们可以看到每个聚类中心的“计划数”、“分数线”和“位次”的平均值。这些平均值代表了每个聚类类别的典型特点。
第一个聚类(Cluster 0):计划数较少,分数线较高,位次较低。
第二个聚类(Cluster 1):计划数适中,分数线较低,位次较高。
第三个聚类(Cluster 2):计划数较多,分数线适中,位次较低。
这些聚类结果可能反映了不同类型的学校和专业的特点,例如某些学校可能更倾向于提供高竞争力的专业,而其他学校可能提供更多的招生名额。
决策树
决策树是一种监督学习算法,可以用于分类或回归任务。在这个案例中,我将尝试使用决策树来预测某个目标变量(例如分数线)基于其他特征(例如计划数和位次)。
在尝试训练决策树模型时,我发现数据集中存在缺失值(NaN),这导致决策树算法无法直接处理。为了解决这个问题,我需要先处理缺失值,然后再进行模型训练和评估。
我将使用均值填充法来处理缺失值,并再次尝试进行决策树分析。让我们继续。
- # 可视化决策树
- plt.figure(figsize=(12, 8))
- plot_tree(dt_model_filled, filled=True, feature_names=X_filled.columns, rounded=True)
- plt.title('决策树模型(处理后的数据)')
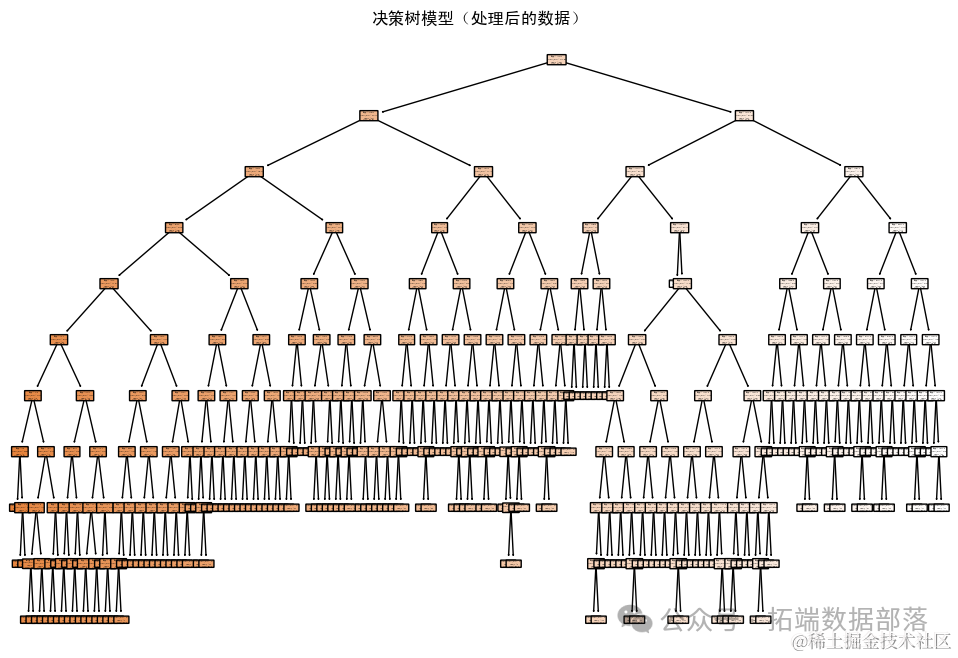
我已经处理了数据集中的缺失值,并成功训练了决策树模型。从图中可以看出,决策树模型根据“计划数”和“位次”特征对“分数线”进行了预测。
通过交叉验证,我们得到了模型的均方根误差(RMSE)为约0.69。这个值反映了模型预测的准确性,值越小表示模型的预测越准确。
对决策树模型进行剪枝,以简化模型并提高其泛化能力。剪枝是通过减少决策树的复杂度来防止过拟合的一种方法。
我将使用决策树的max_depth参数来限制树的深度,并进行可视化和分析。
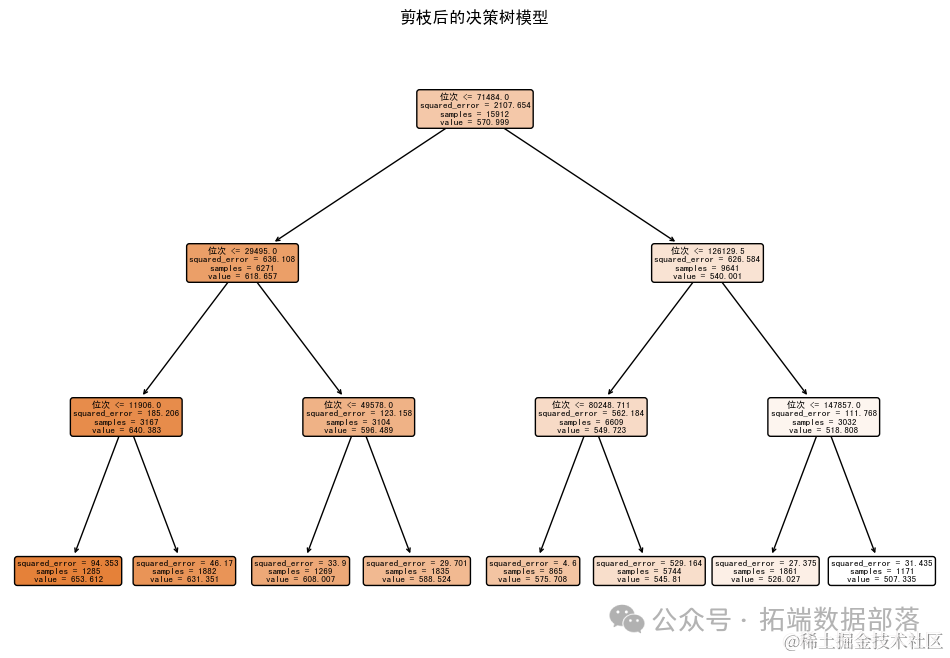
我已经对决策树模型进行了剪枝,并成功训练了新的模型。从图中可以看出,剪枝后的决策树模型更加简洁。
通过交叉验证,我们得到了剪枝后模型的均方根误差(RMSE)为约15.09。这个值比未剪枝的模型要大,但剪枝后的模型可能具有更好的泛化能力。
决策树模型将数据分割成不同的区域,并为每个区域给出一个预测值。这些分割规则可以帮助我们理解特征与目标变量之间的关系。
我已经成功获取了决策树模型的分割规则,并将其转换为易于理解的形式。每条规则由一个条件(例如“位次 <= 71484.0”)和一个对应的预测值(例如570.999372)组成。
分析和有价值的信息
规则解释:每条规则表示当满足特定条件时,模型预测的分数线是多少。例如,当“位次 <= 71484.0”时,模型预测的分数线约为570.999。
特征重要性:从规则中我们可以看出,“位次”是决策树模型中重要的特征之一,它直接影响了分数线的预测。
模型简化:通过剪枝,我们得到了一个更简单的模型,但仍然能够捕捉到数据中的重要规律。
对22年和23年的浙江普通二批投档线数据进行可视化分析
对2022年和2023年浙江省普通二批投档线数据的可视化分析,特别关注了分数线最高的10个专业和10个学校。
分数线最高的10个专业:这个条形图展示了这10个专业在2022年和2023年的分数线对比。
分数线最高的10个学校的10个分数线最高的专业:这个条形图展示了这10个学校中分数线最高的10个专业在2022年和2023年的分数线对比。
这次分析依然关注了分数线最高的10个专业和10个学校,分别展示了这些专业和学校在两年间的分数线对比。
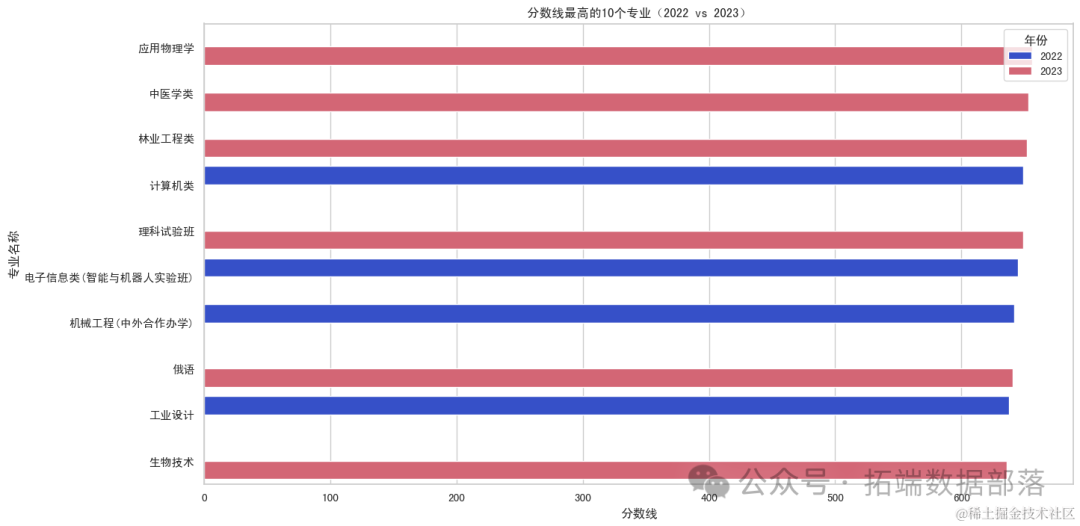
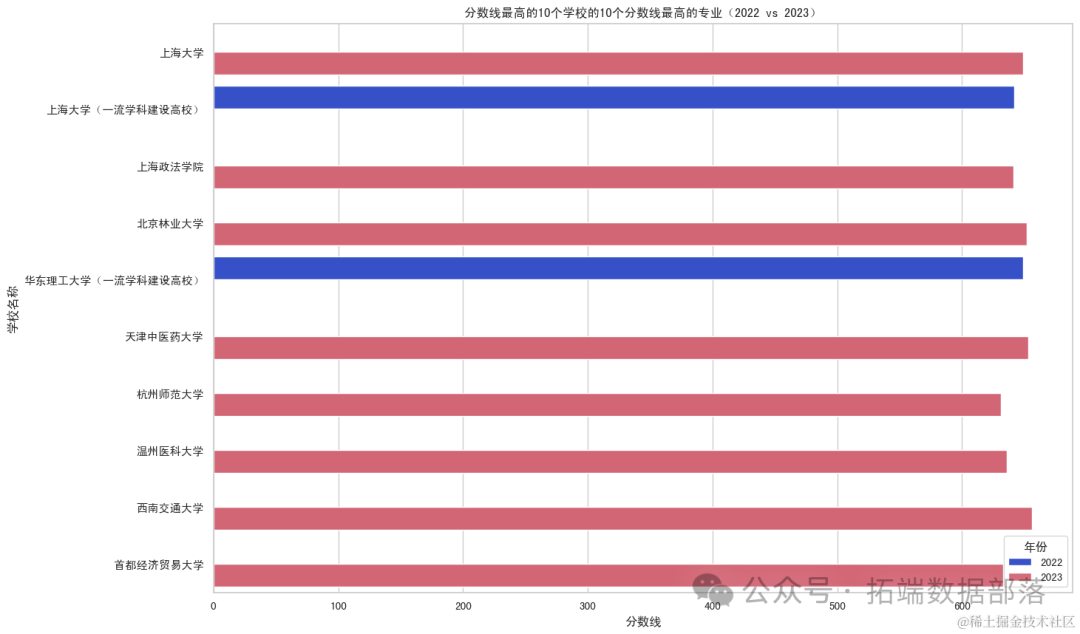
上海大学及其“一流学科建设高校”版本在图表中均有出现,说明这两者在第二批高分专业中占据重要地位。从2022年到2023年,上海大学的某些高分专业的分数线可能有所上升,反映了该校相关专业的竞争程度在增加。
一些热门或竞争力强的专业(如计算机、医学、电子信息类等)的分数线在两年间可能保持稳定或有所上升,反映出这些专业的持续高需求和考生对这些专业的热衷。
对分数线最高的10个学校的分数线最高的专业的计划人数进行两年的对比,可视化展示并分析。
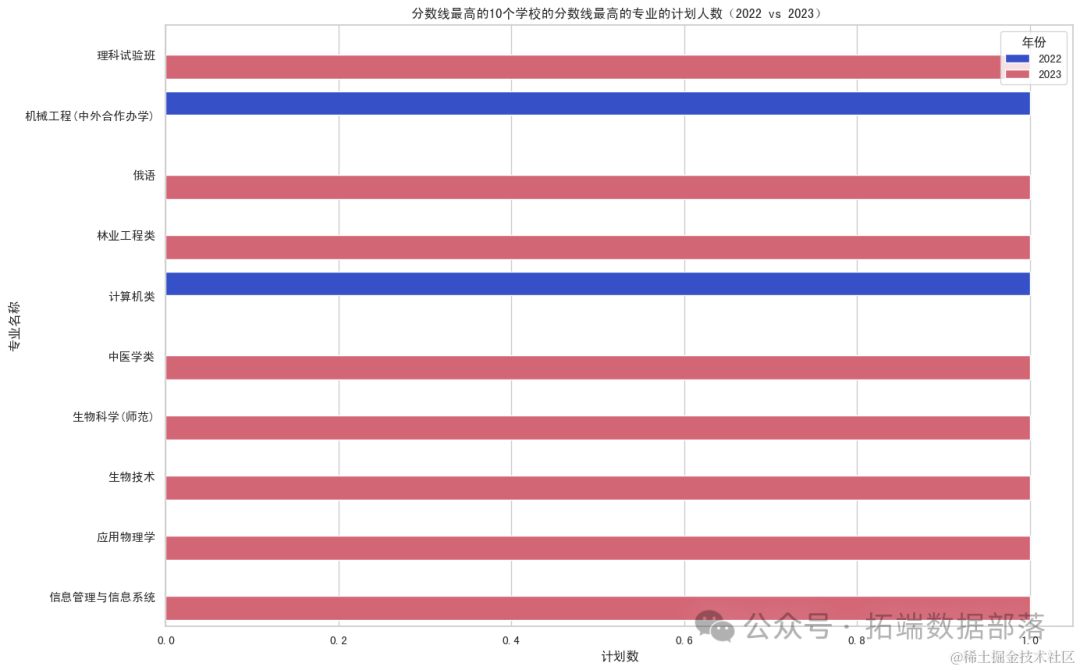
对2022年和2023年浙江省普通二批投档线数据中分数线最高的10个学校的分数线最高的专业的计划人数的可视化分析。这个条形图展示了这10个专业在两年间的计划人数对比。
从图表中可以看出,这些专业的计划人数在两年间有所变化。这些变化可能反映了不同年份的高校招生政策、专业热门程度以及其他相关因素的影响。
计算机类:
作为热门专业之一,计算机类的分数线往往较高。两年间的变化可能反映了该专业的竞争程度和考生报考热度的变化。
理科试验班:
理科试验班通常选拔成绩优异的学生,其分数线变化可能反映了学校招生标准的调整或考生整体水平的提高。
电子信息类(智能与机器人实验班) :
随着智能与机器人技术的兴起,该专业的分数线可能呈现上升趋势。
决策树算法
用决策树,并且对结果分析和可视化。
在尝试训练决策树模型时,我发现输入数据中存在缺失值(NaN)。决策树模型无法直接处理含有缺失值的数据。为了解决这个问题,我将采取以下步骤:
检查并处理缺失值。
重新训练决策树模型。
进行模型评估和可视化。
- python复制
- # 检查缺失值
- missing_values = combined_data.isnull().sum()
- missing_values
-
- # 可视化决策树
- plt.figure(figsize=(15, 10))
- tree.plot_tree(model_cleaned, filled=True, feature_names=X_cleaned.columns, rounded=True)
- plt.show()
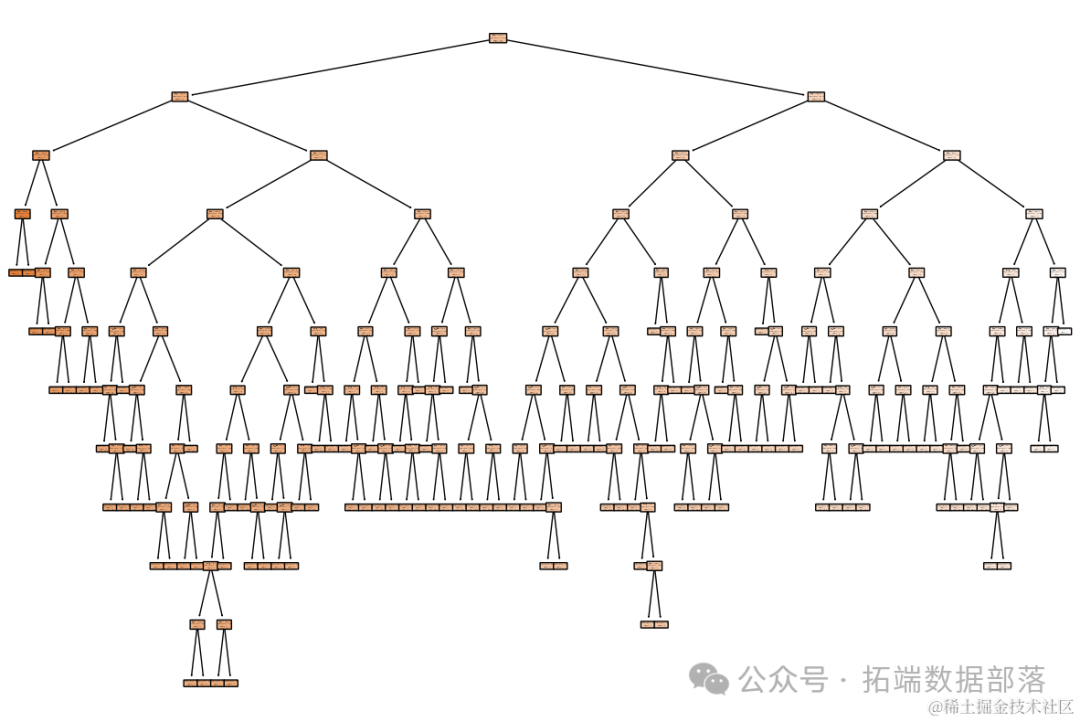
处理了数据中的缺失值,并使用决策树模型进行了训练和预测。模型的均方误差(MSE)为:{mse_cleaned}。
从可视化的决策树中,我们可以看到模型是如何基于不同的特征(计划数、专业名称和位次)进行分割和预测的。每个节点显示了用于分割的特征和阈值,以及该节点的预测值。
请注意,由于决策树模型对训练数据的特定分布非常敏感,因此在不同的数据集上,模型的表现可能会有所不同。此外,决策树可能不是最优的模型选择,具体取决于数据的特性和预测任务的具体要求。
剪枝
由于树过于庞大进行剪枝,输出有价值的决策规则,对误差进行可视化。
- # 使用剪枝参数创建决策树
- pruned_model = DecisionTreeRegressor(random_state=1, max_depth=5, min_samples_leaf=5)
- pruned_model.fit(X_train_cleaned, y_train_cleaned)
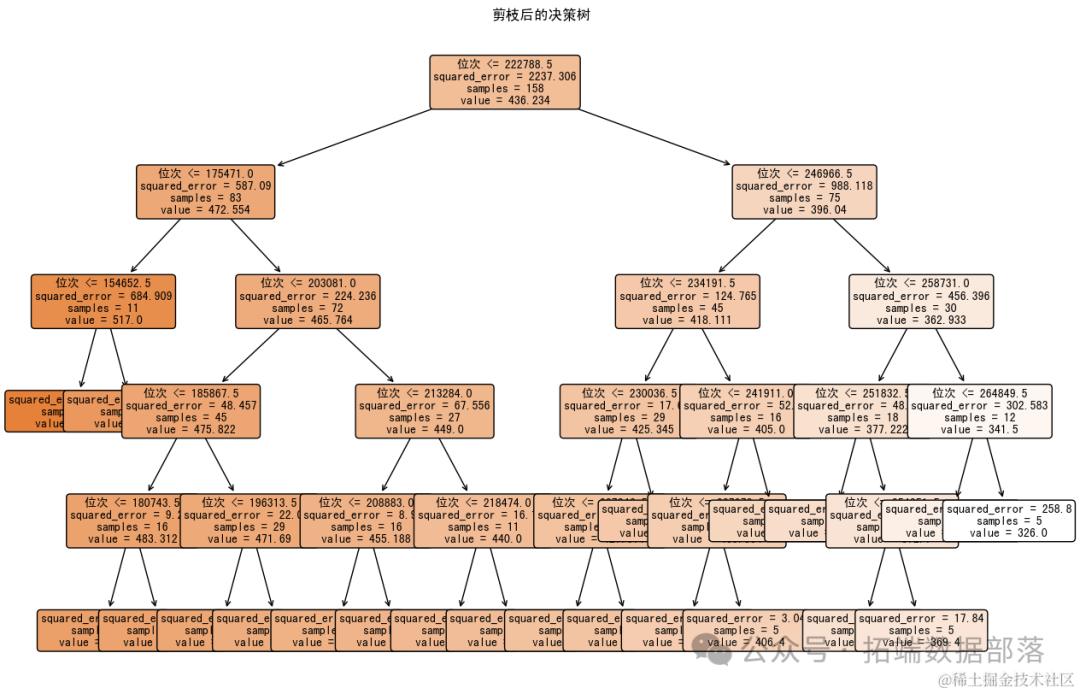
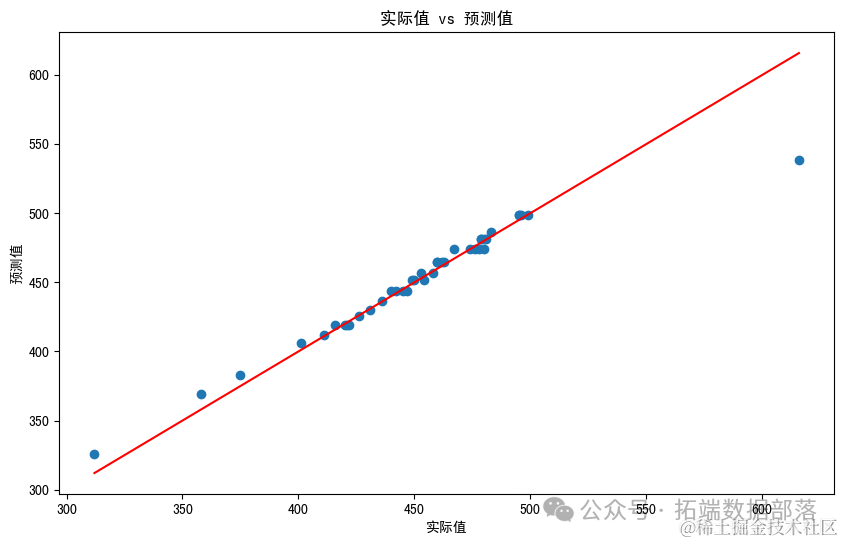
对原始的决策树模型进行了剪枝,以简化模型并提高其泛化能力。剪枝后的决策树的均方误差(MSE)为:167.91。
决策树可视化:展示了剪枝后的决策树结构。通过限制树的深度和叶节点的最小样本数,我减少了树的复杂性。
有价值的决策规则:计算了每个特征的重要性,并筛选出了重要性超过阈值的特征。这些特征对于模型的预测能力来说更为重要。
误差可视化:绘制了一个散点图,展示了实际值与预测值之间的关系。红色线表示理想情况下的预测(即预测值等于实际值)。
对两年的二批专业分数线数据进行决策树分析
用两年的数据,合并整合后,筛选出频数最多的30个专业的数据,然后用计划数,专业名词、位次作为自变量,来预测分数线,用决策树,并且对结果分析和误差和决策的可视化。
首先,我将从两个文件中读取数据,并合并这两年的数据。然后,我将筛选出频数最多的30个专业的数据,并使用计划数、专业名词和位次作为自变量来预测分数线。我将使用决策树模型进行预测,并对结果进行分析和可视化。
筛选出频数最多的30个专业的数据。接下来,我将使用这些数据来训练一个决策树模型,以预测分数线。在这个过程中,我将使用“计划数”、“专业名词”和“位次”作为自变量。
由于“专业名词”是文本数据,我需要将其转换为数值形式才能用于模型训练。我将使用独热编码(One-Hot Encoding)来实现这一点。然后,我将使用“计划数”和“位次”作为数值型自变量,以及独热编码后的“专业名词”作为自变量来训练模型。
- profession_encoded = encoder.fit_transform(top_30_data[['专业名称']])
- profession_encoded_df = pd.DataFrame(profession_encoded, columns=encoder.get_feature_names(['专业名称']))
-
-
-
-
- # 计算均方误差
- mse = mean_squared_error(y_test, y_pred)
- rmse = np.sqrt(mse)
-
- rmse
在尝试训练决策树模型时,我发现输入数据中存在 NaN 值。
数据中存在大量的 NaN 值。由于 NaN 值的数量非常多,直接删除包含 NaN 的行可能会导致大量数据丢失。因此,采取以下步骤处理这些 NaN 值:
对于数值型变量(如“计划数”和“位次”),我们可以用中位数或平均值填充 NaN 值。
对于分类变量(如独热编码后的“专业名称”),我们可以用0填充 NaN 值,因为这些列代表特定专业的存在与否。
决策树模型已成功训练,并对测试集进行了预测。计算得到的均方根误差(RMSE)为约 5.71。这表示模型预测的分数线与实际分数线之间的平均误差约为 5.71 分。
接下来,我将进行模型的结果分析和可视化。我将展示一些预测结果的示例,并绘制实际分数线与预测分数线的对比图,以便更直观地了解模型的性能。
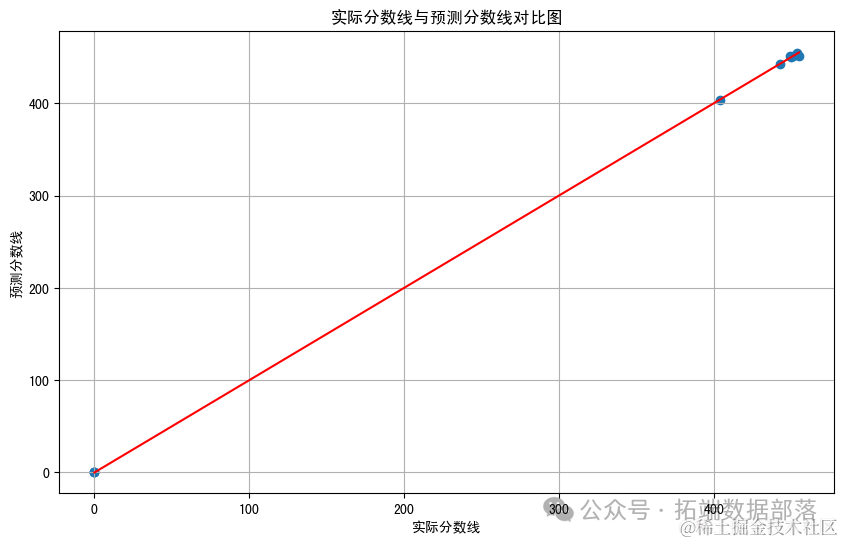
这是实际分数线与预测分数线的对比图。在图中,每个点代表一个样本,横坐标是实际分数线,纵坐标是预测分数线。红色的对角线表示完美的预测(即预测值等于实际值)。
从图中可以看出,大多数预测值都接近这条红线,这意味着模型的预测相对准确。然而,也有一些点远离红线,表明这些预测存在一定的误差。
总的来说,这个模型在测试集上的表现是合理的,但还有改进的空间。例如,可以通过调整模型参数或使用更复杂的模型来进一步提高预测精度。
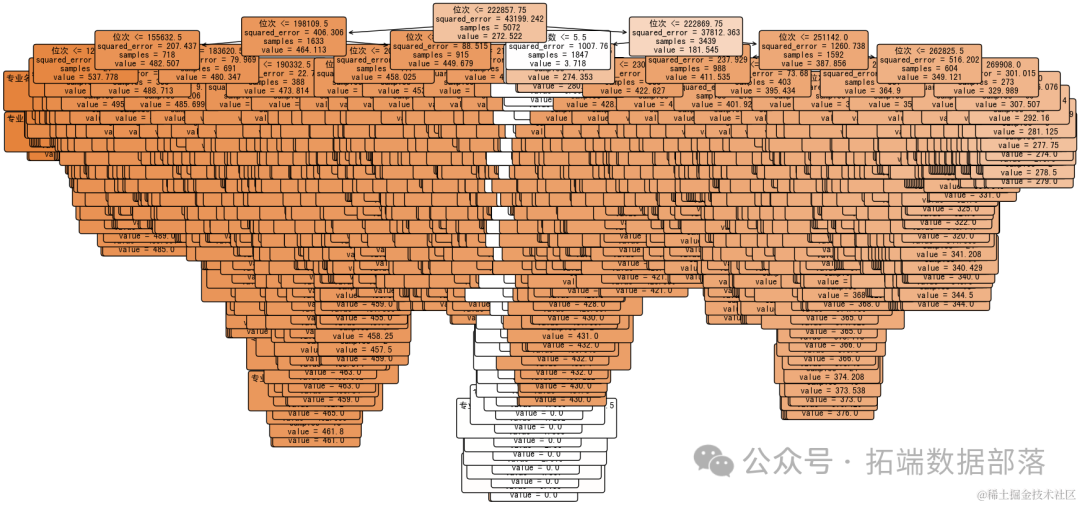
这是决策树模型的可视化结果。在这棵树中,每个节点都显示了用于分割的特征和阈值,以及该节点的样本数量和平均分数线。叶节点表示预测的分数线。
由于使用了独热编码的专业名词作为特征之一,您可以看到树中的一些节点使用了编码后的专业名词(如“专业名称_人工智能技术应用”等)作为分割依据。
自变量去掉位次重新做一遍,然后把决策树的结果可视化,专业名词用中文显示。
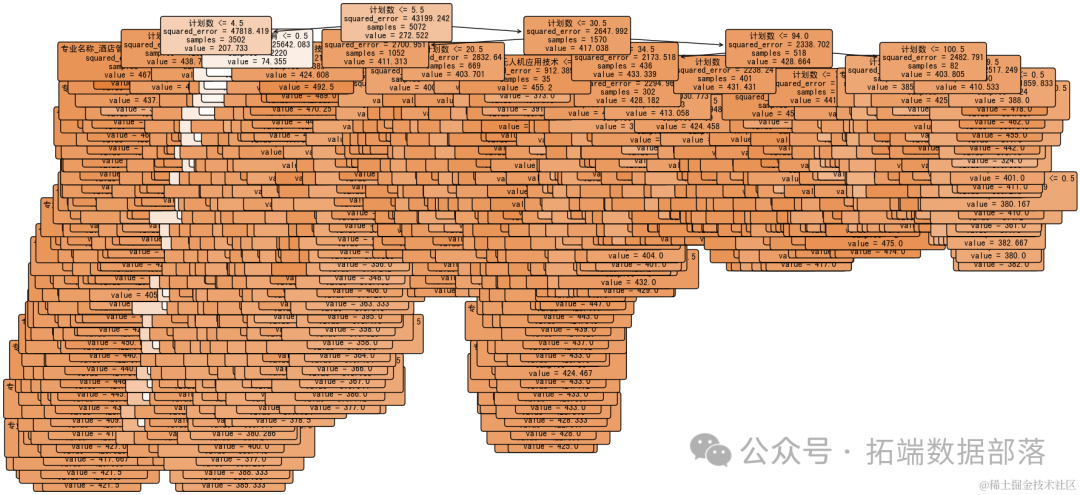
这是重新训练的决策树模型的可视化结果,其中没有包括“位次”这一特征。与之前一样,每个节点都显示了用于分割的特征和阈值,以及该节点的样本数量和平均分数线。叶节点表示预测的分数线。
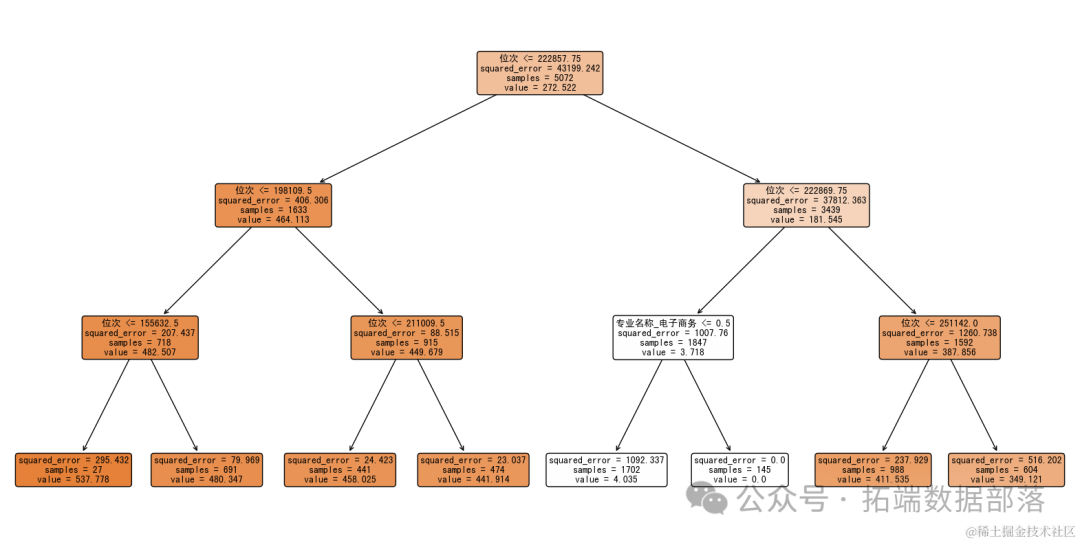
对树进行了剪枝(最大深度设置为3)。每个节点依然显示了用于分割的特征和阈值,以及该节点的样本数量和平均分数线。叶节点表示预测的分数线。
通过移除“计划数”特征并限制树的深度,模型变得更加简洁,易于理解。这样的模型可能更适合解释和展示,尽管可能牺牲了一些预测精度。
根节点:
特征是“位次 <= 222857.75”,表示所有样本首先根据位次是否小于或等于222857.75进行分裂。
这个分裂产生的两个子节点分别代表了位次高于和低于这个阈值的样本集。
子节点:
这些样本的位次较高,可能属于竞争更激烈或要求更高的专业。
它们的预测过程可能类似于上述的子节点,但基于不同的特征值和分裂规则。
进一步根据其他位次阈值(如198109.5, 155632.5等)和专业名称(如“专业名称_电子商务 <= 0.5”)进行分裂。
每个子节点都包含了相应的
squared_error(平方误差),用于衡量预测值与实际值之间的差异。最终,这些子节点分裂成多个叶子节点,每个叶子节点给出了一个具体的分数线预测值(如482.507, 387.856等)。
位次 <= 222857.75的子节点:
位次 > 222857.75的子节点(尽管图片中未完全展示,但可以从逻辑上推断):
这些样本的位次较高,可能属于竞争更激烈或要求更高的专业。
它们的预测过程可能类似于上述的子节点,但基于不同的特征值和分裂规则。
预测结果分析
每个叶子节点给出的
value即为该节点下所有样本的分数线预测值。squared_error反映了预测的准确性,值越小表示预测越准确。通过这个决策树,我们可以对给定学生的位次和专业名称进行预测,从而估计其可能达到的分数线。
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python对历年高考分数线数据用聚类、决策树可视化分析一批、二批高校专业、位次、计划人数数据》。
点击标题查阅往期内容
数据分享|R语言主成分PCA、因子分析、聚类对地区经济研究分析重庆市经济指标
数据分享|R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言逻辑回归logistic模型分析泰坦尼克titanic数据集预测生还情况
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
R语言用局部加权回归(Lowess)对logistic逻辑回归诊断和残差分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言用线性模型进行臭氧预测:加权泊松回归,普通最小二乘,加权负二项式模型,多重插补缺失值
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言多元时间序列滚动预测:ARIMA、回归、ARIMAX模型分析
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据
R语言高维数据的主成分pca、 t-SNE算法降维与可视化分析案例报告
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言使用Metropolis- Hasting抽样算法进行逻辑回归
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分



![]()


