
- 1Android Studio gradle下载失败_gradle-8.0-bin.zip 下载失败
- 2ONLYOFFICE 8.1 版本桌面编辑器测评
- 3开源项目:机遇与挑战共存的创新之路
- 4YOLOv10改进 | 主干/Backbone篇 | 轻量级网络ShuffleNetV1(附代码+修改教程)
- 5百度安全X盈科全球数据合规服务中心:推进数据安全及合规智能化创新领域深化合作
- 6Win10下配置CUDA8.0+Tensorflow1.3+Python3.6_cuda 8.0安装tensorflow1.3.0
- 7MongoDB 安装和数据导入导出问题_mongodb compass如何 export data
- 8Google的guava缓存学习使用_谷歌guava缓存
- 9HBase HMaster启动和停止
- 10Flutter和React Native(RN)的比较
被顶会录用啦!北大张铭、田渊栋、ResNeXt一作谢赛宁等大佬晒成绩单
赞
踩
ICLR 2024录用结果出来了。
昨晚,AI圈的童鞋们收到ICLR官方推送的录用邮件后,纷纷晒出了成绩单。

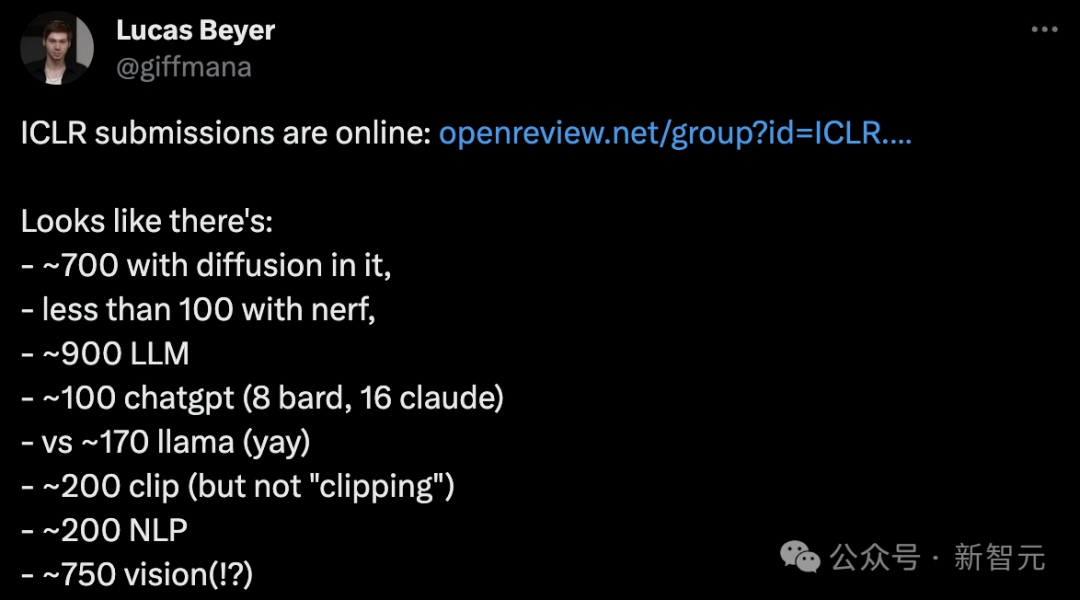
邮件显示,今年ICLR 2024组委会共收到了7262篇投稿,总体录用率约为31%,与去年相似(2023年总投稿数5000)。
其中spotlights论文的录用率为5%(约有363篇),Oral论文的录用率为1.2%(约有85篇)。

ICLR提交的论文主题大致包括:700篇有扩散,NeRF少于100篇,900多篇大模型,100多篇ChatGPT(8篇Bard,16篇Claude),170篇关于Llama,200篇CLIP,200篇NLP,大约750篇视觉研究。
第12届ICLR 2024将在5月7日-11日在奥地利维也纳开幕。
ICLR由图灵奖巨头Yoshua Bengio和Yann LeCun牵头举办,是国际公认的深度学习顶会之一。2013年开启了第一届,一年举办一次。

ICLR的影响力也是逐渐得到广泛学者的认可。在谷歌期刊排名中,ICLR位列第十。
一起看看,ICLR接收的论文都有哪些?
华人学者晒出成绩单
Meta AI的科学家田渊栋发文称,自己团队共有4篇论文被ICLR接收,其中一篇H-GAP还是spotlight。


论文地址:https://arxiv.org/pdf/2307.12950.pdf

论文地址:https://arxiv.org/pdf/2312.02682.pdf

论文地址:https://arxiv.org/pdf/2309.17453.pdf

论文地址:https://arxiv.org/pdf/2310.00535.pdf
曾与何恺明共同提出ResNeXt架构的CV大神谢赛宁的一篇论文被录用为spotlight。


论文地址:https://arxiv.org/pdf/2309.16671.pdf
北大张铭教授发文祝贺祝贺组里博士沈剑豪、袁野,硕士留学生Srbuhi Mirzoyan跟华盛顿圣路易斯大学王晨光老师(2011-2016我组博士生)合作的论文被机器学习顶会ICLR 2024接受。
这篇论文引入了一个新的挑战来测试神经模型的STEM技能,需要理解多模态视觉语言信息。研究人员在数据集上测试了CLIP和ChatGPT等基础模型,它们只具备有限较低年级水平的技能(三年级的2.5%),远低于人类小学生(平均54.7%)的表现,更不用说接近专家水平的表现了。

论文地址:https://openreview.net/pdf?id=spvaV5LELF
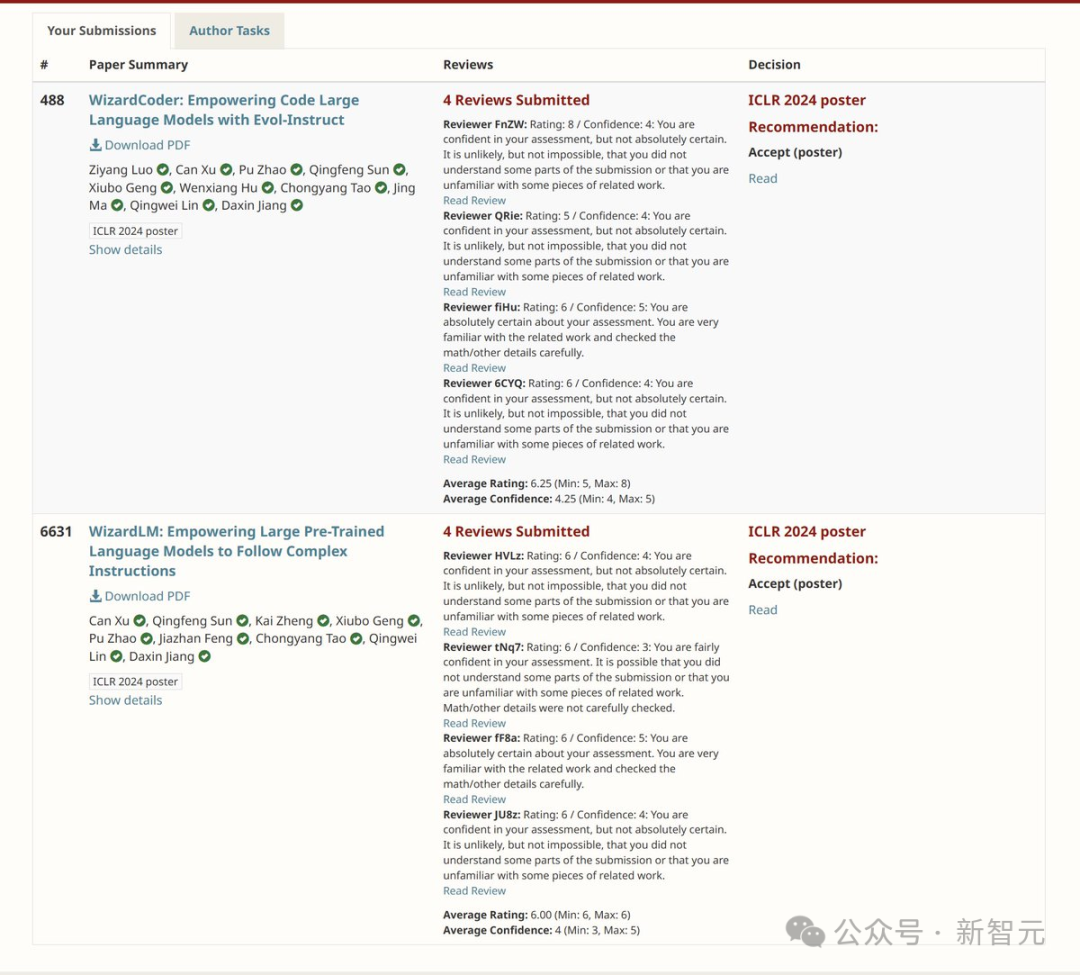
值得一提的是,去年爆火的WizardLM和WizardCode模型的研究也被ICLR 2024接收了。

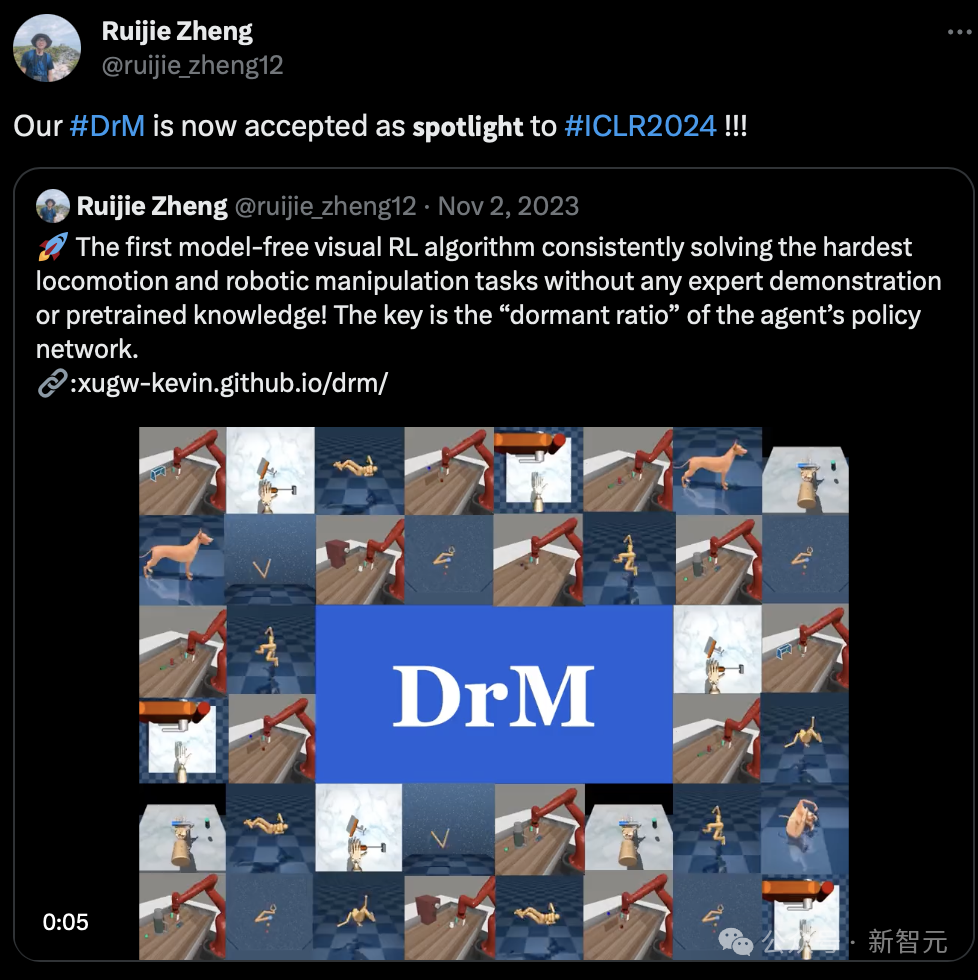
还有微软亚洲研究院团队提出的无模型视觉RL算法DrM被录用,无需任何专家示范或预先训练的知识,就能持续解决最难的运动和机器人操纵任务。
Oral论文85篇
UCLA五年级博士生Pan Lu关于MathVista的研究录用为Oral。
这篇研究构建了首个视觉场景下的数学推理基准,完成了112页的评估报告,首次对GPT-4V等12个大模型的数学推理能力进行了深入分析。

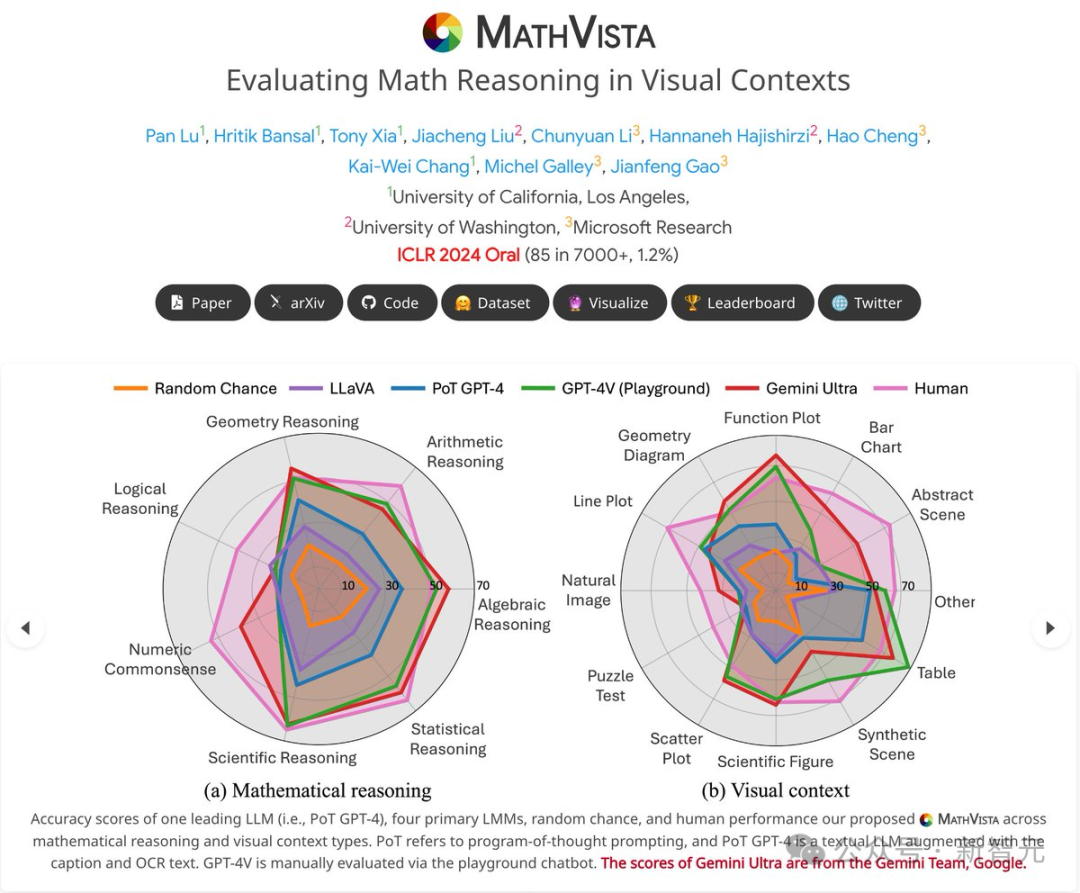
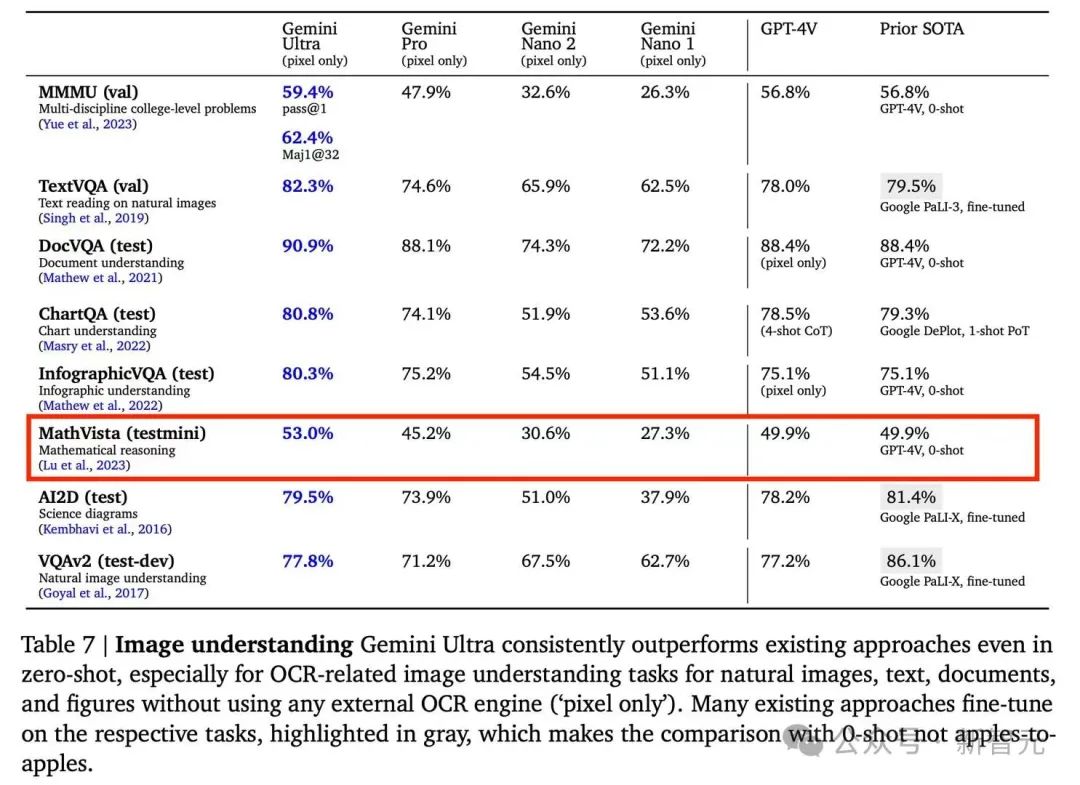
研究者称,多模态大模型的发展方兴未艾,数学推理领域未来可期,MathVista已经成为Google Gemini的多模态数学测试的基准之一。
还有来自霍普金斯大学的研究人员的论文也被ICLR 2024录用为oral,主要研究了了自监督3D模型在医学成像任务中的应用效果如何。

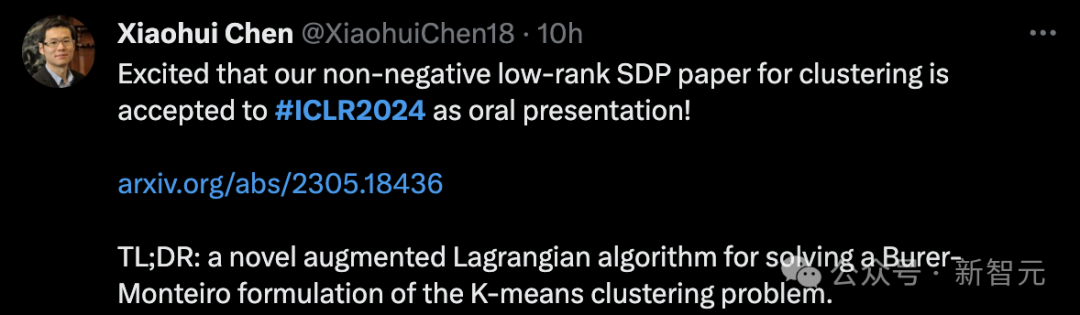
南加州大学的数学副教授Xiaohui Chen的论文「Statistically Optimal K-means Clustering via Nonnegative Low-rank Semidefinite Programming」获得Oral。
这是一种新的增强拉格朗日算法,用于解决K-means聚类问题的Burer-Monteiro公式。
一夜成名的智能体MetaGPT也录用为oral,目前Github有33.4k星。

普林斯顿等机构研究人员关于大模型微调对齐的研究被录用为ICLR 2024的oral论文。


大厂录用论文一览
每个大厂被ICLR 2024接收的研究都有哪些?
微软
微软亚洲研究院的高级研究员Jindong Wang带领团队的研究有2篇是Spotlight,还有2篇Poster。

Spotlight的两篇,一个是提出了对抗数据污染的LLM动态评估新方案DyVal,另一篇是基础模型时代的一个新的研究方向——噪声模型学习。
录用为Poster的一篇是LLM指令调优自动评测基准PandaLM,另一篇是关于小模型帮助LLM获得更好性能的研究。
苹果
苹果的机器学习研究院分享了团队2篇接收的论文。

第一篇提出了一种用于在Riemannian流形上学习连续函数的生成模型,通过利用流形的几何特性和内在坐标系的定义,能更好地捕捉函数的分布。

论文地址:https://arxiv.org/pdf/2305.15586.pdf
第二篇发现了从给定的单目视频,合成动态新视图的通用方法。

论文地址:https://arxiv.org/pdf/2310.08587.pdf
苹果团队另一篇关于扩散模型图像生成的研究也被录用。
他们提出来叫Matryoshka扩散模型新技术,一种专门用来生成高分辨率图像和视频的模型。
MDM的独特之处在于,通过使用NestedUNet架构,巧妙地将低分辨率的扩散过程融入到高分辨率的生成过程中。


论文地址:https://arxiv.org/pdf/2310.15111.pdf
谷歌
谷歌UNC等机构的研究人员提出了一个T2I全新评估框架,

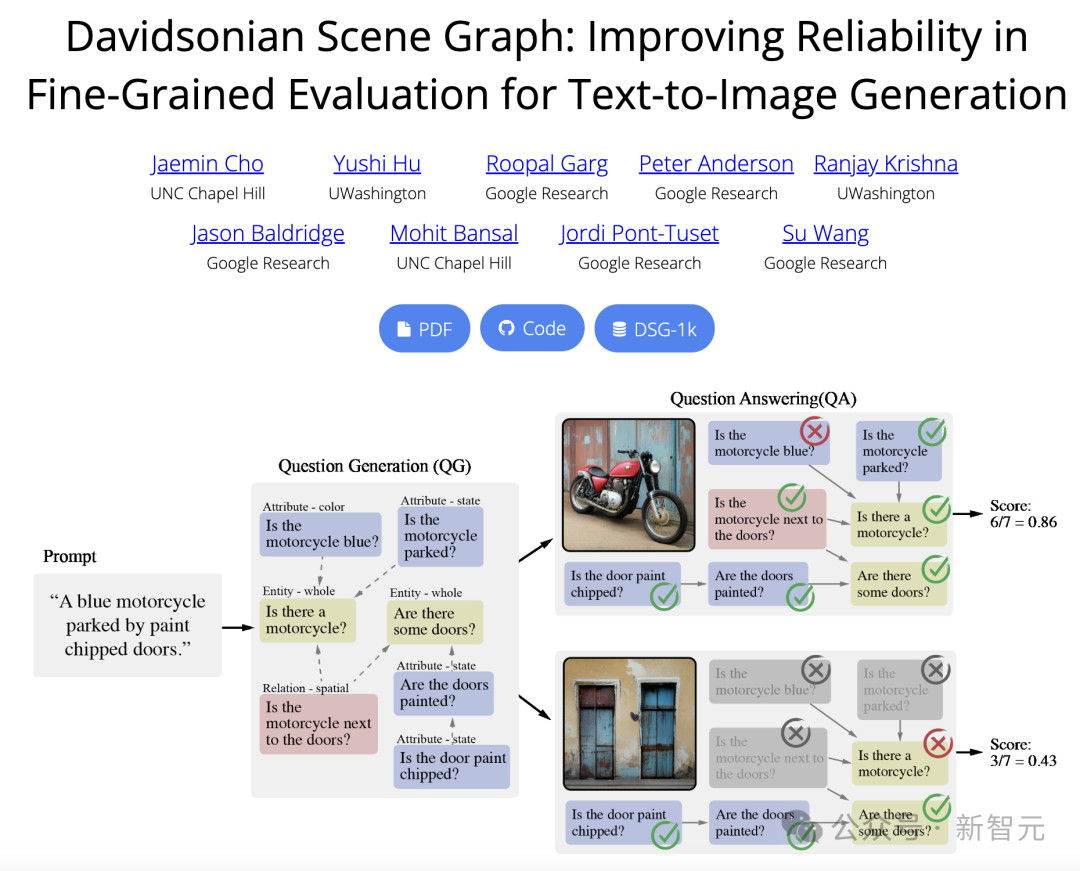
论文地址:https://google.github.io/dsg/
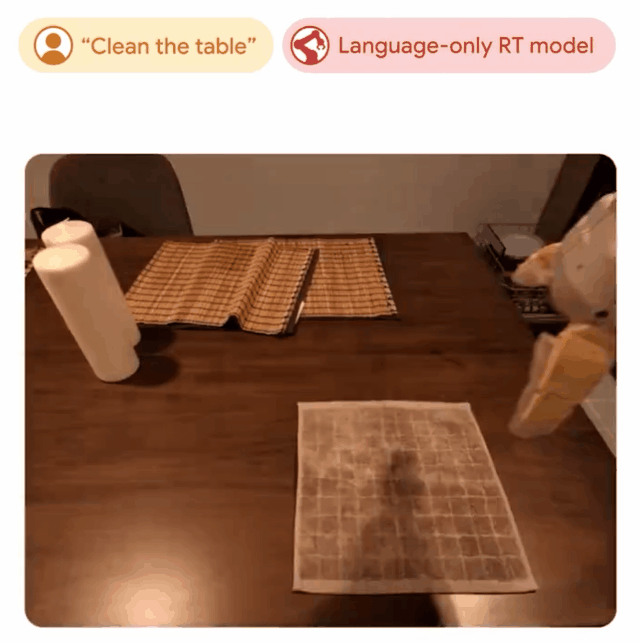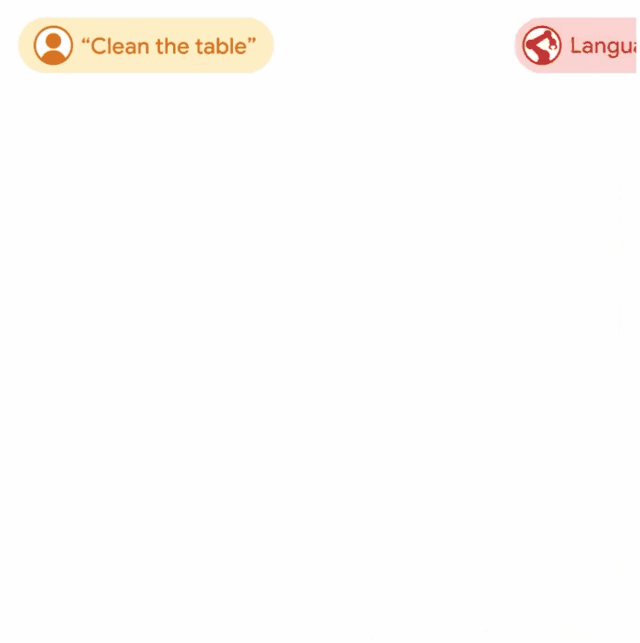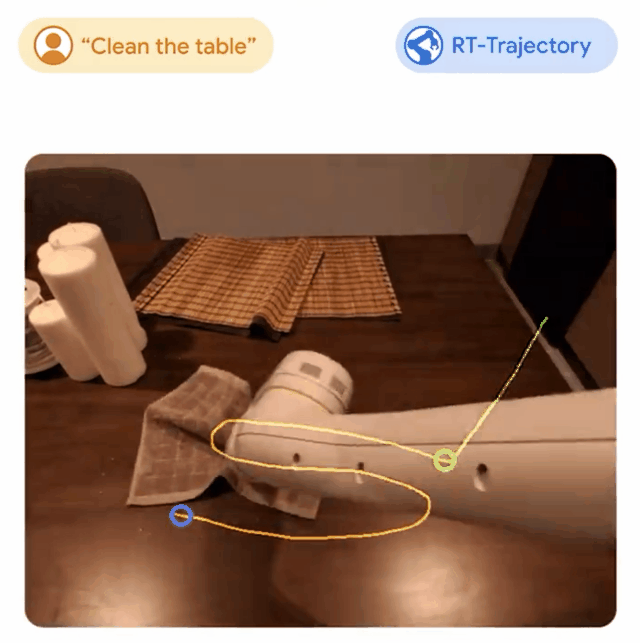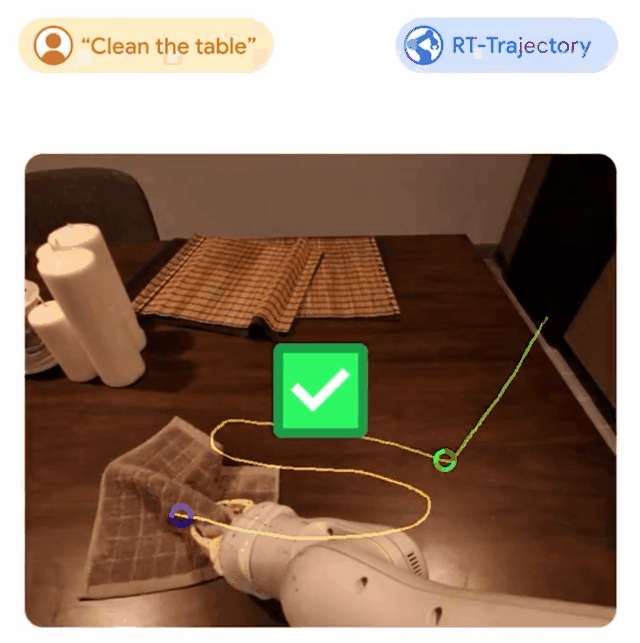
谷歌团队的机器人研究RT-Trajectory成功被录用为Spotlight。
RT-Trajectory模型通过自动将描述机器人运动的视觉轮廓添加到其训练中,来学习如何遵循指令。
英伟达
英伟达自动驾驶团队的研究EmerNeRF,一种重建动态驾驶场景的方法被ICLR录用。


Meta
Meta团队成员在去年推出Habitat 3.0被录用。
Habitat 3.0是第一个支持在多样化、逼真的室内环境中,就人机交互任务进行大规模训练的模拟器
还有来自KAUST、Snap等团队提出了Magic123,是一个基于NeRF的单张图像生成3D mesh的深度学习框架。
目前已在Github收揽1.4k星,论文已有85篇引用。

参考资料:
https://twitter.com/iclr_conf
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

