- 1Seata事务管理---Seata简介
- 2C语言强化-1.数据结构概述
- 3lora训练调参
- 4百度智能云千帆 ModelBuilder 技术实践系列:通过 SDK 快速构建并发布垂域模型_百度智能云千帆modelbuilder 最丰富的大模型,全流程工具链
- 5Qt(C++) | QPropertyAnimation动画(移动、缩放、透明)篇_qt 动画放大
- 6windows的svn_windows svn
- 7YOLOv8的代码如何升级到YOLOv10_yolov10 attributeerror: can't get attribute 'scdow
- 8分布式锁3: zk实现分布式锁3 使用临时顺序节点+watch监听实现阻塞锁_zk watch 与监听事件
- 9(五)阿里云ECS服务器的基本管理与磁盘扩容_阿里云ecs磁盘扩容
- 10【饭谈】面试官让你来个“自我介绍”,你准备怎么说?_自我介绍 需要说 技术栈
深度学习(15)--PyTorch构建卷积神经网络_使用pytorch搭建cnn神经网络
赞
踩
目录
二.graphviz + torchviz使PyTorch网络可视化
一.PyTorch构建卷积神经网络(CNN)详细流程
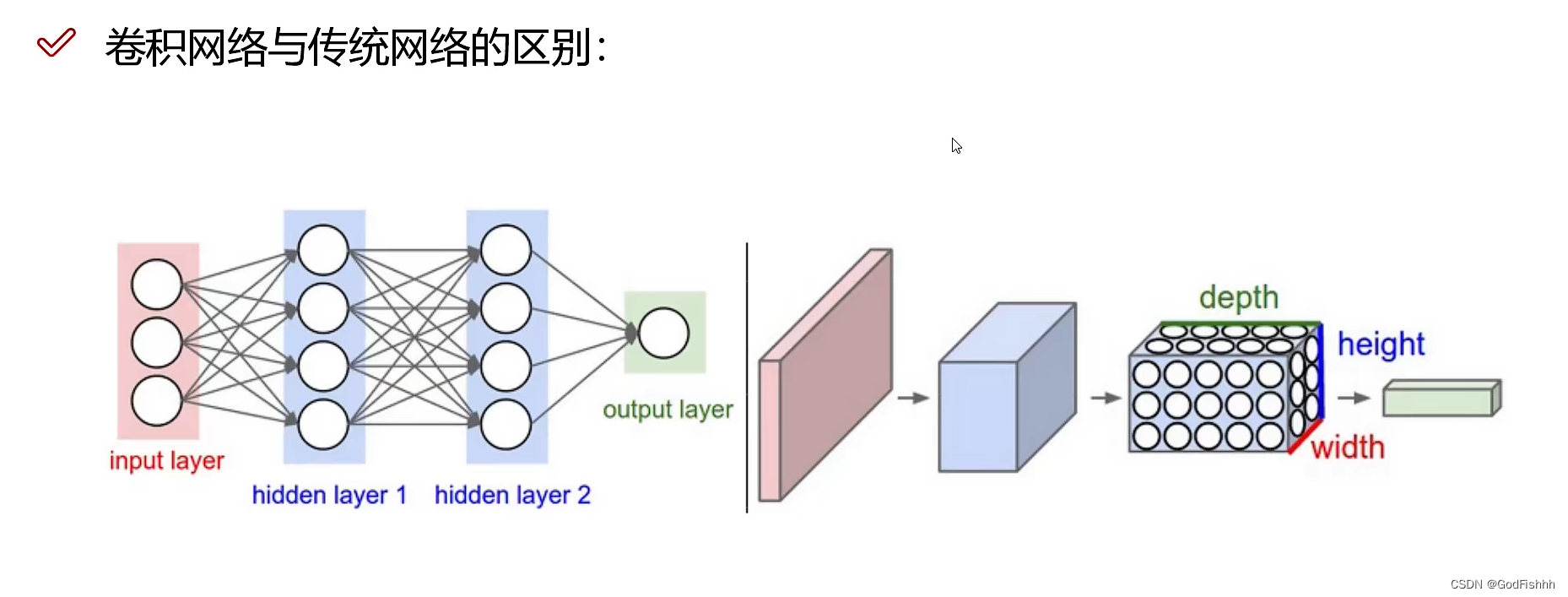
卷积神经网络(Convolutional Neural Networks)是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。
卷积神经网络的详细介绍可以参考博主写的文章:

PyTorch构建神经网络的第一步均为引入神经网络包
import torch.nn as nn
卷积神经网络的构建:
- class CNN(nn.Module):
- def __init__(self):
- super(CNN, self).__init__()
- # 卷积层->激活函数->池化层
- self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28) pytorch中是channel_first的,颜色通道写在第一个位置
- nn.Conv2d( # 1d对结构化数据 2d对图像数据 3d对视频数据
- in_channels=1, # 灰度图 输入的特征图数
- out_channels=16, # 要得到几多少个特征图 输出的特征图数,也就是卷积核的个数(一个卷积核进行卷积可以得到一个特征图,所以卷积核的个数与特征图的数量相同)
- kernel_size=5, # 卷积核大小
- stride=1, # 步长
- padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1 卷积后的图像大小: (h - Kernel_size + 2*p) / s + 1
- ), # 输出的特征图为 (16, 28, 28)
- nn.ReLU(), # relu层
- nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14) 池化后特征数变少
- )
- self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
- nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)
- nn.ReLU(), # relu层
- nn.MaxPool2d(2), # 输出 (32, 7, 7)
- )
- self.out = nn.Linear(32 * 7 * 7, 10) # 全连接层得到的结果 最终数据的大小以及分类的数量
-
- def forward(self, x):
- # 调用卷积层
- x = self.conv1(x)
- x = self.conv2(x)
- x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7),分类无法对三维的数据进行处理,所以需要将三维图像拉长成一维数据再来进行分类.
- # -1是自动计算,只需给出一个维度的大小,会自动计算另外个维度.eg.5x4 -> x.view(2,-1),-1对应的就是10. 2x5x10 -> x.view(2,-1),-1对应的就是5x10
- # 在此处,给出的第一个参数x.size(0)的值为batch,所以-1对应的值就是32x7x7
- # 调用全连接层(全连接层的输入必须是二维的矩阵,上述的flattern操作将参数x变成了一个二维矩阵)
- output = self.out(x)
- return output

详解:
1.创建的神经网络构建类一定要继承nn.Module,后续要调用Module包里面的方法构建神经网络。
2.构造函数的第一步永远是调用父类的构造函数,利用super()进行调用:
super(CNN, self).__init__()3.卷积神经网络的层次顺序一般为:卷积层-> 激活函数做非线性变换 ->池化层,并在输出之前设置一层全连接层。
4.上述代码构建的卷积神经网络是顺序Sequential的,设置有两个卷积层,两个激活函数,两个池化层,以及输出前的一个全连接层。(一般卷积一次就要池化一次)
nn.Sequential()5.卷积层的构造:通过Module模块中的Conv2d来构造卷积层,其中参数分别为:输入图片数据的颜色通道数(第一个卷积层)/输入的特征图数(之后的卷积层)、输出的特征图数、卷积核的大小、步长、padding值。(其中Conv1d用来处理结构化数据,Conv2d用来处理图片数据,Conv3d用来处理视频数据)
此处设置的卷积层由输入的1个特征图数得到最后的32个特征图数
- nn.Conv2d(1, 32, 5, 1, 2)
- nn.Conv2d(16, 32, 5, 1, 2)
值得注意的是,如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1 卷积后的图像大小: (h - Kernel_size + 2*p) / s + 1。
6.此处激活函数设置的是ReLU,可以根据自己的需求设置不同的激活函数。
nn.ReLU()7.池化层的构造: 只需要设置一个参数,即为进行池化操作的区域大小。
nn.MaxPool2d(kernel_size=2)8.全连接层的构造:输入的数据最后经过全连接层得到输出数据,参数分别为输入数据的大小,以及最后进行分类的类别数。
self.out = nn.Linear(32 * 7 * 7, 10)9.前向传播:PyTorch构建的神经网络,前向传播需要手动设置,此处先调用conv1和conv2两层,再将数据拉成二维的传入全连接层,得到最后的输出值。
二.graphviz + torchviz使PyTorch网络可视化
事先需要先安装graphviz库和torchviz库,graphviz具体安装步骤可以参考博主写的文章:
深度学习(9)--pydot库和graphviz库安装流程详解_pydot 怎么安装-CSDN博客![]() https://blog.csdn.net/GodFishhh/article/details/135929146?spm=1001.2014.3001.5501torchviz库可以直接再编译器中进行安装,也可也在cmd中对应环境中使用pip指令安装:
https://blog.csdn.net/GodFishhh/article/details/135929146?spm=1001.2014.3001.5501torchviz库可以直接再编译器中进行安装,也可也在cmd中对应环境中使用pip指令安装:


上述两个库安装完之后,导入网络可视化需要用到的头文件:
- from torchviz import make_dot
- from torchvision.models import vgg16 # 导入vgg16模型用于演示
2.1.可视化经典网络vgg16
- # 随机生成一个tensor张量(对应的数据为图片有十张,图片的大小为3x32x32)
- x = torch.randn(10, 3, 32, 32)
- # 实例化 vgg16
- model = vgg16()
- # 将 x 输入网络
- vgg16_out = model(x)
- # 实例化 make_dot
- vgg16_result = make_dot(vgg16_out)
- # result.view() 直接在当前路径下保存 pdf 并打开
- # 保存文件为pdf到指定路径并不打开
- vgg16_result.render(filename='vgg16_net_Structure', view=False, format='pdf')
生成如下两个文件



2.2.可视化自己定义的网络
- # 随机生成一个tensor张量(对应的数据为图片有四张,图片的大小为1x28x28)
- x = torch.randn(4, 1, 28, 28)
- # 实例化 vgg16
- model = CNN()
- # 将 x 输入网络
- CNN_out = model(x)
- # 实例化 make_dot
- CNN_result = make_dot(CNN_out)
- # result.view() 直接在当前路径下保存 pdf 并打开
- # 保存文件为pdf到指定路径并不打开
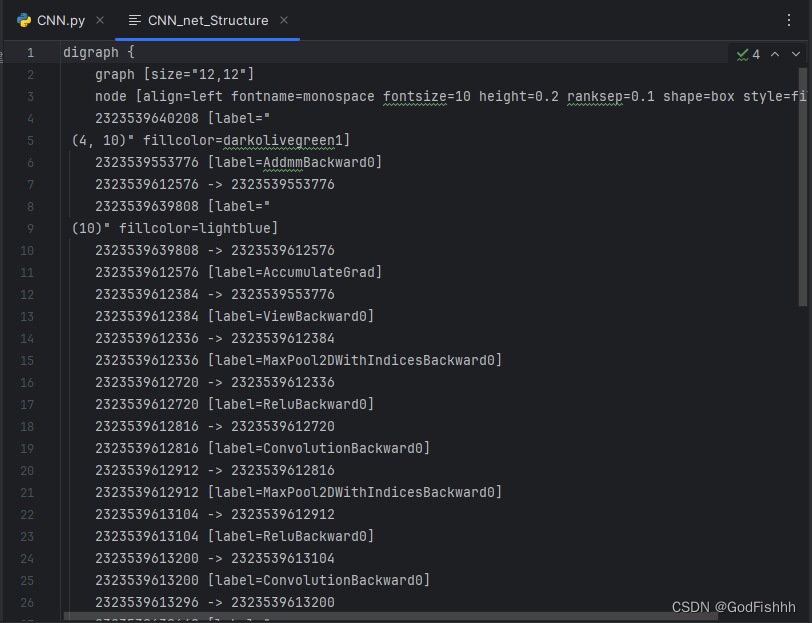
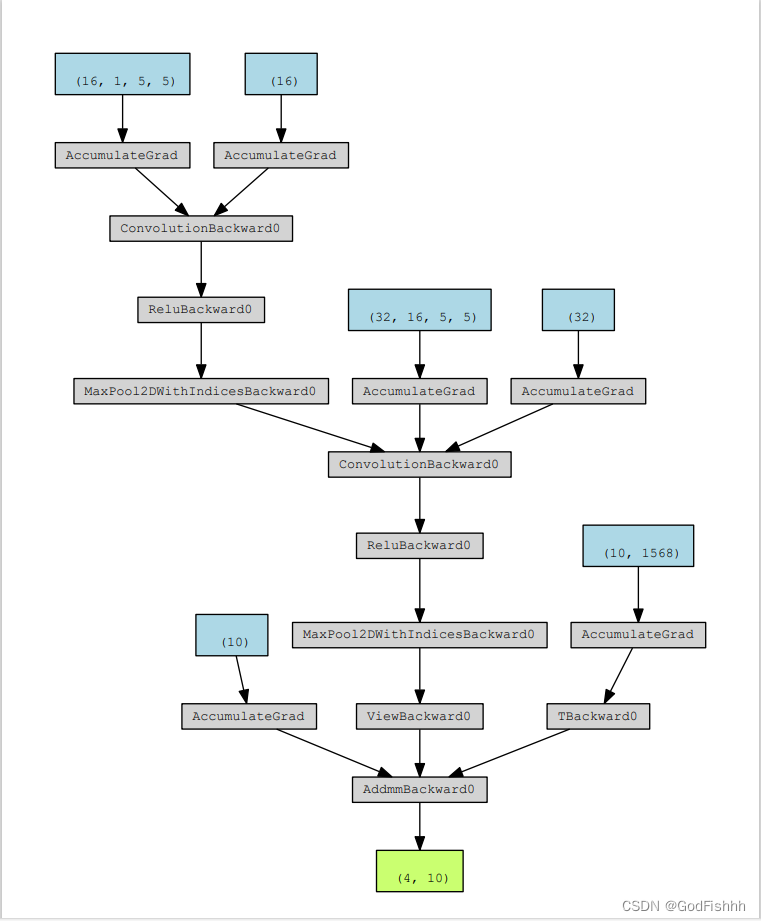
- CNN_result.render(filename='CNN_net_Structure', view=False, format='pdf')
生成如下两个文件
![]()