
- 1Mac 系统文件占用内存过大怎么办?_mac system data太大
- 2聚类分析|基于密度的聚类方法DBSCAN及其Python实现_dbscan特征处理
- 3查看redis常用命令_查看redis数据命令
- 4javaFX学习之提示框(Tooltip) 组件_javafx tooltip
- 5数据分析案例-2024 年全电动汽车数据集可视化分析_新能源公司数据分析项目
- 6SwiftUI 6.0(iOS/iPadOS 18)中全新的 Tab 以及 Sidebar+悬浮 TabView 样式_ios tabsidebar
- 7Redis教程(二十三):Redis的底层数据结构
- 8软件测试之自动化测试面试题合集(全)_软件测试自动化面试常见问题及答案解析
- 9MongoDB本地配置分片
- 1001、Python爬虫——以爬取官方医院信息为例(超详细讲解,小白完全可以看懂)_python爬取医院信息
随机森林分类模型(python案例代码)
赞
踩
随机森林模型概述
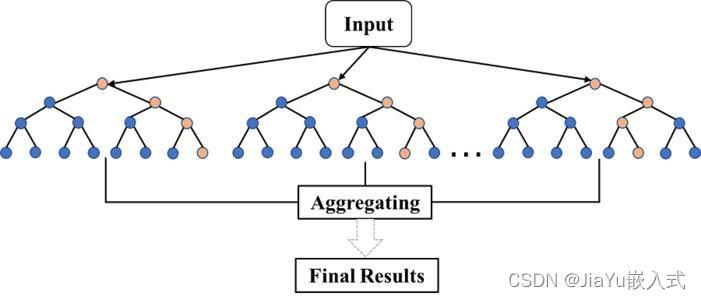
随机森林(Random Forest)是一种集成学习方法,常用于分类和回归问题。它通过构建多个决策树来进行预测,然后通过取这些树的输出的平均值(回归问题)或投票(分类问题)来提高模型的准确性和鲁棒性。随机森林具有很强的泛化能力,对于复杂的数据集和高维特征空间也表现良好。
特点和工作原理
决策树的集成
随机森林是由多个决策树组成的集成模型。每个决策树都是基学习器,用于对数据进行分类或回归。每个树的输出被整合起来以提高整体模型的性能。
随机性
随机森林引入了随机性,这使得每个决策树都是在不同的数据子集上训练的。具体来说,每个决策树的训练样本是通过有放回抽样(bootstrap抽样)得到的,这意味着某些样本可能在同一个树中出现多次,而其他一些样本可能根本没有出现。
特征的随机选择
在每个决策树的节点上,随机森林只考虑一部分特征进行分裂。这样可以确保每个树都不是完全相同的,增加了整体模型的多样性。
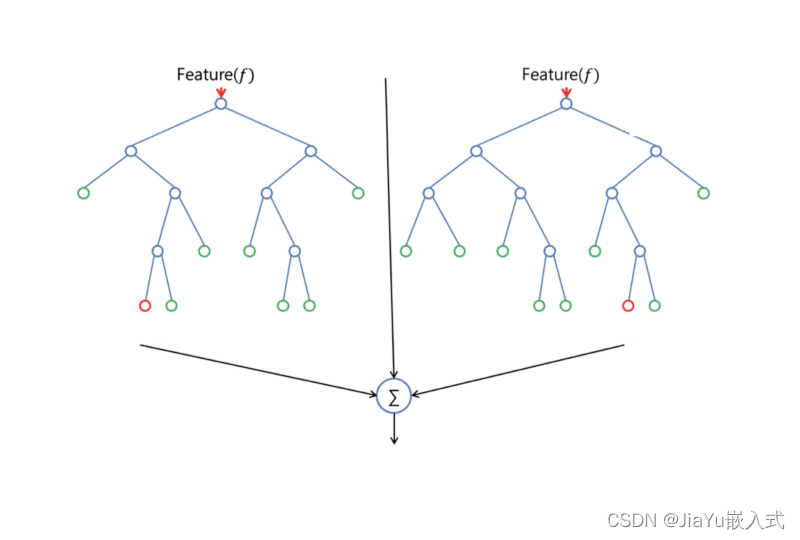
投票或平均
对于分类问题,随机森林采用多数投票的方式,即每个树投票选择的类别最终成为整体模型的输出。对于回归问题,取所有树的输出的平均值作为最终的预测结果。
防止过拟合
随机森林的随机性有助于防止过拟合,使得模型对训练数据的过度拟合的风险降低。
高性能
由于每个树都可以独立训练,随机森林可以通过并行处理快速构建,适用于大规模数据集。
随机森林通过整合多个决策树的意见,减小了单个决策树的过拟合风险,提高了模型的鲁棒性和泛化能力。
什么时候用随机森林分类?
复杂的分类问题
随机森林在处理复杂的分类问题时表现出色,能够捕捉数据中复杂的非线性关系和交互作用。
高维度的特征空间
当数据集具有大量特征时,随机森林通常能够有效地处理高维度的特征空间,而不容易受到维度灾难的影响。
大规模数据集
由于随机森林的训练可以并行化,因此它在处理大规模数据集时具有较好的性能,能够提供相对较快的训练速度。
不平衡的数据集
随机森林对于类别不平衡的问题相对鲁棒,因为在每个决策树的训练中采用了有放回的抽样,使得每个类别都有机会被充分考虑。
不需要过多的特征工程
随机森林对于原始数据的处理相对鲁棒,不太需要进行复杂的特征工程。它能够处理不同类型的特征,包括连续型和离散型特征。
模型解释性要求不高
虽然随机森林能够提供相对好的预测性能,但其模型结构相对复杂,解释性不如一些简单的线性模型。如果对于模型的解释性要求很高,可能需要考虑其他模型。
处理缺失值
随机森林能够有效地处理包含缺失值的数据,无需对缺失值进行额外的处理。
构建和训练的基本步骤
下面是使用Python中的Scikit-Learn库来构建和训练随机森林分类模型的基本步骤:
- # 导入必要的库
- from sklearn.model_selection import train_test_split
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.metrics import accuracy_score, classification_report
-
- # 假设你有一个包含特征的X和相应标签的y的数据集
- # X是特征矩阵,y是目标变量
-
- # 划分数据集为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 创建随机森林分类器
- rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
-
- # 训练模型
- rf_classifier.fit(X_train, y_train)
-
- # 在测试集上进行预测
- y_pred = rf_classifier.predict(X_test)
-
- # 评估模型性能
- accuracy = accuracy_score(y_test, y_pred)
- print(f'Accuracy: {accuracy:.2f}')
-
- # 输出更详细的分类报告
- print('Classification Report:\n', classification_report(y_test, y_pred))
上述代码中的关键步骤包括:
1、导入所需的库。
2、使用train_test_split函数将数据集划分为训练集和测试集。
3、创建RandomForestClassifier对象,设置参数如n_estimators(决策树的数量)等。
4、使用训练集来拟合(训练)模型。
5、使用训练后的模型对测试集进行预测。
6、使用accuracy_score和classification_report等指标来评估模型性能。
注意,随机森林有许多超参数,如n_estimators、max_depth等,你可以根据具体问题进行调整以优化模型性能。
案例代码1
在这个案例中,使用一个流行的数据集,即Iris(鸢尾花)数据集。这个数据集包含了三个不同种类的鸢尾花(Setosa、Versicolor和Virginica),每个种类有四个特征(花瓣长度、花瓣宽度、花萼长度和花萼宽度)。
首先,确保你已经安装了Scikit-Learn库。你可以使用以下命令安装:
pip install scikit-learn然后,你可以使用以下Python代码来创建和训练随机森林分类模型:
- # 导入必要的库
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.metrics import accuracy_score, classification_report
-
- # 加载鸢尾花数据集
- iris = load_iris()
- X = iris.data
- y = iris.target
-
- # 划分数据集为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 创建随机森林分类器
- rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
-
- # 训练模型
- rf_classifier.fit(X_train, y_train)
-
- # 在测试集上进行预测
- y_pred = rf_classifier.predict(X_test)
-
- # 评估模型性能
- accuracy = accuracy_score(y_test, y_pred)
- print(f'Accuracy: {accuracy:.2f}')
-
- # 输出更详细的分类报告
- print('Classification Report:\n', classification_report(y_test, y_pred))
在这个案例中,使用了鸢尾花数据集,将数据集划分为训练集和测试集,创建了一个包含100个决策树的随机森林分类器,并输出了模型的准确度和分类报告。你可以根据你的实际需求和数据集进行调整和修改。
案例代码2
- 随机森林需要调整的参数有:
- (1) 决策树的个数
- (2) 特征属性的个数
- (3) 递归次数(即决策树的深度)
-
- from numpy import inf
- from numpy import zeros
- import numpy as np
- from sklearn.model_selection import train_test_split
-
- #生成数据集。数据集包括标签,全包含在返回值的dataset上
- def get_Datasets():
- from sklearn.datasets import make_classification
- dataSet,classLabels=make_classification(n_samples=200,n_features=100,n_classes=2)
- #print(dataSet.shape,classLabels.shape)
- return np.concatenate((dataSet,classLabels.reshape((-1,1))),axis=1)
-
-
- #切分数据集,实现交叉验证。可以利用它来选择决策树个数。但本例没有实现其代码。
- #原理如下:
- #第一步,将训练集划分为大小相同的K份;
- #第二步,我们选择其中的K-1分训练模型,将用余下的那一份计算模型的预测值,
- #这一份通常被称为交叉验证集;第三步,我们对所有考虑使用的参数建立模型
- #并做出预测,然后使用不同的K值重复这一过程。
- #然后是关键,我们利用在不同的K下平均准确率最高所对应的决策树个数
- #作为算法决策树个数
-
- def splitDataSet(dataSet,n_folds): #将训练集划分为大小相同的n_folds份;
- fold_size=len(dataSet)/n_folds
- data_split=[]
- begin=0
- end=fold_size
- for i in range(n_folds):
- data_split.append(dataSet[begin:end,:])
- begin=end
- end+=fold_size
- return data_split
- #构建n个子集
- def get_subsamples(dataSet,n):
- subDataSet=[]
- for i in range(n):
- index=[] #每次都重新选择k个 索引
- for k in range(len(dataSet)): #长度是k
- index.append(np.random.randint(len(dataSet))) #(0,len(dataSet)) 内的一个整数
- subDataSet.append(dataSet[index,:])
- return subDataSet
-
- # subDataSet=get_subsamples(dataSet,10)
- #############################################################################
-
-
-
- #根据某个特征及值对数据进行分类
- def binSplitDataSet(dataSet,feature,value):
-
-
- mat0=dataSet[np.nonzero(dataSet[:,feature]>value)[0],:]
- mat1=dataSet[np.nonzero(dataSet[:,feature]<value)[0],:]
-
- return mat0,mat1
-
- '''
- feature=2
- value=1
- dataSet=get_Datasets()
- mat0,mat1= binSplitDataSet(dataSet,2,1)
- '''
-
- #计算方差,回归时使用
- def regErr(dataSet):
- return np.var(dataSet[:,-1])*np.shape(dataSet)[0]
-
- #计算平均值,回归时使用
- def regLeaf(dataSet):
- return np.mean(dataSet[:,-1])
-
- def MostNumber(dataSet): #返回多类
- #number=set(dataSet[:,-1])
- len0=len(np.nonzero(dataSet[:,-1]==0)[0])
- len1=len(np.nonzero(dataSet[:,-1]==1)[0])
- if len0>len1:
- return 0
- else:
- return 1
-
-
- #计算基尼指数 一个随机选中的样本在子集中被分错的可能性 是被选中的概率乘以被分错的概率
- def gini(dataSet):
- corr=0.0
- for i in set(dataSet[:,-1]): #i 是这个特征下的 某个特征值
- corr+=(len(np.nonzero(dataSet[:,-1]==i)[0])/len(dataSet))**2
- return 1-corr
-
-
- def select_best_feature(dataSet,m,alpha="huigui"):
- f=dataSet.shape[1] #拿过这个数据集,看这个数据集有多少个特征,即f个
- index=[]
- bestS=inf;
- bestfeature=0;bestValue=0;
- if alpha=="huigui":
- S=regErr(dataSet)
- else:
- S=gini(dataSet)
-
- for i in range(m):
- index.append(np.random.randint(f)) #在f个特征里随机,注意是随机!选择m个特征,然后在这m个特征里选择一个合适的分类特征。
-
- for feature in index:
- for splitVal in set(dataSet[:,feature]): #set() 函数创建一个无序不重复元素集,用于遍历这个特征下所有的值
- mat0,mat1=binSplitDataSet(dataSet,feature,splitVal)
- if alpha=="huigui": newS=regErr(mat0)+regErr(mat1) #计算每个分支的回归方差
- else:
- newS=gini(mat0)+gini(mat1) #计算被分错率
- if bestS>newS:
- bestfeature=feature
- bestValue=splitVal
- bestS=newS
- if (S-bestS)<0.001 and alpha=="huigui": # 对于回归来说,方差足够了,那就取这个分支的均值
- return None,regLeaf(dataSet)
- elif (S-bestS)<0.001:
- #print(S,bestS)
- return None,MostNumber(dataSet) #对于分类来说,被分错率足够下了,那这个分支的分类就是大多数所在的类。
- #mat0,mat1=binSplitDataSet(dataSet,feature,splitVal)
- return bestfeature,bestValue
-
- def createTree(dataSet,alpha="huigui",m=20,max_level=10): #实现决策树,使用20个特征,深度为10,
- bestfeature,bestValue=select_best_feature(dataSet,m,alpha=alpha)
- if bestfeature==None:
- return bestValue
- retTree={}
- max_level-=1
- if max_level<0: #控制深度
- return regLeaf(dataSet)
- retTree['bestFeature']=bestfeature
- retTree['bestVal']=bestValue
- lSet,rSet=binSplitDataSet(dataSet,bestfeature,bestValue) #lSet是根据特征bestfeature分到左边的向量,rSet是根据特征bestfeature分到右边的向量
- retTree['right']=createTree(rSet,alpha,m,max_level)
- retTree['left']=createTree(lSet,alpha,m,max_level) #每棵树都是二叉树,往下分类都是一分为二。
- #print('retTree:',retTree)
- return retTree
-
- def RondomForest(dataSet,n,alpha="huigui"): #树的个数
- #dataSet=get_Datasets()
- Trees=[] # 设置一个空树集合
- for i in range(n):
- X_train, X_test, y_train, y_test = train_test_split(dataSet[:,:-1], dataSet[:,-1], test_size=0.33, random_state=42)
- X_train=np.concatenate((X_train,y_train.reshape((-1,1))),axis=1)
- Trees.append(createTree(X_train,alpha=alpha))
- return Trees # 生成好多树
- ###################################################################
-
- #预测单个数据样本,重头!!如何利用已经训练好的随机森林对单个样本进行 回归或分类!
- def treeForecast(trees,data,alpha="huigui"):
- if alpha=="huigui":
- if not isinstance(trees,dict): #isinstance() 函数来判断一个对象是否是一个已知的类型
- return float(trees)
-
- if data[trees['bestFeature']]>trees['bestVal']: # 如果数据的这个特征大于阈值,那就调用左支
- if type(trees['left'])=='float': #如果左支已经是节点了,就返回数值。如果左支还是字典结构,那就继续调用, 用此支的特征和特征值进行选支。
- return trees['left']
- else:
- return treeForecast(trees['left'],data,alpha)
- else:
- if type(trees['right'])=='float':
- return trees['right']
- else:
- return treeForecast(trees['right'],data,alpha)
- else:
- if not isinstance(trees,dict): #分类和回归是同一道理
- return int(trees)
-
- if data[trees['bestFeature']]>trees['bestVal']:
- if type(trees['left'])=='int':
- return trees['left']
- else:
- return treeForecast(trees['left'],data,alpha)
- else:
- if type(trees['right'])=='int':
- return trees['right']
- else:
- return treeForecast(trees['right'],data,alpha)
-
-
-
- #随机森林 对 数据集打上标签 0、1 或者是 回归值
- def createForeCast(trees,test_dataSet,alpha="huigui"):
- cm=len(test_dataSet)
- yhat=np.mat(zeros((cm,1)))
- for i in range(cm): #
- yhat[i,0]=treeForecast(trees,test_dataSet[i,:],alpha) #
- return yhat
-
-
- #随机森林预测
- def predictTree(Trees,test_dataSet,alpha="huigui"): #trees 是已经训练好的随机森林 调用它!
- cm=len(test_dataSet)
- yhat=np.mat(zeros((cm,1)))
- for trees in Trees:
- yhat+=createForeCast(trees,test_dataSet,alpha) #把每次的预测结果相加
- if alpha=="huigui": yhat/=len(Trees) #如果是回归的话,每棵树的结果应该是回归值,相加后取平均
- else:
- for i in range(len(yhat)): #如果是分类的话,每棵树的结果是一个投票向量,相加后,
- #看每类的投票是否超过半数,超过半数就确定为1
- if yhat[i,0]>len(Trees)/2:
- yhat[i,0]=1
- else:
- yhat[i,0]=0
- return yhat
-
-
-
- if __name__ == '__main__' :
- dataSet=get_Datasets()
- print(dataSet[:,-1].T) #打印标签,与后面预测值对比 .T其实就是对一个矩阵的转置
- RomdomTrees=RondomForest(dataSet,4,alpha="fenlei") #这里我训练好了 很多树的集合,就组成了随机森林。一会一棵一棵的调用。
- print("---------------------RomdomTrees------------------------")
- #print(RomdomTrees[0])
- test_dataSet=dataSet #得到数据集和标签
- yhat=predictTree(RomdomTrees,test_dataSet,alpha="fenlei") # 调用训练好的那些树。综合结果,得到预测值。
- print(yhat.T)
- #get_Datasets()
- print(dataSet[:,-1].T-yhat.T)


